网络退化、过拟合和梯度消散
转载自:https://blog.csdn.net/c2250645962/article/details/102838830 作者:梦坠凡尘
过拟合
指的是模型在训练数据集上表现良好,在测试数据集上表现很差。
原因
模型将对训练数据过学习,将训练数据的特性当成共性学习进去(对数据的细节刻画的过于仔细)。当过拟合模型应用在测试数据集上时,由于测试数据集并不具备有训练数据独有的特性,所以造成模型泛化能力差,在测试数据集上表现不佳。
应对方法
-
增大网络规模
-
扩大训练集数据
-
对模型使用正则化,平衡数据集大小和模型复杂度
-
Dropout,主要用于深度学习的全连接层,Dropout方法是在一定的概率上(通常设置为0.5,原因是此时随机生成的网络结构最多)隐式的去除网络中的神经元。
-
Bagging和Boosting,Bagging和Boosting是机器学习中的集成方法,多个模型的组合可以弱化每个模型中的异常点的影响,保留模型之间的通性,弱化单个模型的特性
网络退化
在增加网络层数的过程中,training accuracy 逐渐趋于饱和,继续增加层数,training accuracy 就会出现下降的现象,而这种下降不是由过拟合造成的。
原因
理论上讲,较深的模型不应该比和它对应的,较浅的模型更差。因为较深的模型是较浅的模型的超空间。较深的模型可以这样得到:先构建较浅的模型,然后添加很多恒等映射的网络层。
实际上较深模型后面添加的不是恒等映射,而是一些非线性层。因此,退化问题也表明了:通过多个非线性层来近似恒等映射可能是困难的。
应对方法
学习残差。Resnet正是基于此问题提出。
梯度消散/爆炸
原因
梯度消散和梯度爆炸本质上是一样的,都是因为网络层数太深而引发的梯度反向传播中的连乘效应。Sigmoid激活函数最容易产生梯度消散,这是由于它的函数特性决定的。
Sigmoid函数图像如下图:
其导数图像如下图:
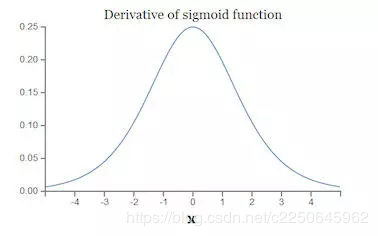
由图中可以知道,如果使用Sigmoid作为激活函数,那么其梯度不可能超过0.25,当层数叠加,经过链式求导后。很容易产生梯度消失。
应对方法
- 改换激活函数,使用relu、LeakyRelu、ELU等激活函数可以改善梯度消散或爆炸问题。relu导数的正数部分恒等于1,所以不会产生梯度消失和梯度爆炸。
- BatchNormalization。对每一层的输入做scale和shift方法,将每层神经元的输入分布强行拉回均值为0、方差为1的标准正态分布,这就使得激活层输入值落入在非线性函数对输入值比较敏感的区域,使得输入的小变化会导致损失函数较大的变化,使得梯度变大,训练速度加快,且避免梯度消失问题。
- ResNet残差结构。
- 梯度剪切,该方法主要是针对梯度爆炸提出。其思想是设置一个梯度剪切阈值,更新梯度时,如果梯度超过这个阈值,那么限制其在这个范围之内。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号