Netty学习笔记-入门版
Netty学习笔记
前言
本文简单介绍下netty的基本原理,I/O模型,Reactor线程模型以及架构设计等相关知识点。
什么是Netty
Netty是由JBOSS提供的一个Java开源框架。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
Netty 是一个基于NIO的客户、服务器端编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户,服务端应用。Netty相当简化和流线化了网络应用的编程开发过程,例如,TCP和UDP的socket服务开发。

Netty是由NIO演进而来,使用过NIO编程的用户就知道NIO编程非常繁重,Netty是能够能跟好的使用NIO
IO基础
概念说明
IO简单介绍

IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
比如你打开浏览器,访问新浪首页,浏览器这个程序就需要通过网络IO获取新浪的网页。浏览器首先会发送数据给新浪服务器,告诉它我想要首页的HTML,这个动作是往外发数据,叫Output,随后新浪服务器把网页发过来,这个动作是从外面接收数据,叫Input。所以,通常,程序完成IO操作会有Input和Output两个数据流。当然也有只用一个的情况,比如,从磁盘读取文件到内存,就只有Input操作,反过来,把数据写到磁盘文件里,就只是一个Output操作。
用户空间与内核空间

现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备(例如负责磁盘IO的设备)的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操作系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0×00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
进程(Process)
是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。程序是指令、数据及其组织形式的描述,进程是程序的实体。
线程(thread)
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
程序和进程
1个程序可以对应多个进程,但1个进程只能对应1个程序。
说白了就是,一个程序可以重复运行,开几个窗口,比如网游的“双开”,一个进程可以对应多个程序就是一个DLL文件可一被多个程序运用,比如DirectX9的动态链接库,就是,许多游戏都要有它才能运行。

我们简单总结下:
进程包含线程。
进程:指在系统中正在运行的一个应用程序;程序一旦运行就是进程;进程——资源分配的最小单位。
线程:系统分配处理器时间资源的基本单元,或者说进程之内独立执行的一个单元执行流。线程——程序执行的最小单位。
进程切换
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
- 保存处理机上下文,包括程序计数器和其他寄存器。
- 更新PCB信息。
- 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
- 选择另一个进程执行,并更新其PCB。
- 更新内存管理的数据结构。
- 恢复处理机上下文。
注:总而言之就是很耗资源
进程阻塞
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。当进程进入阻塞状态,是不占用CPU资源的。
文件描述符
简单理解:一个指向文件本身的指针(由系统所管理的引用标识,该标识可以被系统重新定位到一个内存地址上,间接访问对象 ),值是非负整数。
文件描述符(File descriptor,简称fd)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
文件句柄
Windows下的概念。句柄是Windows下各种对象的标识符,比如文件、资源、菜单、光标等等。文件句柄和文件描述符类似,它也是一个非负整数,也用于定位文件数据在内存中的位置。
缓存IO
大多数文件系统的默认IO都是缓存IO。过程是:数据先被拷贝到操作系统的内核缓冲区(页缓存 page cache)中,然后再拷贝到应用程序的地址空间。
Linux 网络I/O模型
同步、异步、阻塞、非阻塞的概念
同步
所谓同步,发起一个功能调用的时候,在没有得到结果之前,该调用不返回,也就是必须一件事一件事的做,等前一件做完了,才能做下一件。
main函数
int main(){
add();
sout();
}
int add(){
return 1+1;
}
异步

main函数
int main(){
ajax();
sout();
}
int ajax(){
return 1+1;
}
调用发出后,调用者不能立刻得到结果,而是实际处理这个调用的函数完成之后,通过状态、通知和回调来通知调用者。
比如ajax:
请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
(在服务器处理的时候,客户端还可以干其他的事)
阻塞
指调用结果返回之前,当前线程会被挂起(CPU不给线程分配时间片),函数只能在得到结果之后才会返回。
(阻塞调用和同步调用的区别)同步调用的时候,当前线程仍然可能是激活的,只是在逻辑上当前函数没有返回。例如:在Socket中调用recv函数,如果缓冲区没有数据,这个函数会一直等待,知道数据返回。而在此时,这个线程还是可以处理其他消息的。
非阻塞
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
总结
同步是指A调用了B函数,B函数需要等处理完事情才会给A返回一个结果。A拿到结果继续执行。
异步是指A调用了B函数,A的任务就完成了,去继续执行别的事了,等B处理完了事情,才会通知A。
阻塞是指,A调用了B函数,在B没有返回结果的时候,A线程被CPU挂起,不能执行任何操作(这个线程不会被分配时间片)
非阻塞是指,A调用了B函数,A不用一直等待B返回结果,可以先去干别的事。
举个例子
老张爱喝茶,废话不说,煮开水。 出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
- 老张把水壶放到火上,立等水开。(同步阻塞) 老张觉得自己有点傻
- 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞) 老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
- 老张把响水壶放到火上,立等水开。(异步阻塞) 老张觉得这样傻等意义不大
- 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞) 老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。立等的老张,阻塞;看电视的老张,非阻塞。情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
I/O模型
recvfrom函数用于从(已连接)套接口上接收数据,并捕获数据发送源的地址。
本函数用于从(已连接)套接口上接收数据,并捕获数据发送源的地址。
(简单理解就是客户端等待服务端给数据的函数)

举个例子,其中的角色,客人(小明)对应内核线程,服务员对应的是用户线程。现在大黄在南亭新开了一家黄焖鸡,小明(客人)觉得很新鲜,准备喊上几个基友去南亭搓一顿黄焖鸡。
小明到店里了,如果小明成功点餐则需要经过两个步骤,第一步是思考要点什么吃的,第二步是跟服务员说要吃什么。
该模型的内核线程分为两个阶段
- 数据准备阶段:(等待点餐)未阻塞,当数据准备完成之后,会主动的通知用户进程数据已经准备完成,对用户进程做一个回调。
- 数据拷贝阶段:(进行点餐)阻塞用户进程,等待数据拷贝。
阻塞 I/O(blocking IO)

现在黄焖鸡的老板大黄给每个客人都配一个服务员,只要有一个客人来的话,就在旁边等客人思考吃什么并且进行点餐。只要客人还没有点餐完毕,对应的这个服务员就不能离开去做别的事情。
映射到Linux操作系统中,这就是阻塞的IO模型。在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
用户线程(服务员) 内核线程(客人)

当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的两个阶段:
准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。- 当kernel一直等到数据准备好了,它就会
将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待IO(准备IO)和执行IO)都被block了。
非阻塞 I/O(nonblocking IO)
现在随着有些大学生月初拿到零花钱,开始浪了,黄焖鸡的生意也变得越来越火爆了,来吃饭的客人越来越多,要配的服务员也越来越多,黄焖鸡的老板大黄心想这不对劲啊,要是突然同时来100个客人,就要有100个服务员,肯定巨亏啊,得想个法子提高效率。这时候老板大黄想到,在客人想点什么吃的时候,服务员完全可以去做别的事情,例如去给别的桌的客人点餐,只要偶尔过来问下客人是否要点餐了,一旦发现客人需要点餐了,就开始点餐。
映射到Linux操作系统中,这就是非阻塞的IO模型。linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:

- 当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。
- 一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
信号驱动I/O( signal driven IO )
过了一段时间,客人们好多都反应,你们服务员太烦人了,整天问我是不是可以点餐了,客人说我们干脆要点餐的时候就叫服务员过来好了,老板大黄心想这样也不错,能提高餐厅的运行效率,赚多点钱,便答应了(这时候的服务员还在客人旁边傻乎乎的站着,只等着客人喊他点餐)。
映射到Linux操作系统中,这就是信号驱动I/O。当数据报准备好的时候,内核会向应用程序发送一个信号,进程对信号进行捕捉,并且调用信号处理函数来获取数据报。

I/O 多路复用( IO multiplexing)
老板大黄巡查店内情况,看到了服务员大多都傻乎乎的站着等客人喊他点餐,作为资本家的大黄,当然是要充分利用劳动力的。所以老板给服务员们开了个会,安排他们一个人负责一个区域(多个客人)的客人点餐需求,等到客人喊他点餐时,就过去点餐。
映射到Linux操作系统中,这就是I/O 多路复用。IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。

当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制
一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
异步 I/O(asynchronous IO)
后来,随着黄焖鸡的味道大家都比较喜爱,口碑逐渐建立了起来,生意越发地火爆,常常座无虚席,大黄也开始梦想着多久能实现一个小目标。大学城里有些创业团队看到了黄焖鸡的火爆程度,看到服务员有很多时候是在给客人点餐,他们结合自己的专业知识,跟老板说给老板开发个手机点餐系统,客人通过手机就能点餐,服务员只需要查看系统的点餐情况进行上菜就好,老板大黄一看,秒啊,急忙答应了,通过点餐系统,餐厅运行效率更高了,接待的客人也越来越多,离一个小目标的梦想也越来越近了。
映射到Linux操作系统中,这就是异步 I/O。Linux下的asynchronous IO其实用得很少。先看一下它的流程:
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
用户进程只需要知道内核线程处理的结果
5中I/O模型对比

IO多路复用的三种机制
select
数组(长度1024)存储所有的fd
说的通俗一点就是各个客户端连接的文件描述符也就是套接字,都被放到了一个集合中,调用select函数之后会一直监视这些文件描述符中有哪些可读,如果有可读的描述符那么我们的工作进程就去读取资源。
select 在一个进程内可以维持最多 1024 个连接
poll
链表存储所有的fd
poll 和 select 的实现非常类似,本质上的区别就是存放 fd 集合的数据结构不一样。poll 在select基础上做了加强,可以维持任意数量的连接。
但 select 和 poll 方式有一个很大的问题就是,我们不难看出来 select和poll 是通过轮循的方式来查找是否可读或者可写,打个比方,如果同时有100万个连接都没有断开,而只有一个客户端发送了数据,所以这里它还是需要循环这么多次,造成资源浪费。
epoll
链表存储ready的fd
不需要遍历全部fd去找ready的,其全部的fd放在一个红黑树中加以维护。
epoll 是 select 和 poll 的增强版,epoll 同 poll 一样,文件描述符数量无限制。
epoll是基于内核的反射机制,在有活跃的 socket 时,系统会调用我们提前设置的回调函数。而 poll 和 select 都是遍历。
但是也并不是所有情况下 epoll 都比 select/poll 好,比如在如下场景:
在大多数客户端都很活跃的情况下,系统会把所有的回调函数都唤醒,所以会导致负载较高。既然要处理这么多的连接,那倒不如 select 遍历简单有效。
NIO入门
引言
在Java中提供了三种IO模型:BIO、NIO、AIO,模型的选择决定了程序通信的性能。
使用场景
-
BIO
BIO适用于连接数比较小的应用,这种IO模型对服务器资源要求比较高。 -
NIO
NIO适用于连接数目多、连接时间短的应用,比如聊天、弹幕、服务器间通讯等应用。 -
AIO
AIO适用于连接数目多、连接时间长的应用,比如相册服务器。
BIO
同步阻塞式
无脑创建线程

伪异步I/O阻塞式
改用线程池

NIO
同步非阻塞模型,服务器端用一个线程处理多个连接,客户端发送的连接请求会注册到多路复用器上,多路复用器轮询到连接有IO请求就进行处理:

NIO的非阻塞模式,使得一个线程从某通道发送请求或者读取数据时,如果目前没有可用的数据,不会使线程阻塞,在数据可读之前,该线程可以做其他的事情。
NIO有三大核心部分:
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)


由图可知:
- 每个Channel对应一个Buffer。
- Selector对应一个线程,一个线程对应多个Channel。
- Selector会根据不同的事件,在各个通道上切换。
- Buffer是内存块,底层是数据。
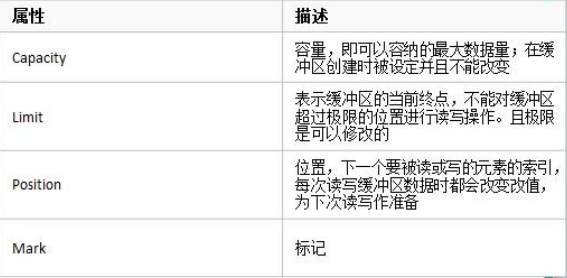
缓冲区(Buffer)
本质是可以读写数据的内存块,Channel读取或者写入的数据必须通过Buffer:

java.nio.Buffer抽象类的属性:
复制代码
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
读写交换要使用flip方法。
通道(Channel)
通道是双向的,可以读操作、也可以写操作。
java.nio.channels.Channel接口的常用实现类:

FileChannel用于文件的数据读写,DatagramChannel用于UDP的数据读写,ServerSocketChannel和SocketChannel用于TCP的数据读写。
选择器(Selector)
Selector选择器使用一个线程来维护。多个Channel会以事件的方式注册到同一个Selector,当有事件发生时,Selector会获取事件,然后针对每个事件进行响应的处理。这样就不必为每个连接创建一个线程,不用维护多线程,也不会有多线程之间的上下文切换导致的系统的开销。
Selector示意图:

AIO
异步非阻塞模型,AIO引入异步通道的概念,使用了Proactor,只有有效的请求才启动线程,特点是先由操作系统完成后,才通知服务器端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
对比

Reactor线程模型
Reactor线程模型是基于同步非阻塞IO实现的。对于异步非阻塞IO的实现是Proactor模型。
Netty就是基于Reactor线程模型开发的,我们今天来简单分析下:
Reactor模型中的三种角色及含义:
Reactor:将I/O事件分配给对应的handler。
Acceptor:处理客户端新连接,并分派请求到处理器链中。
Handlers:执行非阻塞读写任务。

Reactor常用的线程模型有三种

Reactor单线程模型
单线程模型简图

单线程模型就是指所有的I/O操作都是在一个线程中处理完成,NIO的线程需要接受客户端的Tcp连接,并且向客户端发送Tcp连接,读取通信两端的请求或应答,发送请求和应答。
单线程模型详细图解

大致了解了后,让我们看下这个详细流程,当客户端发起连接,Acceptor负责接收客户端的Tcp请求,链路建立成功后,通过Dispatcher将对应的ByteBuffer派发到指定的Hnadler上进行消息解码,用户Handler通过NIO线程将消息发送给客户端。单线程模型其实就是Acceptor的处理和Handler的处理都处在同一个线程中,当其中的一个Hnadler阻塞时,会导致其它的client和handler无法执行,甚至整个服务不能接受新的请求。
单线程模型缺点:不适用于高负载,高并发的场景。
因为一个NIO线程如果同时处理很多的链路,则机器在性能上无法满足海量的消息的编码,解码,读取和发送。如果NIO线程负载过重,处理速度变慢,会导致大量的客户端请求超时,甚至导致整个通信模块不可用。
Reactor多线程模型
为了解决单线程模型的缺点,设计出了多线程模型。如下简图:
多线程模型简图

如图所示在多线程模型下,用一个专门的NIO线程Acceptor来监听客户端的Tcp请求,对于网络I/O的读写操作和消息的读取、编码、解码、发送等使用NIO线程池来完成。因为客户端请求数量大于NIO线程池中的线程,一个NIO线程可以同时处理多条链路请求,但是一个链路请求只对应一个NIO线程。Reactor多线程模型能够大多数的使用场景,但是当客户端的并发连接非常的多,或者是服务端需要对客户端进行安全认证等,单个Acceptor线程可能会存在性能不足的问题。
主从Reactor多线程模型

Reactor的主从多线程模型
如图所示,从这个简图可以看出,服务端用于监听和接收客户端连接的不再是单个线程,而是分配了一个线程池。Acceptor线程池接收了客户端的请求连接并处理完成后(可能包含了权限认证等),后续的I/O操作再由NIO线程池来完成。这样就解决了多线程中客户端请求太多或者需要认证时一个Acceptor可能处理不过来的性能问题。
netty的线程模型
netty的线程模型是可以通过设置启动类的参数来配置的,设置不同的启动参数,netty支持Reactor单线程模型、多线程模型和主从Reactor多线程模型。
server端工作原理

NettyServer整体架构图.png
server端启动时绑定本地某个端口,将自己NioServerSocketChannel注册到某个boss NioEventLoop的selector上。
server端包含1个boss NioEventLoopGroup和1个worker NioEventLoopGroup,NioEventLoopGroup相当于1个事件循环组,这个组里包含多个事件循环NioEventLoop,每个NioEventLoop包含1个selector和1个事件循环线程。
每个boss NioEventLoop循环执行的任务包含3步:
- 第1步:轮询accept事件;
- 第2步:处理io任务,即accept事件,与client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个worker NioEventLoop的selector上;
- 第3步:处理任务队列中的任务,runAllTasks。任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务。
每个worker NioEventLoop循环执行的任务包含3步:
- 第1步:轮询read、write事件;
- 第2步:处理io任务,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理;
- 第3步:处理任务队列中的任务,runAllTasks。
client端工作原理

NettyClient整体架构图.png
client端启动时connect到server,建立NioSocketChannel,并注册到某个NioEventLoop的selector上。
client端只包含1个NioEventLoopGroup,每个NioEventLoop循环执行的任务包含3步:
- 第1步:轮询connect、read、write事件;
- 第2步:处理io任务,即connect、read、write事件,在NioSocketChannel连接建立、可读、可写事件发生时进行处理;
- 第3步:处理非io任务,runAllTasks。
服务端启动时创建了两个NioEventLoopGroup,一个是boss,一个是worker。实际上他们是两个独立的Reactor线程池,一个用于接收客户端的TCP连接,另一个用于处理Io相关的读写操作,或者执行系统/定时任务的task。
简单版


boss线程池作用:
(1)接收客户端的连接,初始化Channel参数
(2)将链路状态变更时间通知给ChannelPipeline
worker线程池作用:
(1)异步读取通信对端的数据报,发送读事件到ChannelPipeline
(2)异步发送消息到通信对端,调用ChannelPipeline的消息发送接口
(3)执行系统调用Task
(4)执行定时任务Task
通过配置boss和worker线程池的线程个数以及是否共享线程池等方式,netty的线程模型可以在单线程、多线程、主从线程之间切换。
为了提升性能,netty在很多地方都进行了无锁设计。比如在IO线程内部进行串行操作,避免多线程竞争造成的性能问题。表面上似乎串行化设计似乎CPU利用率不高,但是通过调整NIO线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁串行线程设计性能更优。
nettyd的NioEventLoop读取到消息之后,直接调用ChannelPipeline的fireChannelRead(Object msg),只要用户不主动切换线程,一直都是由NioEventLoop调用用户的Handler,期间不进行线程切换,这种串行化设计避免了多线程操作导致的锁竞争,性能角度看是最优的。
Netty 的三层架构设计
Netty 采用了典型的三层网络架构进行设计和开发,其逻辑架构图如下所示。

通信调度层 Reactor
它由一系列辅助类完成,包括 Reactor 线程 NioEventLoop 及其父类,NioSocketChannel / NioServerSocketChannel 及其父类,Buffer 组件,Unsafe 组件 等。该层的主要职责就是监听网络的读写和连接操作,负责将网络层的数据读取到内存缓冲区,然后触发各种网络事件,例如连接创建、连接激活、读事件、写事件等,将这些事件触发到 PipeLine 中,由 PipeLine 管理的责任链来进行后续的处理。
责任链层 Pipeline
它负责上述的各种网络事件在责任链中的有序传播,同时负责动态地编排责任链。责任链可以选择监听和处理自己关心的事件,它可以拦截处理事件,以及向前向后传播事件。不同应用的 Handler 节点 的功能也不同,通常情况下,往往会开发编解码 Hanlder 用于消息的编解码,可以将外部的协议消息转换成 内部的 POJO 对象,这样上层业务则只需要关心处理业务逻辑即可,不需要感知底层的协议差异和线程模型差异,实现了架构层面的分层隔离。
业务逻辑编排层 Service ChannelHandler
业务逻辑编排层通常有两类:一类是纯粹的业务逻辑编排,还有一类是其他的应用层协议插件,用于特定协议相关的会话和链路管理。例如,CMPP 协议,用于管理和中国移动短信系统的对接。
架构的不同层面,需要关心和处理的对象都不同,通常情况下,对于业务开发者,只需要关心责任链的拦截和业务 Handler 的编排。因为应用层协议栈往往是开发一次,到处运行,所以实际上对于业务开发者来说,只需要关心服务层的业务逻辑开发即可。各种应用协议以插件的形式提供,只有协议开发人员需要关注协议插件,对于其他业务开发人员来说,只需关心业务逻辑定制。这种分层的架构设计理念实现了 NIO 框架 各层之间的解耦,便于上层业务协议栈的开发和业务逻辑的定制。
正是由于 Netty 的分层架构设计非常合理,基于 Netty 的各种应用服务器和协议栈开发才能够如雨后春笋般得到快速发展。
参考资料
《Netty权威指南》
(22 封私信 / 21 条消息) 怎样理解阻塞非阻塞与同步异步的区别? - 知乎
Linux 下的五种 IO 模型详细介绍_Linux_脚本之家
Linux IO模式及 select、poll、epoll详解 - 人云思云 - SegmentFault 思否
(2条消息)从bio到nio到netty实现原理浅析_嘎嘎的博客-CSDN博客_netty nio
深入了解Netty【一】BIO、NIO、AIO简单介绍 - clawhub - 博客园

 浙公网安备 33010602011771号
浙公网安备 33010602011771号