数据采集作业3
数据采集与融合技术第三次作业
| 学号姓名 | Gitee仓库地址 |
|---|---|
| 102202128 林子豪 | https://github.com/zihaoyihao/-3 |
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(1)代码如下:
item.py
点击查看代码
import scrapy
class DangdangImagesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
class DangdangImagesItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
#spider.py
点击查看代码
import os
import scrapy
from dangdang_images.items import DangdangImagesItem
class DangdangSearchSpider(scrapy.Spider):
name = 'dangdang_search'
allowed_domains = ['search.dangdang.com','ddimg.cn']
start_urls = ['https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'] # 替换为实际的搜索URL
max_images = 128 # 最大图片下载数量
max_pages = 28 # 最大页数
image_count = 0 # 已下载图片数量计数
page_count = 0 # 已访问页面计数
def parse(self, response):
# 检查是否达到爬取的页数限制
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
return
# 获取所有书籍封面图片的 URL
image_urls = self.extract_image_urls(response)
for url in image_urls:
if self.image_count < self.max_images:
self.image_count += 1
item = DangdangImagesItem()
# 使用 response.urljoin 补全 URL
item['image_urls'] = [response.urljoin(url)]
print("Image URL:", item['image_urls'])
yield item
else:
return # 如果图片数量达到限制,停止爬取
# 控制页面数量并爬取下一页
self.page_count += 1
next_page = response.css("li.next a::attr(href)").get()
if next_page and self.page_count < self.max_pages:
yield response.follow(next_page, self.parse)
def extract_image_urls(self, response):
# 获取所有书籍封面图片的 URL
image_urls = response.css("img::attr(data-original)").getall()
if not image_urls:
# 有些图片URL属性可能是 `src`,尝试备用选择器
image_urls = response.css("img::attr(src)").getall()
return image_urls
import os
import scrapy
from dangdang_images.items import DangdangImagesItem
import concurrent.futures
class DangdangSearchSpider(scrapy.Spider):
name = 'dangdang_search'
allowed_domains = ['search.dangdang.com', 'ddimg.cn']
start_urls = ['https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'] # 替换为实际的搜索URL
max_images = 135 # 最大图片下载数量
max_pages = 35 # 最大页数
image_count = 0 # 已下载图片数量计数
page_count = 0 # 已访问页面计数
def parse(self, response):
# 检查是否达到爬取的页数限制
if self.page_count >= self.max_pages or self.image_count >= self.max_images:
return
# 获取所有书籍封面图片的 URL
image_urls = response.css("img::attr(data-original)").getall()
if not image_urls:
# 有些图片URL属性可能是 `src`,尝试备用选择器
image_urls = response.css("img::attr(src)").getall()
# 使用 ThreadPoolExecutor 下载图片
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
futures = []
for url in image_urls:
if self.image_count < self.max_images:
self.image_count += 1
item = DangdangImagesItem()
# 使用 response.urljoin 补全 URL
item['image_urls'] = [response.urljoin(url)]
print("Image URL:", item['image_urls'])
futures.append(executor.submit(self.download_image, item))
else:
break # 如果图片数量达到限制,停止爬取
# 控制页面数量并爬取下一页
self.page_count += 1
next_page = response.css("li.next a::attr(href)").get()
if next_page and self.page_count < self.max_pages:
yield response.follow(next_page, self.parse)
def download_image(self, item):
# 获取图片 URL
image_url = item['image_urls'][0]
# 确定保存路径
image_name = image_url.split("/")[-1] # 从 URL 中提取图片文件名
save_path = os.path.join('./images2', image_name)
try:
# 发送 GET 请求下载图片
response = requests.get(image_url, stream=True)
response.raise_for_status() # 检查请求是否成功
# 创建目录(如果不存在)
os.makedirs(os.path.dirname(save_path), exist_ok=True)
# 保存图片到本地
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
self.logger.info(f"Image downloaded and saved to {save_path}")
except requests.exceptions.RequestException as e:
self.logger.error(f"Failed to download image from {image_url}: {e}")
pipelines.py
class DangdangImagesPipeline:
def process_item(self, item, spider):
return item
settings.py
BOT_NAME = "dangdang_images"
SPIDER_MODULES = ["dangdang_images.1"]
NEWSPIDER_MODULE = "dangdang_images.1"
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
Obey robots.txt rules
ROBOTSTXT_OBEY = False
图片存储路径
IMAGES_STORE = './images'
开启图片管道
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
并发请求数控制
CONCURRENT_REQUESTS = 4 # 可以根据需求调整
DOWNLOAD_DELAY = 2 # 设置下载延迟
LOG_LEVEL = 'DEBUG'
RETRY_TIMES = 5 # 增加重试次数
RETRY_HTTP_CODES = [500, 502, 503, 504, 408]
结果如下:
爬取的图片:


(2)作业心得:本次实验通过在实现单线程和多线程爬取的过程中,我明显感受到了多线程爬取的速度优势。通过Scrapy的异步处理能力,多线程爬取可以同时发起多个请求,显著提高了爬取效率。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
(1)代码如下:
item.py
import scrapy
class StockScraperItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
import scrapy
class StocksScraperItem(scrapy.Item):
bStockNo = scrapy.Field()
bStockName = scrapy.Field()
fLatestPrice = scrapy.Field()
fChangeRate = scrapy.Field()
fChangeAmount = scrapy.Field()
fVolume = scrapy.Field()
fTurnover = scrapy.Field()
fAmplitude = scrapy.Field()
fHighest = scrapy.Field()
fLowest = scrapy.Field()
fOpeningPrice = scrapy.Field()
fPreviousClose = scrapy.Field()
spider.py
import scrapy
import json
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
# 股票分类及接口参数
cmd = {
"沪深京A股": "f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证A股": "f3&fs=m:1+t:2,m:1+t:23",
"深证A股": "f3&fs=m:0+t:6,m:0+t:80",
"北证A股": "f3&fs=m:0+t:81+s:2048",
}
start_urls = []
def start_requests(self):
for market_code in self.cmd.values():
for page in range(1, 3): # 爬取前两页
url = f"https://98.push2.eastmoney.com/api/qt/clist/get?cb=jQuery&pn={page}&pz=20&po=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid={market_code}&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
yield scrapy.Request(url, callback=self.parse)
def parse(self, response):
# 提取JSON格式数据
data = response.text
left_data = re.search(r'^.*?(?=\()', data)
if left_data:
left_data = left_data.group()
data = re.sub(left_data + '\(', '', data)
data = re.sub('\);', '', data)
try:
stock_data = json.loads(data)
except json.JSONDecodeError as e:
self.logger.error(f"JSON Decode Error: {e}")
return # 返回以避免后续操作
self.logger.info(f"Parsed JSON Data: {json.dumps(stock_data, indent=4, ensure_ascii=False)}") # 打印解析后的数据
if 'data' in stock_data and 'diff' in stock_data['data']:
for key, stock in stock_data['data']['diff'].items(): # 遍历 diff 字典
# 在此添加调试信息,检查每个股票的数据
self.logger.debug(f"Stock Data: {stock}")
yield {
'bStockNo': stock.get("f12", "N/A"),
'bStockName': stock.get("f14", "N/A"),
'fLatestPrice': stock.get("f2", "N/A"),
'fChangeRate': stock.get("f3", "N/A"),
'fChangeAmount': stock.get("f4", "N/A"),
'fVolume': stock.get("f5", "N/A"),
'fTurnover': stock.get("f6", "N/A"),
'fAmplitude': stock.get("f7", "N/A"),
'fHighest': stock.get("f15", "N/A"),
'fLowest': stock.get("f16", "N/A"),
'fOpeningPrice': stock.get("f17", "N/A"),
'fPreviousClose': stock.get("f18", "N/A")
}
else:
self.logger.warning("No 'data' or 'diff' found in stock_data.")
else:
self.logger.warning("Left data not found in response.")
pipelines.py
class StockScraperPipeline:
def process_item(self, item, spider):
return item
import pymysql
from scrapy.exceptions import DropItem
class StockPipeline:
def init(self, host, port, user, password, db):
self.host = host
self.port = port
self.user = user
self.password = password
self.db = db
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DB'),
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.db,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
self.cursor = self.connection.cursor()
import pymysql
from itemadapter import ItemAdapter
class StocksScraperPipeline:
def open_spider(self, spider):
self.connection = pymysql.connect(
host='127.0.0.1',
port=33068,
user='root', # 替换为你的MySQL用户名
password='160127ss', # 替换为你的MySQL密码
database='spydercourse', # 数据库名
charset='utf8mb4',
use_unicode=True,
)
self.cursor = self.connection.cursor()
# 创建表格
create_table_sql = """
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(10),
bStockName VARCHAR(50),
fLatestPrice DECIMAL(10, 2),
fChangeRate DECIMAL(5, 2),
fChangeAmount DECIMAL(10, 2),
fVolume BIGINT,
fTurnover DECIMAL(10, 2),
fAmplitude DECIMAL(5, 2),
fHighest DECIMAL(10, 2),
fLowest DECIMAL(10, 2),
fOpeningPrice DECIMAL(10, 2),
fPreviousClose DECIMAL(10, 2)
);
"""
self.cursor.execute(create_table_sql)
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
print(f"Storing item: {item}") # 打印每个存储的项
try:
insert_sql = """
INSERT INTO stocks (bStockNo, bStockName, fLatestPrice, fChangeRate, fChangeAmount, fVolume, fTurnover, fAmplitude, fHighest, fLowest, fOpeningPrice, fPreviousClose)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (
item['bStockNo'],
item['bStockName'],
float(item['fLatestPrice']),
float(item['fChangeRate']),
float(item['fChangeAmount']),
int(item['fVolume']),
float(item['fTurnover']),
float(item['fAmplitude']),
float(item['fHighest']),
float(item['fLowest']),
float(item['fOpeningPrice']),
float(item['fPreviousClose']),
))
self.connection.commit()
except Exception as e:
print(f"Error storing item: {e}")
print(f"SQL: {insert_sql} | Values: {item}")
return item
middlewares.py
from scrapy import signals
useful for handling different item types with a single interface
class StockScraperSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class StockScraperDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
settings.py
BOT_NAME = 'stock_scraper'
SPIDER_MODULES = ['stock_scraper.spiders']
NEWSPIDER_MODULE = 'stock_scraper.spiders'
爬取结果:
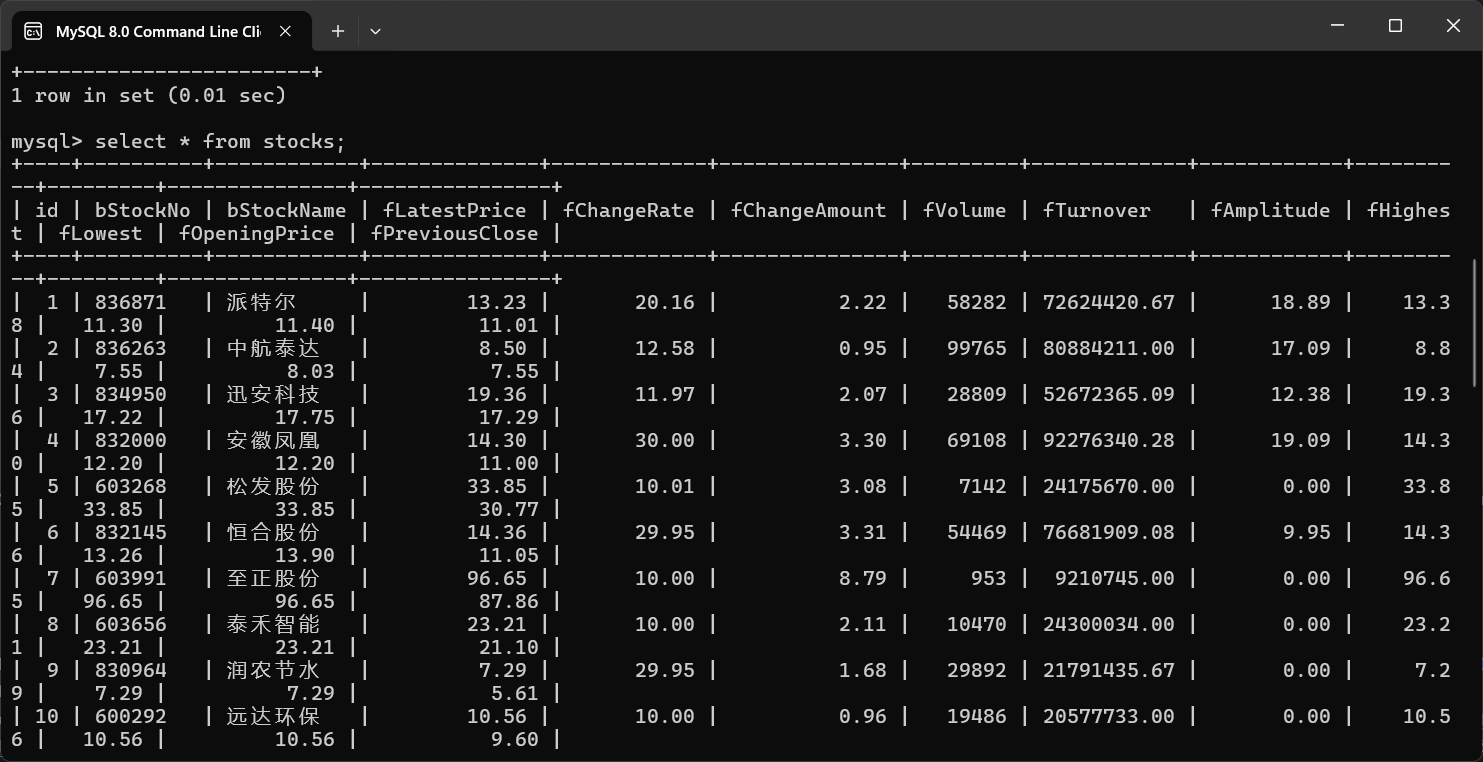

(2)作业心得:通过本次实验,我对于使用XPath解析HTML文档有了进一步的理解,在Scrapy中使用XPath选择器可以精确地定位和提取网页中的数据。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
(1)代码如下:
items.py
import scrapy
class BocExchangeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
import scrapy
class BankItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 时间
spider.py
import scrapy
from boc_exchange.items import BankItem
class ExchangeSpider(scrapy.Spider):
name = "exchange"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 解析表格数据
table = response.xpath('//table[@class="table-data"]')[0]
rows = table.xpath('.//tr')
for row in rows[1:]: # 跳过表头
item = BankItem()
item['Currency'] = row.xpath('.//td[1]/text()').get().strip()
item['TBP'] = row.xpath('.//td[2]/text()').get().strip()
item['CBP'] = row.xpath('.//td[3]/text()').get().strip()
item['TSP'] = row.xpath('.//td[4]/text()').get().strip()
item['CSP'] = row.xpath('.//td[5]/text()').get().strip()
item['Time'] = row.xpath('.//td[6]/text()').get().strip() # 根据实际情况调整
yield item
pipelines.py
class BocExchangePipeline:
def process_item(self, item, spider):
return item
import pymysql
from scrapy.exceptions import DropItem
class BankPipeline:
def init(self, mysql_host, mysql_user, mysql_password, mysql_db, mysql_port):
self.mysql_host = mysql_host
self.mysql_user = mysql_user
self.mysql_password = mysql_password
self.mysql_db = mysql_db
self.mysql_port = mysql_port
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host=crawler.settings.get('MYSQL_HOST', 'localhost'),
mysql_user=crawler.settings.get('MYSQL_USER', 'root'),
mysql_password=crawler.settings.get('MYSQL_PASSWORD', ''),
mysql_db=crawler.settings.get('MYSQL_DB', 'boc_exchange'),
mysql_port=crawler.settings.get('MYSQL_PORT', 3306),
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.mysql_host,
user=self.mysql_user,
password=self.mysql_password,
database=self.mysql_db,
port=self.mysql_port,
charset='utf8mb4',
use_unicode=True
)
self.cursor = self.connection.cursor()
create_table_query = """
CREATE TABLE IF NOT EXISTS exchange_rates (
id INT AUTO_INCREMENT PRIMARY KEY,
Currency VARCHAR(100),
TBP DECIMAL(10,2),
CBP DECIMAL(10,2),
TSP DECIMAL(10,2),
CSP DECIMAL(10,2),
Time VARCHAR(20)
)
"""
self.cursor.execute(create_table_query)
self.connection.commit()
def process_item(self, item, spider):
insert_query = """
INSERT INTO exchange_rates (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_query, (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
))
self.connection.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.connection.close()
settings.py
ITEM_PIPELINES = {
'boc_exchange.pipelines.BankPipeline': 300,
}
MySQL 配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'your_mysql_username'
MYSQL_PASSWORD = 'your_mysql_password'
MYSQL_DB = 'boc_exchange'
MYSQL_PORT = 3306
其他设置(可选)
ROBOTSTXT_OBEY = False
爬取结果:

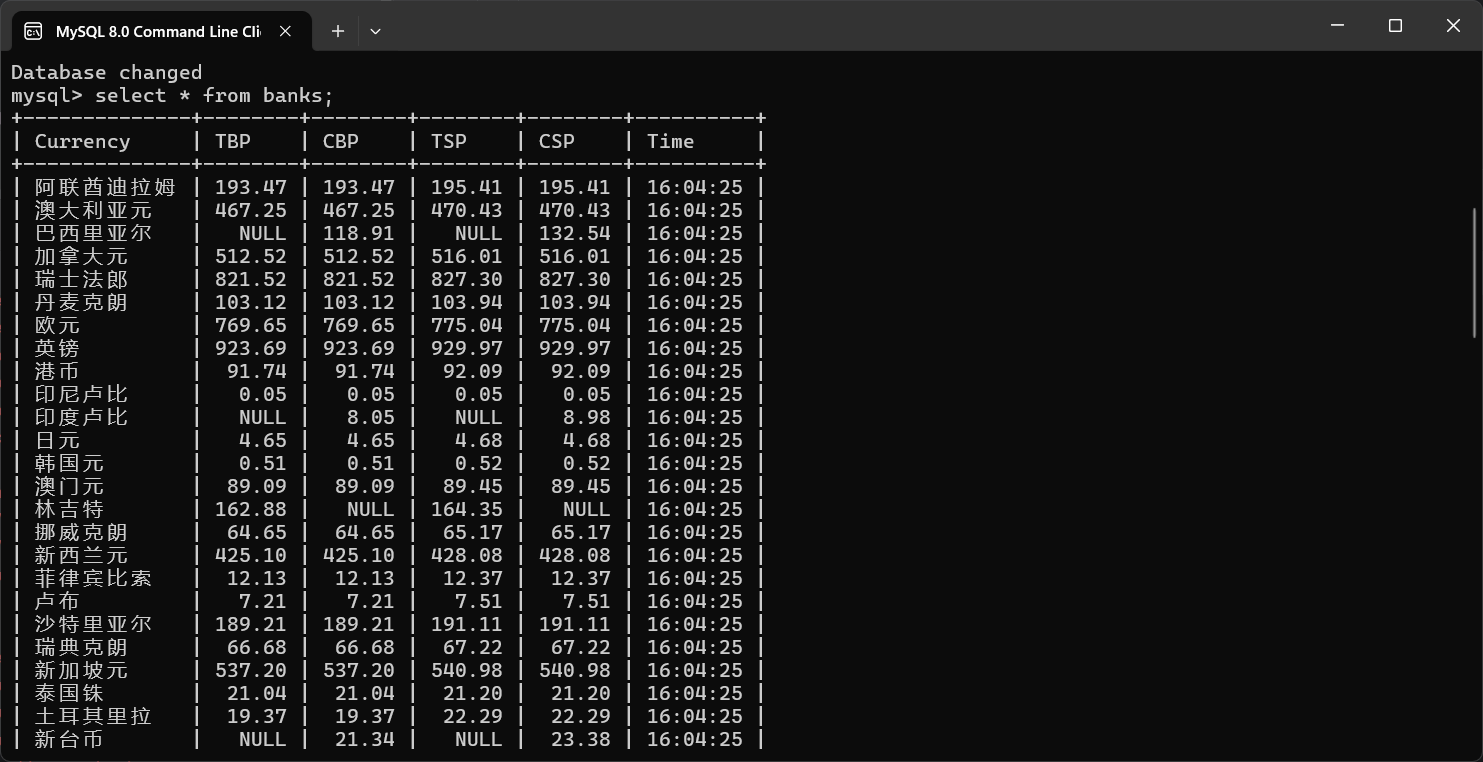
(2)作业心得:在本次项目中,我深入运用了 Scrapy 框架 和 MySQL 数据库,完成了从数据抓取、清洗到存储的完整流程。以下是我在项目实现过程中的一些关键点、遇到的问题以及从中获得的收获和体会。
- 项目实现的关键点
1.1 数据抓取与解析
Scrapy 的 Item 和 Pipeline 模块 是实现数据抓取和存储的核心工具。通过定义 BankItem,我明确了需要抓取的数据字段,并通过 parse 方法解析网页内容,将数据提取出来。
XPath 选择器 在解析网页结构时发挥了重要作用。通过分析网页的 HTML 结构,我能够准确地定位到需要的数据节点,并提取所需的信息。
1.2 数据存储
MySQL 数据库 是本次项目的存储方案。通过配置 pipelines.py,我将抓取到的数据插入到 MySQL 数据库中。在实现过程中,我学习了如何连接数据库、执行 SQL 语句以及处理事务。
数据清洗与转换 在数据存储前是必不可少的步骤。通过 ItemLoader 和自定义清洗方法,我确保了数据的完整性和一致性。 - 遇到的关键问题及解决方案
2.1 字段数据为空值
问题描述: 在抓取过程中,某些字段的数据可能为空,导致数据库插入失败或数据不完整。
解决方案:
在 parse 方法中,添加数据校验逻辑,确保每个字段都有值。
使用 ItemLoader 的 default_output_processor 方法,为空字段设置默认值。
在数据库插入时,使用 NULL 代替空字符串。
python
loader.add_xpath('Currency', './td[1]/text()', default='N/A')
2.2 MySQL 连接参数配置错误
问题描述: 初始配置时,MySQL 连接参数(如主机、端口、用户名、密码)配置错误,导致无法连接到数据库。
解决方案:
仔细检查 settings.py 中的 MySQL 配置,确保所有参数正确无误。
使用数据库管理工具(如 MySQL Workbench)测试连接参数的有效性。
在 pipelines.py 中添加错误处理逻辑,捕获连接错误并输出详细信息。
python
try:
self.connection = pymysql.connect(
host=self.mysql_host,
user=self.mysql_user,
password=self.mysql_password,
database=self.mysql_db,
port=self.mysql_port,
charset='utf8mb4',
use_unicode=True
)
except pymysql.MySQLError as e:
print(f"Error connecting to MySQL: {e}")
sys.exit(1)
2.3 数据插入时的字段类型匹配问题
问题描述: 在插入数据时,某些字段的数据类型与数据库表定义不匹配,导致插入失败。
解决方案:
在 items.py 中,明确字段的数据类型。
在数据库表定义中,使用合适的数据类型(如 DECIMAL 用于价格,VARCHAR 用于文本)。
在 pipelines.py 中,使用参数化查询,确保数据类型正确传递。
python
insert_query = """
INSERT INTO exchange_rates (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(insert_query, (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
))
3. 收获与体会
3.1 深入理解 Scrapy 框架
通过本次项目,我不仅掌握了 Scrapy 的基本用法,还深入理解了 Scrapy 的架构和工作原理。
学会了如何利用 Item 和 Pipeline 模块进行数据处理和存储。
3.2 解决实际问题的能力
在项目过程中,遇到的问题让我意识到,编程不仅仅是写代码,更重要的是分析和解决问题。
通过查阅文档、调试代码和不断尝试,我学会了如何有效地解决问题。
3.3 数据库操作技能
学会了如何连接 MySQL 数据库、执行 SQL 语句以及处理事务。
了解了数据库表设计和数据类型的匹配问题。
4. 总结
本次项目让我对 Scrapy 框架和 MySQL 数据库有了更深入的理解和实际操作经验。通过解决实际问题,我不仅提高了编程能力,还培养了耐心分析和逐步解决问题的习惯。在未来的项目中,我将继续运用这些技能,并不断学习和提升自己。
希望这些总结和反思能够帮助你更好地理解项目实现过程,并为今后的学习和工作提供参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号