


2023数据采集与融合技术实践作业一
作业①:
-
实验要求:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2......
-
完整代码:
import requests
import bs4
import pandas as pd
headers = {'User-Agent': 'Mozilla/5.0'}
def get_info(url):
wb_data = requests.get(url, headers=headers)
wb_data.encoding = wb_data.apparent_encoding
soup = bs4.BeautifulSoup(wb_data.text, 'html')
trs = soup.select('tbody>tr')
ranks = []
names = []
leixings = []
zongfens = []
for tr in trs:
ranks.append(tr.text.split('\n')[1].replace(' ', ''))
names.append(tr.text.split('\n')[2].replace(' ', ''))
leixings.append(tr.text.split('\n')[7].replace(' ', ''))
zongfens.append(tr.text.split('\n')[9].replace(' ', ''))
ranking = {'排名': ranks, '学校名称': names,'类型': leixings,'总分': zongfens}
print(pd.DataFrame(ranking))
if __name__ == '__main__':
url = f'https://www.shanghairanking.cn/rankings/bcur/2020'
get_info(url)
-
实现结果:
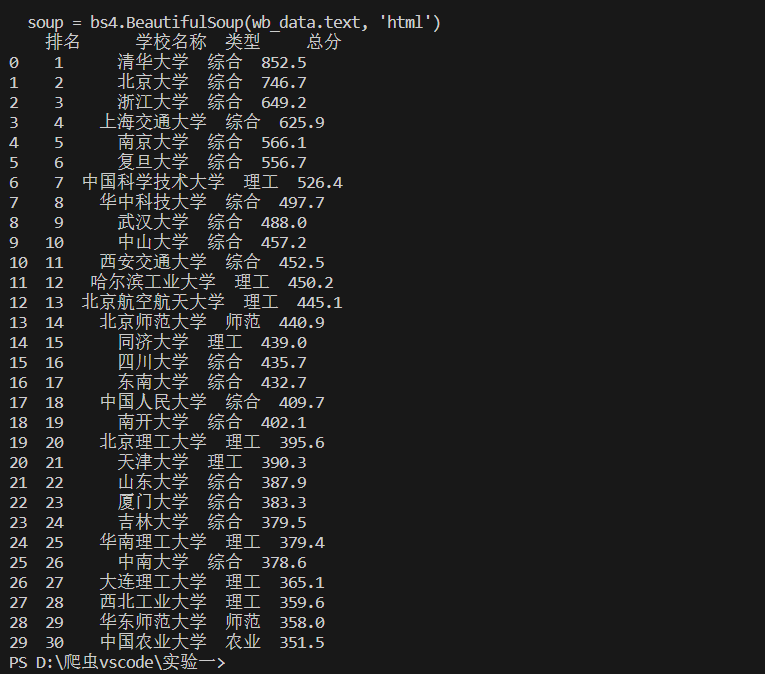
-
心得体会:
学习并且实践了requests和BeautifulSoup库方法爬取网页,对python库的认识更深刻,对爬虫的方法有更好的学习。
作业②:
-
实验要求:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
序号 价格 商品名
1 65.00 xxx
2......
-
完整代码:
import requests
import re
from bs4 import BeautifulSoup as bs
goods=[]
def get_jd_product(keyword):
url = 'https://search.jd.com/Search'
params = {
'keyword': keyword,
'enc': 'utf-8',
'wq': keyword,
}
headers = {
'cookies':"__jdv=122270672|direct|-|none|-|1695284270414; __jdc=122270672; __jda=122270672.16952842704131365791558.1695284270.1695284270.1695284270.1; mba_muid=16952842704131365791558; wlfstk_smdl=8rj8s7sjkya99loxzwcm058z4uue4ipc; __jdu=16952842704131365791558; _pst=jd_ZJKFwFYkEHnY; logintype=wx; unick=jd_ZJKFwFYkEHnY; pin=jd_ZJKFwFYkEHnY; npin=jd_ZJKFwFYkEHnY; thor=06DCA42AA099C9037B3035F8F3E340FC27A9EB22973AECA12FDFA86FE589F233B08DF824663D55AD6CDA6965335EA0C7279697650E546600856E47A4A60FCCC4462DAEF626C634E48F3E952E46376B896CEC6EA883296DB38AB173D3BFE2A2A8C71BF19CDFCA133F673B36747179C8C8894289DFB7A604623E0083D8489F8AE982B55369D5C493A81C916F38FE776921D2DFD914A6CC51E380BC153DEF9B6797; flash=2_uX4iolMcf7h8yepIK-ndLD6ujl_lbjGaI-cI65sO1nXqgHUy3P7b8f7XVN3MKGCjcJ8hbNCBCbwyb2fV6qlO8MnN3Kotrl9A6Adatv-_itP*; _tp=TBYdxMDxRWMpO/H4Ccpg1w==; pinId=rf0AaCMZJ9S83NzewvszDQ; jsavif=1; jsavif=1; 3AB9D23F7A4B3CSS=jdd03BTX7QZMPLQIV3EEVNZR37O7G5LEYVXDEVY24SIVZHGDD4SDF6YSGQCYBDSX2SAPXDL3V3XRYUHPAGHME4SVRUH2XEIAAAAMKW3IWEBQAAAAAC6ZOPMSO75A2C4X; _gia_d=1; xapieid=jdd03BTX7QZMPLQIV3EEVNZR37O7G5LEYVXDEVY24SIVZHGDD4SDF6YSGQCYBDSX2SAPXDL3V3XRYUHPAGHME4SVRUH2XEIAAAAMKW3IWEBQAAAAAC6ZOPMSO75A2C4X; shshshfpa=754ff8be-5aeb-2ac4-e574-673c432850e2-1695284290; shshshfpx=754ff8be-5aeb-2ac4-e574-673c432850e2-1695284290; areaId=16; ipLoc-djd=16-1317-0-0; __jdb=122270672.4.16952842704131365791558|1.1695284270; shshshsID=0c28e22cb7c616b1f2cae4afa5697c5a_2_1695284335332; shshshfpb=AAhsT0raKEk_4vlrrKsTldGc8QyhQ4haVKEKQQQAAAAA; qrsc=2; 3AB9D23F7A4B3C9B=BTX7QZMPLQIV3EEVNZR37O7G5LEYVXDEVY24SIVZHGDD4SDF6YSGQCYBDSX2SAPXDL3V3XRYUHPAGHME4SVRUH2XEI",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # 检查请求是否成功
print(response.text)
soup = bs(response.text, 'lxml')
tags = soup.find('div', attrs={"id": "J_goodsList"})
tags = tags.find_all('li', attrs={'class': "gl-item"})
try:
global goods
for t in tags:
name = t.find('div',attrs = {'class': "p-name p-name-type-2"}).find('em').text.replace('\n',' ')
price = float(t.find('div',attrs = {'class': 'p-price'}).find('i').text)
# print(num_count,'-->',name,price)
goods.append([name,price])
except Exception as e:
print(e)
def get_jd_product2(keyword):
url = 'https://search.jd.com/Search?keyword='+str(keyword)+'&enc=utf-8'+ '&page=2'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
soup = bs(response.text, 'lxml')
tags = soup.find('div', attrs={"id": "J_goodsList"})
tags = tags.find_all('li', attrs={'class': "gl-item"})
try:
global goods
for t in tags:
name = t.find('div',attrs = {'class': "p-name p-name-type-2"}).find('em').text.replace('\n',' ')
price = float(t.find('div',attrs = {'class': 'p-price'}).find('i').text)
# print(num_count,'-->',name,price)
goods.append([name,price])
except Exception as e:
print(e)
# 测试
keyword = '书包'
get_jd_product(keyword)
get_jd_product2(keyword)
goods = sorted(goods,key=lambda a:a[1])
count = 1
for item in goods:
print(count,'>>',item[0],' ',item[1],'¥')
count+= 1
-
实现结果:
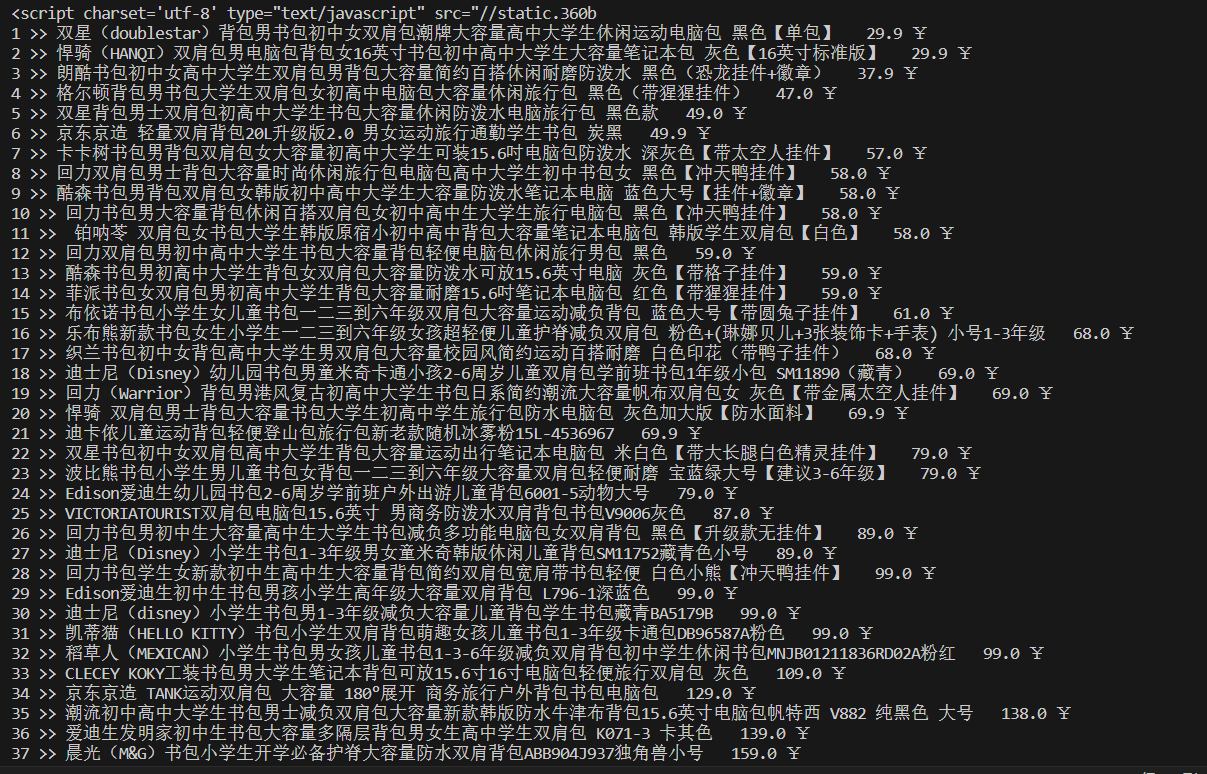
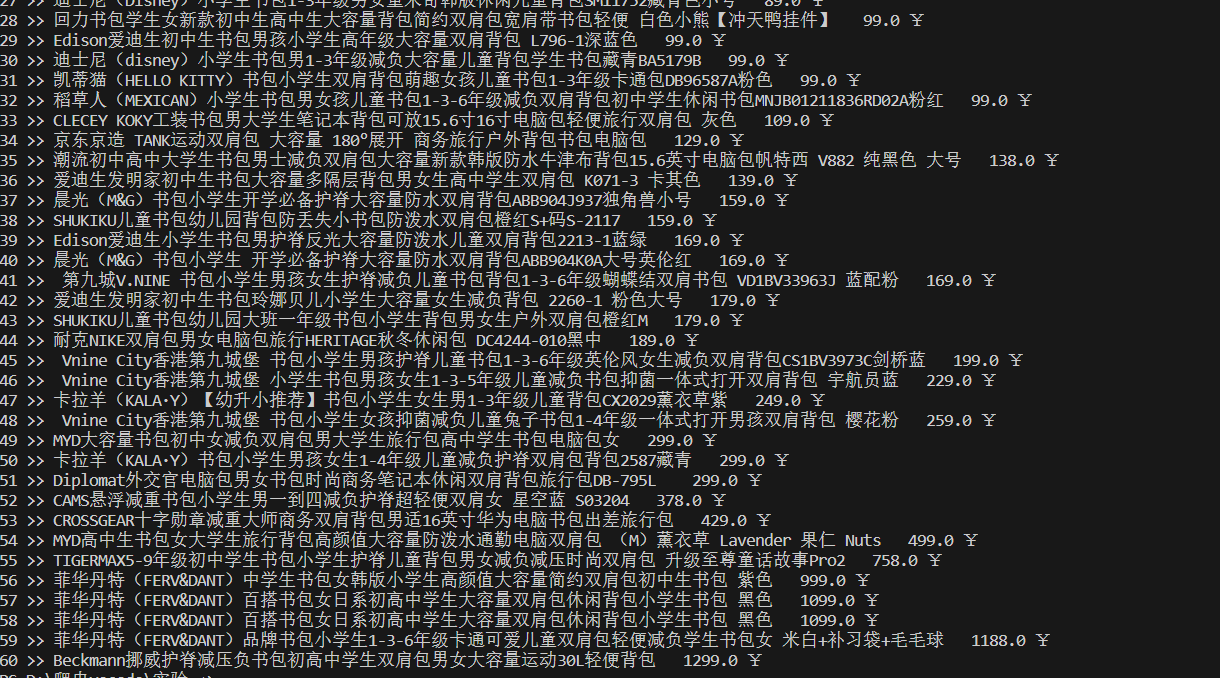
-
心得体会:
学习使用requests和re库方法设计,并自己实践京东爬取商品信息,原来爬淘宝爬太多次号被封了,但是学会了很多方法。
作业③:
-
实验要求:
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
-
完整代码:
#_*_coding:utf-8_*_
import requests
import re
import os
count = 0
class GetImage(object):
def __init__(self,url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36'
}
self.dir_path = os.path.dirname(os.path.abspath(__file__))
self.path = self.dir_path+'/imgs'
isExists = os.path.exists(self.dir_path+'/imgs')
# 创建目录
if not isExists:
os.makedirs(self.path)
def download(self,url):
try:
res = requests.get(url,headers=self.headers)
return res
except Exception as E:
print(url+'下载失败,原因:'+E)
def parse(self,res):
content = res.content.decode()
# print(content)
img_list = re.findall(r'<imgs.*?src="(.*?)"',content,re.S)
img_list = ['https://xcb.fzu.edu.cn'+url for url in img_list]
return img_list
def save(self,res_img,file_name):
if res_img:
# 定义文件名和目录
global count
filename = 'FB5989AAE9881E0EDB3B42F01F7_908A13A6_8426D'+str(count)+'.jpeg'
count+=1
path = 'D:/爬虫vscode/实验一/imgs'
# 将文件名中的非法字符替换为下划线
new_filename = filename.replace('?', '_')
# # 拼接完整的文件路径
file_path = os.path.join(path, new_filename)
with open(file_path, 'wb') as f:
f.write(res_img.content)
print(url+'下载成功')
def run(self):
# 下载
res = self.download(self.url)
# 解析
url_list = self.parse(res)
# 下载图片
for url in url_list:
res_img = self.download(url)
name = url.strip().split('/').pop()
file_name = self.path+'/'+name
# 保存
self.save(res_img,file_name)
if __name__ == '__main__':
url_list = ['https://xcb.fzu.edu.cn/info/1071/4481.htm']
for url in url_list:
text = GetImage(url)
text.run()
-
实现结果:
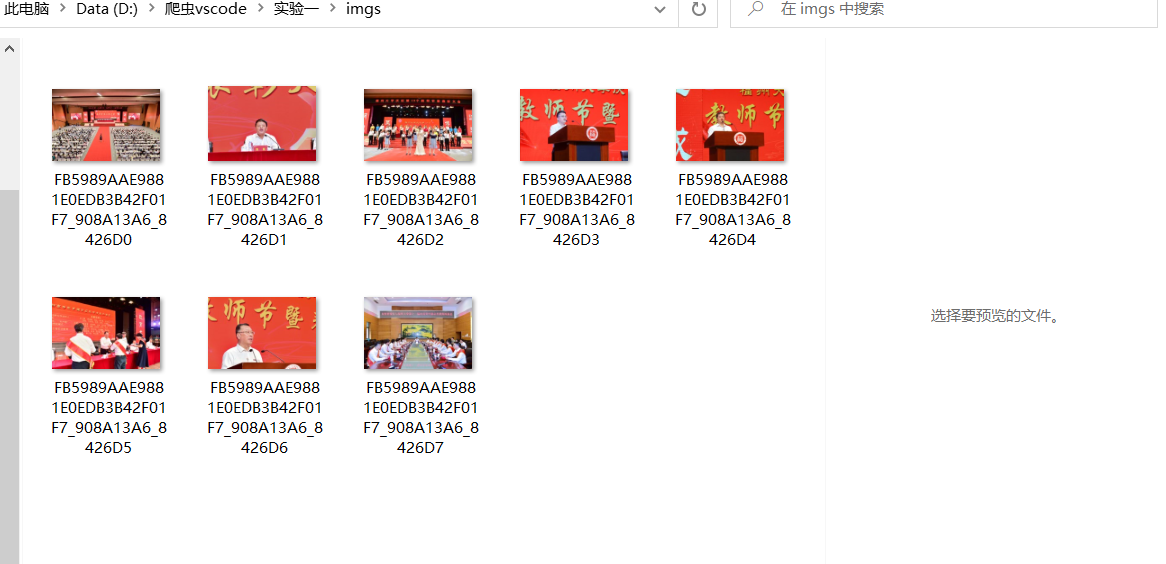
-
心得体会:
通过本次学习,学会了如何将网页上的图片爬到电脑文件夹中,加深了我对爬虫的学习。
