并发编程笔记
一、并发编程知识准备
(1)并发:多种线程操作相同的资源,保证线程安全,合理使用资源
(2)高并发:服务能同时处理很多请求,提高程序性能
(3)知识技能
- 总体架构:Spring Boot、Maven、JDK8、MySql
- 基础组件:Mybatis、Guava、Lombok、Redis、Kafka
- 高级组建:Joda-Time、Atomic、JUC、AQS、ThreadLocal、RateLimiter、Hystrix、ThreadPool、ShardBatis、curator、elastic-job...
二、并发基础
1、CPU多级缓存——缓存一致性
2、CPU多级缓存——重排序
3、Java内存模型
4、并发的优势与风险
三、并发模拟
1、Postman:HTTP请求工具
2、AB(Apache Bench):测试网站性能
Concurrency Level: 50
Time taken for tests: 0.173 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 136000 bytes
HTML transferred: 4000 bytes
Requests per second: 5764.98 [#/sec] (mean)
Time per request: 8.673 [ms] (mean)
Time per request: 0.173 [ms] (mean, across all concurrent requests)
Transfer rate: 765.66 [Kbytes/sec] received
3、Jmeter:压测工具
4、代码:Semaphore、CountDownLatch等
四、线程安全性
1、线程安全性
定义:当多个线程访问某个类时,不管运行时环境采用何种调度方式或者进程如何交替执行,并且在 主调代码中不需要任何额外的同步或协同,这个类都能表现出正确的行为,那么称这个类是线程安全的。
2、线程安全性的表现方式
(1)原子性:提供了互斥访问,同一时刻只能有一个线程来对它进行操作
(2)可见性:一个线程对主内存的修改可以即使被其他线程观察到
(3)有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序的存在,该观察结果一般杂乱无序
3、原子性:Atomic包
(1)AtomicXXX:CAS、Unsafe.compareAndSwapInt
// UnSafe类中的方法
@HotSpotIntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset); // 获取对象o中的底层值
// offset == v 修改成功,反之循环继续判断
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}
@HotSpotIntrinsicCandidate
public final boolean weakCompareAndSetIntRelease(Object o, long offset,int expected,int x) {
return compareAndSetInt(o, offset, expected, x); //CAS
}
(2)AtomicLong、LongAdder
- Long不是原子的,会分成两部分更新。
- LongAdder:热点数据分离,即AtmoicLong中的数据分离为数组,线程访问使用hash算法命中某个数字进行计数,最终结果为数组求和。
- 应用:
- 竞争压力低、序列号:AtmoicLong
- 竞争压力大:LongAdder
(3)AtomicBoolean:VarHandle实现
- 原子操作类型:
- Unsafe:JVM内置函数API,损害安全性和可移植性
- 原子性的FieldUpdaters,运用了反射
- 使用原有原子类AtomicInteger,内存开销大
- VarHandle:
- 安全、高可用、高性能
- 更细粒度的控制内存排序
- 可与任何字段、数组元素或静态变量关联
- 创建VarHandle
public class VarhandleFoo {
volatile int x;
private Point[] points;
private static final VarHandle QA;//for arrays
private static final VarHandle X;//for Variables
static {
try {
QA = MethodHandles.arrayElementVarHandle(Point[].class);
X = MethodHandles.lookup(). // Lockup类
findVarHandle(Point.class, "x", int.class);
//X = MethodHandles.lookup().in(Point.class).findVarHandle(Point.class, "x", int.class);
} catch (ReflectiveOperationException e) {
throw new Error(e);
}
}
class Point {
// ...
}
}
- 使用VarHandle
//plain read
int x = (int) X.get(this);
Point p = (Point) QA.get(points,10);
//plain write
X.set(this,1);
QA.set(points,10,new Point());
//CAS
X.compareAndSet(this,0,1);
QA.compareAndSet(points,10,p,new Point());
//Numeric Atomic Update
X.getAndAdd(this,10);
- 内存排序影响
- 对于引用类型和32位以内的原始类型,read和write(get、set)都可以保证原子性,并且对于执行线程以外的线程不施加可观察的排序约束。
- 不透明属性:访问相同变量时,不透明操作按原子顺序排列。
- Acquire模式的读取总是在与它对应的Release模式的写入之后。
- 所有Volatile变量的操作相互之间都是有序的。
- 应用:控制只有一个线程执行
(4)AtomicReference、AtomicReferenceFieldUpdater
(5)AtomicStampReference:CAS的ABA问题
(6)AtomicLongArray:原子索引中的值
(7)AtomicIntegerFieldUpdater:让普通变量(int)支持原子操作
- 只支持可见的变量
- 变量需要声明为volatile
- 不支持静态变量
(8)StampLock:读写锁改进,乐观读
- 适用于读操作很多,写操作很少的场景(优先满足写操作)
- 用于防止写操作饥饿
- 也可退化为读写锁
4、UnSafe类
(1)概述
- 根据偏移量设置值
- park()
- 底层的CAS操作
- 内存屏障
(2)主要接口
//获得给定对象偏移量上的int值
public native int getInt(Object o,long offset);
//设置给定对象偏移量上的int值
public native void putInt(Object o,long offset, int x);
//获得字段在对象中的偏移量
public native long objectFieldOffset(Field f);
public native long staticFieldOffset(Field f);
//设置给定对象的int值,使用volatile语义
public native void putIntVolatile(Object o,long offset,int x);
//获得给定对象对象的int值,使用volatile语义
public native int getIntVolatile(Object o,long offset);
//和putIntVolatile()一样,但是它要求被操作字段就是volatile类型的
public native void putOrderedInt(Object o,long offset,int x);
// cas设值
public final boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
// 内存屏障
public void fullFence();
public void loadFence();
public void storeFence();
public void loadLoadFence();
public void storeStoreFence();
//------------------数组操作---------------------------------
//获取给定数组的第一个元素的偏移地址
public native int arrayBaseOffset(Class<?> arrayClass);
//获取给定数组的元素增量地址,也就是说每个元素的占位数
public native int arrayIndexScale(Class<?> arrayClass);
//--------------------锁指令(synchronized)-------------------------------
//对象加锁
public native void monitorEnter(Object o);
//对象解锁
public native void monitorExit(Object o);
public native boolean tryMonitorEnter(Object o);
//解除给定线程的阻塞
public native void unpark(Object thread);
//阻塞当前线程
public native void park(boolean isAbsolute, long time);
//------------------内存操作----------------------
// 在本地内存分配一块指定大小的新内存,内存的内容未初始化;它们通常被当做垃圾回收。
public native long allocateMemory(long bytes);
//重新分配给定内存地址的本地内存
public native long reallocateMemory(long address, long bytes);
//将给定内存块中的所有字节设置为固定值(通常是0)
public native void setMemory(Object o, long offset, long bytes, byte value);
//复制一块内存
public native void copyMemory(Object srcBase, long srcOffset,
Object destBase, long destOffset,
long bytes);
//释放给定地址的内存
public native void freeMemory(long address);
5、原子性:锁
(1)概述
- synchronized:依赖JVM
- Lock:依赖特殊的CPU指令,代码实现,ReentrantLock
(2)synchronized
- 修饰代码块:作用于调用的对象
- 修饰方法:作用于调用的对象
- 修饰静态变量:作用于所有调用对象
- 修饰类:作用于所有调用对象
(3)原子性对比
- synchronized:不可中断,适合竞争不激烈,可读性好
- Lock:可中断锁,多样化同步,竞争激烈时能维持常态
- Atomic:竞争激烈时维持常态,性能比Lock好;但只能同步一个值
6、可见性
(1)共享变量不可见在线程间不可见原因
- 线程交叉执行
- 重排序结合线程交叉执行
- 共享变量更新后的值没有从工作内存刷新到主内存中(CPU缓存和内存)
(2)synchronized的可见性
- 线程解锁时,把共享变量的最新值刷新到主内存
- 线程解锁时,清空工作内存中共享变量的值,即共享变量需要从主内存中重新读取最新值
(3)volatile的可见性
- 通过加入内存屏障和禁止重排序来实现
- volatile变量的写后面加入store屏障,将本地内存的共享变量值刷新到主存
- volatile变量的读前面加入load屏障,从主存中读取共享变量
(4)volatile应用
- 作为状态标识量
volatile boolean inited = false;
// 线程1
context = loadContext();
inited = true;
// 线程2
while(!inited)
sleep();
doSomethingWithConfig(context);
- double checked:保证单例等
(5)可见性的原因
- CPU缓存的存在
- 编译器的优化

- 重排序导致看到的值不一致
6、有序性
(1)java内存模型中,允许编译器和处理器对指令进行重排序,但重排序不影响单线程程序的执行,却可能影响到多线程的正确性
(2)volatile、synchronized、Lock
(3)happens-before原则
- 程序次序原则:程序次序前先于后
- 锁定规则:unlock先于lock操作
- volatile规则:写先于读操作
- 传递规则:A先于B,B先于C,则A先于C
- 线程启动规则:start 先于 run
- 线程中断规则:interrupt先于线程中断发生
- 线程终结规则:线程中所有操作先于线程终止,Thread.join方法结束、Thread.isAlive返回值检测线程终止与否
- 对象终结规则:对象的初始化完成先于完成它的finalize方法的开始
(4)一条指令的执行可以分为多个步骤:
- 取址 IF
- 译码和取寄存器操作数 ID
- 执行或者有效地址计算 EX
- 存储器访问 MEM
- 写回寄存器 WB
(5)重排序的原因
- 重排序不影响单线程的执行结果,消除“气泡(停顿时间)”,使得流水线更加顺畅

五、安全发布对象
1、发布对象
- 发布对象:使一个对象能被当前范围之外的代码所使用
- 对象逸出:错误的发布,对象未构建完成时,被其他线程所见
2、安全发布对象
- 在static函数中初始化一个对象引用
- 将对象的引用保存到volatile类型域或者AtomicReference对象中
- 将对象的引用保存到某个正确构造函数的final类型域中
- 将对象的引用保存到由锁保护的域中
六、不可变对象
1、不可变对象的条件:参考String类
- 对象创建后状态不能修改
- 对象所有域都是final类型
- 对象是正确创建的(没有发生逸出)
2、 final关键字:类、方法、变量
- 类:不能被继承,方法隐式变为final
- 方法:private方法隐式变为final方法
- 锁定方法不能被继承类修改
- 效率
- 变量:基本数据类型变量(无法修改值)、引用类型变量(无法指向另外一个对象)
3、不可变方式
- final
- Collections.unmodifiableXXX:Collection List Set Map
- Guava:ImutableXXX Collection List Set Map
4、线程封闭
- Ad-hoc线程封闭:程序控制实现,不推荐
- ThreadLocal:推荐
- 堆栈封闭:局部变量,无并发问题
6、常见线程不安全
- StringBuilder -> StringBuffer
- DateFormat -> joda-time包中的DateTimeFormatter
- ArrayList HashSet HashMap等Collections
- 先检查在执行:if(condition(a)){ handler(a); } -> CAS方法或者加锁
7、同步容器
- ArrayList -> Vector,Stack
- HashMap -> HashTable
- Collections.synchronizedXXX(List Set Map)
注:集合遍历(foreach、iterator)的时候有对集合进行增删操作将导致ConcurrentModificationException.需要进行更新,可以先打标记,遍历完再进行操作。
8、并发容器——JUC
- ArrayList -> CopyOnWriteArrayList
- 拷贝需要消耗内存,可能发生GC
- 不能用于实时性的场景,只满足最终一致性
- 只适合读多写少的场景
- 读写分离,使用时另外开辟空间,进行并发保护
- HashSet、TreeSet -> CopyOnWriteArraySet、ConcurrentSkipListSet
- CopyOnWriteArraySet底层使用CopyOnWriteArrayList
- ConcurrentSkipListSet基于ConcurrentSkipListMap,只有单次操作时原子的,但批量操作(containAll)不是原子的。add调用了putIfAbsent方法
- HashMap、TreeMap -> ConcurrentHashMap、ConcurrentSkipListMap
- ConcurrentSkipListMap的Key值有序,存取时间与并发线程数无关
- 并发低时ConcurrentHashMap效率更高,并发高时ConcurrentSkipListMap效率更高。
9、安全共享对象策略——总结
- 线程限制对象:由线程独占,并且只能被占用它的线程修改
- 共享只读对象:再没有额外同步的情况下,可被多个线程并发访问,但任何线程都不能修改它
- 线程安全对象:在内部通过同步机制来保证线程安全,所以其他线程无需额外的同步就可以通过公共接口任意访问它
- 被守护对象:只能通过获取特定的锁来访问
七、JUC之AQS
1、AbstractQueuedSynchronizer——AQS
- Sync Queue,底层为双向队列;Condition Queue,单项链表,等待某个条件的队列
- 使用Node实现FIFO队列,用于构建锁或者其他同步装置的基础框架
- 利用int类型表示状态
- 使用方法是继承,模板方法模式
- 子类通过继承并通过实现它的方法管理其状态{acquire和release}的方法操纵状态
- 可以同时实现排他锁和共享锁模式(独占和共享)
2、AQS同步组件
- CountDownLatch
- Semaphore
- CyclicBarrier
- ReentrantLock
- Condition
- FutureTask
3、CountDownLatch
- 计数器不能被重置
- 一个线程等待计数器变为0(某个条件)
- 父任务等待子任务执行完成才去做汇总操作
4、Semaphore
- 有限访问的资源,限制并发访问的数目
- 共享锁
- 一次可以获取多个许可(acquire(3)),一次也可以释放多个许可(realease(3))
- 尝试获取许可(可加等待时间),获取不到可以丢弃掉
5、CyclicBarrier
- 多个线程等待,等待某个条件达成后,线程才继续执行
- 多线程计算,最后计算结果执行汇总(fork -> join)
- 可重置,各个线程相互等待
- 可用于更复杂的场景
6、ReentrantLock与锁
-
ReetrantLock和Synchronized区别
- 可重入性
- 锁的实现
- jvm实现
- jdk实现
- 性能区别
- 偏向锁、轻量级锁、自旋锁、重量级锁
- 用户态进行解决,避免进入内核态,采用cas技术
- 功能
- 便利性:自动加锁和释放
- 细粒度:ReetrantLock优于synchronized
-
ReetrantLock特有功能
- 可指定公平锁和非公平锁,公平为先等待先获取锁
- Condition类,分组唤醒需要唤醒得线程
- 中断等待锁得机制,lock.lockInterruptibly()
- 自旋cas,避免进入内核态
-
synchronized能够在对象头标识对象所处状态,便于调试
-
ReentrantReadWriteLock
- 悲观读取,只有没有读操作时,才可以写
- 适用于写多读少的情况
-
StampedLock
- 乐观读,乐观认为读操作时有写操作存在,如果读完后发现有写操作,再进行处理。
- 适用于读多写少的情况
-
Condition
- condition.await():释放锁并等待信号,进入condition队列;当获取到信号并被唤醒后将重新获取到锁
- condition.signal():发送信号,获取condition队列的值放入sync队列中,此时并未释放锁
7、并发相关概念
- PV(page view):网站的总访问量,页面浏览量或点击量,用户没刷新一次就会被记录一次
- UV(unique visitor):网站的访客量,一般时0~24的相同的IP地址只记录一次
- QPS(query per second):每秒服务器支持的查询量
- RT(response time):请求的响应时间
- 峰值QPS = (总PV * 80%)/ (606024*20%)
- 机器数 = 总的峰值QPS / 压测得出的单机极限qps
八、JUC组件拓展
1、FutureTask
- Callable与Runnable接口比较
- Callable有返回值且能抛出异常(jdk1.5)
- Runnable没有返回值
- Future接口
- 异步编程
- 获取其他线程的返回值
- Future.get():当其他线程未执行完将阻塞直到线程执行完,并获取返回值
- 可以取消任务
- FutureTask类:继承Runnable和Future接口
- 可以作为Runnable传入线程类执行
- 也可以作为Future传入线程类并获取返回值
- 用于某个线程执行需要时间且有返回值,但当前线程不需要等待,可以先执行其他业务,直到需要该返回值才阻塞去获取返回值。
2、Fork/Join框架(Map-Reduce思想)
-
任务窃取:线程1执行完自己的任务,则去窃取线程2的任务,为了防止重复执行任务,则从其他线程的尾部进行窃取任务
-
缺点:
- 任务少时,消耗等待时间
- 创建过多的线程和双端任务队列,浪费空间资源
-
特点:
- 任务只能使用fork和join进行同步
- 任务不能执行IO操作
- 任务不能抛出异常
-
ForkJoinPool:执行类,执行ForkJoinTask
-
ForkJoinTask:任务类,需要实现compute方法
3、BlockingQueue
- 阻塞情况:
- 入队时,发现队列已满时
- 出队时,发现队列已空时
- 消费者生产者模型
- 多种场景:
| - | Throw Exception | Special Value | Blocks | Time Out |
|---|---|---|---|---|
| Insert | add(o) | offer(o) | put(o) | offer(o,timeout,timeunit) |
| Remove | remove(o) | poll() | take() | poll(timeout,timeunit) |
| Examine | element() | peek() |
- 实现类
- ArrayBlockingQueue:有界,FIFO
- DelayQueue:元素需要实现Delayed接口,继承了Comparable接口,即元素需要排序获取过期时间(内部实现:PriorityQueue和ReentrantLock)
- LinkedBlockingQueue:可有界可无界(最大为Integer.MAX_VALUE),FIFO
- PriorityBlockingQueue:无边界队列,元素需要实现Comparable接口
- SynchronousQueue:同步队列,只能存放一个元素,把并发执行变为同步执行
- ArrayDeque(数组双端队列)
- LinkedBlockingDeque(基于链表的FIFO双端阻塞队列)
4 并发设计模式
(1)Future模式
-
概述
- 异步
- 类似商品订单
- 用户无需一直等待请求的结果,用户可以继续浏览或者操作其他内容
-
实现图
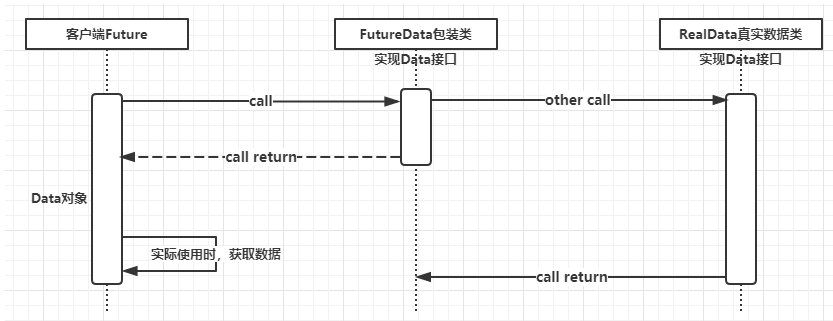
- 代码
public interface Data {
String getRequest();
}
public class FutureClient {
public Data request(String queryStr) {
FutureData data = new FutureData();
new Thread(()->{
RealData realData = new RealData(queryStr);
data.setRealData(realData);
}).start();
return data;
}
}
public class FutureData implements Data {
private RealData realData;
private volatile boolean isComplete = false;
@Override
public synchronized String getRequest() {
while (!isComplete) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return realData.getRequest();
}
public synchronized void setRealData(RealData realData) {
if (isComplete) return;
this.realData = realData;
isComplete = true;
notify();
}
}
public class RealData implements Data {
private String result;
public RealData(String queryStr) {
System.out.println("根据" + queryStr + "进行查询,这是一个耗时间5s的操作");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
result = "查询结果";
}
@Override
public String getRequest() {
return result;
}
}
public class Main {
public static void main(String[] args) {
FutureClient fc = new FutureClient();
Data data = fc.request("请求参数");
System.out.println("请求发送成功");
System.out.println("继续执行其他事情");
// 这个方法会阻塞等待结果执行完成
String result = data.getRequest();
System.out.println(result);
}
}
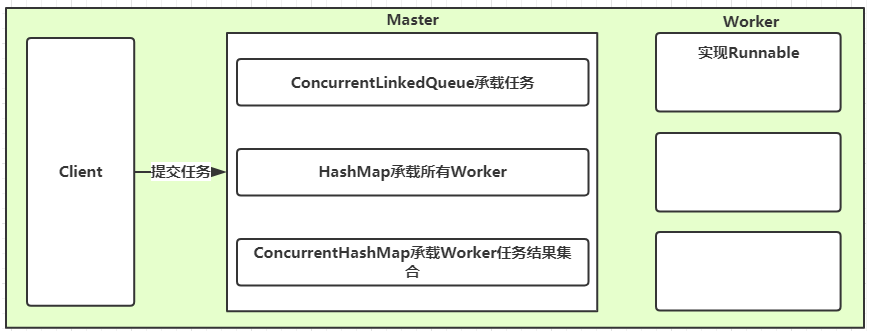
(2)Master-Slave模式
-
概述
- 常用的并行计算模式
- Master:负责接受和分配任务
- Worker:负责处理子任务
- Worker子进程处理完成后,将结果返回给Master,Master进行归纳和总结。
-
实现图
- 代码
public class Master {
// 1.承载任务的集合
private ConcurrentLinkedQueue<Task> taskQueue = new ConcurrentLinkedQueue<>();
// 2.承载所有Worker对象
private Map<String, Thread> workers = new HashMap<>();
// 3. 使用容器承载所有Worker执行任务的结果结合
private Map<String, Object> resultMap = new ConcurrentHashMap<>();
public Master(Worker worker, int workerCount) {
worker.setResultMap(resultMap);
worker.setTaskQueue(taskQueue);
for (int i = 0; i < workerCount; i++) {
// key=Worker名字 value=线程执行对象
workers.put("worker" + i, new Thread(worker));
}
}
public void submit(Task task) {
this.taskQueue.add(task);
}
public void execute() {
workers.values().forEach(Thread::start);
}
public boolean isComplete() {
Collection<Thread> threads = workers.values();
for (Thread thread : threads) {
if (thread.getState() != Thread.State.TERMINATED) return false;
}
return true;
}
public long getResult() {
return resultMap.values().stream().mapToInt(obj->(Integer)obj).reduce((sum, val) -> sum+val).getAsInt();
}
}
@Data
public class Task {
private int id;
private String name;
private int price;
public Task(int id, String name, int price) {
this.id = id;
this.name = name;
this.price = price;
}
}
@Data
public class Worker implements Runnable {
private ConcurrentLinkedQueue<Task> taskQueue;
private Map<String, Object> resultMap;
@Override
public void run() {
while (true) {
Task task = this.taskQueue.poll();
if (task == null) break;
Object obj = handle(task);
// key=id value=结果
resultMap.put(String.valueOf(task.getId()), obj);
}
}
// 可以作为抽象方法提取出去
private Object handle(Task task) {
Object object = null;
// 业务耗时
try {
Thread.sleep(500);
object = task.getPrice();
} catch (InterruptedException e) {
e.printStackTrace();
}
return object;
}
}
public class Main {
public static void main(String[] args) {
Master master = new Master(new Worker(), 50);
Random r = new Random();
for (int i = 1; i <= 100; i++) {
master.submit(new Task(i, "任务" + i, r.nextInt(1000)));
}
master.execute();
long start = System.currentTimeMillis();
while (true) {
if (master.isComplete()) {
long result = master.getResult();
System.out.println(result);
System.out.println("执行时间:" + (System.currentTimeMillis() - start));
break;
}
}
}
}
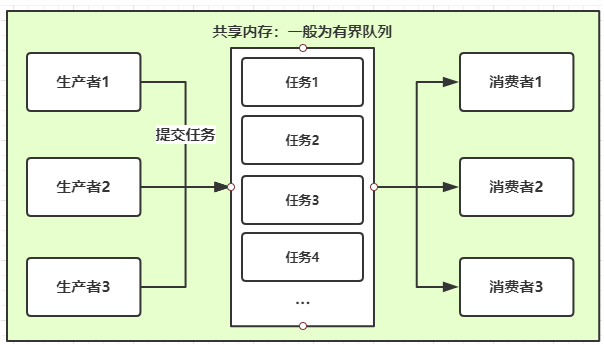
(3)生产者与消费者实现
-
概述
- 经典的多线程模式
- 生产者线程:负责提交用户处理
- 消费者线程:负责具体处理生产者提交的任务
- 生产者和消费者通过共享缓冲区进行通信
-
实现图
- 代码
class ProducerThread implements Runnable {
private BlockingQueue<String> blockingQueue;
private AtomicInteger count = new AtomicInteger();
private volatile boolean FLAG = true;
public ProducerThread(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "生产者开始启动....");
while (FLAG) {
String data = count.incrementAndGet() + "";
try {
boolean offer = blockingQueue.offer(data, 2, TimeUnit.SECONDS);
if (offer) {
System.out.println(Thread.currentThread().getName() + ",生产队列" + data + "成功..");
} else {
System.out.println(Thread.currentThread().getName() + ",生产队列" + data + "失败..");
}
Thread.sleep(1000);
} catch (Exception e) {
}
}
System.out.println(Thread.currentThread().getName() + ",生产者线程停止...");
}
public void stop() {
this.FLAG = false;
}
}
class ConsumerThread implements Runnable {
private volatile boolean FLAG = true;
private BlockingQueue<String> blockingQueue;
public ConsumerThread(BlockingQueue<String> blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "消费者开始启动....");
while (FLAG) {
try {
String data = blockingQueue.poll(2, TimeUnit.SECONDS);
if (data == null || data == "") {
FLAG = false;
System.out.println("消费者超过2秒时间未获取到消息.");
return;
}
System.out.println("消费者获取到队列信息成功,data:" + data);
} catch (Exception e) {
// TODO: handle exception
}
}
}
}
public class Main {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new LinkedBlockingQueue<>(3);
ProducerThread producerThread = new ProducerThread(blockingQueue);
ConsumerThread consumerThread = new ConsumerThread(blockingQueue);
Thread t1 = new Thread(producerThread);
Thread t2 = new Thread(consumerThread);
t1.start();
t2.start();
// 10秒后 停止线程..
// 可以使用CountDownLatch来等待子线程结束
try {
Thread.sleep(10*1000);
producerThread.stop();
} catch (Exception e) {
// TODO: handle exception
}
}
}
九、线程池
1、new Thread弊端
- 每次new Thread新建对象,性能查
- 线程缺乏统一管理,可能无限制新建线程,相互竞争,可能导致死机或者OOM
- 功能少,没有定期执行、线程中断
2、线程池好处
- 降低资源消耗:重用线程,减少对象创建和消亡的开销
- 提高线程的可管理性:能有效控制最大并发线程数,提高系统资源利用率,
- 提高响应速度:避免了过多资源竞争,避免阻塞
- 提供强大的功能:提供定时执行、定期执行、单线程、并发控制等功能
3、ThreadPoolExecutor
-
参数:
- corePoolSize:核心线程数量;
- maximumPoolSize:最大线程数;当workQueue有界才有效。
- workQueue:阻塞队列,存储等待执行的任务
- keepAliveTime:当线程数大于corePoolSize小于maximumPoolSize的线程,不会直接从线程池移除,而是等keepAliveTime还没被使用才移除。
- unit:keepAliveTime的时间单位
- threadFactory:线程工厂,创建线程
- rejectHandler:拒绝处理的策略
- 抛出异常:AbortPolicy
- 用调用者所在线程执行任务:CallRunsPolicy
- 丢弃队列中最靠前的任务,并执行当前任务:DiscardOldestPolicy
- 直接丢弃:DiscardPolicy
- 自定义拒绝策略
-
执行过程:
- 当一个任务到来,发现当前线程池的数量小于corePoolSize,则直接创建线程执行
- 当一个任务到来,没有多余线程执行,放入workQueue,发现workQueue满了,但是当前线程池的线程数量未达到maximumPoolSize,则创建线程执行任务。
-
状态:
- RUNNING:workQueue能放入任务
- SHUTDOWN:不能放入任务,但可以执行workQueue中的任务
- STOP:不能放入任务,也不执行workQueue任务,且会终止正在执行的任务
- TIDYING:调用终结方法
- TERMINATED:已终结
-
方法:
- execute:提交任务,交给线程池执行
- submit:提交任务,能够获取执行结果,execute+Future
- shutdown:关闭线程池,等待任务都执行完成
- shutdownNow:关闭线程池,不等待线程执行完,强行暂停正在执行的任务
-
监控方法:
- getTaskCount:线程池已经执行和未执行的任务总数
- getCompletedTaskCount:已完成的任务数量
- getPoolSize:线程池当前线程数量
- getActiveCount:当前线程池中正在执行任务的线程数量
-
线程池创建:
- Executors.newCachedThreadPool:可缓存线程池,可 回收线程
- Executors.newFixedThreadPool:线程数固定
- Executors.newScheduledThreadPool:定长,定时和周期执行任务
- Executors.newSingleThreadExecutor:单线程线程池,保证任务顺序执行
-
合理配置:
- CPU密集型任务,需要尽量压榨CPU,参考值设置未N*CPU+1
- IO密集型任务,参考值为2N*CPU
十、多线程并发拓展
1、死锁与活锁
- 死锁必要条件
- 互斥条件
- 请求和保持条件
- 不剥夺条件
- 环路等待条件
- 活锁:当线程间互相谦让资源,导致所有线程都无法获取到足够资源进行业务处理。
2、并发相关概念
- 阻塞:当一个线程进入临界区后,其他线程必须等待
- 无障碍:
- 宽进严出,可能导致死循环
- 无竞争时,有限步内完成操作
- 有竞争时,回滚数据
- 无锁:
- 无障碍
- 保证有一个线程能够胜出
- cas就是无锁的
- 无等待:
- 无锁
- 要求所有线程都必须在有限步数内完成
- 无饥饿:相当于没有线程优先级
3、并发最佳实践
-
使用本地变量
-
使用不可变类
-
最小化锁的作用域范围:S=1/(1-a+a/n) 阿姆达尔定律
- a并行计算部分所占的比例
- n并行计算处理的节点个数
- S为加速比
-
使用线程池,不直接使用new Thread
-
使用同步也不要使用线程的wait和notify
-
使用BlockingQueue实现生产消费模式
-
使用并发集合而不是加锁的同步集合
-
使用Semaphore创建有界的访问
-
宁可使用同步代码块也不适用同步方法
-
避免使用静态变量(除非final只读)
4、Spring与线程安全
- Spring bean(scope):singleton、prototype
- 无状态对象:如DTO、DAO
- 有状态需要加锁,或者ThradLocal
5、HashMap与ConcurrentHashMap解析
(1)HashMap
- 初始容量:16
- 加载因子:0.75
- hash值取mod,数组长度必须为2的n次方
- HashMap的resize可能出现死循环,迭代器fail-fast
(2)ConcurrentHashMap
-
java7:分段锁
-
java8:红黑树
6、并发的两个重要定律
(1)Amdahl定律(阿姆达尔定律)
-
定义了串行系统并行化后的加速比的计算公式和理论上限
-
加速比定义:加速比=优化前系统耗时/优化后系统耗时
$$
加速比公司:S=1/(1-a+a/n)
$$
- a代表并行计算部分所占的比例,n为并行处理节点个数。
- 例如,若串行代码占整个代码的25%,则并行处理的总体性能不可能超过4。
- 增加CPU数量并不一定能起到有效的作用,提高系统内可并行的模块比重,合理增加并行处理器数量,才能以最小的投入,得到较大的加速比
(2)Gustafson定律(古斯塔夫森定律)
- 说明处理器个数,串行比例和加速比之间的关系
- 执行时间 :a + b a 串行时间 b并行时间
- 总执行时间 a+nb n处理器个数
- 串行比例:F = a/(a+b)
$$
加速比公式:S = n-F(n-1)
$$
- 只要有足够的并行化,那么加速比和CPU个数成正比
7、Amino无锁类
public class LockFreeList<E> implements List<E> {
protected static class Entry<E> {
E element;
AtomicMarkableReference<Entry<E>> next;
}
protected AtomicMarkableReference<Entry<E>> head;
public LockFreeList() {
head = new AtomicMarkableReference<Entry<E>>(null, false);
}
public boolean add(E e) {
if (null == e) throw new NullPointerException();
final Entry<E> newNode = new Entry<E>(e,
new AtomicMarkableReference<Entry<E>>(null, false));
while (true) {
Entry<E> cur = head.getReference();
newNode.next.set(cur, false);
if (head.compareAndSet(cur, newNode, false, false)) {
return true;
}
}
}
// http://amino-cbbs.sourceforge.net/qs_java.html
}
十一、高并发处理思路与手段
1、扩容
- 方式:
- 垂直扩容:提高系统部件能力
- 水平扩容:增加更多系统成员来实现
- 数据库扩容:
- 读操作:memcache、redis、CDN等缓存
- 写操作:Cassandra、Hbase等
2、缓存
-
缓存特征:
- 命中率:命中数/(命中数+没有命中数)
- 最大元素(空间)
- 清空策略:FIFO、LFU(最少使用策略)、LRU(最近最少使用策略)、过期时间、随机等
-
缓存命中率影响因素:
- 业务场景和业务需求
- 缓存的涉及(粒度和策略)
- 缓存容量和基础设施
-
缓存分类和应用场景:
- 本地缓存:编程实现、Guava Cache
- 分布式缓存:Memcache、Redis
3、Guava Cache
- 多个segments的细粒度锁,类似java7HashMap分段锁
- LRU算法移除
- key -> WeakReference value -> Weak/SoftReference
- 统计缓存命中率 未命中率 异常率
4、Memcache
- 一致性hash算法
- slab_class:
- slab:数量有限,1.25倍
- page:1M内存,申请内存
- chunk:存放数据,page通过chunk进行切分
- chunk总有内存浪费
- LRU不是针对全局的,而是针对slab的
- key值最大为250字节
- 单个item最大为1M
- 不能遍历items
- 非阻塞基于事件
5、Redis
(1)type
- string
- hash
- list
- set
- sorted set
(2)编码方式
- raw
- int
- ht
- zipmap
- linkedlist
- ziplist
- intset
(3)特征
-
支持持久化
-
数据备份,主从模式
-
读性能11w/s,写性能8w/s
-
单操作原子性,支持多操作的原子性
-
subsribe/pushlish通知key过期
(4)使用场景:
- 排行榜,取top n的操作
- 取最新n个数
- 计数器
- 唯一性检查
- 实时系统
- 消息队列系统
6、缓存问题
-
缓存一致性问题:
- 更新db成功 -> 更新缓存失败 -> 数据不一致
- 更新缓存成功 -> 更新db失败 -> 数据不一致
- 更新db成功 -> 淘汰缓存失败 -> 数据不一致
- 淘汰缓存成功 -> 更新db失败 ->查询缓存miss
-
缓存穿透问题
- 缓存空对象,空集合,命中不高但频繁更新的数据
- 单独过滤数据,命中不高更新不频繁的数据
-
缓存雪崩:
- 缓存抖动:缓存故障导致,一致性hash算法解决
- 缓存原因导致大量请求到db,导致db宕机
- 多个缓存的数据周期性大量集中失效,也可能导致db压力过大
- 解决方案:
- 多级缓存
- 限流
- 降级
十二、消息队列
1、订单和手机短信(异步解耦)
2、消息队列特征
- 业务无关:消息分发
- FIFO:先投递先到达
- 容灾:节点的动态增删和消息的持久化
- 性能:吞吐量提升,系统内部通信效率提高
3、为什么需要消息队列
生产和消费的速度或稳定性等因素不一致
4、消息队列的好处
-
业务解耦
-
最终一致性(两个系统的状态一样,RocketMQ ZeroMQ):交易系统的高可靠
- 跨jvm的一致性问题解决方案:强一致性(分布式事务)和最终一致性实现简单
- 依靠定时任务和db实现最终一致性
-
广播
-
错峰与流控:
- 上下游处理能力不同,web前端lvs负载均衡 nginx服务器等设备提升到上千万请求,数据库处理能力有限
- 两个系统之间(滑动窗口也可实现)处理能力不同
5、消息队列距离
-
Kafka
- 高性能 跨语言 分布式 发布订阅消息队列的系统
- 支持快速持久化 O(1)的系统开销下进行持久化
- 高吞吐 10w/s producer broker counsumer原生支持分布式,自动实现负载均衡
- Hadoop数据并行加载,统一在线和离线数据
-
RabbitMQ
- Exchange:消息分发(分发策略)
- Queue:队列
十三、应用拆分思路
1、拆分原则
- 业务优先
- 循序渐进
- 兼顾技术:重构、分层
- 可靠测试
2、思考
- 应用之间通信:RPC(dubbo等)、消息队列
- 应用之间数据库涉及:每个应用都有独立的数据库
- 避免事务操作跨应用
3、组件
(1)Dubbo:服务注册到zookeeper
(2)Spring Cloud
-
独立的服务共同组成一个系统
-
单个部署,每个跑在自己的进程中
-
每个服务为独立的业务开发
-
分布式管理,强调隔离性
-
标准:
- 分布式服务组成的系统
- 按照业务,不是按照技术划分
- 有生命的产品而不是项目
- 强服务个体,弱通信
- 自动化运维,devops
- 高度的容错性
- 可以快速演化和迭代
-
客户端访问服务:Api Gateway
- 提供统一的入口
- 微服务对于前台透明
- 聚合后台服务
- 集成流量,提升性能
- 安全,过滤,流控
-
服务之间通信:
- 异步:消息队列(一致性减弱,需要实现幂等性)
- 同步:
- rest(http):SpringBoot Vert.x Dropwizard
- rpc:dubbo
-
服务发现:zookeeper注册
-
服务可靠性:
- 重试机制
- 熔断机制
- 限流机制
- 系统降级
十四、限流机制
1、常见限流
- 限制总并发数
- 限制瞬时并发数
- 限制时间窗口内的平均速率
2、算法
-
计数器法(1分钟100个)
-
滑动窗口(10秒一个,每格都有独立的计数器)
-
漏桶算法
- 出水恒定
- 超出溢出
-
令牌桶算法
3、算法对比
- 计数器法 VS 滑动窗口
- 计数器是滑动窗口低精度的实现
- 滑动窗口实现需要更多的空间
- 漏桶算法 VS 令牌桶算法
- 令牌桶算法允许一定条件的突发,因为取走token的不需要耗费时间
十五、服务降级和熔断思路
1、服务降级
- 自动降级:超时、失败次数、故障、限流
- 人工降级:秒杀、双11大促
2、熔断思路与服务降级对比
- 共性:目的(可用性 可靠性着想)、最终表现(不可达)、粒度(服务、数据持久型)、自治(自动触发)
- 区别:
- 触发原因:熔断是下级服务引起,降级是整体负荷考虑
- 管理层次:熔断是框架级处理,降级对业务有层级之分(最外围)
- 实现不同
3、服务降级需要考虑的问题
- 核心和非核心服务
- 是否支持降级,降级策略
- 业务放行场景,策略
4、Hystrix(服务降级实现)
- 再通过第三方client访问(网络)依赖服务出现高延迟或者失败时,为系统提供保护和控制
- 再分布式系统中防止级联失败
- 快速失败(Fail fast)同时能快速恢复
- 提供失败回退和优雅的服务降级机制
十六、数据库切库
1、数据库瓶颈
- 单个数据库过大:多个库
- 单个数据库压力过大,读写瓶颈:多个库
- 单个表数据量过大:分表
2、数据库切库
- 切库基础:读写分离,1主多从
- 自定义注解实现数据库切库
- 代码实现多数据源
3、数据分表
- 什么时候分表?
- 横向分表(id取mod)和纵向分表(根据数据活跃度分离数据)
- 数据库分表:mybatis分表插件 shardbatis2.0
十七、高可用的手段
- 任务调度系统分布式:elastic-job + zookeeper(无中心化的思想)
- 主备切换:apache curator + zookeeper分布式锁实现(多个服务器向zookeeper获取锁)
- 监控报警机制
十八、NIO与AIO
1、NIO的特性
- 基于块(Block),以块为基本单位处理
- 为所有的原始类型提供(Buffer)缓存支持 ,如ByteBuffer
- 增加通道(Channel)对象,作为新的原始 I/O 抽象
- 支持锁和内存映射文件的文件访问接口
- 提供了基于Selector的异步网络I/O
2、Buffer && Channel
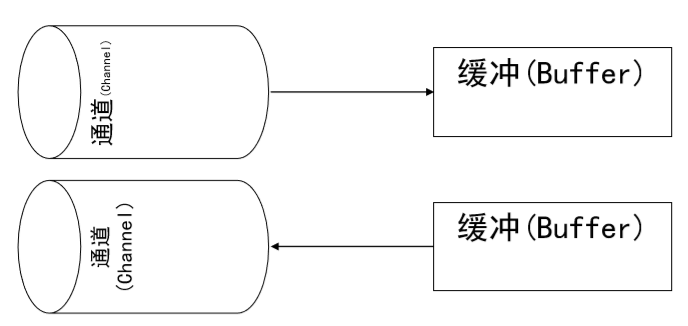
- 文件复制
public static void nioCopyFile(String resource, String destination) throws IOException {
FileInputStream fis = new FileInputStream(resource);
FileOutputStream fos = new FileOutputStream(destination);
FileChannel readChannel = fis.getChannel(); //读文件通道
FileChannel writeChannel = fos.getChannel(); //写文件通道
ByteBuffer buffer = ByteBuffer.allocate(1024);//读入数据缓存
while (true) {
buffer.clear();
int len = readChannel.read(buffer); //读入数据
if (len == -1) break; //读取完毕
buffer.flip(); // 读写切换
writeChannel.write(buffer); //写入文件
}
readChannel.close();
writeChannel.close();
}
- 文件映射到内存
RandomAccessFile raf = new RandomAccessFile("C:\\mapfile.txt", "rw"); FileChannel fc = raf.getChannel(); //将文件映射到内存中
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, raf.length());
while(mbb.hasRemaining()){
System.out.print((char)mbb.get());
}
mbb.put(0,(byte)98); //修改文件
raf.close();
- 三个重要的参数
| 参数 | 写模式 | 读模式 |
|---|---|---|
| position | 从position的下一个位置写数据 | 从position该位置读数据 |
| capacity | 缓冲区总容量 | 缓冲区总容量 |
| limit | 缓冲区实际上限,通常与capacity相等 | 代表可读容量,与上次写入的数据量相等 |
- 重要api
- rewind:将position置零,并清除标志位(mark),limit不变 ,即可重新读或写
- clear:将position置零,同时将limit设置为capacity的大小,并清除了标志mark
- flip:先将limit设置到position所在位置,然后将position置零,并清除标志位mark (通常用于读写切换)
3、网络编程
(1)BIO
// 客户端
public class NioClient {
private static final int sleepTime = 1000 * 1000 * 1000;
public static void main(String[] args) throws IOException {
ExecutorService tp = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
tp.execute(new EchoClient());
}
}
public static class EchoClient implements Runnable {
@Override
public void run() {
Socket client = null;
PrintWriter writer = null;
BufferedReader reader = null;
try {
client = new Socket();
client.connect(new InetSocketAddress("localhost", 8000));
writer = new PrintWriter(client.getOutputStream(), true);
writer.print("H");
LockSupport.parkNanos(sleepTime);
writer.print("e");
LockSupport.parkNanos(sleepTime);
writer.print("l");
LockSupport.parkNanos(sleepTime);
writer.print("l");
LockSupport.parkNanos(sleepTime);
writer.print("o");
LockSupport.parkNanos(sleepTime);
writer.print("!");
LockSupport.parkNanos(sleepTime);
writer.println(); // 这行很重要
writer.flush();
reader = new BufferedReader(new InputStreamReader(client.getInputStream()));
System.out.println("from server: " + reader.readLine());
} catch (IOException e) {
e.printStackTrace();
} finally {
writer.close();
try {
reader.close();
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
// 服务端
public class BIOServer {
public static void main(String[] args) {
ExecutorService tp = Executors.newCachedThreadPool();
ServerSocket echoServer = null;
Socket clientSocket = null;
try {
echoServer = new ServerSocket(8000);
} catch (IOException e) {
System.out.println(e);
}
while (true) {
try {
clientSocket = echoServer.accept();
System.out.println(clientSocket.getRemoteSocketAddress() + " connect!");
tp.execute(new HandleMsg(clientSocket));
} catch (IOException e) {
System.out.println(e);
}
}
}
static class HandleMsg implements Runnable {
private Socket clientSocket;
public HandleMsg(Socket clientSocket) {
this.clientSocket = clientSocket;
}
public void run() {
BufferedReader is = null;
PrintWriter os = null;
try {
is = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
// 从InputStream当中读取客户端所发送的数据
os = new PrintWriter(clientSocket.getOutputStream(), true);
String inputLine = null;
long b = System.currentTimeMillis();
while ((inputLine = is.readLine()) != null) {
os.println(inputLine);
}
long e = System.currentTimeMillis();
System.out.println("spend:" + (e - b) + " ms ");
} catch (IOException e) {
e.printStackTrace();
} finally {
//省略资源关闭
}
}
}
}
(2)Nio
public class NioServer {
private ExecutorService tp = Executors.newCachedThreadPool();
private Selector selector;
private Map<Socket, Long> geym_time_stat = new HashMap<>();
class EchoClient {
private LinkedList<ByteBuffer> outQueue;
public EchoClient() {
outQueue = new LinkedList<>();
}
public LinkedList<ByteBuffer> getOutQueue() {
return outQueue;
}
public void enqueue(ByteBuffer byteBuffer) {
outQueue.addFirst(byteBuffer);
}
}
private void startServer() throws IOException {
selector = SelectorProvider.provider().openSelector();
// 配置为非阻塞
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false);
// 绑定端口
InetSocketAddress address = new InetSocketAddress(8000);
serverChannel.socket().bind(address);
// 注册socket监听事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
for (; ; ) {
selector.select();
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = readyKeys.iterator();
long e = 0;
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
iterator.remove();
if (selectionKey.isAcceptable()) {
doAccept(selectionKey);
} else if (selectionKey.isValid() && selectionKey.isReadable()) {
Socket socket = ((SocketChannel) selectionKey.channel()).socket();
if (!geym_time_stat.containsKey(socket)) {
geym_time_stat.put(socket, System.currentTimeMillis());
}
doRead(selectionKey);
} else if (selectionKey.isValid() && selectionKey.isWritable()) {
doWrite(selectionKey);
Socket socket = ((SocketChannel) selectionKey.channel()).socket();
e = System.currentTimeMillis();
long b = geym_time_stat.remove(socket);
System.out.println("spend:" + (e - b) + "ms");
}
}
}
}
private void doWrite(SelectionKey selectionKey) {
SocketChannel channel = (SocketChannel) selectionKey.channel();
EchoClient echoClient = (EchoClient) selectionKey.attachment();
LinkedList<ByteBuffer> outQueue = echoClient.getOutQueue();
ByteBuffer buffer = outQueue.getLast();
try {
int len = channel.write(buffer);
if (len == -1) {
disconnect(selectionKey);
return;
}
if (buffer.remaining() == 0) {
outQueue.removeLast();
}
} catch (IOException e) {
System.out.println("Failed: write to client");
e.printStackTrace();
disconnect(selectionKey);
}
if (outQueue.size() == 0) {
selectionKey.interestOps(SelectionKey.OP_READ);
}
}
private void disconnect(SelectionKey selectionKey) {
try {
selectionKey.selector().close();
selectionKey.channel().close();
} catch (IOException e) {
e.printStackTrace();
}
}
private void doRead(SelectionKey selectionKey) {
SocketChannel channel = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = ByteBuffer.allocate(8 * 1024);
int len;
try {
len = channel.read(buffer);
if (len < 0) {
channel.socket().close();
return;
}
} catch (IOException e) {
e.printStackTrace();
}
buffer.flip();
tp.execute(new HandleMsg(selectionKey, buffer));
}
class HandleMsg implements Runnable {
private SelectionKey selectionKey;
private ByteBuffer buffer;
public HandleMsg(SelectionKey selectionKey, ByteBuffer buffer) {
this.selectionKey = selectionKey;
this.buffer = buffer;
}
@Override
public void run() {
EchoClient echoClient = (EchoClient) selectionKey.attachment();
echoClient.enqueue(buffer);
selectionKey.interestOps(SelectionKey.OP_READ | SelectionKey.OP_WRITE);
selector.wakeup(); //强迫selector立即返回
}
}
private void doAccept(SelectionKey selectionKey) {
ServerSocketChannel server = (ServerSocketChannel) selectionKey.channel();
SocketChannel clientChannel;
try {
clientChannel = server.accept();
clientChannel.configureBlocking(false);
SelectionKey clientKey = clientChannel.register(selector, SelectionKey.OP_READ);
EchoClient echoClient = new EchoClient();
clientKey.attach(echoClient);
InetAddress inetAddress = clientChannel.socket().getInetAddress();
System.out.println("accepted from :" + inetAddress.getHostAddress());
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
NioServer nioServer = new NioServer();
try {
nioServer.startServer();
} catch (IOException e) {
e.printStackTrace();
}
}
}
(3)AIO
public class AIOEchoServer {
private AsynchronousServerSocketChannel server;
public static void main(String[] args) throws IOException {
AIOEchoServer aioServer = new AIOEchoServer();
aioServer.init("localhost", 8000);
}
private void init(String host, int port) throws IOException {
//ChannelGroup用来管理共享资源
AsynchronousChannelGroup group = AsynchronousChannelGroup.withCachedThreadPool(Executors.newCachedThreadPool(), 10);
server = AsynchronousServerSocketChannel.open(group);
//通过setOption配置Socket
server.setOption(StandardSocketOptions.SO_REUSEADDR, true);
server.setOption(StandardSocketOptions.SO_RCVBUF, 16 * 1024);
//绑定到指定的主机,端口
server.bind(new InetSocketAddress(host, port));
System.out.println("Listening on " + host + ":" + port);
//等待连接,并注册CompletionHandler处理内核完成后的操作。
server.accept(null, new CompletionHandler<>() {
final ByteBuffer buffer = ByteBuffer.allocate(1024);
@Override
public void completed(AsynchronousSocketChannel result, Object attachment) {
System.out.println(Thread.currentThread().getName());
buffer.clear();
try {
//把socket中的数据读取到buffer中
result.read(buffer).get();
buffer.flip();
System.out.println(System.currentTimeMillis()+" Echo " + new String(buffer.array()).trim() +" to"+result.getRemoteAddress());
//把收到的直接返回给客户端
result.write(buffer);
buffer.flip();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭处理完的socket,并重新调用accept等待新的连接
result.close();
server.accept(null, this);
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void failed(Throwable exc, Object attachment) {
System.out.print("Server failed...." + exc.getCause());
}
});
//因为AIO不会阻塞调用进程,因此必须在主进程阻塞,才能保持进程存活。
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号