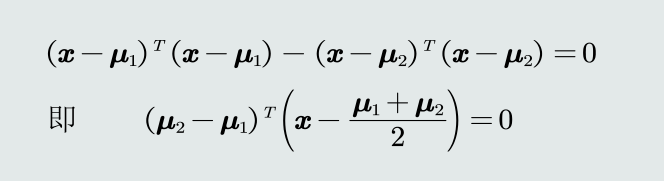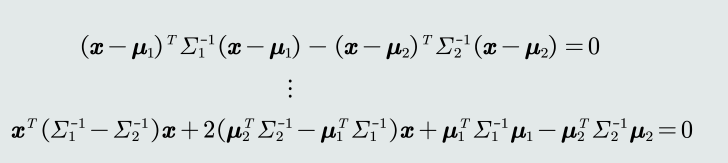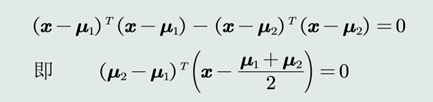- 机器学习第一次作业
- 第一章 模式识别的基本概念
- 笔记
- 第二章 基于距离的分类器
- 笔记
- 第三章 贝叶斯决策与学习
- 笔记
-
第一次作业
第一章 模式识别的基本概念
笔记
模式识别是一个推理过程
-
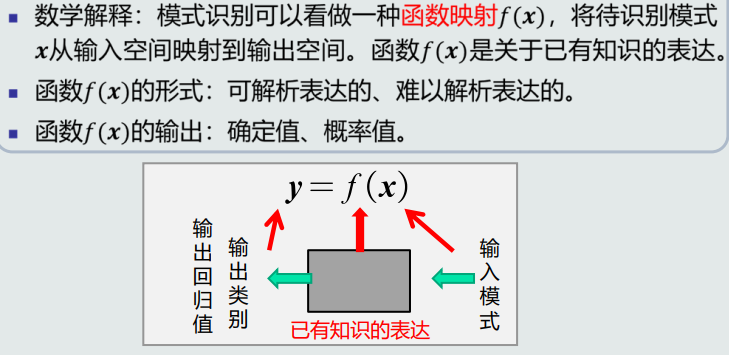
如何解释模式识别?
![image.png]()
-
模型的作用?
(1)用于回归,将特征映射到回归值
![image.png]()
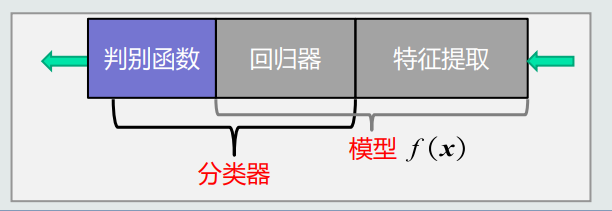
(2)用于分类, 特征提取+回归器+判别函数
![image.png]()
-
特征的表达?
特征向量:多个特征构成的(列)向量
特征的相似度度量
-
特征向量点积
由于每个特征向量代表一个模式,所以度量特征向量两两之间的 相关性是识别模式之间是否相似的基础。
-
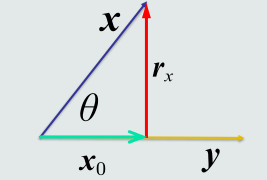
残差向量
向量x分解到向量y方向上得到的投影向量和原向量x的误差
![image.png]()
机器学习的概念
-
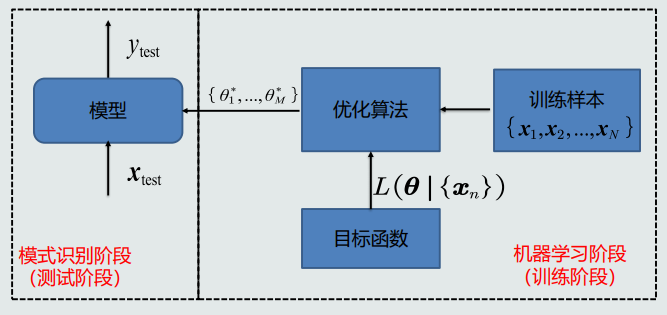
拿什么学?
训练样本(数据),计作
-
学什么?
,学习模型的参数
-
怎么学?
设置目标函数 ,通过优化算法最小化或最大化目标函数,通过优化算法,最终得到模型参数的最优解
![image.png]()
-
机器学习的方式?监督学习?半监督学习?无监督学习?
模型的泛化能力指标
-
什么是泛化能力?
训练得到的模型不仅要对训练样本具有决策能力, 也要对新的(训练过程中未看见)的模式具有决策能力。
-
什么在影响泛化能力?
过拟合、欠拟合
-
如何提高泛化能力?
思路是不能过度训练,要选择复杂度合适的模型,并在目标函数中加入正则项
评估方法和性能指标
-
如何量化的评估模型性能?
留出法、K折交叉验证、留一验证
-
性能指标度量
准确度(Accuracy)、精度(Precision)、召回率(Recall)、F-Score、混淆矩阵、PR曲线、ROC曲线、AUC
第一章 学习心得
物体识别实际上是通过模式识别来实现的,现实生活中的很多时候,区分两个物体的不同,并不是靠最本质的区别来判定的,因为会很复杂或者麻烦。所以要借助一些其他的特征来判定。因此实际上,模式识别并不是根据物体本身来判断的,而是根据被感知到的某些性质,容易感知到的某些物体特征来进行判别。也就引出了模式的定义——如物体的颜色、厚度、大小、重量等的易被感知到的物体特性,叫做模式。 为了识别物体,也就是进行分类,一般会用分类器这个工具。故而分类器实际上识别的不是物体,而是物体的模式。
第二章 基于距离的分类器
笔记
MED分类器——最小欧式距离分类器
-
基于距离的决策
把测试样本到每个类之间 的距离作为决策模型,将测试样 本判定为与其距离最近的类
-
如何计算测试样本与每个类的距离?
类的原型: 用来代表这个类的一个模式或者 一组量,便于计算该类和测试样 本之间的距离。
原型的种类:该类中所有训练样本的均值作为类 的原型:
-
常见的距离度量
欧式距离、曼哈顿距离、加权欧式距离
-
MED分类器决策边界
![image.png]()
-
MED分类器的问题?
MED分类器采用欧氏距离作为距离度量,没有考虑 特征变化的不同及特征之间的相关性。
特征正交白化——去除特征相关性
令
-
解耦
通过实现协方差矩阵对角化,去除特征之间的相关性
-
白化
通过对上一步变换后的特征再进行尺度变化,实现所有特征具有相同方差
MICD分类器——最小类内距离分类器(基于马氏距离)
-
马氏距离的属性
其中Σ是多维随机变量的协方差矩阵. 马氏距离(Mahalanobis Distance)是一种距离的度量,可以看作是欧氏距离的一种修正,修正了欧式距离中各个维度尺度不一致且相关的问题。
(1)当Σ=I 时:等于欧氏距离
(2)当Σ为对角矩阵时:
(3)当Σ是任意值时:等距图是一个有方向的超椭圆面
-
决策边界
![image.png]()
-
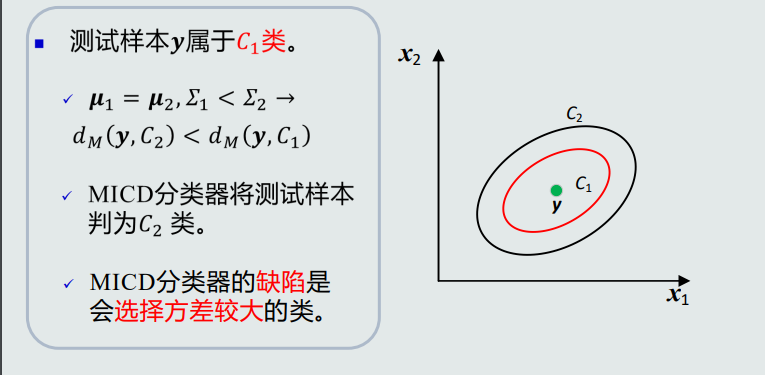
问题缺陷
![image.png]()
-
推导MED分类器的边界公式?
![image.png]()
第三章 贝叶斯决策与学习
笔记
贝叶斯决策与MAP分类器
-
基于距离决策的通病
- 仅考虑每个类别各自观测到的训练样本的分布情况,例如, 均值(MED分类器)和协方差(MICD分类器)。
- 没有考虑类的分布等先验知识,例如,类别之间样本数量 的比例,类别之间的相互关系。
-
什么是后验概率?
, 表达给定模式𝒙属于类可能性 。
-
如何得到后验概率?
基于贝叶斯规则(Bayes rule),已知先验概率和观测概率, 模式𝒙属于类后验概率的计算公式为:
- :类的先验概率
- :观测似然概率
- :所有类别样本x的边缘概率
-
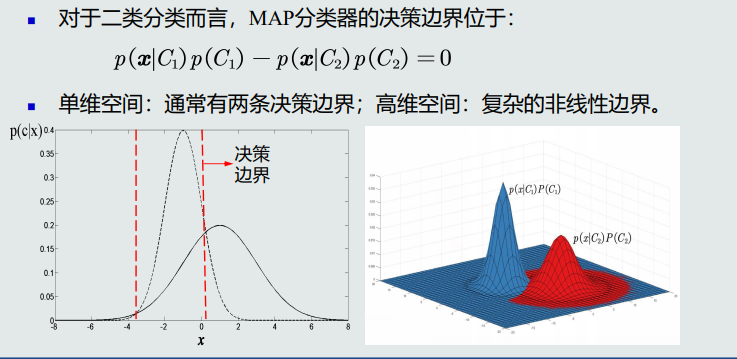
MAP分类器的概念:
将测试样本 决策分类给后验概率最大的那个类。
![image.png]()
-
MAP分类器的决策边界
![image.png]()
-
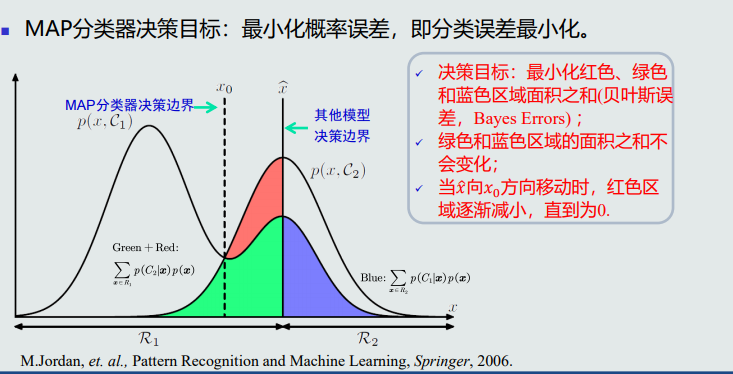
MAP分类器的决策误差
![image.png]()
-
决策误差最小化
![image.png]()
-
如何表达观测概率
参数化机械表达——高斯分布
将观测似然概率设置为高斯分布。
决策风险和贝叶斯分类器
-
决策风险和损失的概念
决策风险: 贝叶斯决策不能排除出现错误判断的情况,由此会带来决策风险。 更重要的是,不同的错误决策会产生程度完全不一样的风险 。
损失: 在推理/测试阶段,分类器并不知道其输出的决策是否正确。 因此,我们需要定义一个惩罚量,用来表征当前决策动作相 对于其他候选类别的风险程度,即损失(loss)
-
决策风险的评估
![image.png]()
-
贝叶斯分类器——选择风险最小的类
在MAP分类器基础上,加入决策风险因素,得到贝叶斯分类器 (Bayes classifier), 给定一个测试样本𝒙,贝叶斯分类器选择决策风险最小的类。
-
贝叶斯分类器决策损失有多大?
![image.png]()
-
贝叶斯分类器的决策目标
![image.png]()
-
特征维度较高,如何简化?
![image.png]()
-
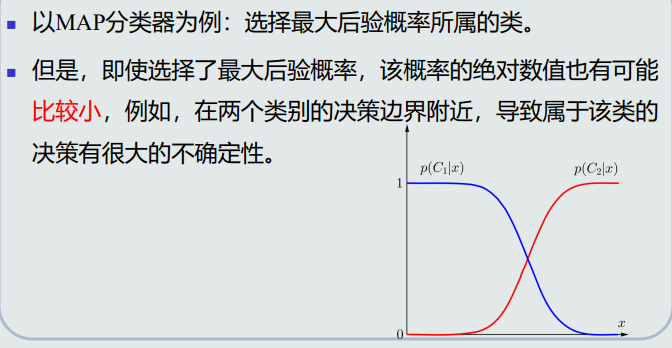
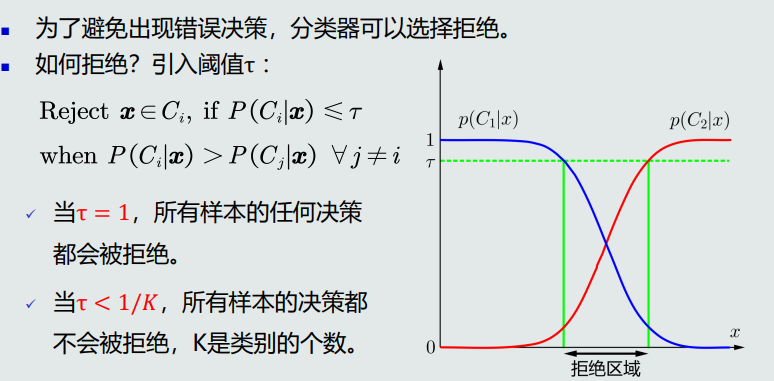
在决策边界附近怎么处理?
![image.png]()
![image.png]()
最大似然估计
公式推导略
贝叶斯估计
-
贝叶斯估计的概念
给定参数𝜃分布的先验概率以及训练样本,估计参 数θ分布的后验概率
假设𝜃 服从一个概率分布:
-
该概率分布的先验概率已知:𝑝(𝜃)
-
先验概率反映了关于参数𝜃的最初猜测及其不确定信息
-
-
参数的后验概率
-
高斯观测似然
-
参数先验概率
-
参数先验对后验的影响
无参数概率密度估计
-
KNN估计
![image.png]()
-
直方图估计
![image.png]()
![image.png]()
-
核密度估计
![image.png]()
![image.png]()
第三章 学习心得
学习了线性判据方法的基本概念,并行及串行感知机算法,Fisher线性判据等,尤其对拉格朗日乘数法有了进一步的了解。
线性判据顾名思义,如果判别模型f(x)是线性函数,则称为线性判据,既可以用于两类分类,也可以用于多类分类,多类分类中要求相邻两类之间的决策边界也是线性的即可。而拉格朗日乘数法则是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。
这种方法将一个有n 个变量与k个约束条件的最优化问题转换为一个有n + k个变量的方程组的极值问题,其变量不受任何约束,对问题的求解有很大的帮助。
-
- 第一章 模式识别的基本概念
|
|
 |
管理
|
管理
机器学习第一次作业——一至三章笔记目录 
|