
第二次作业2
本次作业是一个词频统计的小程序,要求如下
https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
一、程序使用比较常用的C++进行编写,初步设想中,编写这样一个程序需要解决下列问题:(其实不都是事先想的,有的是编程中遇到的问题,但是很难分清,为了行文流畅,故都放在前面)
1.文件的读写,包括type关键字文本的写入
2.单词的划分,包括空格与标点
3.文件列表的获取,包括了路径和文件的查找。
4.关键词的判断。包括通过三种关键词进行不同的操作,特别是wf后可能接不同的类型。
5.词频的统计。
6.版本的控制,使用github进行,以前没有用过。
之后编写程序并使用搜索引擎来解决遇到的问题。
#1.文件的读写
对于的操作是type关键字。当检测到用户输入type关键字时,调用WriteTxt函数
1 void WriteTxt(const vector<string> splits) 2 { 3 ofstream outfile(splits.at(1)); 5 string words; 6 if (outfile.is_open()) 7 { 8 getline(cin,words); 11 outfile << words << endl; 12 outfile.close(); 13 } 14 else 15 cout << "Cannot open this file!" << endl; 16 17 }
对于文件的读入,没有进行特殊的处理,略。
2.单词的划分本来想要自己进行划分,但是查到一个函数ispunct(),可以直接判断某个字符是否是标点,于是就简化了一些
去除空格与无效字符就可以了,先去除无效字符,然后去除空格
去除空格的方法如下,大概是找到两个空格,中间的为一个单词,将其保存。
1 void Split(const string inputs, vector<string>& splits) 2 { 3 std::string::size_type pos1, pos2; 4 string block = " "; 5 pos2 = inputs.find(block); 6 pos1 = 0; 7 while (std::string::npos != pos2) 8 { 9 if (pos2 != pos1) 10 { 11 splits.push_back(inputs.substr(pos1, pos2 - pos1)); 12 } 13 pos1 = pos2 + block.size(); 14 pos2 = inputs.find(block, pos1); 15 } 16 if (pos1 != inputs.length()) 17 splits.push_back(inputs.substr(pos1)); 18 }
3.文件列表的获取
dir命令要求显示目录下的所有文档,需要知道路径。通过搜索引擎搜索,知道了一个函数getcwd,可以获取当前目录的绝对路径,比较容易就可以得到文件的路径了。同时还有一个用于文件查找的结构体_finddata_t
整个dir命令显示列表的代码如下,首先查找路径然后使用结构体_finddata_t来查找文件,将结果存在string型的向量lists中
1 vector<string> Dir(const string path) 2 { 3 char buff[1000]; 4 getcwd(buff, 1000); 5 struct _stat buf = { 0 }; 6 string p; 7 p.append(buff); 8 p.append("\\"); 9 p.append(path); 10 p.append("\\*"); 11 vector<string> lists; 12 _finddata_t fileDir; 13 long lfDir; 14 15 if ((lfDir = _findfirst(p.c_str(), &fileDir)) != -1l) 16 { 17 do{ 18 if (!(fileDir.attrib & _A_SUBDIR)) { 19 lists.push_back(fileDir.name); 20 21 } 22 } while (_findnext(lfDir, &fileDir) == 0); 23 24 } 25 _findclose(lfDir); 26 return lists; 27 }
4.对于不同关键字的处理
其中,若是输入type则进行写文件操作(前文已经提到),输入dir则进行展示文件列表的操作(3中提到)。
而wf则比较复杂,wf后面共有三种形式
(1)-s *.txt
(2)文件名
(3)文件夹名
因为这三种处理方式是不同的,所以要先进行判断
首先用了很土的办法,判断后面是几个字符,将(1)与(2)和(3)分开,而怎么判断是否是文件名与文件夹名起初并不会,后来知道可以使用_S_IFDIR & buf.st_mode来判断类型是否是directory。知道这个之后这个问题就比较简单,这里不贴代码了。
5.词频的统计
使用了Map进行统计,其中KEY为string,VALUE为int,若出现新的单词,则创建新的节点,若出现重复的单词,则value加1。
用sort排序后将结果输出,总词数即为节点个数。
1 for (vector<string>::iterator it = words.begin(); it != words.end(); it++) 2 { 3 statis[*it]++; 4 } 5 6 vector<pair<string, int>> final; 7 copy(statis.begin(), statis.end(), back_inserter(final)); 8 sort(final.begin(), final.end(), cmp); 9 return final;
6.版本控制
使用TortoiseGit 进行push。
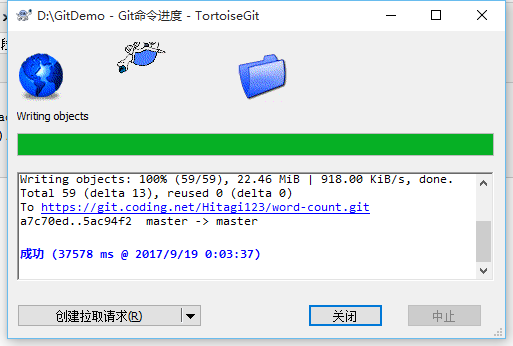
地址是
https://git.coding.net/Hitagi123/word-count.git
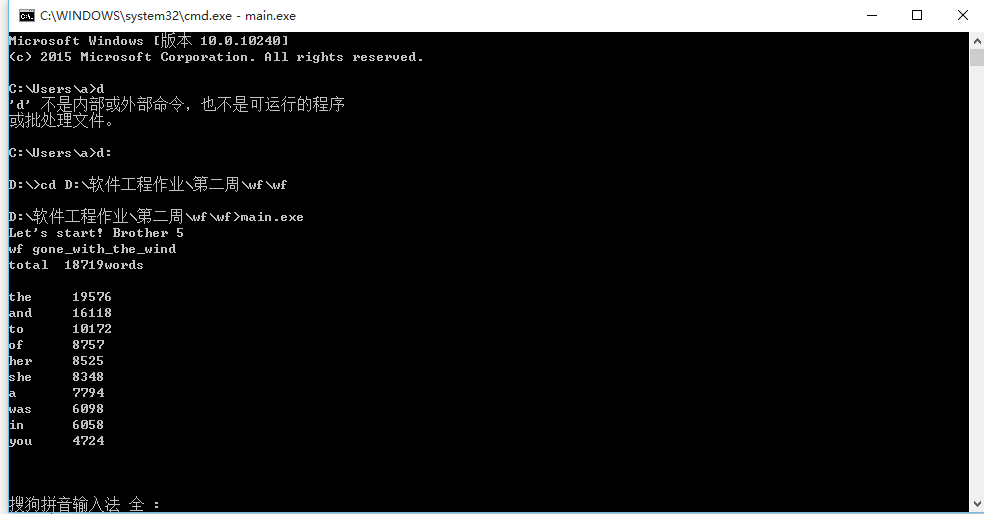
二、截图:


三、PSP
| 任务 | 预估时间(min) | 时间花费时间(min) |
| 前期学习与准备 | 60 | 90 |
| 读写函数 | 10 | 15 |
| 单词划分 | 20 | 90 |
| 文件的显示(DIR函数) | 30 | 105 |
| 关键字的处理 | 5 | 30 |
| 词频统计 | 10 | 30 |
| 整合 | 30 | 90 |
| 版本控制 | 30 | 120 |
| 合计 | 195 | 570 |
原因:这次的项目耗费时间的地方主要有以下几个方面
(1)学习使用vector。考虑到容器比较适合编写这个程序,所以想试试。但是以前很少使用vector,用起来非常不熟练,也比较依赖搜索引擎,这一部分花了比较多的时间。
(2)对于一些常用的函数和解决方法不熟悉,特别是在文件和路径这一部分。在一些问题上会卡住,但是实际上可能有函数可以直接解决这个问题(前文提到了)。
(3)长时间不编程编程生疏,从准备的时间到整合的时间以及在实现过程中都花的比想像中的要长很多,有的时候越变越蒙。
(4)需求理解问题。
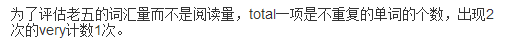

最初看见这两句话,想当然的认为功能一统计不重复的词,功能二统计总词数。期间也和同学有了很多讨论,代码改来改去,后来最后一天才最终确定要统计不重复词。以后应该第一时间问清楚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号