

代码规范+Java日志LogNDC和MDC
一次代码评审,差点过不了试用期!

作者:小傅哥
博客:https://bugstack.cn
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
好的代码往往也很好看
代码是给机器运行的,但同样也是给人看的,并且随着上线还需要由人来运维。那么写出可扩展、易维护、好读懂的代码就显得非常重要。
对于新人来说,互联网大厂项目开发与平常自己学习的代码还是有很大的差别的。日常学习时候通常只要能运行出结果即可,并不会有其他的要求。也不会说有;PRD评审、研发设计评审、代码开发、代码评审以及中间一些列的提交物,直到测试完成,上线验证,开量对外等等。
所以很多新人刚从学校毕业或者从小公司进入大厂,在规范制约下会有一些不习惯,甚至犯错误。那么为了让大家更好的知晓这些问题,小傅哥特意整理了一些例子,欢迎参考。
二、会议室
谢飞机,刚刚入职没多久,兴奋的写着leader给的需求,🐎码的飞快。恰巧组长走过来:“飞机,带着你的电脑,跟我来码云会议室,做下代码评审。”
leader:飞机,你这代码咋这么粗鲁!
飞机:啊?😱
leader:我要不拦着你,我感觉你这代码都能飞。
leader:你看哈,就说这行,这日志打的,上线后出了问题,你能查到原因吗?
飞机:好像...
leader:还有这,这idea都提示你了,都报黄色了,你怎么不看看。还有,这代码也不格式化,一个月后它认识你,你还认识它吗。
leader:给你发的入职编码规范看了?
飞机:哦,看一些,写的时候忘了。
leader:先别着急写,看会了再写代码,这还有一个不错的工程:《Netty+JavaFx实战:仿桌面版微信聊天》,可以参考。
写代码不是以完成功能就算完事,还需要写的漂亮。评审后,飞机,坐回工位,收起了躁动的心,安心熟读手册并练习。
三、代码评审
1. 日志规范
日志是整个代码开发过程中非常重要的环节,如果日志打的不好,那么遇到的线上bug就没法快速定位,定位不了问题也就没法快速解决问题。直接带来的结果可能包括;客诉更多、资损更大、修复更慢。
就像下面这段代码中的日志;
public Result execRule(RuleReq req) {
try {
logger.info("执行服务规则 req:{}", JSON.toJSONString(req));
// 业务流程
return Result.buildSuccess();
} catch (Exception e) {
logger.error("执行服务规则失败", e);
return Result.buildError(e);
}
}
- 看似没什么问题,但在这段异常代码中,没有打方法的入参信息。如果方法异常时只是抛出一些异常栈信息,那么是很难定位具体的由次调用触发的。
- 另外如果你的系统监控服务,没有类似方法跟踪ID的功能,最好还需要在日志中把本次调用具有标识性的id,作为查询条件打到日志中。
修改后的日志:
public Result execRule(RuleReq req) {
try {
logger.info("执行服务规则{}开始 req:{}", req.getrId(), JSON.toJSONString(req));
// 业务流程
logger.info("执行服务规则{}完成 res:{}", req.getrId(), "业务流程,必要的结果信息");
return Result.buildSuccess();
} catch (Exception e) {
logger.error("执行服务规则{}失败 req:{}", req.getrId(), JSON.toJSONString(req), e);
return Result.buildError(e);
}
}
- 那么现在这样改成这样打日志,就可以非常方便的查询问题,例如搜索;
执行服务规则100098921,那么它的一整串关于这次调用的信息就可以都搜索出来了,方便排查问题。 - 在异常中打印入参是为了更加方便的定位问题,不需要比对上下文。
- 打日志还有很多技巧,但所有打的日志目的都为了在出问题时可以快速定位问题,但也注意不要打太多日志,精简好用即可。
2. IDEA提示
很多时候因为你,走神、疏忽、手滑,写出来的错误代码,IntelliJ IDEA,都会给你警告⚠提示,只是你,没有去看、没有去看、没有去看!
来自idea的警告;
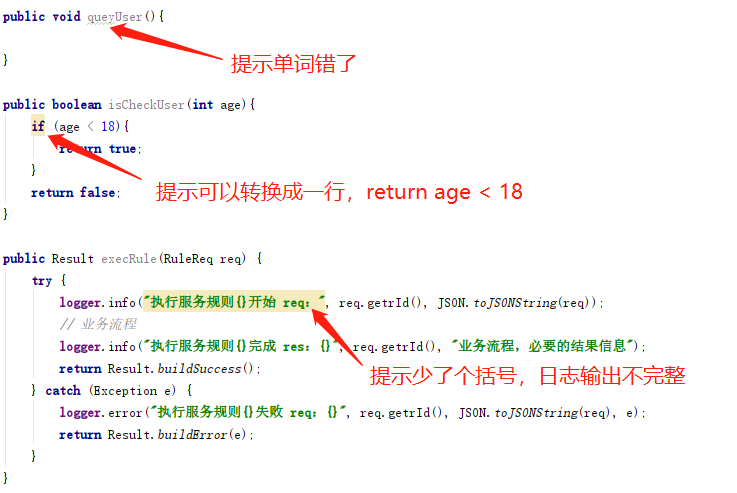
- Idea在警告提示这方面非常优秀,只要你能看得见,按照它的提示修改,就可以减少很多的错误。
- 如果你还希望有更强的提示,那么你可以按照
p3c插件,帮你检查代码错误。
3. 代码格式
可能这并不是一个致命的问题,但代码格式化最大的好处是,提升可读性、规整性、以及可以让整组人都在一个标准下执行。因为很多时候一个组的程序员,会在一个类下开发,有人格式化、有人不格式化除了不好看以外,合并代码有时候也会遇到麻烦。
不格式化的代码缺少灵魂;
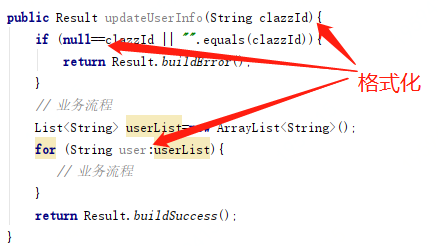
- 对于严格要自己的程序员来说,代码没有格式化还是很难受的。
- 看一段代码,只要发现差一个空格位置,都知道这是格式化还是没格式化。
4. 单元测试
单测?覆盖率?写代码不是写完就可以了吗?
当然不是,你写的代码你需要保证它能你跑通你所有的流程节点,确保这份功能是没有问题的,才能提交给测试,否则来回反复,耗时耗力。这也就是写单测的目的!甚至好一点的研发可以通过单测驱动开发,在这个阶段能把一些共用的方法合并、抽离,避免过多的冗余方法。
单测长什么样;
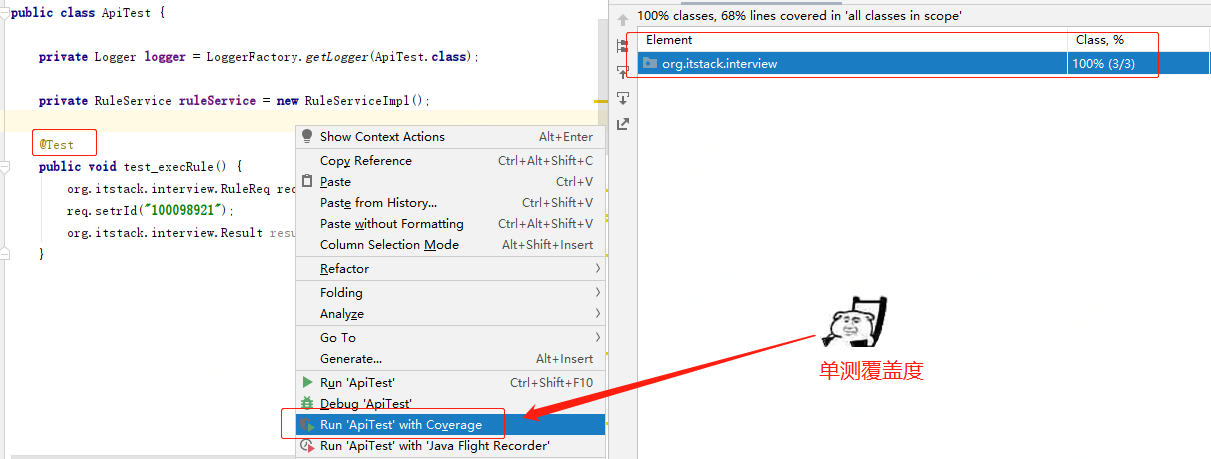
- 单测完整基本也就是代码的健壮性更好,能把单测写好,基本提交的代码就不会有那么多测试妹子找你聊天。
- 在很多公司中一般都会要求单测覆盖率超过多少,否则是不允许编译提交的,这有插件可以和
Jenkins配合使用。
5. 分支规范
可能有些人看到分支规范根本没有感觉,因为他们开发的项目较小,没有多人开发,上线周期也短,也不会开发中添加需求。
但在互联网中并不是这样,往往一个系统需要几个人维护,并同时进行开发。一般这里会包括;master分支、test分支、本次需求的分支,有这么多分支怎么用呢,如下;
- master分支,是主分支,也是上线分支,不允许在上面直接修改代码。
- test分支,是测试环境分支,每个人都需要把自己开发完的分支,提测后合并到test分支,交由测试验证。
- 需求分支,也是个人开发的分支,同一个需求下,大家在这个分支写代码,当然也可能这个系统模块的分支就一个人在开发。
重点,如果有人不遵守分支规范或者压根没概念,把自己的需求代码写在test分支上,并且是多次修改提交都在test分支写。那么就危险了,严重会耽误上线;为什么?
- test分支,是由大家把自己的代码合并过来共用的,那么这个分支就会包含2个或者更多的并行需求,当你需要上线的时候,需要把自己的代码合并到master,但test分支代码是不能合并到master的,那么多未知的内容,根本没有在上线范围。
- 那么你又想上线,又不能避开test分支,就需要把你写的代码,重新粘贴过去,这个时间成本非常大。
- test分支,还随时有删除重新拉的可能,如果有人通知大家删除重新拉,那你的代码就会丢失。
6. 夹带需求
提交测试,但还藏一个需求
研发开发需求代码时候,有时候会额外加一些其他代码,而且这些代码可能跟本次需求并没有关系。那为什么会这样呢?
- 以前留下来的bug,想修复下,但忘记告知测试
- 在开发这个需求时,其他产品又找过来让加功能,并说功能很小,没有发邮件通知相关测试人员
- 看到某块以前写的代码太乱了,就想着优化下,自信心很高,不必告诉测试
那这时候你提交的代码,如果不在测试范围又出了问题,只能研发自己抗。并且在所有的研发团队,几乎是不会让夹带需求上线的,这样的做完了不算功劳,做出了问题还会被骂。
所以,千万不要私自夹带!哪怕你是好心!
7. 异常流程
擦屁屁的纸,80%的面积都是保护手的!
这句话是我经常用的,因为我们编程很多时候都是在处理异常流程,正常流程往往并不难,难的是分析出这段开发的代码有多少异常流程有没有处理。
那么,会有哪些异常呢?
- 支付成功MQ消息发送失败,需要worker补偿
- PRC接口调用失败,网络超时,实际成功
- 接口幂等性,多次调用结果一致性
等等,这些都是异常流程,尤其在一些交易提现环节,会出现各种异常,那么不可能把这些异常都反馈用户展示到界面。而是要有一些非常友好的提示,并且在服务端的流程里,有一定的补偿机制,来保证最终的调用成功,或者逆反。
8. 代码成坨

CRUD往往可能是因为你的设计,换个人写也许不同
很多时候研发写代码,根本不考虑是否要扩展,总之一个类 + 几十行ifelse,能搞定所有需求。等下次在开发类似的,就粘贴过去再修修补补,能用就行。
缺少写出良好代码的研发,一方面是经历有限,另外一方面是学了很多理论但是不好落地。比如设计模式,但自己实际写代码的时候还是很晕。
这里推荐一本我写的《重学Java设计模式》,全书共计22个真实业务场景对应59组案例工程、编写了18万字271页的PDF、包含交易、营销、秒杀、中间件、源码等22个真实场景。可以添加小傅哥微信获取:fustack
9. SQL性能
select * from table where status = 1 limit 200;
这是一段定时任务扫描库表的SQL,这段sql会定时扫库,将库表中状态是1的扫描出来进行处理,每次扫描200行。你发现有什么问题了吗?
- 扫描必要字段即可,不需要全部字段
- 这段sql会越来越慢,即使状态字段加了索引。因为
status并不能大量排掉其他状态字段,随着数据越来越多依然是全表扫描。
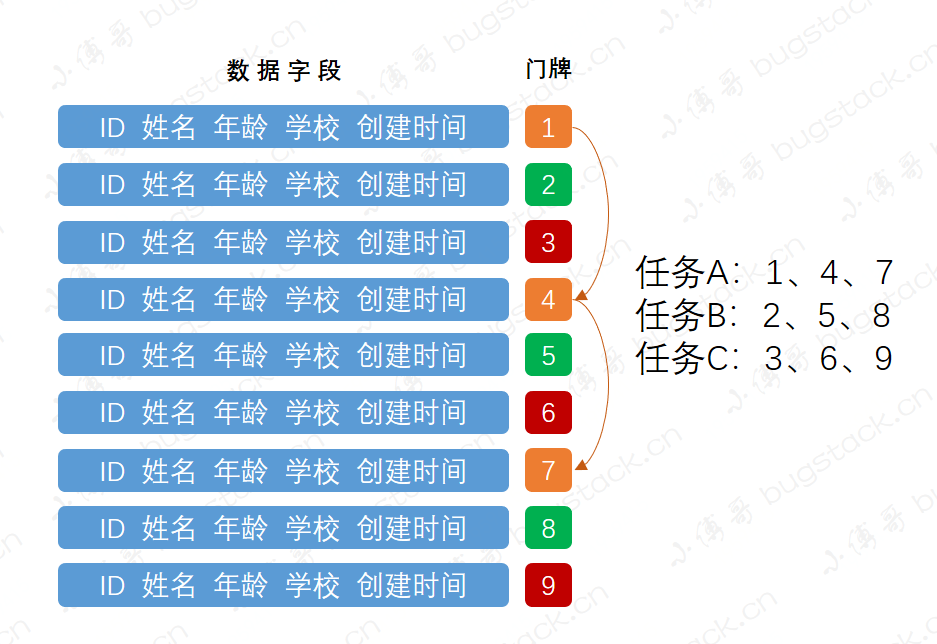
那么怎么优化呢,其实优化也比较简单,需要先根据状态查询到符合条件的最小的id,之后再sql的查询条件中添加id > xx,即可。另外如果你的任务需要多个worker扫描,增加效率,可以增加门牌号设计,提升扫描效率,如下;
10. 结伴编程
评审代码最后这点想说说,陪伴式开发,可能这不是结伴编程,不是共同合作,而是一个研发需要另外一个研发不断的提供帮助。有时候可能就是很简单的问题,也不想查,或者说没有意识去查,只是问。
业务开发的过程,只要把流程定下来,研发设计评审完,其他的开发过程中遇到的小点并不难,只要查一查就可以搞定。当日也不是说完全不能问,只不过特别普遍,简单的代码问题,自己搞定就可以了,但这个时候还像保姆似的陪伴,就会拖累整个团队的进展,最终大家都需要扛起那个慢的。
所以,如果你是那个需要陪伴的,要及早断奶,学会自己攻克,快速成长。而如果你是那个卷纸,可哪擦屁股的,要把卷纸传递给他。一个人擦一次是能力体现,反反复复擦一个人,就惹屎上身了。
四、总结
- 以上介绍了代码评审中涉及到的比较常见的点,基本也是很多研发容易忽略和犯错误的地方。这些问题点但拿出哪一个看,都不大。但运行在代码中,确都有可能发生致命或者麻烦的事情。
- 想让自己能把代码写好,就不只面试时候造飞机的回答,什么时间复杂度、什么可重入锁、什么红黑树,什么DDD,只要你不能正确的落地和运用这些技术,说的再多都是空谈。
- 多学一些、多看一些、多问一些,没有坏处,但要自己能成长,把吸取到的经验心得,运用到业务开发中,写出可扩展、可维护的代码,才能让自己真的升职加薪。也能让既有留下的本事,也有出去的能力。
五、系列推荐
- 握草,你竟然在代码里下毒!
- DDD领域驱动设计落地方案
- 重学Java设计模式(22个真实开发场景) 面经手册(上最快的车
- 拿最贵的offer) 字节码编程(非入侵式全链路监控实践)
Java日志Log4j或者Logback的NDC和MDC功能
01
NDC和MDC的区别
Java中使用的日志的实现框架有很多种,常用的log4j和logback以及java.util.logging,而log4j是apache实现的一个开源日志组件(Wrapped implementations),logback是slf4j的原生实现(Native implementations)。需要说明的slf4j是Java简单日志的门面(The Simple Logging Facade for Java),如果使用slf4j日志门面,必须要用到slf4j-api,而logback是直接实现的,所以不需要其他额外的转换以及转换带来的消耗,而slf4j要调用log4j的实现,就需要一个适配层,将log4j的实现适配到slf4j-api可调用的模式。
说完基本的日志框架的区别之后,我们再看看NDC和MDC。
不管是log4j还是logback,打印的日志要能体现出问题的所在,能够快速的定位到问题的症结,就必须携带上下文信息(context information),那么其存储该信息的两个重要的类就是NDC(Nested Diagnostic Context)和MDC(Mapped Diagnositc Context)。
NDC采用栈的机制存储上下文,线程独立的,子线程会从父线程拷贝上下文。其调用方法如下:
1.开始调用 NDC.push(message); 2.删除栈顶消息 NDC.pop(); 3.清除全部的消息,必须在线程退出前显示的调用,否则会导致内存溢出。NDC.remove(); 4.输出模板,注意是小写的[%x] log4j.appender.stdout.layout.ConversionPattern=[%d{yyyy-MM-dd HH:mm:ssS}] [%x] : %m%n
MDC采用Map的方式存储上下文,线程独立的,子线程会从父线程拷贝上下文。其调用方法如下:
1.保存信息到上下文 MDC.put(key, value); 2.从上下文获取设置的信息 MDC.get(key); 3.清楚上下文中指定的key的信息 MDC.remove(key); 4.清除所有 clear() 5.输出模板,注意是大写[%X{key}] log4j.appender.consoleAppender.layout.ConversionPattern = %-4r [%t] %5p %c %x - %m - %X{key}%n
最后需要注意的是:
- Use %X Map中全部数据
- Use %X{key} 指定输出Map中的key的值
- Use %x 输出Stack中的全部内容
02
MDC的使用例子
//MdcUtils.java
// import ...MdcConstants
// 这个就是定义一个常量的类,定义了SERVER、SESSION_ID等
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
public class MdcUtils {
private final static Logger logger = LoggerFactory.getLogger(MdcUtils.class);
private static void put(String key, Object value) {
if (value != null) {
String val = value.toString();
if (StringUtils.isNoneBlank(key, val)) {
MDC.put(key, val);
}
}
}
public static String getServer() {
return MDC.get(MdcConstants.SERVER);
}
public static void putServer(String server) {
put(MdcConstants.SERVER, server);
}
public static String getSessionId() {
return MDC.get(MdcConstants.SESSION_ID);
}
public static void putSessionId(String sId) {
put(MdcConstants.SESSION_ID, sId);
}
public static void clear() {
MDC.clear();
logger.debug("mdc clear done.");
}
}
上述工具类中MdcConstants是定义一个常量的类,定义了SERVER、SESSION_ID等,put方法就是调用了slf4j的MDC的put方法。其他方法类比。
看看使用该工具类的具体方式:
// MdcClearInterceptor.java
import ...MdcUtils;
// 导入上面的工具类
import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;i
mport javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MdcClearInterceptor extends HandlerInterceptorAdapter {
@Override
public void afterConcurrentHandlingStarted(HttpServletRequest request, HttpServletResponse response, Object handler)throws Exception {
MdcUtils.clear();
}
}
在该拦截器中,重写了afterConcurrentHandlingStarted方法,该方法执行了工具类的clear方法,也就是通过调用slf4j的clear方法清除了本次会话上下文的日志信息。为什么要放在afterConcurrentHandlingStarted方法中呢?这恐怕得从springmvc的拦截器的实现说起。
springmvc的拦截HandlerInterceptor接口定义了三个方法(代码如下),具体说明在方法注释上:
public interface HandlerInterceptor {
//在控制器方法调用前执行
//返回值为是否中断,true,表示继续执行(下一个拦截器或处理器)
//false则会中断后续的所有操作,所以我们需要使用response来响应请求
boolean preHandle(
HttpServletRequest request, HttpServletResponse response,
Object handler)
throws Exception;
//在控制器方法调用后,解析视图前调用,我们可以对视图和模型做进一步渲染或修改
void postHandle(
HttpServletRequest request, HttpServletResponse response,
Object handler, ModelAndView modelAndView)
throws Exception;
//整个请求完成,即视图渲染结束后调用,这个时候可以做些资源清理工作,或日志记录等
void afterCompletion(
HttpServletRequest request, HttpServletResponse response,
Object handler, Exception ex)
throws Exception;
}
很多时候,我们只需要上面这3个方法就够了,因为我们只需要继承HandlerInterceptorAdapter就可以了,HandlerInterceptorAdapter间接实现了HandlerInterceptor接口,并为HandlerInterceptor的三个方法做了空实现,因而更方便我们定制化自己的实现。
相对于HandlerInterceptor,HandlerInterceptorAdapter多了一个实现方法afterConcurrentHandlingStarted(),它来自HandlerInterceptorAdapter的直接实现类AsyncHandlerInterceptor,AsyncHandlerInterceptor接口直接继承了HandlerInterceptor,并新添了afterConcurrentHandlingStarted()方法用于处理异步请求,当Controller中有异步请求方法的时候会触发该方法时,异步请求先支持preHandle、然后执行afterConcurrentHandlingStarted。异步线程完成之后执行preHandle、postHandle、afterCompletion。
那至于这些可能用到的日志字段从什么地方赋值呢,也就是什么地方调用MDCUtils.put()方法呢?一般我们都会实现一个RequestHandlerInterceptor,在preHandler方法中处理日志字段即可。如下:
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
if (DispatcherType.ASYNC.equals(request.getDispatcherType())) {
return true;
}
// 开始保存信息到日志上下文
MdcUtils.putServer(request.getServerName());
String sId = request.getHeader(HeaderConstants.SESSION_ID);
MdcUtils.putSessionId(sId);
if (sessionWhiteList.contains(request.getPathInfo())) {
return true;
}
// TODO 处理其他业务
}
还没完,就目前看,我们已经有两个自定义的拦截器实现了。怎么使用,才能将日志根据我们的意愿正确的打印呢?必然,拦截器是有顺序的,如果配置了多个拦截器,会形成一条拦截器链,执行顺序类似于AOP,前置拦截先定义的先执行,后置拦截和完结拦截(afterCompletion)后注册的后执行。
Soga,我们需要清除上次请求的一些无用的信息,再次将我们的信息写入到MDC中(拦截器的配置在DispatcherServlet中),由于afterConcurrentHandlingStarted()方法需要异步请求触发,因此我们需要在web.xml的DispatchServlet配置增加<async-supported>true</async-supported>配置。
<mvc:interceptors>
<bean class="com.xxx.handler.MdcClearInterceptor"/>
<bean class="com.xxx.handler.RequestContextInterceptor"/>
</mvc:interceptors>
或者这样:
<mvc:interceptors>
<mvc:interceptor>
<bean class="com.xxx.handler.MdcClearInterceptor"/>
</mvc:interceptor>
<mvc:interceptor>
<bean class="com.xxx.handler.RequestContextInterceptor"/>
</mvc:interceptor>
</mvc:interceptors>
转发:https://www.cnblogs.com/xiaofuge/p/13671488.html+https://cloud.tencent.com/developer/article/1526878
