
爬虫综合大作业
这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 。
B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕。这次我的目的就是爬取B站视频的评论数据,分析某番剧为何会深受大家喜爱。
首先我通过B站大神的数据统计了解到,B站评论数量最多的番剧是《全职高手》。如下图所示:

通过数据可知《全职高手》这部番的第一集和最后一集分别占据了评论数量排行榜的第二名和第一名,远超越其他很多很火的番。于是我先去B站https://www.bilibili.com/bangumi/play/ep107656 ,发现这部番需要开通大会员才能观看。如下图所示:
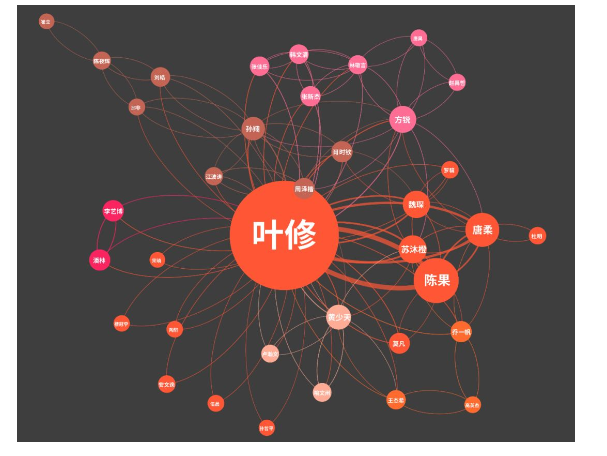
因为我不是B站大会员,看不了视频,我便百度百科了《全职高手》https://baike.so.com/doc/289439-27501474.html 。《全职高手》是一部游戏竞技类的番,故事讲述网游荣耀中被誉为教科书级别的顶尖高手叶修,因为种种原因遭到俱乐部的驱逐,离开职业圈的他寄身于一家网吧成了一个小小的网管。但是拥有十年游戏经验的他,在荣耀新开的第十区重新投入了游戏,带着对往昔的回忆和一把未完成的自制武器,开始了重返巅峰之路。下图是这部番剧中的人物关系图:
虽然视频看不了,评论和相关回复却是可以看的。如下图所示:

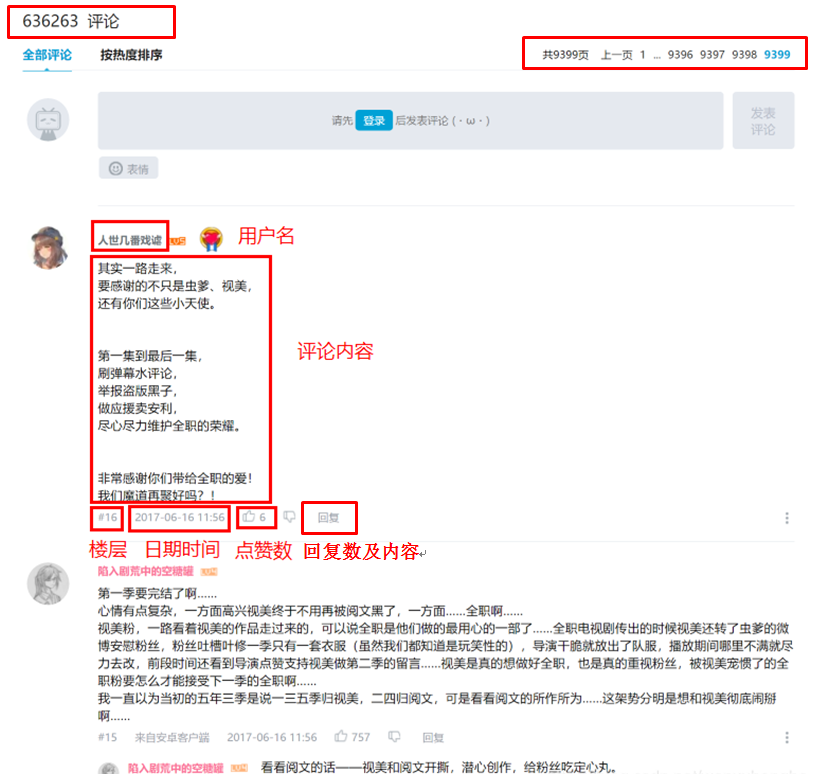
63w6条!9k多页的评论!由于数据量实在庞大,每条数据一一查看显然不现实,我就开始编写爬虫爬取所需数据。
使用Python爬取网页一般分为五个阶段,接下来我将按步骤分析并爬取评论数据,分析番剧《全职高手》大火的原因。
1. 分析目标网页
首先我观察评论区结构,发现评论区为鼠标点击翻页形式,共9399页数据,每一页有20条评论,每条评论包含用户名、评论内容、评论楼层、时间日期、点赞数等用户个人信息。如下图所示:
接着我打开开发者工具,用鼠标点击评论翻页,观察这个过程变化。
我发现整个过程中URL不变,说明评论区翻页不是通过URL控制,而在每翻一页时,网页会向服务器发出Request URL的请求。如下图所示:

点击Preview栏,切换到预览页面,可以看到这个请求返回的最终结果。下面是该请求返回的json文件,包含了本页在replies里的评论数据。这个json文件里包含了很多信息,除了网页上展示的信息,还有很多未展示的信息。如下图所示:


2.获取网页内容
现在正式写代码来爬取数据------访问目标url的网页,获取目标网页的html内容并返回。代码如下:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url,headers=headers)
r.raise_for_status()
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
if __name__ == '__main__':
url = 'https://api.bilibili.com/x/v2/reply?callback=jQuery172020326544171595695_1541502273311&jsonp=jsonp&pn=2&type=1&oid=11357166&sort=0&_=1541502312050'
html = fetchURL(url)
print(html)
运行结果如下图所示:
运行后发现网页出错,服务器拒绝了我们的访问。
同理,这个请求放浏览器地址栏里面直接打开,网页出错,服务器拒绝访问,什么内容都看不到。如下图所示:

查阅许多相关资料https://baike.so.com/doc/5438832-5677151.html之后,我找到了解决方法。原请求的URL有callback 、jsonp、pn、type、oid和
_ = 共六个参数。其中,真正有用的参数只有三个:pn(页数)、type(=1)和oid(视频id)。删除其余不必要的参数后,用新整理出的URL访问服务器,成功获取到评论数据。如下图所示:
在主函数中,通过写一个for循环来改变pn(页数)的值,获取每一页的评论数据。
if __name__ == '__main__': for page in range(0,9400): url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=' + str(page) html = fetchURL(url)
3.提取关键信息
通过json库对获取的响应内容进行解析,接着提取所需的信息,即楼层、用户名、性别、时间、评价、点赞数和回复数。代码如下:
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ import requests import json import time def fetchURL(url): ''' 功能:访问 url 的网页,获取网页内容并返回 参数: url :目标网页的 url 返回:目标网页的 html 内容 ''' headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } try: r = requests.get(url,headers=headers) r.raise_for_status() print(r.url) return r.text except requests.HTTPError as e: print(e) print("HTTPError") except requests.RequestException as e: print(e) except: print("Unknown Error !") def parserHtml(html): ''' 功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容 参数: html:类似文件的内存 HTML 文本对象 ''' s = json.loads(html) for i in range(20): comment = s['data']['replies'][i] # 楼层,用户名,性别,时间,评价,点赞数,回复数 floor = comment['floor'] username = comment['member']['uname'] sex = comment['member']['sex'] ctime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime'])) content = comment['content']['message'] likes = comment['like'] rcounts = comment['rcount'] print('--'+str(floor) + ':' + username + '('+sex+')' + ':'+ctime) print(content) print('like : '+ str(likes) + ' ' + 'replies : ' + str(rcounts)) print(' ') url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=3' html = fetchURL(url) parserHtml(html)
运行结果如下图所示:
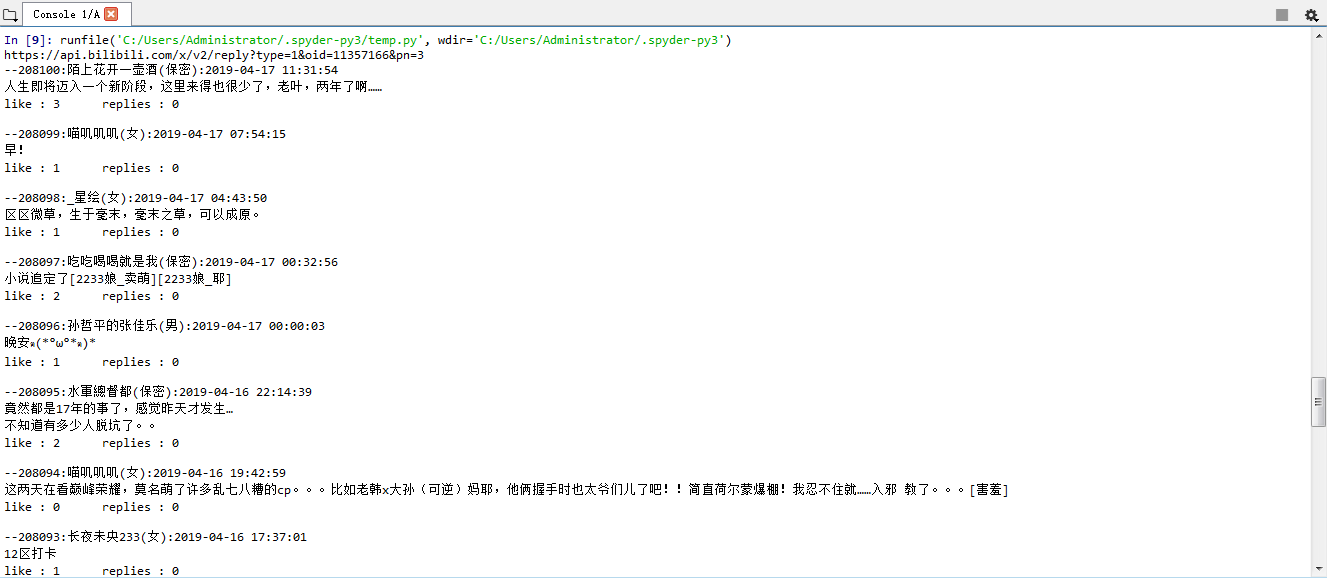
4.输出保存
爬取到想要的评论数据后,除了将其显示输出,还要将数据以csv格式保存于本地并存储到数据库中。项目部分代码如下:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests
import json
import time
import random
import pymysql
import pandas as pd
from sqlalchemy import create_engine
def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
# headers是为了把爬虫程序伪装成浏览器
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
# 请求标头中的所有信息都是headers内容,添加到requests请求中
try:
r = requests.get(url,headers=headers) # 发送请求,获取某个网页
r.raise_for_status() # 如果发送了一个错误请求(客户端错误或者服务器错误响应),可以通过r.raise_for_status()来抛出异常
print(r.url)
return r.text
except requests.HTTPError as e: # 如果HTTP请求返回了不成功的状态码,r.raise_for_status()会抛出一个 HTTPError异常
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
# 抛异常处理
def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
try:
s = json.loads(html) # json.load()主要用来读写json文件函数:json.loads函数的使用,将字符串转化为字典
except:
print('error')
commentlist = []
hlist = []
# 列表append()方法用于将传入的对象附加(添加)到现有列表中
hlist.append("序号")
hlist.append("名字")
hlist.append("性别")
hlist.append("时间")
hlist.append("评论")
hlist.append("点赞数")
hlist.append("回复数")
#commentlist.append(hlist)
# 楼层,用户名,性别,时间,评价,点赞数,回复数
for i in range(20): # 每页只有20条评论,循环20次
comment = s['data']['replies'][i]
blist = []
floor = comment['floor']
username = comment['member']['uname']
sex = comment['member']['sex']
ctime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime']))
content = comment['content']['message']
likes = comment['like']
rcounts = comment['rcount']
blist.append(floor)
blist.append(username)
blist.append(sex)
blist.append(ctime)
blist.append(content)
blist.append(likes)
blist.append(rcounts)
commentlist.append(blist)
writePage(commentlist)
print('---'*20)
def writePage(urating):
'''
Function : To write the content of html into a local file
html : The response content
filename : the local filename to be used stored the response
'''
# Pandas读取本地CSV文件并设置Dataframe(数据格式),将爬取数据保存到本地CSV文件。加上mode='a' 追加写入数据;sep=','表示数据间使用逗号作为分隔符;不保存列名和行索引
dataframe = pd.DataFrame(urating)
dataframe.to_csv('B_comments.csv', mode='w', index=False, sep=',', header=False)
# 将爬取数据保存到数据库中
conInfo = "mysql+pymysql://root:@localhost:3306/comments?charset=utf8"
engine = create_engine(conInfo,encoding='utf-8')
dataframe.to_sql(name='comment',con=engine,if_exists='append',index=False,index_label='id')
pymysql.connect(host='localhost',port=3306,user='root',passwd='',db='comments',charset='utf8')
# 循环输出9399页,共188454条评论数据内容
if __name__ == '__main__':
for page in range(0,9400):
url = 'https://api.bilibili.com/x/v2/reply?type=1&oid=11357166&pn=' + str(page)
html = fetchURL(url)
parserHtml(html)
# 为了降低被封ip的风险,设置合理的爬取间隔,每爬20页便随机歇1~5秒。
if page%20 == 0:
time.sleep(random.random()*5)
运行结果如下图所示:
数据保存如下图所示(相关文件保存在文件夹):

5.数据分析
数据的可视化分析:(Pyecharts)
注意:得到数据之后要先对数据进行清洗和预处理再进行数据的统计分析。代码如下:
from pyecharts import Pie attr = ['男','女','保密'] value= [31129,63123,93748] pie = Pie('《全职高手》评论性别比例', title_pos='center', width=900) pie.add("7-17", attr, value, center=[75, 50], is_random=True, radius=[30, 75], rosetype='area', is_legend_show=False, is_label_show=True) pie.render('./网友评论性别.html')
运行结果如下图所示: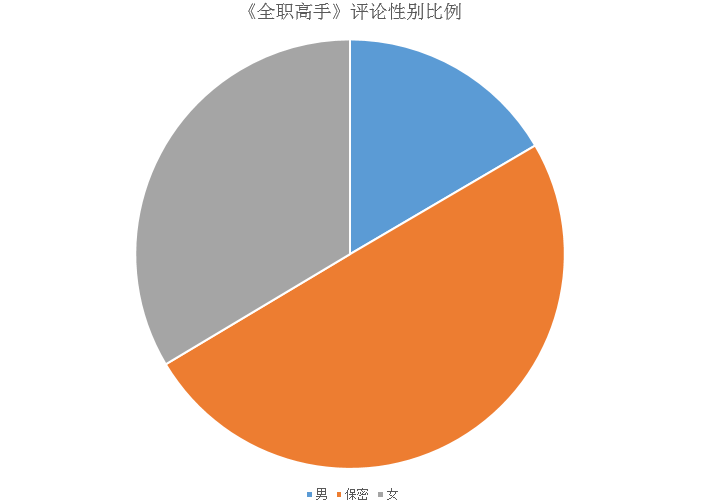
可以看出,这类讲网游的动漫,不仅深受大众喜爱,而且女生尤其喜欢,这部番剧观看人数女生还远超男生呢。
词云分析:(jieba)
代码如下:
import jieba # 导入matplotlib,用于生成2D图形 import matplotlib.pyplot as plt # 导入wordcount,用于制作词云图 from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator # 获取所有评论 comments = [] with open('B_comments.csv', mode='r', encoding='utf-8') as f: rows = f.readlines() for row in rows: comment = row.split(',')[3] if comment != '': comments.append(comment) # 设置分词 comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false words = " ".join(comment_after_split) # 以空格进行拼接 # print(words) # 设置屏蔽词 stopwords = STOPWORDS.copy() stopwords.add("电影") stopwords.add("一部") stopwords.add("一个") stopwords.add("没有") stopwords.add("什么") stopwords.add("有点") stopwords.add("这部") stopwords.add("这个") stopwords.add("不是") stopwords.add("真的") stopwords.add("感觉") stopwords.add("觉得") stopwords.add("还是") stopwords.add("但是") stopwords.add("就是") # 导入背景图 bg_image = plt.imread('bg.jpg') # 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小 wc = WordCloud(width=1024, height=768, background_color='white', mask=bg_image, font_path='STKAITI.TTF', stopwords=stopwords, max_font_size=400, random_state=50) # 将分词后数据传入云图 wc.generate_from_text(words) plt.imshow(wc) plt.axis('off') # 不显示坐标轴 plt.show() # 保存结果到本地 wc.to_file('词云图.jpg')
运行结果如下图所示:

可以看出,全职、荣耀、君莫笑、叶修、叶神等剧情里面的重要事件和人物都是评论里常提及的词语,“啊啊啊”也出现非常多,是因为大部分人在上线观剧后都会发出巨多的感叹词表示激动之情。

除此之外,分析用户个人昵称,还会发现这里面有许多死忠粉,在昵称里面会采用和《全职高手》相关信息。比如,“叶修、陈果、唐柔、苏沐橙......”是剧中人物名字,“君莫笑、毁人不倦、寒烟柔......”是人物游戏角色昵称。而其余角色如黄少天、蓝河、魏琛等都是主角叶修的好友,也是网络上主角的同性cp对象。此外,像“BOSS、团队、治疗、战术、节奏、属性、武器、神之领域......”则是游戏本身或游戏过程中的一些重要名词。
总结:
爬取用户评论数据后,分析可知《全职高手》这部番剧如此受青睐的原因有:首先,它是根据蝴蝶蓝编写的同名小说《全职高手》改编,吸引一大批书迷去观看。其次,故事所揭露的正是当今社会的一些现象和人文理念,引发观众共鸣。再加上制作精良且有国内老牌动画制作公司视美精典保驾护航,许多观众都给予很高的评价,堪称“国漫神作”。
在本次作业爬取B站最受喜爱番剧20w评论数据过程中,我遇到了不少困难。譬如:
(1)请求的网页url不能直接用,需要对参数进行筛选整理后才能访问网页。
(2)爬取过程并不顺利,因为如果爬取期间有用户发表评论,则请求返回的响应会为空,导致程序出错。所以在实际爬取过程中,需记录爬取的位置,以便出错之后从该位置继续爬取。此外,挑选发帖人数少的时间段爬取数据,可以极大程度降低程序出错的机率。
(3)爬取到的数据有多处不一致,主要原因有------评论区楼层只到了20w,但是评论数量却有63w6条,数目不一致是由于B站的评论是可以回复的,回复的评论也会计算到总评论数里。我只爬取了楼层的评论,而相应的回复内容则忽略,只需统计回复数量。另外,评论区楼层有20w条,但是最后爬取的数据只有18w条,这是因为有删评论的情况。评论删除后,后面的楼层并不会重新排序,而是把删掉的那层空下了,导致楼层数和评论数不一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号