

1. 底层基础概念
CIL(Common Intermediate Language) 中间语言(C# VB 最终编译成CIL语言)
BCL(Base Class Library) 基础类库 (System 类库这样的最基层类库)
FCL (Framework Class Library) 微软类库 (包括基层类库等微软提供的所有类库)
CTS(Class Type System) 公共类型规范 (最基本的语言规定,比如string class 这些蓝色关键字)
CLS(Common Language Specification)公共语言规范 (基于CIL语法的规范做法)
CLR(Common Language Runtime).net运行托管(.net程序的虚拟机,基于window上)
资料参考:
http://www.tracefact.net/CLR-and-Framework/DotNet-Framework.aspx
2. 泛型简单理解
泛型集合List<T>
泛型的意义何在?类型安全和减少装箱、拆箱并不是泛型的意义,而是泛型带来的两个好处而已(或许在.net泛型中,这是最明显的好处了)。泛型的意义在于 ——把类型作为参数,它实现了代码之间的很好的横向联系,我们知道继承为代码提供了一种从上往下的纵向联系,但泛型提供了方便的横向联系(从某种程度上说,它和AOP在思想上有相通之处)。在PersonCollection例子中,我们知道Add()方法和Remove()方法的参数类型相同,但我们明确无法告诉我们的程序这一点,泛型提供了一种机制,让程序知道这些。道理虽然简单,但这样的机制或许能给我们的程序带来一些深远的变化吧。
泛型的Where能够对类型参数作出限定。有以下几种方式。
l where T : struct 限制类型参数T必须继承自System.ValueType。
l where T : class 限制类型参数T必须是引用类型,也就是不能继承自System.ValueType。
l where T : new() 限制类型参数T必须有一个缺省的构造函数
l where T : NameOfClass 限制类型参数T必须继承自某个类或实现某个接口。
以上这些限定可以组合使用,比如:
public class Point<T> where T : class, IComparable, new()

//泛型应用 public class Person<T>//创建泛型类 { private T temp; public Person(T nameAge) { this.temp = nameAge; } public void Read() { Console.WriteLine(temp); } } static void Main(string[] args) { Person<string> personName = new Person<string>("jack"); //string类型名字 Person<int> personAge = new Person<int>(15); //int类型名字 personName.Read();//输出jack personAge.Read();//输出15 for (;;) ; }
//泛型类集合 public class Person { private string name; public Person(string oneName)//构造函数 { name = oneName; } public void SayHello(){ Console.WriteLine("Hello" + name); } } static void Main(string[] args) { List<Person> colPerson = new List<Person>(); //创建集合类 colPerson.Add(new Person("jack")); colPerson.Add(new Person(“jhon”));//添加集合类 foreach (Person aPerson in colPerson) aPerson.SayHello();//输出Hellojack Hellojhon Person smith = new Person("smith"); colPerson.Add(smith); Console.WriteLine(colPerson.Contains(smith));//输出true for (;;) ; }
3.数据库索引
参考资料:http://www.cnblogs.com/huangxincheng/p/4243080.html
1.主键建立的时候 会自动创建唯一索引 类型是聚集
2.插入三百万数据 查询 like 某一个字符需要7秒 (返回一百多万条数据)
3.加入 非聚集索引 速度提升到5秒(返回一百多万条数据)
CREATE NONCLUSTERED INDEX Index_USer_Name ON [dbo].[User] (Name)
4.索引的语法
CREATE [UNIQUE][CLUSTERED | NONCLUSTERED] INDEX index_name
ON {table_name | view_name} [WITH [index_property [,....n]]
说明:
UNIQUE: 建立唯一索引。
CLUSTERED: 建立聚集索引。
NONCLUSTERED: 建立非聚集索引。
Index_property: 索引属性。
UNIQUE索引既可以采用聚集索引结构,也可以采用非聚集索引的结构,如果不指明采用的索引结构,则SQL Server系统默认为采用非聚集索引结构。
1.42 删除索引语法:
DROP INDEX table_name.index_name[,table_name.index_name]
说明:table_name: 索引所在的表名称。
index_name : 要删除的索引名称。
1.43 显示索引信息:
使用系统存储过程:sp_helpindex 查看指定表的索引信息。
执行代码如下:
Exec sp_helpindex book1;
测试代码
--truncate table [dbo].[User]
--DECLARE @i int
--Set @i = 1
--WHILE @i < 3000000
--BEGIN
--Set @i =@i +1
--insert into [dbo].[User] values(('A'+Convert(nvarchar,@i)),18,('A'+Convert(nvarchar,@i)))
--End
select * from [dbo].[User] where id=168
dbcc dropcleanbuffers
set statistics io on
select Name from [dbo].[User] where Name like 'A1%'
set statistics io off
select Count(1) from [dbo].[User]
CREATE NONCLUSTERED INDEX Index_USer_Name ON [dbo].[User] (Name)
Exec sp_helpindex [User];
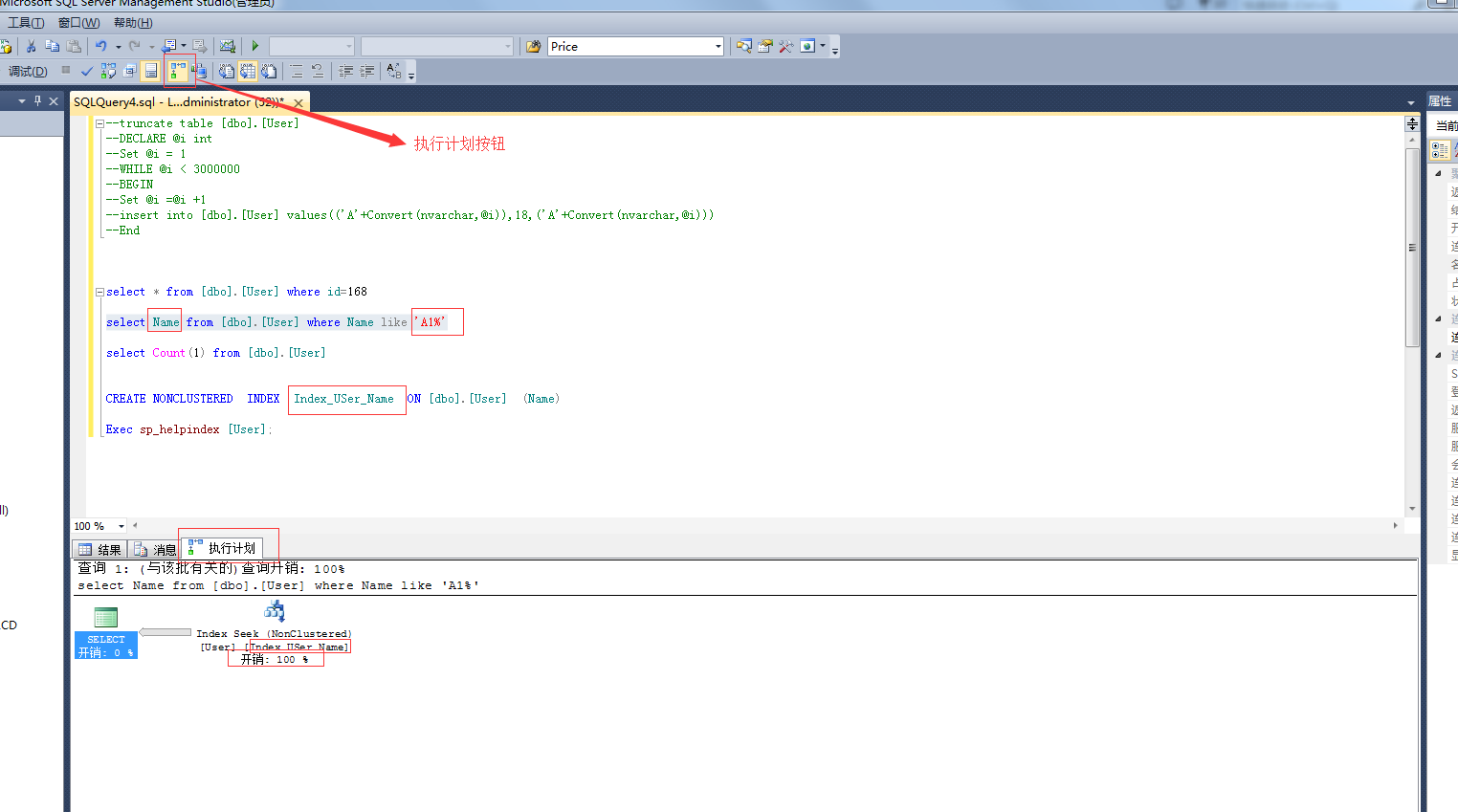
没加索引IO次数对比
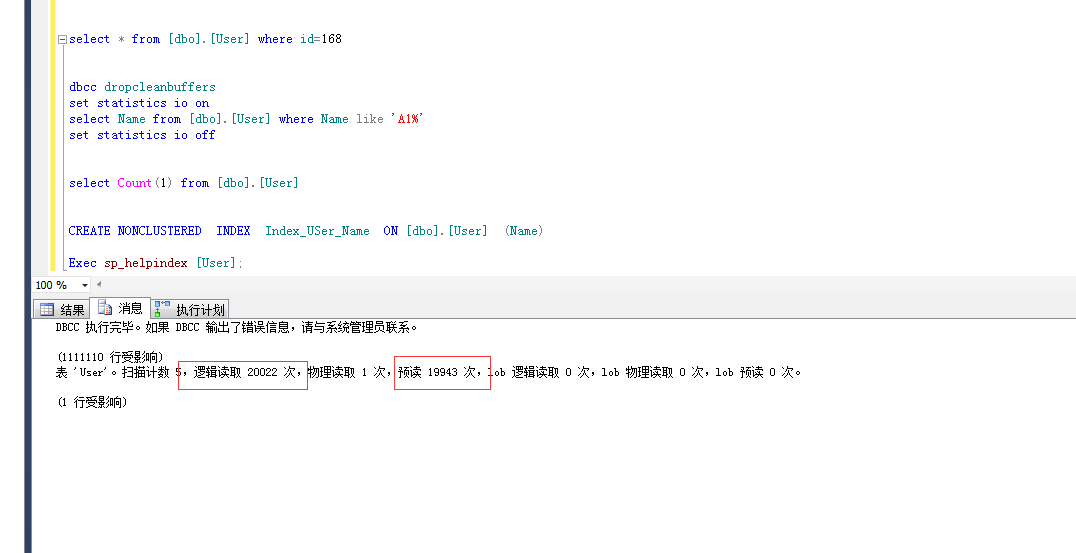
加了索引
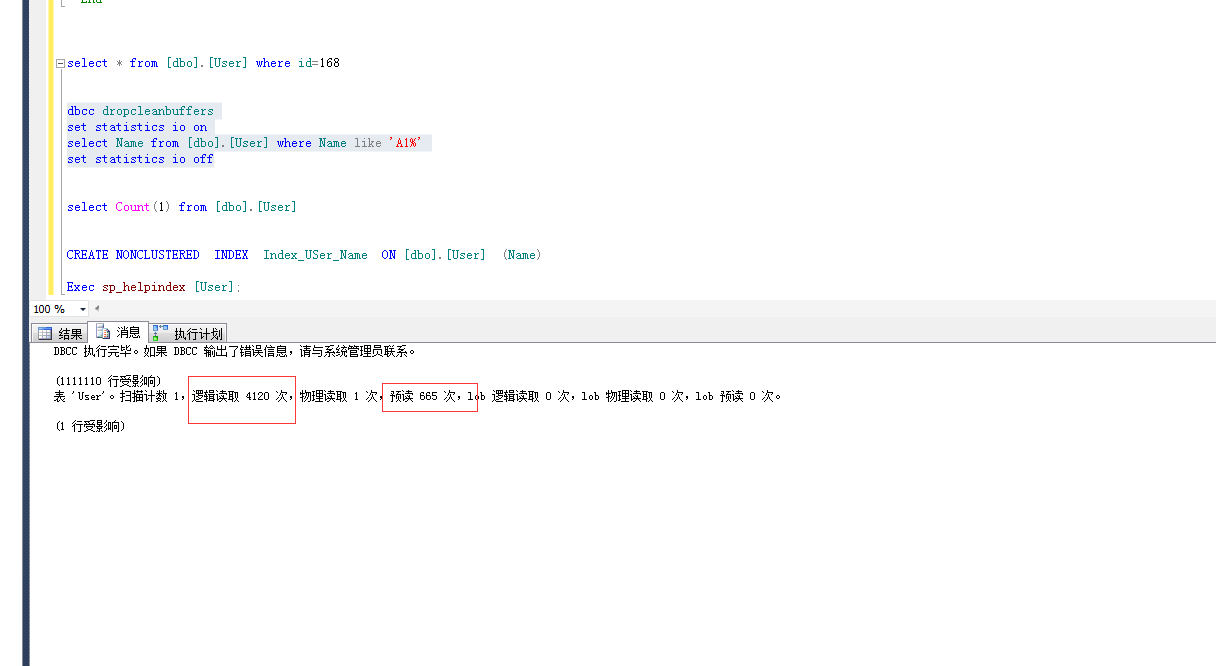
顺便补充下 数据库存储知识,数据库存储是由页组成的 一页等于8k
查询数据存在哪一页
dbcc ind 命令 (DBCC 数据库控制台命令)
5.数据库锁
学习锁之前,必须要知道锁大概有几种???通常情况下作为码农我们只需知道如下几个锁即可。。。
1.S(Share)锁
为了方便理解,我们可以直接这么认为,当在select的时候在表,数据页,记录上加上共享锁。
2.X(Exclusive) 锁
我们在delete数据的时候会在记录上附加X锁,我们知道X锁并不与其他的锁兼容。如果其他的锁与其遭遇,就会处于等待,后续我们再说。
3.U(Update)锁
顾名思义,我们在Update的时候,在寻找记录的过程中,会逐一的给记录附加U锁,如果找到了目标记录的话,则会将U锁转化为X锁。。。
4.I (Intent)锁
这个就是所谓的意向锁,一般都是给表和数据页附加的锁,好处就是防止被其他连接修改表结构。
总得来说,每个操作SQLSERVER都会自动的加入锁定机制。
最常见的是当某一条件下的数据在被查询的时候,另一个相关的数据请求会导致等待,原因是SQL为了防止脏读
,但是我们的业务逻辑经常是允许脏读,然后在后台做最后的判断,针对10:1的读写,很多码农可能都会遇到类似神乎其神的死锁,卡住,
读不出来,插不进入等等神仙的事情导致性能低下,这个时候 我们的查询语句就要指定解锁动作
比如 上面的情况 有两种优化方案
1.加入索引
2.加入解锁语句
SELECT * FROM xx 表 WITH(NOLOCK) where 条件
操作锁的动作种类如下
粒度锁:PAGLOCK(数据页锁), TABLOCK(表锁), TABLOCKX(表X锁), ROWLOCK(行锁), NOLOCK(无锁模式)
模式锁:HOLDLOCK(整个事务中持有锁), UPDLOCK(加了UPDATE就得等), XLOCK(排斥X锁)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2014-04-01 ipad safari 滚动(overflow)解决方案