
【学习笔记】数学
数学
大概就是一个数学知识的梳理,可能会有一些地方写的并不是很全很好,未来可能会补。
模意义下的数论
欧几里得算法
扩展欧几里得算法
求解:
分析:
设 ax1+by1=gcd(a,b)ax1+by1=gcd(a,b),bx2+(a%b)y2=gcd(b,a%b)bx2+(a%b)y2=gcd(b,a%b)。
根据欧几里得算法则 gcd(a,b)=gcd(b,a%b)gcd(a,b)=gcd(b,a%b),也就是说:
根据 a%b=a−⌊ab⌋×ba%b=a−⌊ab⌋×b,则有:
化简一下就有:
必然存在一组解为 x1=y2,y1=x2−⌊ab⌋×b×y2x1=y2,y1=x2−⌊ab⌋×b×y2
不断递归下去,当 b=0b=0 时使用 x=1,y=0x=1,y=0 作为一组解然后回溯即可。
费马小定理
对于素数 pp,若 gcd(a,p)=1gcd(a,p)=1,则有:
欧拉定理
若 gcd(a,p)=1gcd(a,p)=1,则有:
扩展欧拉定理
中国剩余定理
问题描述:
求一组解:
其实满足 m1,m2,⋯,mnm1,m2,⋯,mn 两两互质
问题分析:
令 M=∏ni=1aiM=∏ni=1ai。
对于第 ii 个方程,令 pi=Mmipi=Mmi,计算 pipi 在模 mimi 意义下的逆元 p−1ip−1i,令 ci=pip−1ici=pip−1i(不对 mimi 取模)。
则答案为 x=∑ni=1ciaimodMx=∑ni=1ciaimodM
扩展中国剩余定理
考虑合并两个方程:
可以将它们转化为不定方程即:
转化一下即 m1p−m2q=a2−a1m1p−m2q=a2−a1,根据裴蜀定理当 a2−a1a2−a1 不能被 m1−m2m1−m2 整除时无解,否则可以通过扩展欧几里得算法得到一组解 p,qp,q。
这样的话就可以将原方程组合并为:x≡bmodMx≡bmodM,其中 b=m1p+a1,M=lcm(m1,m2)b=m1p+a1,M=lcm(m1,m2)
Wilson 定理
pp 为素数的充要条件为 (p−1)!≡−1modp(p−1)!≡−1modp
Kummer 定理
形式一:pp 在 (nm)(nm) 中的幂次,等于 pp 进制下 n−mn−m 需要的借位次数
形式二:pp 在 (n+mm)(n+mm) 中的幂次,等于 pp 进制下 n+mn+m 的进位次数
Lucas 定理
若有两个正整数 n,mn,m 和一个素数 pp,则有:
感性的理解就是拆到 pp 进制下,然后每一位单独考虑。
阶
定义: 对于 a∈Z,m∈N∗a∈Z,m∈N∗,若 (a,m)=1(a,m)=1,则满足 an≡1(modm)an≡1(modm) 的最小正整数 nn 称为 aa 模 mm 的阶,记为 δm(a)δm(a) 或 ordm(a)ordm(a)。
性质一: a1,a2,⋯,aδm(a)a1,a2,⋯,aδm(a) 模 mm 两两不同余。
- 证明:考虑使用反证法,若存在 i≠ji≠j 满足 ai≡aj(modm)ai≡aj(modm),则必然有 a|i−j|≡1(modm)a|i−j|≡1(modm),而 0<|i−j|<δm(a)0<|i−j|<δm(a) 与定义冲突。
性质二: 若 an≡1(modm)an≡1(modm),则必然有 δm(a)|nδm(a)|n。以及据此可以推出若 ap≡aqap≡aq,则 p≡q(modδm(a))p≡q(modδm(a))
性质三: δm(ab)=δm(a)δm(b)δm(ab)=δm(a)δm(b) 的充要条件为 (δm(a),δm(b))=1(δm(a),δm(b))=1。
性质四: δm(ak)=δm(a)(δm(a),k)δm(ak)=δm(a)(δm(a),k)
所以根据上面这些性质,阶就给了人一种“循环节”的感觉。
原根
若 δm(g)=φ(m)δm(g)=φ(m),则称 gg 为模 mm 意义下的原根。
性质一: gg 是模 mm 意义下的原根的充要条件为,对于 φ(m)φ(m) 的每个质因数 pp,都有 gφ(m)p≢1(modm)gφ(m)p≢1(modm)
性质二: 若模 mm 意义下有原根,则原根个数为 φ(φ(m))φ(φ(m))
性质三: 数 mm 存在原根当且仅当 m=2,4,pα,2pαm=2,4,pα,2pα,其中 pp 为奇质数,α∈N∗α∈N∗
性质四: 最小原根的值为 O(n0.25)O(n0.25),可以暴力。
BSGS
满足 (a,p)=1(a,p)=1,求解下列方程的解:
考虑按 tt 分块,也就是将上述式子改写为:
移一下项也就是:
所以就可以直接预处理 a0,a1,⋯,at−1a0,a1,⋯,at−1,然后枚举 ii,通过 hash 判断预处理的数里面是否存在 b×a−itb×a−it 即可。
显然当 t=√pt=√p 时复杂度最优,为 O(√p)O(√p)。
exBSGS
不满足 (a,p)=1(a,p)=1,求解下列方程的解:
想法就是将这个方程转化为 (a,p)=1(a,p)=1。
首先这个方程显然可以转化为:
设 (a,p)=d(a,p)=d,根据裴蜀定理这个式子有解当且仅当 d∣bd∣b,所以不合法直接判无解。
这样的话这个式子就可以转化为:
此时可以令 ax−1→ax,pd→p,bd→bax−1→ax,pd→p,bd→b,这样一直递归下去,直到 (a,p)=1(a,p)=1。
设总共递归了 cntcnt 次,递归过程中 dd 的乘积为 d′d′,则显然原式为:
此时直接令 a′=a,b′=bd′,p′=pd′a′=a,b′=bd′,p′=pd′,跑一遍 BSGS 然后将答案加 cntcnt 即可。
要注意此时左边式子会多一个 acntd′acntd′ 的系数,要记得乘上。
二次剩余
定义:
若 pp 为奇质数,且 (n,p)=1(n,p)=1,使得存在一个 xx 满足:
则称 nn 为模 pp 意义下的二次剩余,简称二次剩余,默认 n≥1n≥1。(顾名思义就是二次方后剩余的数)
二次剩余的数量:
考虑对于一个二次剩余 nn,考虑 x2≡n(modp)x2≡n(modp) 有多少个解。
若存在多个解,设其中两个解为 x0,x1x0,x1 且满足 x0≠x1x0≠x1,则有:
化简一下就是:
因为 x0≠x1x0≠x1,所以 x0−x1≠0x0−x1≠0,即要让上述式子为 00 则必然存在 x0+x1=0(modp)x0+x1=0(modp)
也就是模 pp 意义下的一对相反数对应一个二次剩余,因为 pp 为奇质数所以任意一对 x0,x1x0,x1 若满足 x0+x1=0x0+x1=0,则必然满足 x0≠x1x0≠x1,也就是说任意一对相反数都可以对应一个二次剩余。
还可以知道的是任意两对相反数所对应的两个二次剩余均不同,所以二次剩余的数量就是 p−12p−12,故非二次剩余的数量就是 p−12p−12
欧拉准则:
考虑怎么快速判断一个数 nn 是不是二次剩余。
考虑费马小定理,np−1≡1(modp)np−1≡1(modp),因为 pp 为奇质数,所以有 n2⋅p−12≡1(modp)n2⋅p−12≡1(modp),也就是说 np−12np−12 是 11 的开根,因为 11 的开根只有 11 或 −1−1,所以 np−12np−12 只可以为 11 或者 −1−1。
下面考虑证明 np−12≡1(modp)np−12≡1(modp) 与 nn 为二次剩余等价,也就是证明充分性和必要性。
充分性,也就是已知 np−12≡1(modp)np−12≡1(modp),设 gg 表示模 pp 意义下的原根,则可以令 n=gkn=gk,则有 gk⋅p−12≡1(modp)gk⋅p−12≡1(modp),有原根的性质可得 (p−1)∣k⋅p−12(p−1)∣k⋅p−12,也就是说 kk 一定是偶数,即我们可以将 kk 除以 22,所以 nn 就是可以开根的,开根后的结果就是 x=gk2x=gk2
必要性,也就是已知 nn 是二次剩余,np−12=(x2)p−12=xp−1np−12=(x2)p−12=xp−1,因为 xφ(p)≡1(modp)xφ(p)≡1(modp),所以 xp−1≡1(modp)xp−1≡1(modp),即 np−12≡1(modp)np−12≡1(modp)
所以就证明了 np−12≡1(modp)np−12≡1(modp) 与 nn 为二次剩余等价,所以当 np−12≡−1(modp)np−12≡−1(modp) 时 nn 就是非二次剩余。
Cipolla:
考虑求解 x2≡n(modp)x2≡n(modp)
首先找到一个 aa 使得 a2−na2−n 是非二次剩余,因为非二次剩余的数的个数接近 p2p2 所以期望两次找到。
定义 i2=a2−ni2=a2−n,下面就是关于怎么找到这个 ii。
可以类似复数域,定义这样的一个 ii,使得每一个数都可以被表示为 A+BiA+Bi,其中 A,BA,B 都是模 pp 意义下的。
下面考虑证明下面这个结论:
引理 11: ip≡−i(modp)ip≡−i(modp)
- 证明:ip=i(i2)p−12=i(a2−n)p−12=−iip=i(i2)p−12=i(a2−n)p−12=−i
引理 22: (A+B)p≡Ap+Bp(modp)(A+B)p≡Ap+Bp(modp)
- 证明:(A+B)p≡∑pi=0(pi)AiBp−i≡(pp)Ap+(p0)Bp≡Ap+Bp(modp)(A+B)p≡∑pi=0(pi)AiBp−i≡(pp)Ap+(p0)Bp≡Ap+Bp(modp)
有了这两个引理就可以证明了:
第二个等于号 ap≡a(modp)ap≡a(modp) 就是扩展欧拉定理。
因为 pp 为奇质数,所以 p+1p+1 为偶数,因此 nn 开方后的数就是 (a+i)p+12(a+i)p+12,即 xx 就是 (a+i)p+12(a+i)p+12
可以证明 (a+i)p+12(a+i)p+12 的 “虚部” 一定为 00。
使用反证法来证明这个结论,若存在 (A+Bi)2≡n(modp)(A+Bi)2≡n(modp) 且 B≠0B≠0,那么展开之后就是 A2+B2i2+2ABi≡n(modp)A2+B2i2+2ABi≡n(modp),因为右边"虚部"为 00 所以显然左边"虚部"为 00,即 AB=0AB=0,因为 B≠0B≠0,所以 A=0A=0,上面式子就可以化为 B2i2≡n(modp)B2i2≡n(modp),即 i2≡nB−2(modp)i2≡nB−2(modp),显然 B−2B−2 是一个二次剩余,而 nn 也是一个二次剩余,所以 nB−2nB−2 就是一个二次剩余,即 i2i2 是一个二次剩余,这与我们的假设 i2i2 不是一个二次剩余违背,故此这个结论不成立。
正整数中的数论
算术基本定理
内容: 对于任意一个大于 11 的自然数 NN,其一定可以被唯一分解为有限个质数的乘积。
标准分解式: N=∏mi=1pkiiN=∏mi=1pkii,满足 p1<p2<p3⋯<pmp1<p2<p3⋯<pm 且 p1,p2,p3,⋯,pmp1,p2,p3,⋯,pm 均为质数,kiki 均为正整数,将这样的分解称为 NN 的标准分解式。
p 进赋值序列: 记 vp(n)=max{k∈n∣pk∣n}vp(n)=max{k∈n∣pk∣n},则 nn 的 pp 进赋值序列为 {v2(n),v3(n),v5(n),v7(n),⋯}{v2(n),v3(n),v5(n),v7(n),⋯},即要求 pp 均为质数。
pp 进赋值序列可以帮助我们在数论的角度下刻画正整数,在 pp 进赋值序列下任何一个正整数都唯一对应一个高维平面上的点,该平面每一维对应一个素数。
gcdgcd 与 lcmlcm 就可以转化为高维平面上的 minmin 与 maxmax。
狄利克雷前缀和就对应高维前缀和,狄利克雷卷积就对应着高维和卷积。
莫比乌斯函数相当于高维差分的容斥系数。
素性检测和因数分解
素性检测就是在不对给定数进行质因数分解的情况下判断这个数是否为质数。
Miller–Rabin 素性测试
引理一:费马小定理
若 pp 为素数,aa 为整数,若 (a,p)=1(a,p)=1,则有 ap−1≡1(modp)ap−1≡1(modp)
费马小定理只是 pp 为素数的充分条件,如不成立则 pp 一定为合数,若成立则 pp 不一定为素数。
引理二:二次检测定理
若 pp 为素数,且 0<x<p0<x<p,则 x2≡1(modp)x2≡1(modp) 的解为 x=1x=1 或 x=p−1x=p−1
证明:
x2≡1(modp)⟹x2−1≡0(modp)⟹(x+1)(x−1)≡0(modp)⟹p∣(x+1)(x−1)x2≡1(modp)⟹x2−1≡0(modp)⟹(x+1)(x−1)≡0(modp)⟹p∣(x+1)(x−1)。
因为 pp 为质数,所以只有 x=1x=1 或 x=p−1x=p−1。
下面考虑给定 pp 判断其是否为素数。
我们将 p−1p−1 写成 2k×t2k×t 的形式,可以考虑随机一个数 aa,然后计算 at(modp)at(modp) 的值。
将这个数不断自乘,然后使用二次检测定理判断,也就是若当前的数为 AA 满足 A×A=1A×A=1 且 A≠1A≠1 且 A≠p−1A≠p−1,则 pp 不是素数。
这样乘 kk 次的结果就是 ap−1ap−1,这个时候只需要判断 ap−1≡1(modp)ap−1≡1(modp) 是否满足即可,如果不满足则一定不是素数。
这样检测的正确率是不低的,可以验证的是如果我们取前 1212 个素数作为 aa 进行检测则在 [1,264)[1,264) 内的数都不会出现问题。
时间复杂度就是 O(|a|log3n)O(|a|log3n)
代码实现如下:
点击查看代码
bool Miller(int P) {
if(P == 1) return 0;
int t = P - 1, k = 0;
while(!(t & 1)) k++, t >>= 1;
for(int i = 0; i < 12; i++) {
if(P == Test[i]) return 1;
LL a = pow(Test[i], t, P), nxt = a;
for(int j = 1; j <= k; j++) {
nxt = (a * a) % P;
if(nxt == 1 && a != 1 && a != P - 1) return 0;
a = nxt;
}
if(a != 1) return 0;
}
return 1;
}
Pollard-Rho 算法
首先要明确这个算法的功能就是在 O(n14)O(n14) 的时间内找到数 nn 的一个因子。
一个暴力的想法就是我们每次随机一个数,判断这个数是不是因子,如果是就返回如果不是就继续随机,但是这样的复杂度就炸了。
考虑构造如下的随机数序列:
定义 f(x)=(x2+c)(modN)f(x)=(x2+c)(modN),那么我们构造的随机数序列就是 x,f(x),f(f(x)),⋯x,f(x),f(f(x)),⋯。
这个序列的样子大概就是下面这个样子:
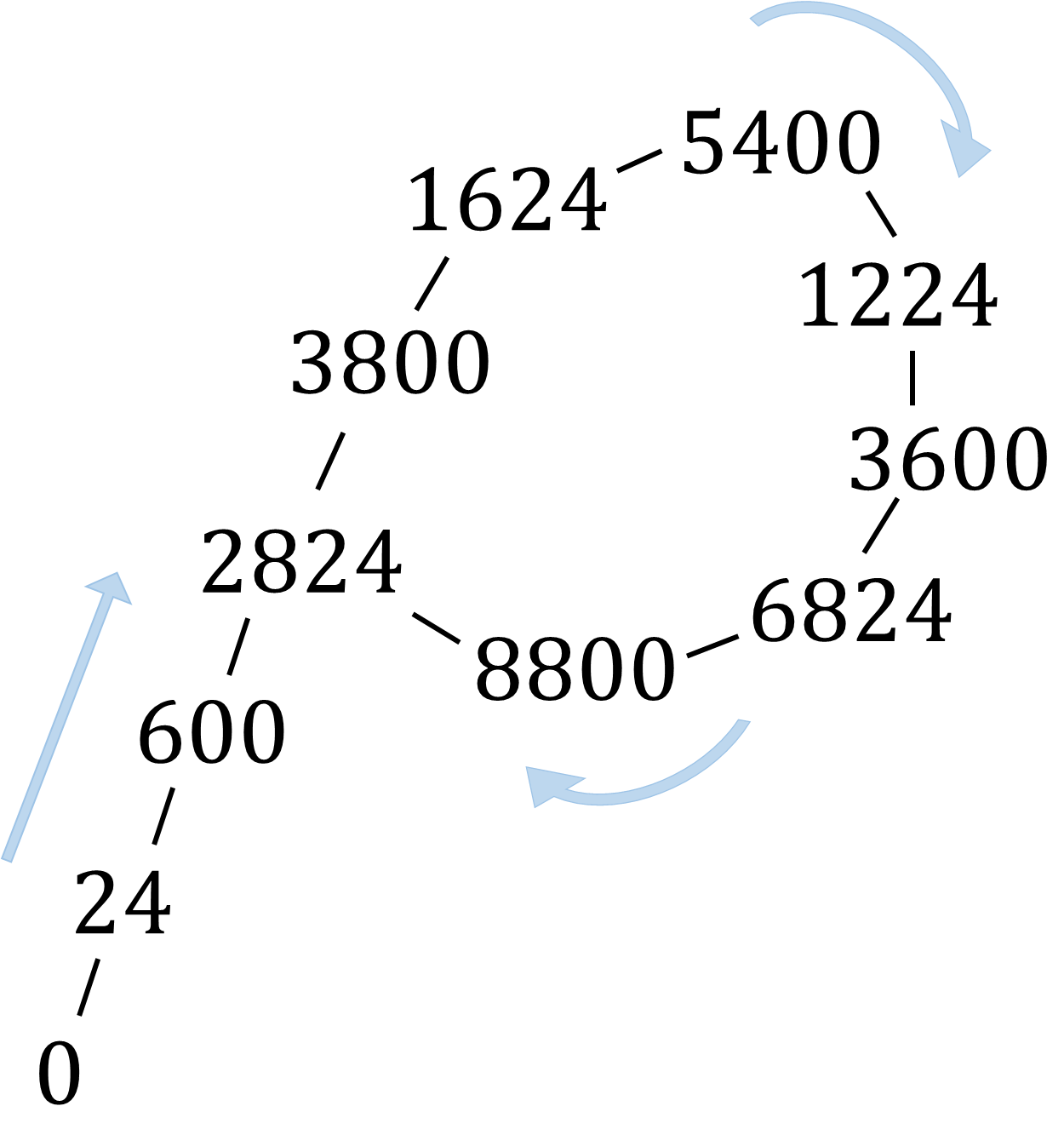
也就是一个 ρρ 的形状,而根据生日悖论期望随机 O(n14)O(n14) 个数可以找到相同的数,所以这里期望环长为 O(n14)O(n14)。
那么如果快速判环,可以使用类似龟兔赛跑的算法,也就是设置两个变量 t,rt,r,每次判断是否有 gcd(|t−r|,n)≠1gcd(|t−r|,n)≠1 且 gcd(|t−r|,n)≠ngcd(|t−r|,n)≠n,若有则 |t−r||t−r| 就是 nn 的一个因数,如果没有我们就令 t=f(t),r=f(f(r))t=f(t),r=f(f(r)),可以发现这样的话 rr 比 tt 跑的快也就是它们在环上一定可以相遇。
这个时候就能体现出我们这个随机序列的优势了:
若 |i−j|≡0(modp)|i−j|≡0(modp),则有 |fi−fj|=(i2−j2)=(i−j)(i+j)≡0(modp)|fi−fj|=(i2−j2)=(i−j)(i+j)≡0(modp),所以我们只需要对两个点之间的距离 dd 进行判断就好,不在于哪两个点而在于他们的距离,而我们上面的龟兔赛跑也显然是枚举到了每一种距离。
直接这样做就是 O(n14logn)O(n14logn)。
优化就是减小求 gcdgcd 的次数,可以考虑设一个固定的距离 CC 然后每隔 CC 个求一个公因数然后判断,这样的话期望的时间复杂度就是 O(n14)O(n14)。
代码实现:
点击查看代码
ll Pollard_Rho(ll N)
{
if (N == 4)
return 2;
if (is_prime(N))
return N;
while (1)
{
ll c = randint(1, N - 1);
auto f = [=](ll x) { return ((lll)x * x + c) % N; };
ll t = 0, r = 0, p = 1, q;
do
{
for (int i = 0; i < 128; ++i) // 令固定距离C=128
{
t = f(t), r = f(f(r));
if (t == r || (q = (lll)p * abs(t - r) % N) == 0) // 如果发现环,或者积即将为0,退出
break;
p = q;
}
ll d = gcd(p, N);
if (d > 1)
return d;
} while (t != r);
}
}
数论函数和筛法
此处可以查看如下几篇 blog,推荐按顺序观看:
本文只在此基础上补充几个知识点。
区间筛
给定区间 [l,r][l,r] 要求区间 [l,r][l,r] 中的素数的数量。
考虑若 x≤rx≤r 且 xx 不为素数,则 xx 必然拥有一个小于等于 √r√r 的质因子,所以只需要用 [2,√r][2,√r] 筛一遍区间 [l,r][l,r] 留下来的就是素数。
一些小 tip
amodb=a−a×⌊ab⌋amodb=a−a×⌊ab⌋
⌊⌊ab⌋c⌋=⌊abc⌋⌊⌊ab⌋c⌋=⌊abc⌋
整除分块中如果式子中多个数整除,复杂度是加而不是乘。
集合幂级数
FWT 与 FMT
FWT 与 FMT 是解决如下问题的工具:
其中 ⊕⊕ 为二进制下的 and or xor 三种运算之一。
下面将 FWT 与 FMT 统称为 FWT。
其解决这个问题的思路也类似 FFT,就是将序列 a,ba,b 转化为某种变换 FWT(a),FWT(b)FWT(a),FWT(b) 然后乘起来得到 FWT(c)FWT(c) 后反演得到 cc。
OR
要求:
考虑若 i∣k=ki∣k=k 且 j∣k=kj∣k=k 则 (i∣j)∣k=k(i∣j)∣k=k,就使用这个来设计变换。
即 FWTor(A)k=∑i∣k=kAiFWTor(A)k=∑i∣k=kAi
也就是 ii 为 kk 的子集才可以转移。
那考虑为什么这样是对的:
所以这个变换就是正确的。
那么考虑如何快速进行这个变换,类似 FFT 每次合并两个长度为 2n2n 的段,设不同的最高位为 11 的序列为 A1A1,为 00 的序列为 A0A0,则根据 oror 的性质 A0A0 可以转移到 A1A1,而 A1A1 不能转移到 A0A0,也就是形如下面这样:
其中 A+BA+B 是对应系数相加,(A,B)(A,B) 就是按顺序写下 A,BA,B。
逆变换就是逆着做这个操作就好了,即:
代码:
点击查看代码
void Or(ll *x,int n,int op){
for(int l=1;l<n;l<<=1){
for(int st=0;st<n;st+=l*2){
for(int i=0;i<l;i++){
ll u=x[st+i],v=x[st+l+i];
if(op==1) x[st+i]=u,x[st+l+i]=(v+u)%mod;
else x[st+i]=u,x[st+l+i]=(v+mod-u)%mod;
}
}
}
}
AND
要求:
考虑若 i&k=ki&k=k 且 j&k=kj&k=k 则 (i&j)&k=k(i&j)&k=k,所以可以构造如下的变换:FWTand(A)k=∑i&k=kAiFWTand(A)k=∑i&k=kAi
也就是 ii 为 kk 的超集时产生贡献。
变化的与上文同理:
代码:
点击查看代码
void And(ll *x,int n,int op){
for(int l=1;l<n;l<<=1){
for(int st=0;st<n;st+=l*2){
for(int i=0;i<l;i++){
ll u=x[st+i],v=x[st+l+i];
if(op==1) x[st+i]=(u+v)%mod,x[st+l+i]=v;
else x[st+i]=(u+mod-v)%mod,x[st+l+i]=v;
}
}
}
}
XOR
要求:
设 d(x)d(x) 表示二进制下 xx 的 11 的个数的奇偶性,则有如下性质:d(i&k)⊕d(j&k)=d((i⊕j)&k)d(i&k)⊕d(j&k)=d((i⊕j)&k)。
证明:因为我们是与操作,所以可以只考虑 kk 为 11 的位。若某一位上 i,ji,j 同时为 00 或 11 则显然不会有什么影响,若某一位上 i,ji,j 分别为 0,10,1 那么左右两边都是同步变化的,所有也是一样的。
所以可以设计出以下的变换:
可以乘一下看看是不是对的:
这样就形式化对了,所以这个就是正确的。
考虑怎么快速求解,其实就是新加一位,而新加一位只有 11 贡献到 11 会导致奇偶性改变,也就是取负,其它的都没有变化。
即:
逆变换其实就是考虑 A0,A1A0,A1 已经变成上面那个东西了,怎么还原回来的,就是:
代码:
点击查看代码
void Xor(ll *x,int n,int op){
for(int l=1;l<n;l<<=1){
for(int st=0;st<n;st+=l*2){
for(int i=0;i<l;i++){
ll u=x[st+i],v=x[st+l+i];
if(op==1) x[st+i]=(u+v)%mod,x[st+l+i]=(u+mod-v)%mod;
else x[st+i]=(u+v)%mod*inv2%mod,x[st+l+i]=(u+mod-v)%mod*inv2%mod;
}
}
}
}
FWT 的一些性质
FWT 的本质是一个线性变换,也就是:
FWT(A+B)=FWT(A)+FWT(B)FWT(A+B)=FWT(A)+FWT(B),FWT(cA)=cFWT(A)FWT(cA)=cFWT(A)
集合幂级数
位运算是 OI 中的常考知识点,因为位运算中每一位的独立性,所以可以将其看作两个 {0,1}n{0,1}n 上的向量的运算。
生成函数是刻画序列的有力工具,而集合幂级数就是处理集合(位运算)的一种特殊形式。对于序列 a0,a1,⋯,a2n−1a0,a1,⋯,a2n−1 我们可以定义其集合幂级数 A(x)=2n−1∑i=0aixiA(x)=2n−1∑i=0aixi。
定义集合幂级数的乘法操作,也就是子集卷积为如下的形式;
组合意义就是选择两个不交的集合,可以直接枚举子集就可以做到 O(3n)O(3n)。
可以构造占位函数 w(x)=popcount(x)w(x)=popcount(x),这样上述条件可以等价为 j xor k=ij xor k=i 且 w(j)+w(k)=w(i)w(j)+w(k)=w(i),这样就可以以 w(x)w(x) 来构造一个二元集合幂级数 A(x,y)=2n−1∑i=0aixiyw(i)A(x,y)=2n−1∑i=0aixiyw(i),而子集卷积就相当于对于第一维异或卷积,第二维和卷积,都是可以做的,所以就可以一维维来做,时间复杂度 O(n22n)O(n22n)。
因为不出意外的话我们第二维都为 O(logn)O(logn) 级别,所以直接暴力做和卷积就没问题,不用再写 FFT 了。
代码:
点击查看代码
int main()
{
m=read();n=(1<<m);
for (int i=1;i<n;i++)c[i]=c[i>>1]+(i&1);
for (int i=0;i<n;i++)F[i].a[c[i]]=read();
for (int i=0;i<n;i++)G[i].a[c[i]]=read();
FWT(F,n);FWT(G,n);
for (int i=0;i<n;i++)
F[i]=F[i]*G[i];
IFWT(F,n);
for (int i=0;i<n;i++)
printf("%d ",(F[i].a[c[i]]+mod)%mod);
return 0;
}
这个技巧就被称为占位多项式,有了这个占位多项式我们就可以对集合幂级数做各种多项式的操作,但是那东西我完全不会,就不说了。
组合计数
计数原理
加法原理: 若完成某道工序有两种方法,第一种方法的实现方式有 aa 种,第二种方法的实现方式有 bb 种,则完成这道工序的实现方法有 a+ba+b 种。
乘法原理: 若完成某道工序有两个步骤,第一个步骤有 aa 种实现方式,第二个步骤有 bb 种实现方式,则完成这道工序的实现方法有 abab 种。
其实只需要观察它们是不是相互独立的就可以判断出应使用加法原理还是乘法原理。
算两次原理(富比尼原理): 将同一个量同两个不同角度计算两次,从而建立等量关系。
这东西看上去很玄乎,但是其实放在 OI 中就是:维度的变换(枚举下标/权值)、贡献的计算(直接计算/增量计算)等,从不同的角度解决问题,并在选取了合适的角度之后通过其它的方法解决问题。
例题 P8557 炼金术:
有 kk 个熔炉,每个熔炉可以随机炼出 nn 种金属中的一些,当 nn 种金属都被炼制出来过该方案就是合法的,询问有多少种合法的方案。
考虑按每一种金属考虑,其在每一个熔炉中都可以出现或者不出现,所以方案数为 22,而其在 kk 个熔炉中出现的情况相互独立,所以方案数为 2k2k,但是这个金属必须要在某一个熔炉中出现,所以真实的方案数为 2k−12k−1。
对于不同的金属之间相互独立,所以总方案数为 (2k−1)n(2k−1)n。
鸽巢原理: nn 个小球放到 mm 个抽屉中,至少有一个抽屉放了大于等于 ⌈nm⌉⌈nm⌉ 个。
这个原理常用于结论的证明,以及一些极端情况的求解等。
组合数
组合数的计算
递推形式:(nm)=(n−1m)+(n−1m−1)(nm)=(n−1m)+(n−1m−1)。
阶乘形式:(nm)=n!m!(n−m)!=nm_m!(nm)=n!m!(n−m)!=nm––m!
Lucas 定理:(nm)=(nmodpmmodp)×(⌊np⌋⌊mp⌋)(nm)=(nmodpmmodp)×(⌊np⌋⌊mp⌋)
组合恒等式:
- 吸收恒等式: (nm)=nm(n−1m−1)(nm)=nm(n−1m−1),移项得 m(nm)=n(n−1m−1)m(nm)=n(n−1m−1)
证明:根据组合数的阶乘形式易得 - 行求和:∑ni=0(ni)=2n∑ni=0(ni)=2n
证明:根据二项式定理 (1+1)n=∑ni=0(ni)=2n(1+1)n=∑ni=0(ni)=2n - 列求和:∑mi=n(in)=(m+1n+1)∑mi=n(in)=(m+1n+1)
证明:(nn)+(n+1n)+(n+2n)+⋯+(mn)=(n+1n+1)+(n+1n)+(n+2n)+⋯+(mn)=(n+2n+1)+(n+2n)+⋯+(mn)=(mn+1)+(mn)=(m+1n+1)(nn)+(n+1n)+(n+2n)+⋯+(mn)=(n+1n+1)+(n+1n)+(n+2n)+⋯+(mn)=(n+2n+1)+(n+2n)+⋯+(mn)=(mn+1)+(mn)=(m+1n+1),主要是使用了组合数的递推形式。 - 范德蒙德卷积:∑ki=0(ni)×(mk−i)=(n+mk)∑ki=0(ni)×(mk−i)=(n+mk)
证明:考虑我们枚举的其实就是 nn 个里面选 ii 个和 mm 个里面选 k−ik−i 个,显然可以合并起来。
组合数的应用:
隔板法:nn 个相同的小球放到 mm 个不同的盒子里,每个盒子里必须至少放一个小球,方案数为 (n−1m−1)(n−1m−1)。
证明:考虑将 nn 个小球放到一排,这样中间就出现了 n−1n−1 个缝隙,放到 kk 个不同的盒子中相当于划分为 kk 段也就是选择 k−1k−1 个缝隙放上隔板,方案数就是 (n−1m−1)(n−1m−1)。
扩展: 如果将要求改为每个盒子可以不放小球,那么方案数就是 (n+m−1m−1)(n+m−1m−1),可以理解为先将所有的盒子提前放上一个小球,这样就必须至少放 11 个了。
捆绑法:有 nn 个不同的人站队,要求其中两个人必须相邻,方案数为 (n−1)!×2!(n−1)!×2!。
证明:将这两个人视为一个人去站队方案数为 (n−1)!(n−1)!,而两个人内部也可以随便站方案数为 2!2!。
格路计数:给定一个 n×mn×m 的网格,每次可以从 (x,y)(x,y) 走到 (x+1,y)(x+1,y) 或者 (x,y+1)(x,y+1),从 (1,1)(1,1) 走到 (n,m)(n,m) 的方案数为 (n+mn)(n+mn)。
证明:我们总共要走 n+mn+m 步才能走到 (n,m)(n,m) 这其中有 nn 步是执行 (x,y)→(x+1,y)(x,y)→(x+1,y),而且这 nn 步可以在任意位置。
卡特兰数:见数论之生成函数基础。
prufer 序列
对于一棵有 nn 个节点的带标号树,其 prufer 序列一定是一个长度为 n−2n−2 值域为 [1,n][1,n] 的序列。
树转化为 prufer 序列:
- 选择树上编号最小的叶子节点,将其父亲插入到序列的末尾
- 删除这个选择的叶子节点
- 重复上述步骤直到树中只剩下两个节点
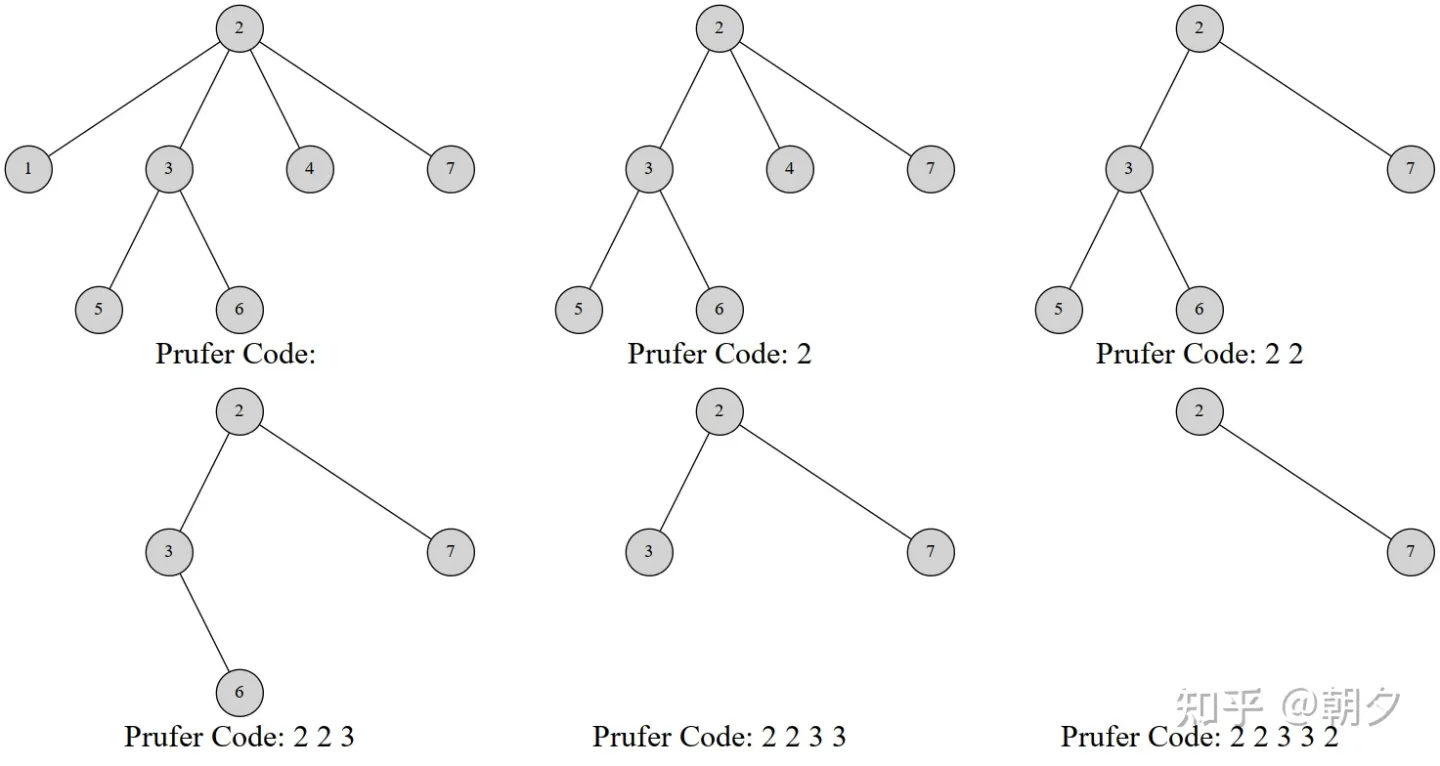
注意到我们的 prufer 序列与树构成一个双射,所以我们可以由 prufer 序列还原对应的树。
- 选择编号最小的一个叶子节点(即从未在序列中出现的点),其父亲就是序列第 ii 个数。(ii 初始为 11)
- 点 xx 的度数为 xx 的出现次数加 11,所以可以删除这个叶子节点,然后将其父亲的度数减 11,直到其父亲度数变为 11 就成为了叶子节点。
- 重复上述两步,直到序列全部被用完。
可以发现这样构造出的 prufer 序列有如下的性质:
- 剩下的两个节点中,一定有一个为 nn 号节点
- 对于一个 nn 度点,其会在 prufer 序列中出现 n−1n−1 次
应用:
无向完全图生成树计数:若该完全图点数为 nn,则任意一个长度为 n−2n−2 的值域为 [1,n][1,n] 的序列都可以还原出一棵生成树,所以方案数即 nn−2nn−2,与 Cayley 定理的结论一致。
Cayley 定理:假设图中有 mm 个连通块,连通块内的点数为 a1,a2,⋯,ama1,a2,⋯,am,且满足 a1+a2+⋯+am=na1+a2+⋯+am=n,则选择 m−1m−1 条边将图联通的方案数为 nm−2∏mi=1ainm−2∏mi=1ai
广义 Cayley 定理:nn 个有标号的点形成的包含 kk 棵无向树的森林,要求给定的 kk 个点没有两个点属于同一棵树的方案数为 k×nn−k−1k×nn−k−1。
nn 个点的有根树计数:因为每个点都可以作为根,所以答案为 n×nn−2=nn−1n×nn−2=nn−1
容斥原理
最基本的式子就是交集与并集的转化:
设 SS 为有限集,Ai⊆S(i∈[1,n])Ai⊆S(i∈[1,n]),则有:
证明:考虑元素 xx 属于 mm 个 AA,则其产生的贡献就是这个式子 ∑mi=1(−1)i−1(mi)=−(∑mi=1(−1)i(mi))=−(−1+∑mi=0(−1)i(mi))=−(−1+(1−1)m)=1∑mi=1(−1)i−1(mi)=−(∑mi=1(−1)i(mi))=−(−1+∑mi=0(−1)i(mi))=−(−1+(1−1)m)=1
直观理解这个式子就是将满足 A1A1 或满足 A2A2 或 ⋯⋯ 的元素个数转化为了强制同时满足某些条件的元素个数。
当然有的时候也要有一些直观的理解,比如 [a,b][a,b] 中满足 AA 的数的个数可以转化为 [1,b][1,b] 中满足的个数减去 [1,a−1][1,a−1] 中满足的个数;满足 AA 的个数可以转化为无所谓的个数减去不满足 AA 的个数等。
在容斥以及反演过程中常使用二项式定理证明结论。
反演
反演其实就是容斥原理的代数形式,下面就简单介绍几种反演。
通过这些反演推导的练习,相信你一定会学会如何推导容斥系数。
二项式反演
形式一:
证明:
这里只证明充分性,必要性显然成立。
也就是得到在计算 G(n)G(n) 的时候 G(i)G(i) 的系数是多少,要证明的就是后面这个式子 G(n)G(n) 的系数为 11,其余的系数为 00。
下面就是考虑计算 G(i)G(i) 的系数,一个想法就是枚举所有的 F(j)F(j) 然后将 F(j)F(j) 中 G(i)G(i) 的系数求和。
所以系数就正确了,得证。
形式二:
证明:
考虑使用 EGF 证明;
这个式子显然就是一个卷积的形式也就是:
所以:
移项之后就是:
得证。
形式三:
形式四:
这两种形式都可以通过慢慢推的方式证明,因为形式一已经类似证明过了就不证明了。
莫比乌斯反演
请查看:
Min-Max 容斥
定义全集 U={a1,a2,a3,⋯,an}U={a1,a2,a3,⋯,an},有一个集合 SS,则 max(S)=maxai∈Saimax(S)=maxai∈Sai,min(S)=minai∈Saimin(S)=minai∈Sai。
则有如下结论:
下面考虑证明第一个式子。
一样的套路,假设元素 xx 为第 kk 大,钦定 xx 为集合中的最小值,那么它在后面的式子里对答案贡献的系数是什么,可以枚举大于 xx 的数选择多少个。
所以只有最大值会产生 11 的贡献,其他都会产生 00 的贡献,得证。
要注意的一点就是 Min-Max 容斥在期望意义下依然成立,即:
如果我们要求第 kk 大也是可以容斥出来的:
这个容斥系数我们是可以很简单推导出来的。
考虑设:
考虑若 xx 为第 pp 大,则由上文可知其贡献即:
我们的目的就要让这个式子的值等于 [p=k][p=k],也就是:
这个就是一个二项式反演的形式,所以就有:
因此 F(|T|)=(−1)|T|−k(|T|−1k−1)F(|T|)=(−1)|T|−k(|T|−1k−1)
子集反演
莫比乌斯反演相当于在因子多重集上的子集反演,所以本质也是子集反演。
现有一个满足某些条件的元素集合 AA。
设 f(S)f(S) 表示 A=SA=S 时的答案,g(S)g(S) 表示 S⊆AS⊆A 时的答案,则有如下结论:
设 f(s)f(s) 表示满足 A=SA=S 时的答案,g(S)g(S) 表示 A⊆SA⊆S 时的答案,则有如下结论:
斯特林反演
定义第一类斯特林数 [nm][nm] 表示 nn 个不同元素形成 mm 个圆排列的方案数。
注意 (1,2,3,4)(1,2,3,4) 与 (2,3,4,1)(2,3,4,1) 为同一个圆排列,但 (1,2,3,4)(1,2,3,4) 与 (4,3,2,1)(4,3,2,1) 不是同一个圆排列。
其满足如下递推式:
这个递推式就是考虑元素 nn 是自己单独变成一个圆排列还是放到前 n−1n−1 个数的前面。
对于任意一个排列我们如果将其变成置换的形式,就相当于划分成了若干圆排列,也就是说:
定义第二类斯特林数 {nm}{nm} 表示将 nn 个不同的元素划分到 mm 个相同的集合中,要求集合非空的方案数。
则有如下的递推式:
就是考虑元素 nn 是自己新建一个集合,还是放在前面已有的集合中。
可以显然发现这个结论:
因为一个圆排列只对应一个集合,而一个集合可以对应多个圆排列。
斯特林数最关键的应用就是:普通幂、上升幂、下降幂之间的转换。
定义下降幂:xn_=x×(x−1)×(x−2)×⋯×(x−n+1)xn––=x×(x−1)×(x−2)×⋯×(x−n+1)。
定义上升幂:x¯n=x×(x+1)×(x+2)×⋯×(x+n−1)x¯¯¯n=x×(x+1)×(x+2)×⋯×(x+n−1)。
显然若 x<nx<n,则 xn_=0xn––=0。
普通幂转下降幂:
证明:
考虑使用数学归纳法,显然 n=0n=0 时成立,考虑假设 [0,n−1][0,n−1] 成立,证明 nn 时成立。
上升幂转通常幂:
证明同上。
下降幂转通常幂:
通常幂转上升幂:
上述两个式子的证明:
首先这个式子成立:
将这个式子分别带入第一、二个公式即可得到这两个式子。
反转公式:
证明:
将第三、四个公式,分别带入第一、二个公式就可以得到这个公式。
斯特林反演:
下面只证明一下第一个式子的充分性,其余的都可以类比地推出。
线性代数
矩阵乘法
若给定矩阵 A,BA,B,使得 C=A×BC=A×B,则满足:ci,j=∑k(Ai,k×Bk,j)ci,j=∑k(Ai,k×Bk,j)
也就是说若 A,BA,B 可以进行矩阵乘法则必须要满足:AA 的列数等于 BB 的行数。
矩阵乘法之后的 CC 矩阵 (i,j)(i,j) 位置的元素,相当于 AA 的第 ii 行与 BB 的第 jj 列对应相乘再相加后的结果。
矩阵乘法之后的 CC 矩阵的行数等于 AA 的行数,列数等于 BB 的列数。
矩阵乘法满足结合律,但不满足交换律,即若我们要计算 AkAk 也可以用类似快速幂的方法进行计算。
我们可以将矩阵乘法中的运算更换,比如换成:ci,j=maxk(Ai,k+Bk,j)ci,j=maxk(Ai,k+Bk,j),这个东西叫做 max+max+矩乘,可以证明这种形式的矩阵乘法也满足结合律。
而我们的许多 dpdp 中的转移方程就可以用这种矩阵表示出来,所以就可以通过矩阵乘法在 O(logn)O(logn) 的时间内进行 dpdp 或者快速维护动态 dpdp。
高斯消元
请查看:
本文只会扩展一下高斯消元的应用,主要是这种加减消元法的思想。
解异或方程组
记 ⊕⊕ 为按位 xor 操作,解下列方程组:
其中 ai,j∈{0,1}ai,j∈{0,1}
注意到一点 a⊕a=0a⊕a=0,也就是我们可以使用这点性质进行消元。
过程与高斯消元相同,因为我们每次只需要支持行的交换和行的对应异或所以可以使用 bitset 优化到 O(n3w)O(n3w)。
矩阵求逆
对于方阵 AA 若方阵 A−1A−1 满足 A×A−1=A−1×A=IA×A−1=A−1×A=I,则称矩阵 AA 可逆,其中 A−1A−1 就是它的逆矩阵。
记 InIn 表示 n×nn×n 的单位矩阵,则逆矩阵的求法如下:
- 构造一个 n×2nn×2n 的矩阵 (A,In)(A,In)。
- 通过高斯消元将矩阵变成 (In,A−1)(In,A−1),这样右半部分的矩阵就是 AA 的逆矩阵 A−1A−1,若左边不可以化为 InIn 则矩阵 AA 不可逆。
行列式求值
对于一个 n×nn×n 的行列式 AA,其行列式的值定义为:
其中 SnSn 定义为长度为 nn 的全排列集合,sgn(σ)sgn(σ) 定义为排列 σσ 的奇偶性,若 σσ 中逆序对数为偶数则 sgn(σ)=1sgn(σ)=1,否则 sgn(σ)=−1sgn(σ)=−1
行列式有如下性质:
-
交换两行(列)行列式的值取反
证明:若交换 x,yx,y 两行,则考虑贡献是怎么变化的,如果要使得 ∏ni=1ai,σi∏ni=1ai,σi 依旧是之前的值,就相当于要交换 σxσx 和 σyσy,此时 σx,σyσx,σy 是否构成逆序对的情况取反,而对于 p∈(x,y)p∈(x,y),σpσp 是否与 σx,σyσx,σy 构成逆序对的情况要么同时改变,要么同时不变,所以不会有影响,对于 p∈[1,x)⋃(y,n]p∈[1,x)⋃(y,n],σpσp 是否与 σx,σyσx,σy 构成逆序对显然不会有任何影响。
综上逆序对恰好变化 11,也就是奇偶性会改变,会乘以 −1−1。 -
将一行(列)加到另一行(列)上行列式的值不变
证明:若将 xx 列加入到 yy 列上,那么对于一个排列 σσ 交换 σxσx 与 σyσy 后可以得到一个新的排列 σ′σ′,显然 sgn(σ)=−sgn(σ′)sgn(σ)=−sgn(σ′),而对于多加的贡献在两者中正好形成相反数所以相互抵消了。 -
若行列式只有 ai,j(i≤j)ai,j(i≤j) 处有值,即一个上三角处有值,则该行列式的值为 ∏ni=1ai,i∏ni=1ai,i
证明:此时对于一个排列 σσ 要使得 ∏ni=1ai,σi∏ni=1ai,σi 不为 00,只有 σ={1,2,3,4,⋯,n}σ={1,2,3,4,⋯,n},而此时 sgn(σ)=1sgn(σ)=1,所以行列式的值就是 ∏ni=1ai,i∏ni=1ai,i -
将行列式某行(列)同时乘 kk,则行列式的值乘 kk
证明:相当于对于每个 σσ 都将某个 ai,σiai,σi 乘以 kk,所以最后的值就会乘以 kk。
通过上述性质我们就可以直接通过高斯消元将行列式消成上三角,然后对角线元素的乘积就是行列式的值。
需要注意如果消的过程中交换了一次行,要将最后的答案乘以 −1−1。
LGV 引理
LGV 引理常用于解决 DAG 上不相交路径(权值)计数问题
记 w(P)w(P) 表示 PP 这条路径的权值和,若为路径计数则可将权值记为 11。
记 e(u,v)e(u,v) 表示 uu 到 vv 所有路径 PP 的 w(P)w(P) 之和。
记起点集合为 AA,终点集合大小为 BB,其大小均为 nn。
则我们的答案为下列行列式的值:
感觉这个如果不给例题就实在是太抽象了。
例题 CF348D Turtles:
一张 nn 行 mm 列的网格图,图中的有些格子上面有障碍物,但保证 (1,1)(1,1) 和 (n,m)(n,m) 上面都没有障碍物。在 (1,1)(1,1) 处有两只乌龟,都想要去 (n,m)(n,m)。乌龟每次都可以向下或者向右走一格,前提是格子上没有任何障碍物。要求两只乌龟在前往 (n,m)(n,m) 的路途中不可以相遇,即除了起点和终点,他们的路径没有其他公共点。求出从起点到终点的不同路径对数。答案对 109+7109+7 取模。
考虑我们从 (1,1)(1,1) 出发必然经过 (1,2)(1,2) 和 (2,1)(2,1) 到达 (n,m)(n,m) 必然经过 (n−1,m)(n−1,m) 和 (n,m−1)(n,m−1),所以我们的起点集合就是 A={(1,2),(2,1)}A={(1,2),(2,1)} 终点集合就是 B={(n−1,m),(n,m−1)}B={(n−1,m),(n,m−1)}。
根据 LGV 引理,我们要算四次 e(i,j)e(i,j) 表示从 ii 到 jj 的路径条数,而这个东西 O(nm)O(nm) 的 dpdp 做法显然,就很好做了。
矩阵树定理
矩阵树定理可以解决给定一张图,求其生成树个数,这里要求给定的图没有自环。
下面考虑无向图的情况。
给定一张图 G=(V,E)G=(V,E),mi,jmi,j 表示直接连接 (i,j)(i,j) 的边数,degidegi 表示点 ii 的度数,定义它的拉普拉斯矩阵 LL 为:
则生成树个数为 LL 中任意删去一行一列后其行列式的值。
下面考虑有向图的情况。
记 mi,jmi,j 表示从 ii 指向 jj 的边数,定义出度拉普拉斯矩阵为:
定义入度拉普拉斯矩阵为:
记图 G 的以 r 为根的根向生成树的方案数为 troot(G,r),记图 G 的以 r 为根的叶向生成树的方案数为 tleaf(G,r),则根据矩阵树定理有:
其中定义 L(1,2,3,⋯,k−1,k+1,⋯,n1,2,3,⋯,k−1,k+1,⋯n) 表示 L 矩阵除去第 k 行第 k 列后的矩阵。
BEST 定理
定义 troot(G,k) 表示图 G 的以 k 为根的根向生成树个数。
在有向欧拉图 G 中,G 中不同欧拉回路的数量为:
degv 既可以指出度也可以指入度,因为欧拉图中每个点的入度和出度相等。
k 可以为任意点,因为此时对于任意两个点 u,v 都有 troot(G,x)=troot(G,y)。
一种感性理解这个定理的方法:
对于一条欧拉路径,我们保留每一个点的最后一条出边,出边一定构成一棵根向树,因为如果不是就无法构成欧拉路径。
而对于其它的边发现任意排列都可以构成欧拉路径,所以就是∏v∈V(degv−1)!。
乘起来就是 BEST 定理。
多项式与生成函数
请查看:
群论入门
请查看:
计算几何
请查看:
博弈论
请查看:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律