博物识植—多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名 | 从你的全世界爬过 团队logo:  |
| 项目简介 | 项目名称:博物识植 项目logo:  项目介绍:在探索自然奥秘的旅途中,我们常与动植物相伴而行,却无法准确识别它们,更难以深入了解他们的特征。为了更好地理解和欣赏自然界的多样性,提升我们对动植物的认识和保护意识,我们需要一个智能系统。该系统能够根据用户拍摄的动植物照片,智能识别并匹配相应的信息,同时为用户提供丰富的学习资源,帮助人们更深入地了解和学习动植物知识。通过这样的方式,我们不仅能够更准确地识别和欣赏周围的生命,还能够在日常生活中,随时随地增长见识,体验探索自然的乐趣。 项目背景:人类的生活离不开动植物的支持,动植物的多样性是一切地球生物的依赖。在生活中随处可见很多动植物,动植物是人类生活必不可少的一部分。 保护大自然保护动植物就是在保护人类自己。在保护动植物的过程中,首先要解决的是动植物识别的问题。 项目意义:提供了一种我们与自然界互动的方式。其应用场景广泛,渗透到了教育、旅游等多个领域。在学校,它可以是生物课程的辅助工具,通过实践学习生物多样性;在旅游行业,它可以帮助游客更好地了解他们所参观的自然景观,提升旅行体验 |
| 团队成员学号 | 042201401陈高菲、102202107王勤琛、102202108王露洁、102202115孙佳会、102202123张铭心、102202130林烨、102202138徐婉瑜、102202140郭心怡 |
| 项目目标 | 本系统旨在实现以下功能: a.图片识别功能:用户上传动植物图片,系统通过图像识别技术自动识别物种,返回准确的物种名称。 b.物种详细信息:识别后,用户将获取该物种的详细信息,包括外形特点、生长环境、分布区域等相关数据。 c.物种图片展示:系统将提供该物种的高质量图片,帮助用户更直观地了解物种特征。 d.名称搜索功能:用户可以手动输入动植物的名称,系统将返回该物种的相关信息,方便快速查询。 e.历史记录保存:保存用户的历史搜索记,用户可以随时查看过去的搜索记录。 f.网站部署上线:通过华为云的弹性计算服务部署网站,确保系统高可用和稳定运行,实现网站上线。 |
| 其他参考文献 | 1.yanjingang/pigimgclassification: 图像分类 2.基于改进SE-MnasNet骨干网络YOLOv5的动植物树木识别系统_开源 树木识别 |
| gitee链接 | 2024学年数据采集与融合技术大作业——博物识植 团队:从你的全世界爬过 |
一、系统总体技术概述
1.1 系统架构概述
系统分为前端、后端、数据库、AI接口、爬虫模块、部署等多个层级。前后端之间通过RESTful API进行通信。具体分为以下几个部分:
- 前端:使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。用户可以上传文本、图片等文件。
- 后端:使用Python语言和Flask框架实现,处理图像识别、查询请求、调用AI接口和爬虫数据存储等业务逻辑。
- 数据库:存储动植物物种的详细信息,包括图像、分布、特点等。存储物种识别的历史记录信息。
- 图像识别与AI接口:利用图像识别模型或调用第三方AI服务(如百度AI、Google Vision等)识别图片并返回结果。
- 爬虫:提前爬取动植物相关网站数据,补充物种数据库。使用Selenium框架进行实时图片爬取。
- 部署平台:使用华为云平台部署系统,保证系统的高可用和稳定性。
1.2 各模块技术实现
1.2.1 图像识别模块
- 目标:用户上传图片,系统通过图像识别技术返回物种名称。
- 技术方案:
使用深度学习模型:基于改进SE-MnasNet骨干网络YOLOv5和卷积神经网络cnn opencv进行图像分类和识别。
基于识别精确度的考虑调用第三方云服务百度智能云的动植物识别API提供快速而准确的图像识别。 - 流程:
用户上传图片,前端将图片通过API发送至后端。
后端调用模型或AI图像识别API分析图片,获取可能的物种标签。
后端将物种名称返回给前端,前端展示识别结果。
1.2.2 物种信息查询功能
- 目标:根据识别后的物种名称或用户输入的名称,返回该物种的详细信息。
- 技术方案:
利用selenium技术和scrapy框架爬取信息网站所有物种信息(如外形特点生长环境、分布区域等)存储在csv表导入数据库并定期更新。
利用查询语句在数据库中进行查找并返回详细信息。
若数据库中没有相关信息,则调用百度智能云的千帆大模型识别物种名称,查询物种相关信息。 - 流程:
后端识别出物种名称时,系统首先查询数据库,若没有该物种的信息,再调用AI接口获取。
1.2.3 相似图片展示
- 目标:根据用户上传的图片,返回物种的相似图片,帮助用户直观了解物种。
- 技术方案:
运用selenium爬虫技术实时爬取百度识图返回的相似图片 - 流程:
后端接收前端传入的图片后,将图片作为输入文件传入百度识图网站实时爬取相似图片,在系统返回物种详细信息时,将图片URL一并返回。
1.2.4 保存历史记录
- 目标:将用户的历史搜索记录保存至数据库,方便用户在“我的图鉴”页面查看并跳转至物种详情页,随时查看过去的搜索记录。
- 技术方案:
创建一个数据库表专门用来保存用户的搜索记录,包括用户上传的图片、识别出来的物种名称、物种的详细信息(如描述、分布、图片URL等) - 流程:
当用户获取识别结果时,后端系统会将物种信息保存至数据库中。在点击我的图鉴中的物种名称时,后端调取数据库信息展示在前端界面。
1.2.5 部署与部署架构
- 目标:将整个系统部署到华为云服务器上,让非本地用户可以访问。
- 技术方案:
使用华为云ECS(Elastic Cloud Server)部署后端服务。
使用华为云OBS 存储图片等静态资源。
使用RDS(Relational Database Service)存储物种信息数据库。
前端可以使用 Nginx 进行负载均衡和反向代理 - 流程:
前后端文件上传部署完成后即可实现非本地用户的访问。
1.3 源码运行步骤
- gitee仓库下载源码
- 启动文件中的ai.py与database.py文件
- 运行index.html文件
(!注意在本地主机运行代码时请更换代码中的路径名)
二、个人分工及具体实现
在本次实践中,我主要负责实现图片识别、大模型接口调用和后端代码。
(1)根据图片返回识别结果-调用两个图片识别API
起初,遇到的最大问题:如何能够准确识别动植物图像?即对于输入的一张图片,输出植物或动物识别结果。
经过搜索,我选择直接尝试使用百度AI接口。这是我首次调用AI接口,起初稍显不熟。
调用前准备
1.注册,完成个人实名认证并领取植物识别和动物识别免费资源
2.创建应用。应用成功创建后,我们会看到百度给予的API Key和Serect Key,可以通过这两个Key获取token
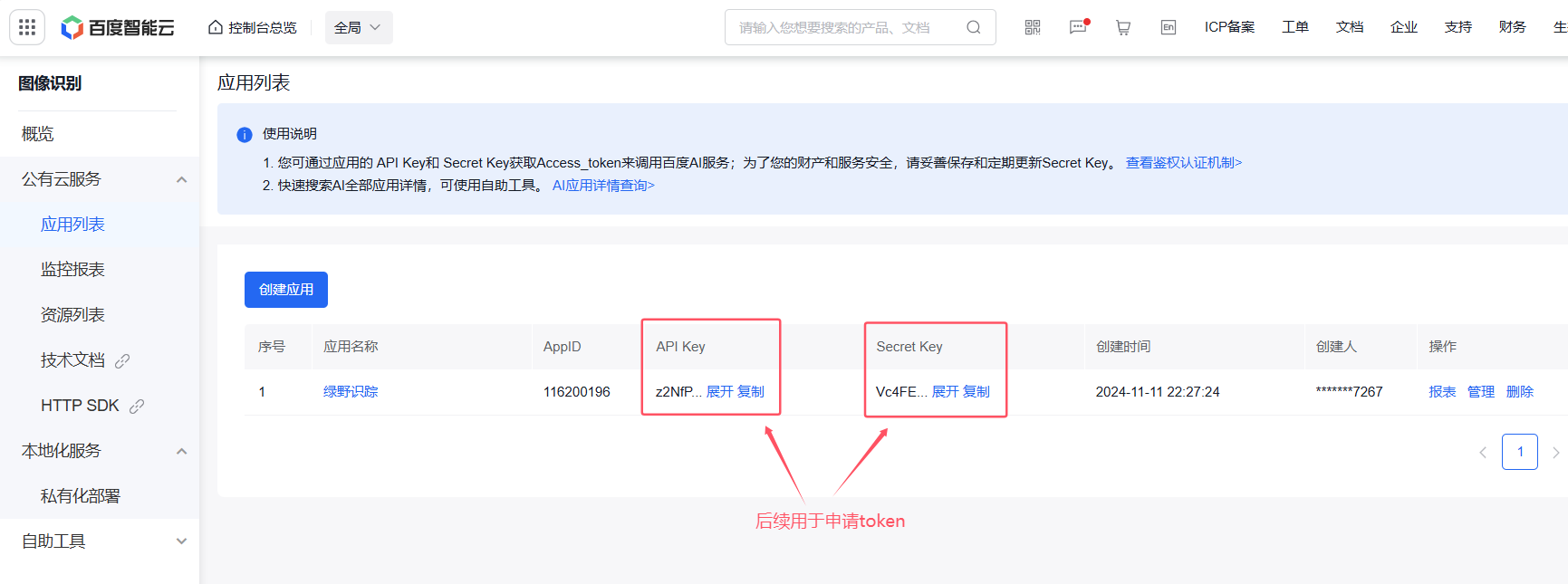
#获取access token
#encoding:utf-8
import requests
def get_access_token():
#client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=此处为官网获取的AK&client_secret=此处为官网获取的SK'
response = requests.get(host)
if response:
print(response.json())
access_token = response.json().get("access_token")
return access_token
else:
print("获取访问令牌失败。")
return None
print(get_access_token())
正式调用
以植物识别为例,编写调用api,实现选取识别的功能
HTTP 方法:POST
请求URL: https://aip.baidubce.com/rest/2.0/image-classify/v1/plant
URL参数:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token |
请求参数
| 参数名称 | 是否必选 | 类型 | 说明 | |
|---|---|---|---|---|
| image | 和url二选一 | string | 图像数据,base64编码,要求base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式。注意:图片需要base64编码、去掉编码头后再进行urlencode。 | |
| url | 和image二选一 | string | 图片完整URL,URL长度不超过1024字节,URL对应的图片base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式,当image字段存在时url字段失效。 | |
| baike_num | 否 | integer | 用于控制返回结果是否带有百科信息,若不输入此参数,则默认不返回百科结果;若输入此参数,会根据输入的整数返回相应个数的百科信息 |
代码如下:
import requests
import base64
#动物识别
# request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/animal"
#植物识别
request_url1="https://aip.baidubce.com/rest/2.0/image-classify/v1/plant"
#二进制方式打开图片文件
f = open('D:\\360MoveData\\Users\\ASUS\\Desktop\\API接口调用\\7.jpg', 'rb')#此处我使用一张榕树的照片
img = base64.b64encode(f.read())
params = {
"image": img,
"baike_num": 1# 添加baike_num参数,这里设置为1,表示返回1个百科信息
}
access_token = '你的access_token'#此处隐藏,为上一步获取到的token
# request_url = request_url+ "?access_token=" + access_token#动物
request_url = request_url1 + "?access_token=" + access_token #植物
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print(response.json())
输出结果如下:

返回参数
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| log_id | uint64 | 是 | 唯一的log id,用于问题定位 |
| result | arrry(object) | 是 | 植物识别结果数组 |
| +name | string | 是 | 植物名称,示例:榕树 |
| +score | uint32 | 是 | 置信度,示例:0.8649 |
| +baike_info | object | 否 | 对应识别结果的百科词条名称 |
| ++baike_url | string | 否 | 对应识别结果百度百科页面链接 |
| ++image_url | string | 否 | 对应识别结果百科图片链接 |
| ++description | string | 否 | 对应识别结果百科内容描述 |
经过多次尝试发现百科信息并不是所有动植物都能够返回,只有少部分动植物才可以返回百科信息,为使返回结果统一,选择在请求参数中删去baike_num。
由返回结果可以看出,会根据图片返回置信度前三的名称name和score,我们只需要置信度最高的名称
result = response.json()
if 'result' in result and result['result']:
highest_result = max(result['result'], key=lambda x: x['score'])
plant_name = highest_result['name']
(2)根据名称返回详细信息-调用千帆大模型API
只通过百度AI接口的调用,我们只能得到图片中动物或者植物的名称,这显然是不够的。接着将返回的名称作为输入到爬虫保存的数据库里面进行搜索,返回数据库中的详细信息。但数据库中的信息无法满足所有的动植物。会出现新问题:如何根据动植物的名称来返回详细信息?
我们要找到一个免费的AI接口来根据名称返回物种的详细信息
经过多个模型的尝试,如Kimi,文心一言API,通义万象等,最终使用千帆大模型
有了前面调用的基础,较为容易地完成了千帆大模型的调用
class QIANFAN:
_api_url = "https://aip.baidubce.com"
def __init__(self, api_key, secret_key):
self.API_KEY = 'ohkUn0XAJnynNC5OjEZN6EUs'
self.SECRET_KEY = '0EusjiaxuY6Z6Q40z4Q7LBD7IrgpQlPb'
url = self._api_url + "/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": self.API_KEY, "client_secret": self.SECRET_KEY}
result = self.http_request_v2(url, method="POST", params=params)
if 'access_token' in result:
self.access_token = result["access_token"]
else:
print(result)
exit()
def chat(self, model="ernie-lite-8k", message=None, **kwargs):
url = f"{self._api_url}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/{model}?access_token={self.access_token}"
payload = json.dumps({
"messages": [{"role": "user", "content": message}],
"temperature": 0.95,
"penalty_score": 1
})
for key, value in kwargs.items():
payload[key] = value
print(payload)
response = self.http_request_v2(url, method="POST", params=payload)
return response
# 生成headers头
def headers(self, params=None):
headers = {}
headers['Content-Type'] = 'application/json'
return headers
def http_request_v2(self, url, method="GET", headers={}, params=None):
headers[
'User-Agent'] = 'Mozilla/5.0 \(Windows NT 6.1; WOW64\) AppleWebKit/537.36 \(KHTML, like Gecko\) Chrome/39.0.2171.71 Safari/537.36'
if method == "GET":
response = requests.get(url)
elif method == "POST":
# data = bytes(json.dumps(params), 'utf-8')
response = requests.post(url, data=params)
elif method == "DELETE":
response = requests.delete(url, data=data)
result = response.json()
return result
这个模型同样适用于根据描述来返回详细信息。
(3)后端代码编写
接口1:实时爬取相似图片
若直接用前端用户上传的文件作为爬虫的输入文件,会出现错误 "No file part of the request" ,表示 Flask 没有在请求中找到文件。

由于爬虫时使用的是绝对路径,而从前端获取的图片只能得到相对路径,因此要在 Flask 路由中,将上传的文件保存到服务器的临时目录。使用保存的文件路径调用爬虫函数。
UPLOAD_FOLDER = r'D:\plants_and_animals\upload' # 改成自己电脑本文件夹的绝对路径
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
@app.route('/api/upload_and_crawl', methods=['POST'])
def upload_and_crawl():
# 检查是否有文件上传
if 'image' not in request.files:
return jsonify({"success": False, "error": "No file uploaded."}), 400
file = request.files['image']
# 保存上传的文件
if file.filename == '':
return jsonify({"success": False, "error": "No file selected."}), 400
print(f"Received file: {file.filename}")
filename = secure_filename(file.filename)
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(file_path)
print(file_path)
# 调用爬虫程序处理图片
try:
similar_images = crawl_similar_images(file_path)
if os.path.exists(file_path):
os.remove(file_path)
print(f"Deleted temporary file: {file_path}")
return jsonify({"success": True, "similar_images": similar_images})
except Exception as e:
return jsonify({"success": False, "error": str(e)}), 500
接口2:根据输入的图片返回植物详细信息
接收上传的植物图片,并对其进行识别
@app.route('/api/classify_plants', methods=['POST'])
def classify_plants():
try:
if 'image' not in request.files:
return jsonify({'success': False, 'error': 'No image uploaded'}), 400
file = request.files['image']
if file.filename == '':
return jsonify({'success': False, 'error': 'No selected file'}), 400
recognition_result = classify_plant(file)
return jsonify(recognition_result)
except Exception as e:
return jsonify({'success': False, 'error': str(e)}), 500
定义了一个名为 classify_plant 的函数,其主要目的是利用百度 AI 的图像识别 API 对上传的植物图片进行识别,并获取该植物的详细信息。
函数接收一个 image_data 参数,该参数可以是字节数据或文件对象。根据 image_data 的类型,函数将其转换为 Base64 编码的字符串,并存储在 img_base64 变量中。接着,函数将 img_base64 放入 params 字典中,并设置请求头 headers,指定内容类型为 application/x-www-form-urlencoded。
然后,函数使用 requests.post 方法向百度 API 发送 POST 请求,并附带访问令牌、参数和请求头。如果响应状态码不是 200,response.raise_for_status 会触发异常。函数解析响应的 JSON 数据,并检查是否包含 result 字段。如果包含,函数会从结果中找到得分最高的分类结果,并提取植物名称 plant_name。
接下来,函数调用 get_plant_details 函数获取植物的详细信息。如果详细信息未找到,函数会使用 QIANFAN 类调用千帆大模型生成详细描述。最后,函数返回一个包含分类结果和详细信息的 JSON 响应。如果在请求过程中发生异常,函数会捕获异常并返回包含错误信息的 JSON 响应。
def classify_plant(image_data):
request_url = "https://aip.baidubce.com/rest/2.0/image-classify/v1/plant"
access_token = '此处省略,为根据key获取的token'
if isinstance(image_data, bytes):
img_base64 = base64.b64encode(image_data).decode('utf-8')
else:
img_base64 = base64.b64encode(image_data.read()).decode('utf-8')
params = {
"image": img_base64
}
headers = {'content-type': 'application/x-www-form-urlencoded'}
try:
response = requests.post(
f"{request_url}?access_token={access_token}",
data=params,
headers=headers
)
response.raise_for_status() # 将触发异常,如果状态码不是200
result = response.json()
if 'result' in result and result['result']:
highest_result = max(result['result'], key=lambda x: x['score'])
plant_name = highest_result['name']
# 获取植物详细信息
details = get_plant_details(plant_name)
if details in ["植物详情文件未找到。", "No details found for this plant."]:
# 如果details为空,调用chat方法获取更多信息
API_KEY = 'ohkUn0XAJnynNC5OjEZN6EUs'
SECRET_KEY = '0EusjiaxuY6Z6Q40z4Q7LBD7IrgpQlPb'
chat_client = QIANFAN(API_KEY, SECRET_KEY)
chat_result = chat_client.chat(model='ernie_speed', message=f"请详细说明一下{plant_name}这个植物")
# print(chat_result["result"])
details = chat_result["result"]
# print(details)
return {
'success': True,
'plant_name': plant_name,
'details': details
}
else:
return {'success': False, 'error': 'No results found'}
except requests.RequestException as e:
return {'success': False, 'error': str(e)}
通过读取 CSV 文件并查找匹配的植物名称,来获取植物的详细信息,并在文件未找到或未找到匹配项时提供相应的错误信息。
def get_plant_details(plant_name):
try:
with open('plant_details.csv', mode='r', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
if row['中文名'] == plant_name:
return f"学名: {row['学名']}\n分类系统: {row['分类系统']}\n形态特征: {row['形态特征']}\n生态习性: {row['生态习性']}\n"
except FileNotFoundError:
return "植物详情文件未找到。"
return "No details found for this plant."
接口3:根据输入的文字描述返回植物的详细信息
接收用户提交的植物描述,并返回详细的植物信息
@app.route('/api/submit_description_plant', methods=['POST'])
def submit_description_plant():
try:
if 'description' not in request.form:
return jsonify({'success': False, 'error': 'No description provided'}), 400
description = request.form['description']
API_KEY = '此处省略,创建应用处获取'
SECRET_KEY = '此处省略,创建应用处获取'
chat_client = QIANFAN(API_KEY, SECRET_KEY)
chat_result = chat_client.chat(model='ernie_speed',
message=f"请根据下面描述详细说明一下这个植物: {description}")
details = chat_result["result"]
return jsonify({
'success': True,
'details': details
})
except Exception as e:
return jsonify({'success': False, 'error': str(e)}), 500
接口4:根据输入的图片返回动物详细信息
类比植物
@app.route('/api/classify_animals', methods=['POST'])
def classify_animals():
try:
if 'image' not in request.files:
return jsonify({'success': False, 'error': 'No image uploaded'}), 400
file = request.files['image']
if file.filename == '':
return jsonify({'success': False, 'error': 'No selected file'}), 400
recognition_result = classify_animal(file)
return jsonify(recognition_result)
except Exception as e:
return jsonify({'success': False, 'error': str(e)}), 500
近期,进行AI接口的调用时出现错误,显示"No result found",表示调用失败

回到原始的识别的代码进行探察,发现token过期了


可以每次都请求重新拉取token,将获取token封装进一个函数中,修改代码如下:
def get_access_token():
#client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=官网获取的AK&client_secret=官网获取的SK'
response = requests.get(host)
if response:
access_token = response.json().get("access_token")
return access_token
else:
print("获取访问令牌失败。")
return None
access_token = get_access_token()
接口5:根据输入的文字描述返回动物详细信息
与植物识别进行同样操作
@app.route('/api/submit_description_animal', methods=['POST'])
def submit_description_animal():
try:
if 'description' not in request.form:
return jsonify({'success': False, 'error': 'No description provided'}), 400
description = request.form['description']
API_KEY = '此处省略,创建应用处获取'
SECRET_KEY = '此处省略,创建应用处获取'
chat_client = QIANFAN(API_KEY, SECRET_KEY)
chat_result = chat_client.chat(model='ernie_speed',
message=f"请根据下面描述详细说明一下这个动物: {description}")
details = chat_result["result"]
return jsonify({
'success': True,
'details': details
})
except Exception as e:
return jsonify({'success': False, 'error': str(e)}), 500
(4)实践总结与收获
在本次实践中,我负责实现图片识别、大模型接口调用和后端代码编写,通过这个项目,我深入了解了API调用在实际应用中的工作流程。面对如何准确识别动植物图像的挑战,我选择了百度AI接口,并成功实现了图像识别功能。这是我首次调用AI接口,虽然起初遇到了困难,但通过不断学习和实践,我逐渐熟悉了整个流程,包括创建应用获取API Key和Secret Key,以及获取access_token。我还编写了Python脚本来处理请求参数,包括图像数据的base64编码和urlencode处理,并分析API返回的结果,提取置信度最高的名称作为识别结果。
为了获取动植物的详细信息,我探索并选择了千帆大模型API,并基于之前的经验,较为容易地完成了接口调用。在后端代码编写方面,我开发了Flask接口,实现了实时爬取相似图片、根据上传图片返回植物详细信息的功能,以及根据用户提交的文字描述返回植物和动物详细信息的功能。我还加入了异常处理机制,确保了接口的稳定性和健壮性,并通过封装函数和类,提高了代码的可重用性和可维护性。
通过本次实践,我的编程能力、API调用技巧和后端开发能力得到了显著提升,学会了如何面对和解决实际开发中遇到的问题,提高了问题解决能力,并与团队成员紧密合作,提高了团队协作能力。
最后作为组长,真的非常感谢各个组员的积极配合,每个组员都能够积极响应和高效工作,总是迅速而准确地完成自己的任务,极大地推动了实践的进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号