数据采集与融合技术实践作业三
数据采集与融合技术作业三
码云链接:2022级数据采集与融合技术 - 码云 (gitee.com)
作业①:
-
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
-
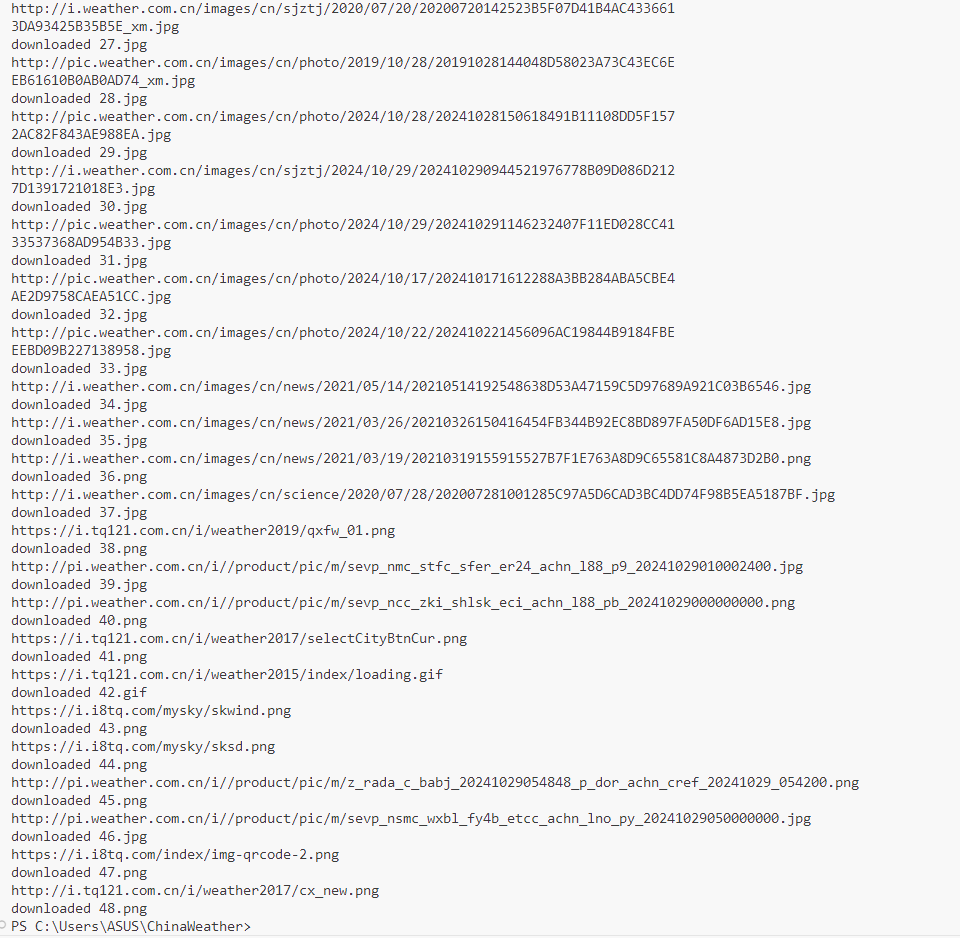
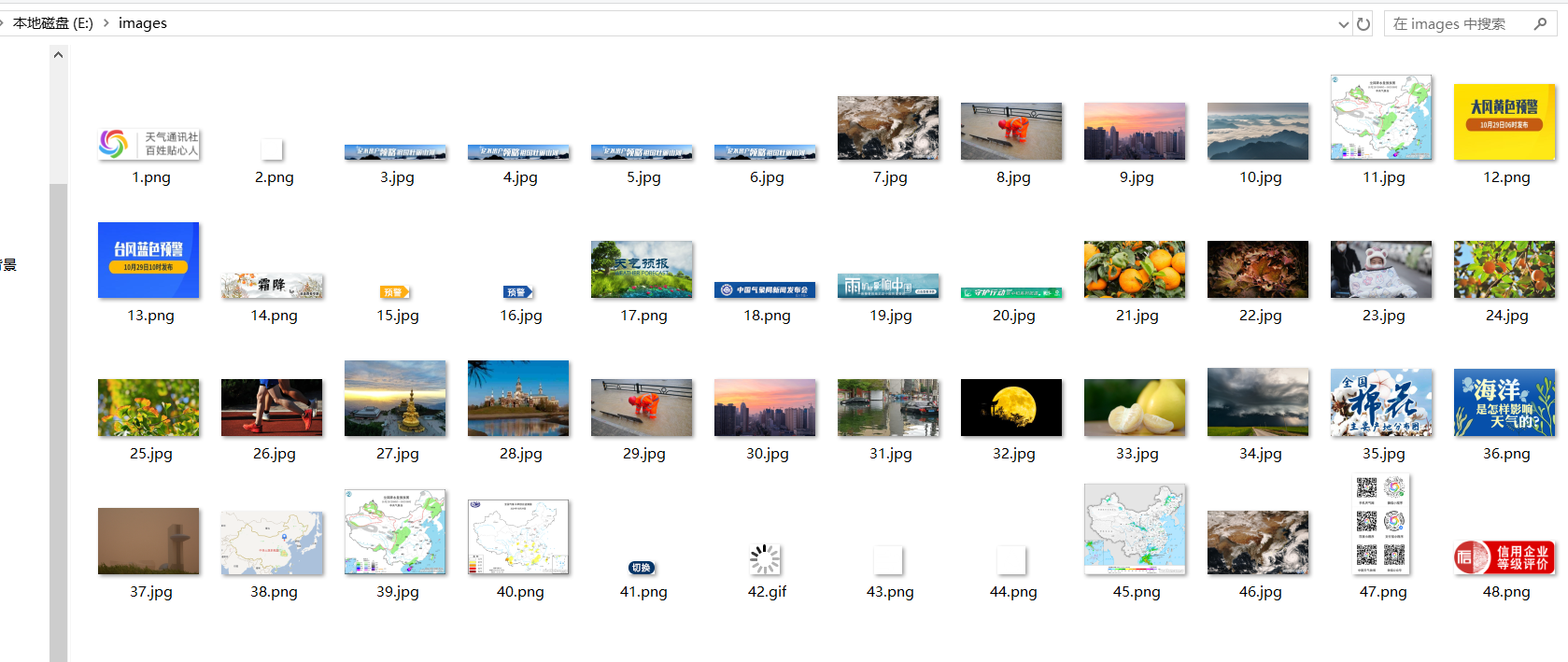
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
(1)实验过程
天气网站单页面爬取
创建Scrapy项目:
部分代码:
my_spiders.py
说明:这个Spider负责爬取中国气象网的图片。它首先将响应内容解码,然后使用XPath表达式提取所有img标签的src属性。对于每个找到的图片URL,它创建一个ChinaWeatherItem实例,并将URL存储在其中,然后yield返回这个item。
from items import ChinaWeatherItem
import scrapy
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
try:
data = response.body.decode()
selector = scrapy.Selector(text=data)
srcs = selector.xpath('//img/@src').extract() # 选择图像文件的src地址
for src in srcs:
print(src)
# 将提取出的src交由item处理
item = ChinaWeatherItem()
item['src'] = src
yield item
except Exception as err:
print(err)
items.py
说明:定义了一个Scrapy Item,用于存储爬取的图片信息。这里只有一个字段src,用于保存图片的URL。
import scrapy
class ChinaWeatherItem(scrapy.Item):
src = scrapy.Field()
pass
pipelines.py
说明:负责处理Spider返回的图片URL,并将其下载到本地。它使用urllib.request来发送HTTP请求并接收图片数据,然后将数据写入本地文件。
import urllib.request
import pymysql
from itemadapter import ItemAdapter
class ChinaWeatherPipeline:
count = 0
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
def process_item(self, item, spider):
try:
self.count += 1
src = item['src']
if src[len(src) - 4] == ".":
ext = src[len(src) - 4:]
else:
ext = ""
req = urllib.request.Request(src, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("E:\\images\\" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(self.count) + ext)
except Exception as err:
print(err)
return item
settings.py
说明:这个文件包含了Scrapy项目的配置。ROBOTSTXT_OBEY设置为False,以忽略网站的robots.txt规则。ITEM_PIPELINES设置了启用的Pipeline和其优先级。其他设置涉及到请求指纹和响应编码。
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ChinaWeather.pipelines.ChinaWeatherPipeline': 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
run.py
说明:这个脚本用于运行Scrapy Spider。它直接调用cmdline.execute方法来执行指定的Spider文件,同时禁用了日志输出。
from scrapy import cmdline
cmdline.execute("scrapy runspider C:\\Users\\ASUS\\ChinaWeather\\ChinaWeather\\spiders\\my_spiders.py -s LOG_ENABLED=false".split())
码云链接:
输出结果:
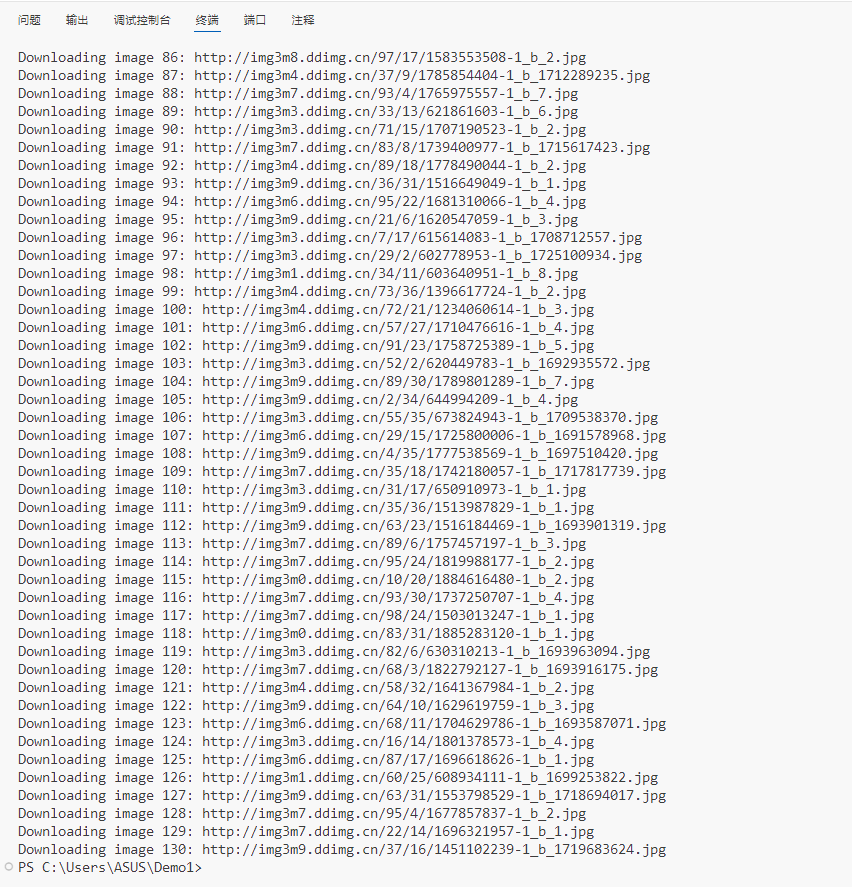
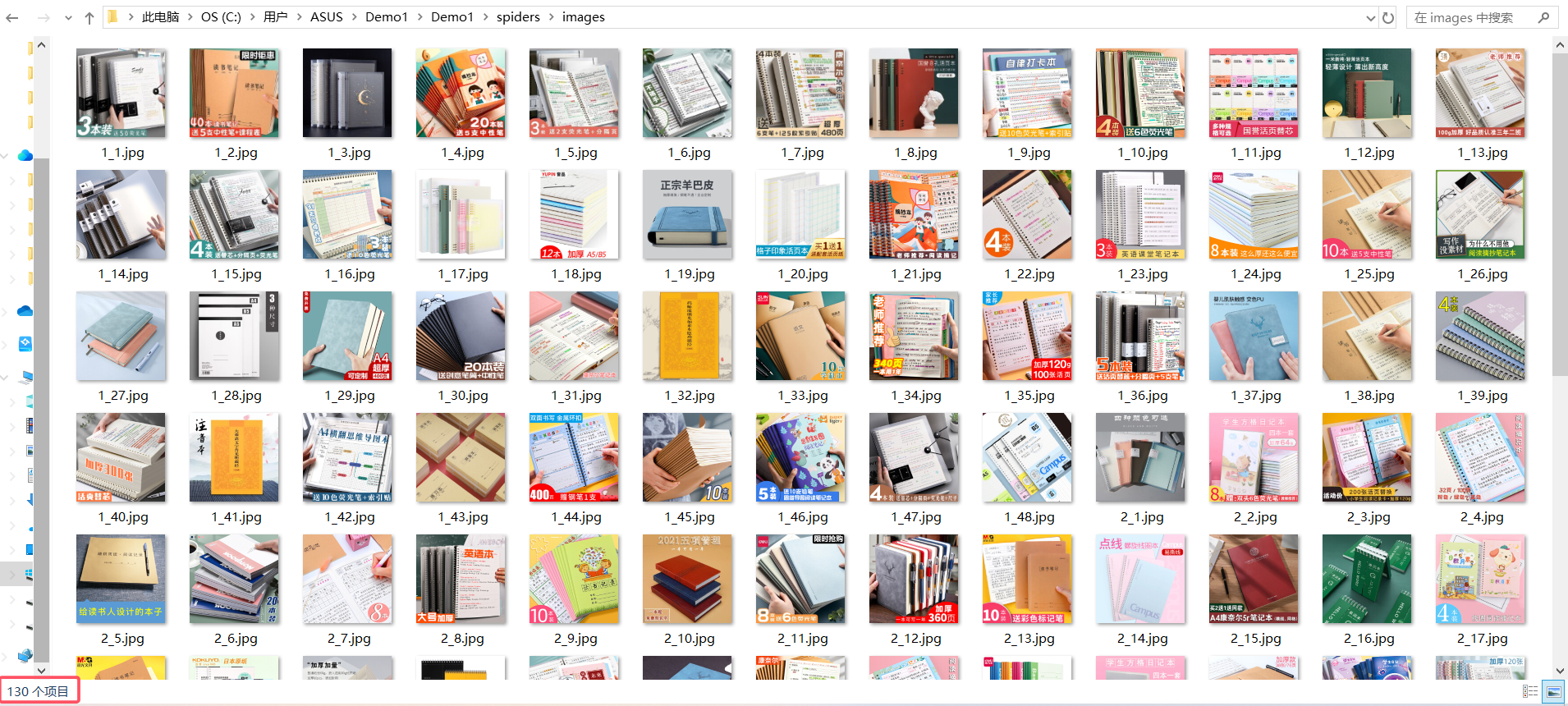
当当网实现翻页和定量爬取:总页数30(学号尾数2位)、总下载的图片数量130(尾数后3位)
部分代码:
books.py
说明: 定义了一个名为BooksSpider的Scrapy Spider,用于爬取当当网某一分类下的书籍封面图片。Spider通过XPath选择器提取图片URL,并根据设置的最大下载图片数量和页数进行限制。
import scrapy
from items import Demo1Item
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["category.dangdang.com"]
start_urls = ["https://category.dangdang.com/cid10009512.html"]
base_url = "https://category.dangdang.com/pg"
page = 1
count = 0
max_images = 130 # 最大下载图片数量
max_pages = 30 # 最大爬取页数
def parse(self, response):
li_list = response.xpath('//ul[@id="component_47"]/li')
id = 0
for li in li_list:
id += 1
src = li.xpath('./a/img/@data-original').extract_first()
if not src:
src = li.xpath('./a/img/@src').extract_first()
if src.startswith("//"):
src = "http:" + src
if self.count < self.max_images: # 检查是否达到最大图片数量限制
images = Demo1Item(src=src, id=id, page=self.page)
yield images
self.count += 1
print(f"Downloading image {self.count}: {src}") # 输出下载的URL信息
else:
break # 达到最大图片数量限制,终止爬取
if self.page < self.max_pages and self.count < self.max_images: # 检查是否达到最大页数限制
self.page += 1
url = self.base_url + str(self.page) + '-cid10009512.html'
yield scrapy.Request(url=url, callback=self.parse)
items.py
说明:定义了一个Scrapy Item,名为Demo1Item,用于存储爬取的图片信息。它包含三个字段:page(页面编号)、id(图片编号)和src(图片URL)。
import scrapy
class Demo1Item(scrapy.Item):
page = scrapy.Field()
id = scrapy.Field()
src = scrapy.Field()
pipelines.py
说明: 定义了一个名为Demo1Pipeline的Item Pipeline,用于处理Spider输出的Item。它将图片下载到本地文件系统中,并保存在指定的路径。
from itemadapter import ItemAdapter
import urllib.request
class Demo1Pipeline:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
def process_item(self, item, spider):
url = item.get('src')
filename = 'C:\\Users\\ASUS\\Demo1\\Demo1\\spiders\\images\\' + str(item.get('page')) + '_' + str(item.get('id')) + '.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item
settings.py
说明: 包含了Scrapy项目的配置设置,包括项目名称、Spider模块、管道设置、并发请求数等。这些设置控制Scrapy的行为,例如是否遵守robots.txt协议、请求指纹实现、响应编码等。
BOT_NAME = "Demo1"
SPIDER_MODULES = ["Demo1.spiders"]
NEWSPIDER_MODULE = "Demo1.spiders"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ChinaWeather.pipelines.ChinaWeatherPipeline': 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
run.py
from scrapy import cmdline
cmdline.execute("scrapy runspider C:\\Users\\ASUS\\Demo1\\Demo1\\spiders\\books.py -s LOG_ENABLED=false".split())
Scrapy的settings.py中的并发设置
说明: 这部分设置用于控制Scrapy爬虫的并发请求和下载速度。DOWNLOAD_DELAY设置请求之间的延迟,CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP设置每个域名或IP的并发请求数。
# 设置为0.5意味着Scrapy将等待0.5秒后发起下一个请求。
DOWNLOAD_DELAY = 0.5
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
# 当以上两个值都为1时为单线程
输出结果:
(2)心得体会
在本次作业中,我成功地使用Scrapy框架对中国气象网进行了图片爬取。通过设置DOWNLOAD_DELAY和CONCURRENT_REQUESTS_PER_DOMAIN参数,实现了单线程和多线程的爬取方式,有效地控制了爬虫的并发请求和下载速度。在parse函数中,利用XPath表达式提取了网页上的图片src属性,并特别注意处理了相对路径和缺失src属性的情况。通过封装数据到ChinaWeatherItem对象并使用yield返回,确保了Scrapy框架能够正确处理这些数据。
此外,成功地使用Scrapy框架爬取了当当网上的本子商品图片,并对爬取的数量和页数进行了限制,分别设定为最多130张图片和30页。通过这个过程,我对Scrapy框架有了更深入的理解,尤其是对Item和Pipelines的应用。首先在parse函数中利用XPath表达式来提取网页上的数据。具体来说,我提取了所有id为"component_47"的ul标签下的li标签,这些标签包含了商品列表的关键信息。遍历这些li标签,从中提取了所需的商品信息。在提取图片src属性时,特别注意到了两种情况:如果图片src属性以"//"开头,其为相对路径,并进行了相应的处理;如果src属性不存在,则提取了a标签中的img标签的src属性作为图片的路径。在信息提取完毕后,我将这些数据封装到了一个Demo1Item对象中,并使用yield关键字将其返回。在遍历商品列表的过程中,我还考虑到了翻页的逻辑。当爬取到第130个商品时,停止了遍历。最终,将URL传递给scrapy.Request对象,并指定回调函数为parse,使得Scrapy框架能够继续执行parse函数,直至完成所有页面的数据爬取。
最终,所有图片被成功下载到本地的images文件夹中,并在控制台输出了下载的URL信息。
刚开始的时候并不是很顺利,各种文件的相互联系经常出错,仔细检查名称将名称改为正确的,慢慢就更加熟悉了。总的来说,这次实践加深了我对Scrapy框架的理解,提升了数据提取和处理能力。
作业②:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
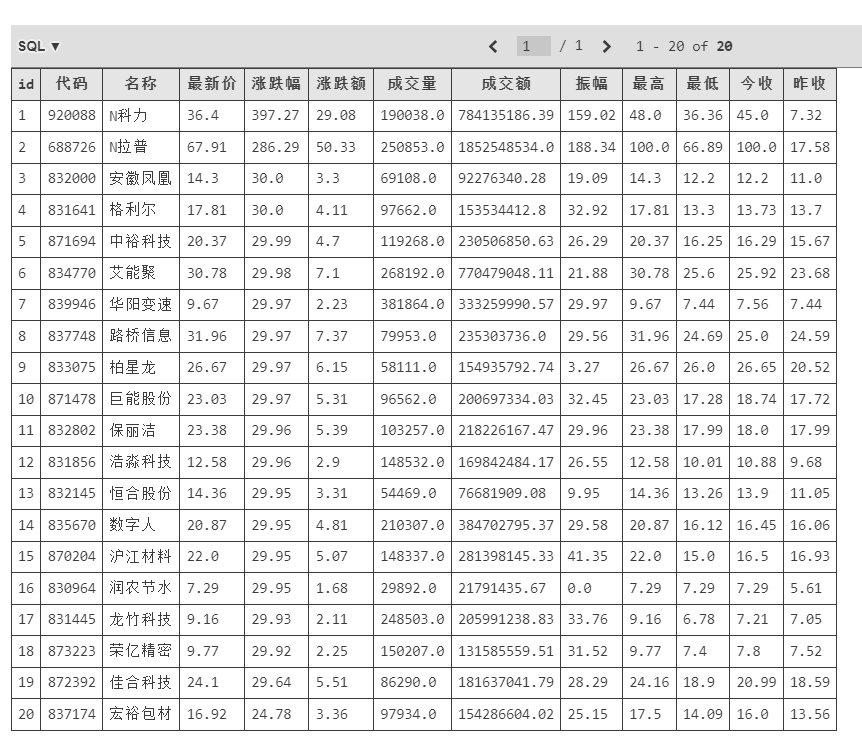
- 输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
| 序号 | 股票代码 | 股票名称 | 最新报价涨跌幅 | 涨跌额 | 成交量 | 振幅 | 最高 | 最底 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.20 |
| 2 | ..... |
(1)实验过程
创建Scrapy项目:

部分代码:
stock.py
import scrapy
import json
from items import DfstocksItem
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["quote.eastmoney.com"]
start_urls = ['https://56.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403078379325809608_1730184932354&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1730184932355']
def parse(self, response):
content = response.text
content = content.split('(')[1].split(')')[0]
json_data = json.loads(content)
data = json_data['data']['diff']
for obj in data:
item = DfstocksItem()
item['code'] = obj['f12']
item['name'] = obj['f14']
item['quotation'] = obj['f2']
item['percentage'] = obj['f3']
item['amount']= obj['f4']
item['volume'] = obj['f5']
item['turnover'] = obj['f6']
item['volatility'] = obj['f7']
item['highest'] = obj['f15']
item['lowest'] = obj['f16']
item['open'] = obj['f17']
item['close'] = obj['f18']
# print(item)
yield item
items.py
import scrapy
class DfstocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
quotation = scrapy.Field()
percentage = scrapy.Field()
amount = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
volatility = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
open = scrapy.Field()
close = scrapy.Field()
pass
pipelines.py
from itemadapter import ItemAdapter
import sqlite3
class DfstocksPipeline:
def open_spider(self, spider):
self.con = sqlite3.connect("沪深京A股.db")
self.cursor = self.con.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY,
代码 TEXT,
名称 TEXT,
最新价 REAL,
涨跌幅 REAL,
涨跌额 REAL,
成交量 REAL,
成交额 REAL,
振幅 REAL,
最高 REAL,
最低 REAL,
今收 REAL,
昨收 REAL
)
''')
def process_item(self, item, spider):
self.cursor.execute('''
insert into stocks(
代码 ,名称 ,最新价 ,涨跌幅 ,涨跌额 ,成交量 ,成交额 ,振幅 ,最高 ,最低 ,今收 ,昨收
)
VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item['code'],
item['name'],
item['quotation'],
item['percentage'],
item['amount'],
item['volume'],
item['turnover'],
item['volatility'],
item['highest'],
item['lowest'],
item['open'],
item['close']
)
)
return item
def close_spider(self, spider):
self.con.commit()
self.con.close()
settings.py
BOT_NAME = "Dfstocks"
SPIDER_MODULES = ["Dfstocks.spiders"]
NEWSPIDER_MODULE = "Dfstocks.spiders"
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
"Dfstocks.pipelines.DfstocksPipeline": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
run.py
from scrapy import cmdline
cmdline.execute("scrapy runspider C:\\Users\\ASUS\\Dfstocks\\Dfstocks\\spiders\\stock.py -s LOG_ENABLED=false".split())
输出结果:
(2)心得体会
通过Scrapy框架结合XPath和MySQL数据库存储技术,使用抓包的方式爬取了东方财富网的股票相关信息。在parse函数中,我解析了JSON格式的响应数据,提取了股票代码、名称、最新报价等关键信息,并将其封装到DfstocksItem对象中。随后,在Pipeline中,将这些数据存储到了MySQL数据库中,实现了数据的持久化。增强了数据处理和存储的能力。
作业③:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
-
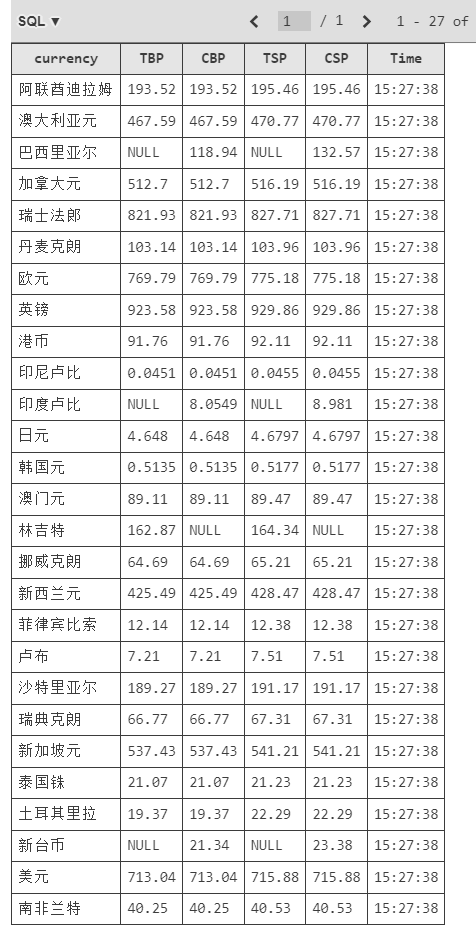
输出信息:
Currency TBP CBP TSP CSP Time 阿联酋迪拉姆 198.58 192.31 199.98 206.59 11:27:14
(1)实验过程
创建Scrapy项目:

部分代码:
currency.py
import scrapy
from items import BankItem
class CurrencySpider(scrapy.Spider):
name = "currency"
allowed_domains = ["https://www.boc.cn/sourcedb/whpj/"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
li_list = response.xpath('//div[2]/table[@align="left"]//tr')
# / html / body / div / div[5] / div[1] / div[2]
for li in li_list[1:]:
item = BankItem()
item['Currency'] = li.xpath('./td[1]/text()').extract_first()
item['TBP'] = li.xpath('./td[2]/text()').extract_first()
item['CBP'] = li.xpath('./td[3]/text()').extract_first()
item['TSP'] = li.xpath('./td[4]/text()').extract_first()
item['CSP'] = li.xpath('./td[5]/text()').extract_first()
item['Time'] = li.xpath('./td[8]/text()').extract_first()
yield item
pass
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pass
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import sqlite3
class BankPipeline:
def open_spider(self, spider):
self.con = sqlite3.connect("外汇牌价.db")
self.cursor = self.con.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS money (
currency TEXT,
TBP REAL,
CBP REAL,
TSP REAL,
CSP REAL,
Time TEXT
)
''')
def process_item(self, item, spider):
self.cursor.execute('''
insert into money(
currency,TBP,CBP,TSP,CSP,Time
)
VALUES(?, ?, ?, ?, ?, ?)
''', (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
)
)
return item
def close_spider(self, spider):
self.con.commit()
self.con.close()
settings.py
BOT_NAME = "Bank"
SPIDER_MODULES = ["Bank.spiders"]
NEWSPIDER_MODULE = "Bank.spiders"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
"Bank.pipelines.BankPipeline": 300,
}
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
run.py
from scrapy import cmdline
cmdline.execute("scrapy runspider C:\\Users\\ASUS\\BANK\\Bank\\spiders\\currency.py -s LOG_ENABLED=false".split())
输出结果:
(2)心得体会
使用Scrapy框架爬取了中国银行网站的外汇牌价数据,并将其存储到SQLite数据库中。通过XPath提取了外汇数据的各个字段,包括货币名称、买入价、卖出价等信息。在parse函数中,遍历了表格中的每一行,提取了所需的信息并封装到BankItem对象中。通过Pipeline,将数据插入到SQLite数据库中,确保数据的持久化存储。
通过这次作业,进一步加深了对Scrapy框架的理解,掌握了如何处理网页数据并将其存储到数据库中。整个过程让我体会到了数据采集与存储的完整流程,进一步增强数据处理和存储的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号