数据采集与融合技术实践作业一
数据采集与融合技术实践作业一
码云链接:2022级数据采集与融合技术 - 码云 (gitee.com)
作业①:
·要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
·输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
(1)实验过程
通过F12寻找相关信息:
通过审查元素,找到对应信息的位置,再分析其格式
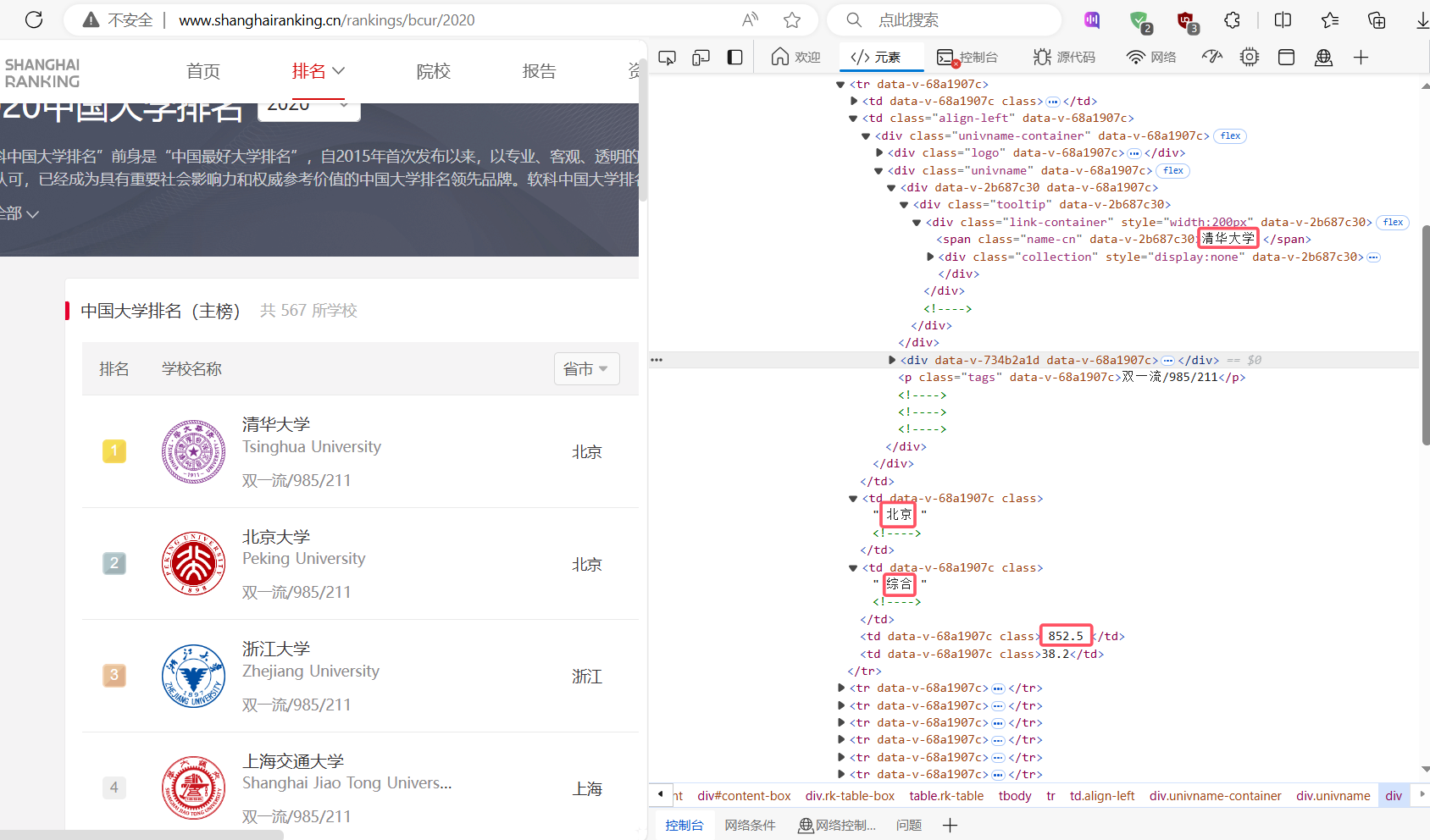
代码实现:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def daxue():
url="http://www.shanghairanking.cn/rankings/bcur/2020";
req=urllib.request.Request(url)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
soup=BeautifulSoup(data,"html.parser")
list=soup.select("tbody tr")
tplt = "{0:^13}\t{1:^13}\t{2:^13}\t{3:^10}\t{4:^10}"
print(tplt.format("排名","学校","省市","类型","总分",chr(12288)))
for item in list[0:40]:
ls=item.select("td")
length=len(ls)
count=0
inf=[]
for i in ls[0:5]:
count+=1
text = i.text.replace(" ", "").replace("\n", "")
inf.append(text)
# 依次输出大学信息
print(tplt.format(inf[0],inf[1],inf[2],inf[3],inf[4],chr(12288)))
daxue()
输出结果:

(2)心得体会
通过本题实验,我学习到了如何使用Python的requests和BeautifulSoup库来爬取和解析网页数据。我掌握了通过分析网页的HTML结构来精确定位所需数据,并将其以一种结构化的方式提取出来。
此外,我还体会到了格式化输出的重要性。良好的格式化输出能够使数据呈现得更加清晰、易于阅读。在处理含有中文字符的数据时,我遇到了字符对齐的挑战,这可能会影响输出的美观性。通过巧妙地使用chr(12288)来插入空格,我成功解决了对齐问题,使得输出结果更加整。若没有进行格式化输出,本题的输出结果会占用多行(如不可见字符\n)。
通过这次实践,我不仅掌握了基本的网络爬虫技术,还学会了如何格式化输出数据,使其更加易于阅读和理解
作业②:
·要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
·输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
(1)实验过程
通过F12寻找相关信息
通过审查元素,找到对应信息的位置,再分析其格式
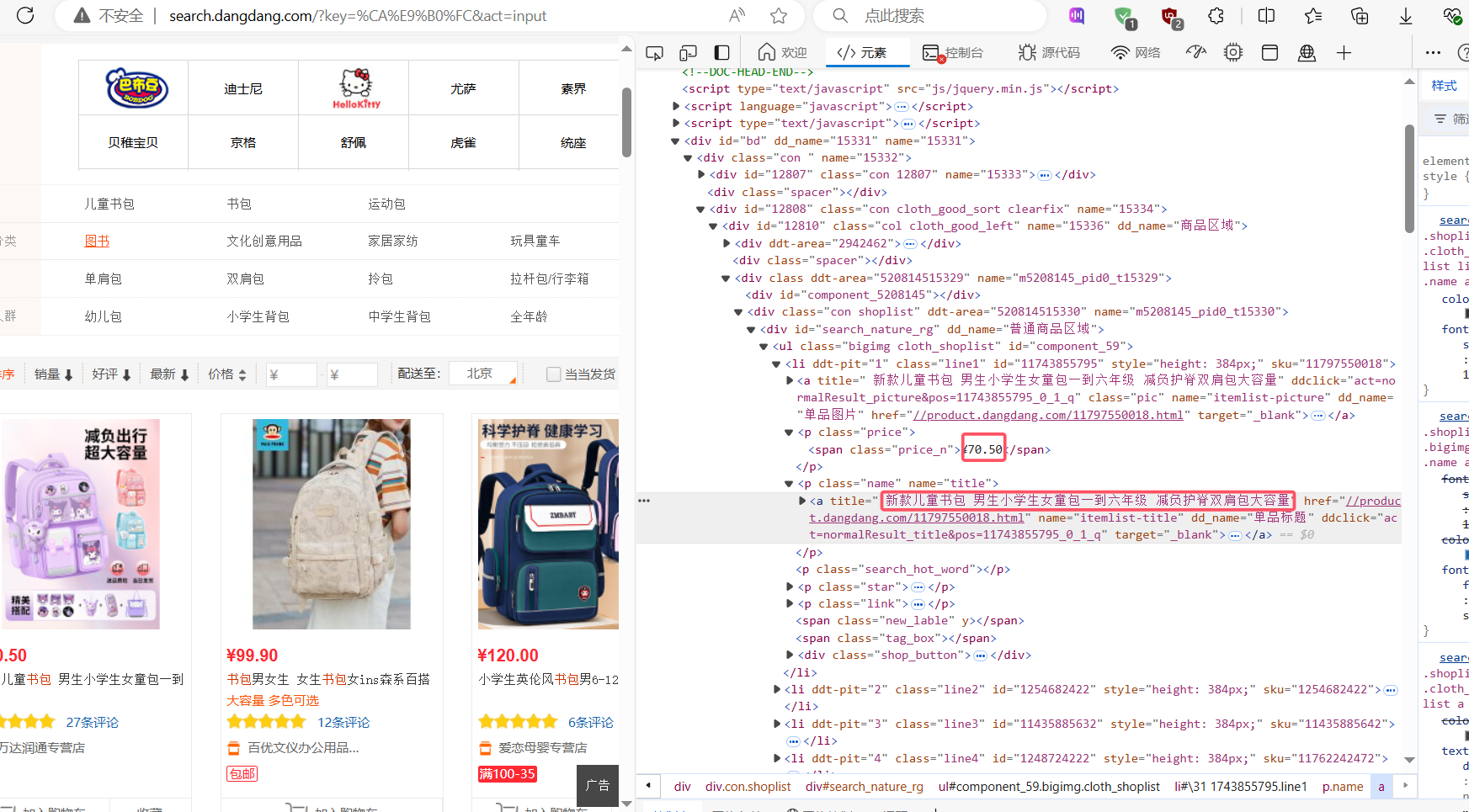
部分代码:
使用re.search查找商品列表
match = re.search(r'<ul class="bigimg cloth_shoplist".*?>(.*?)</ul>', data, re.S)
使用正则表达式匹配li标签,查找价格以及商品名称
items = re.findall(r'<li.*?>(.*?)</li>', data, re.S)
i = 1
for item in items:
price_match = re.search(r'<span class="price_n">¥(.*?)</span>', item)
title_match = re.search(r'title="(.*?)"', item)
if price_match and title_match:
price = price_match.group(1).strip()
name = title_match.group(1).strip()
print(f"{i}\t{price}\t{name}")
i += 1
else:
print(f"{i}\t未找到价格或名称")
i += 1
输出结果:

(2)心得体会
在完成作业②时,我选择了一个商城网站进行商品比价爬虫的设计和实现。这个过程中,我首先通过F12开发者工具分析了网页的结构,找到了商品列表的HTML标签和对应的价格、名称信息。然后,我使用了Python的requests库来获取网页内容,并利用re库中的正则表达式来提取商品的名称和价格。
这个实验让我认识到了正则表达式在文本处理中的威力,尤其是在提取复杂或不规则文本数据时。
通过本次实验,我能够通过 urllib 网页下载函数方法下载网页 能够实现编码的转换、能够根据功能组件的不同实现需求,使用正则表达式匹配并提取网页中的数据。
作业③:
·要求:爬取一个给定网页https://news.fzu.edu.cn/yxfd.htm或者自选网页的所有JPEG和JPG格式文件
·输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
(1)实验过程
通过F12寻找相关信息:
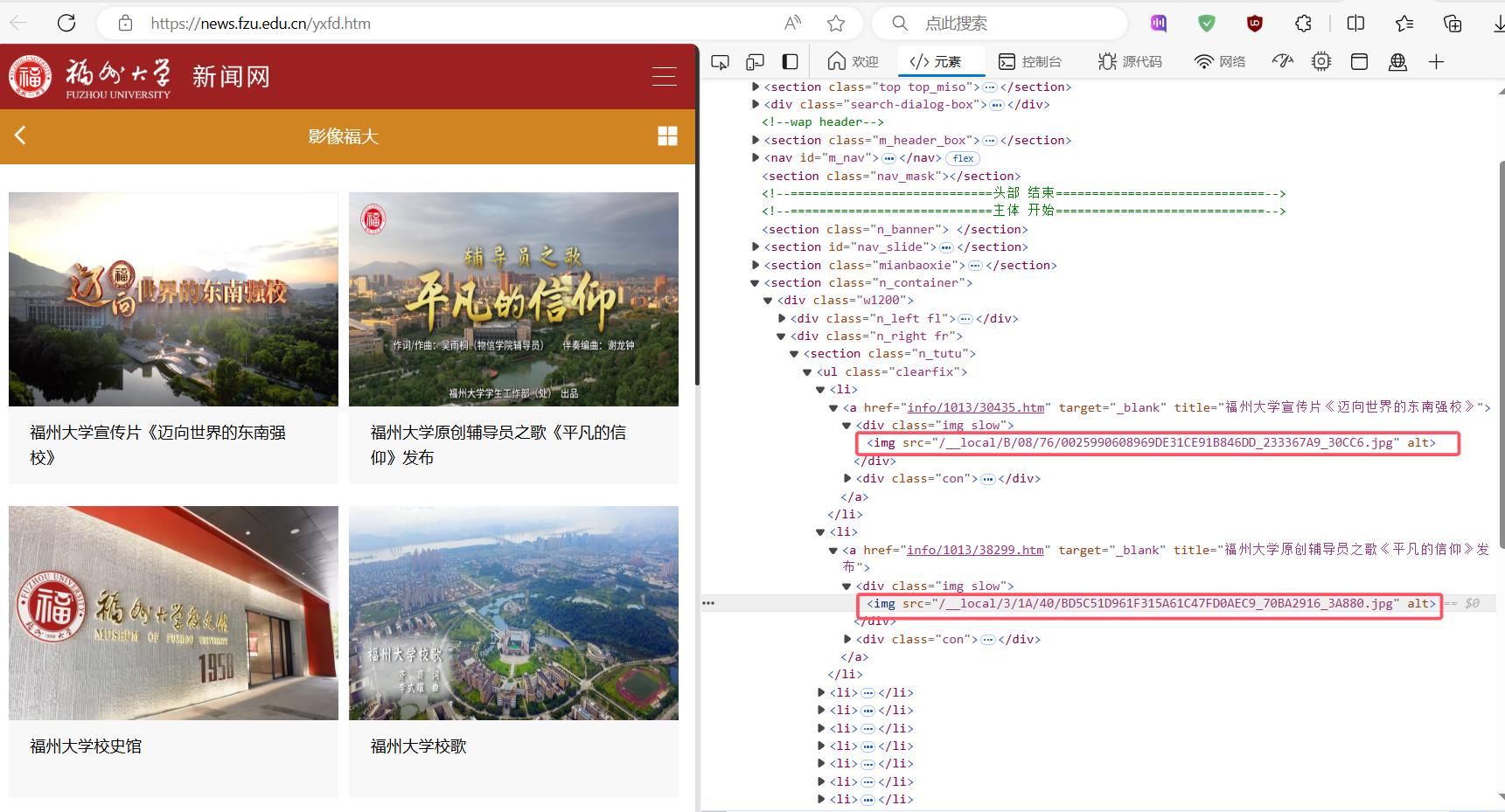
部分代码:
import requests
import os
import re
import time
from urllib.parse import urljoin
# 设置图片存储目录
image_folder = 'downloaded_images'
os.makedirs(image_folder, exist_ok=True)
# 目标网址,确保链接是正确的
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 发送请求并设置编码
try:
response = requests.get(url)
response.encoding = 'utf-8'
time.sleep(6) # 等待页面加载
# 使用正则表达式匹配图片链接
image_pattern = re.compile(r'src="(.*?\.jpe?g)"')
images = image_pattern.findall(response.text)
# 下载图片
for i, image_url in enumerate(images, 1):
if not image_url.startswith('http'):
image_url = url.rsplit('/', 1)[0] + '/' + image_url
print(f"Attempting to download: {image_url}") # 打印出图片URL进行调试
try:
image_data = requests.get(image_url).content
image_name = os.path.join(image_folder, f'image_{i}.jpg')
with open(image_name, 'wb') as f:
f.write(image_data)
print(f'下载完成: {image_name}')
except requests.RequestException as e:
print(f"Failed to download image {i}: {e}")
except requests.RequestException as e:
print(f"Failed to access the webpage: {e}")
print("Please check the webpage URL's legitimacy or try again later.")
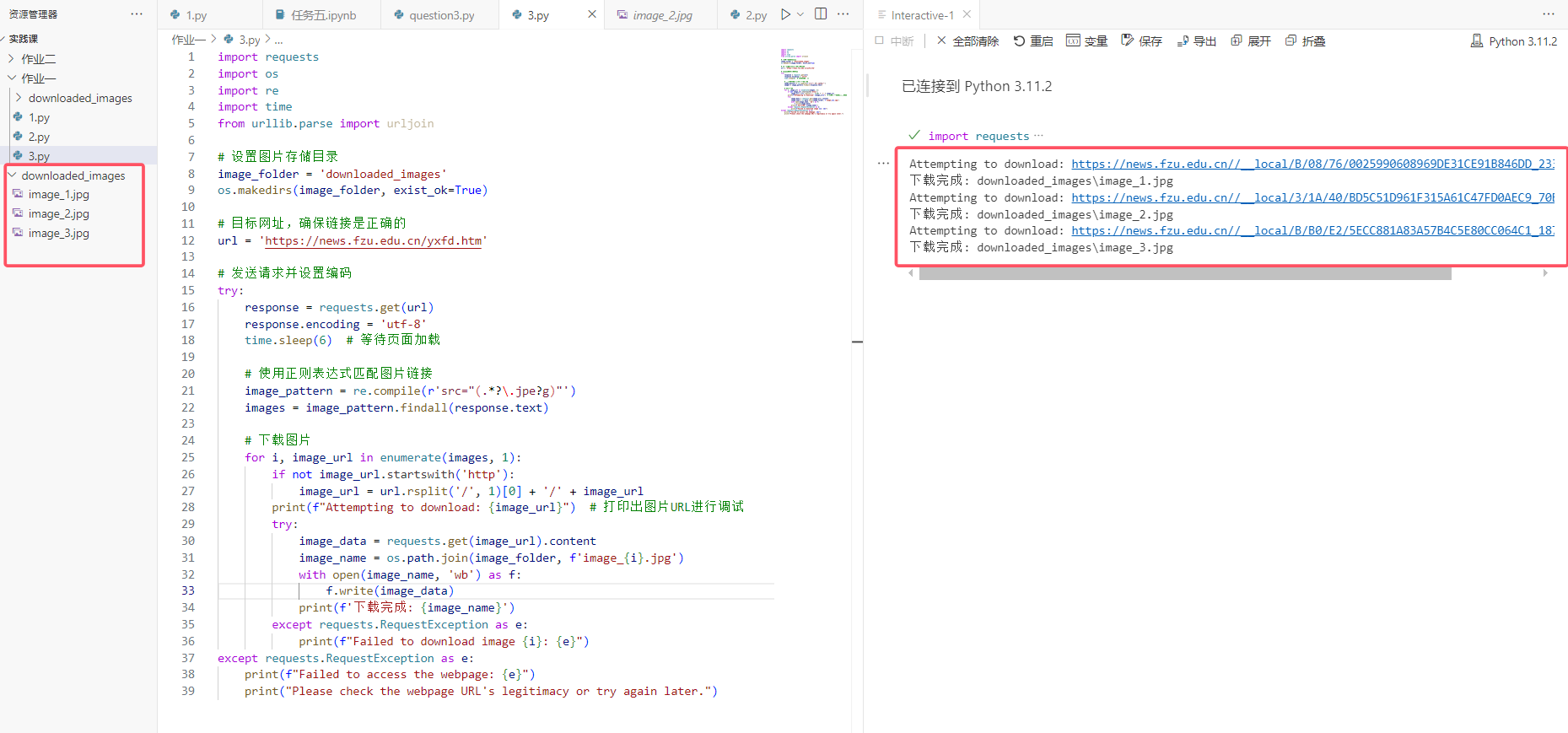
输出结果:
只有三张图片满足JPEG和JPG格式,其他都为PNG格式,符合实验要求。

(2)心得体会
我学习了如何使用Python的requests库和正则表达式来爬取网页中的所有JPEG和JPG格式的图片。这个过程不仅让我掌握了基本的网络爬虫技术,还让我学会了如何处理文件下载和保存。
在实现过程中,我遇到了一些挑战,比如如何处理相对路径的图片链接,以及如何确保下载的图片数据是完整的。通过使用urljoin函数和添加异常处理,我成功地解决了这些问题。
此外,我还学习到了如何使用os库来创建目录和保存文件,这让我对文件操作有了更深的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号