Python数据结构——散列表
散列表的实现常常叫做散列(hashing)。散列仅支持INSERT,SEARCH和DELETE操作,都是在常数平均时间执行的。需要元素间任何排序信息的操作将不会得到有效的支持。
散列表是普通数组概念的推广。如果空间允许,可以提供一个数组,为每个可能的关键字保留一个位置,就可以运用直接寻址技术。
当实际存储的关键字比可能的关键字总数较小时,采用散列表就比较直接寻址更为有效。在散列表中,不是直接把关键字用作数组下标,而是根据关键字计算出下标,这种
关键字与下标之间的映射就叫做散列函数。
1.散列函数
一个好的散列函数应满足简单移植散列的假设:每个关键字都等可能的散列到m个槽位的任何一个中去,并与其它的关键字已被散列到哪个槽位无关。
1.1 通常散列表的关键字都是自然数。
1.11 除法散列法
通过关键字k除以槽位m的余数来映射到某个槽位中。
hash(k)=k mod m
应用除法散列时,应注意m的选择,m不应该是2的幂,通常选择与2的幂不太接近的质数。
1.12 乘法散列法
乘法方法包含两个步骤,第一步用关键字k乘上常数A(0<A<1),并取出小数部分,然后用m乘以这个值,再取结果的底(floor)。
hash(k)=floor(m(kA mod 1))
乘法的一个优点是对m的选择没有什么特别的要求,一般选择它为2的某个幂。
一般取A=(√5-1)/2=0.618比较理想。
1.13 全域散列
随机的选择散列函数,使之独立于要存储的关键字。在执行开始时,就从一族仔细设计的函数中,随机的选择一个作为散列函数,随机化保证了
没有哪一种输入会始终导致最坏情况发生。
1.2 如果关键字是字符串,散列函数需要仔细的选择
1.2.1 将字符串中字符的ASCII码值相加
def _hash(key,m):
hashVal=0
for _ in key:
hashVal+=ord(_)
return hashVal%m
由于ascii码最大127,当表很大时,函数不会很好的分配关键字。
1.2.2 取关键字的前三个字符。
值27表示英文字母表的字母个数加上一个空格。
hash(k)=k[0]+27*k[1]+729*k[2]
1.2.3 用霍纳法则把所有字符扩展到n次多项式。
用32代替27,可以用于位运算。
def _hash(key,m):
hashval=0
for _ in key:
hashval=(hashval<<5)+ord(_)
return hashval%m
2. 分离链接法
散列表会面临一个问题,当两个关键字散列到同一个值的时候,称之为冲突或者碰撞(collision)。解决冲突的第一种方法通常叫做分离链接法(separate chaining)。
其做法是将散列到同一个值的所有元素保留到一个链表中,槽中保留一个指向链表头的指针。
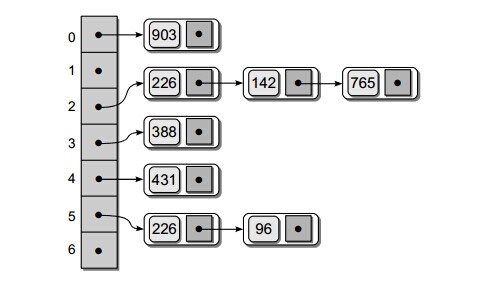
为执行FIND,使用散列函数来确定要考察哪个表,遍历该表并返回关键字所在的位置。
为执行INSERT,首先确定该元素是否在表中。如果是新元素,插入表的前端或末尾。
为执行DELETE,找到该元素执行链表删除即可。
散列表中元素个数与散列表大小的比值称之为装填因子(load factor)λ。
执行一次不成功的查找,遍历的链接数平均为λ,成功的查找则花费1+(λ/2)。
分离链接散列的一般做法是使得λ尽量接近于1。
代码:
class _ListNode(object):
def __init__(self,key):
self.key=key
self.next=None
class HashMap(object):
def __init__(self,tableSize):
self._table=[None]*tableSize
self._n=0 #number of nodes in the map
def __len__(self):
return self._n
def _hash(self,key):
return abs(hash(key))%len(self._table)
def __getitem__(self,key):
j=self._hash(key)
node=self._table[j]
while node is not None and node.key!=key :
node=node.next
if node is None:
raise KeyError,'KeyError'+repr(key)
return node
def insert(self,key):
try:
self[key]
except KeyError:
j=self._hash(key)
node=self._table[j]
self._table[j]=_ListNode(key)
self._table[j].next=node
self._n+=1
def __delitem__(self,key):
j=self._hash(key)
node=self._table[j]
if node is not None:
if node.key==key:
self._table[j]=node.next
self._-=1
else:
while node.next!=None:
pre=node
node=node.next
if node.key==key:
pre.next=node.next
self._n-=1
break
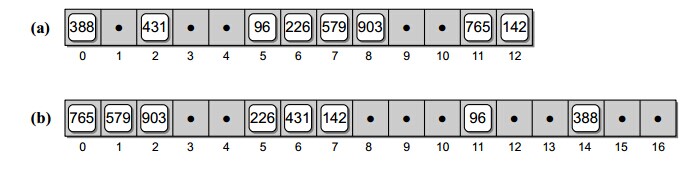
3.开放定址法
在开放定址散列算法中,如果有冲突发生,那么就要尝试选择另外的单元,直到找出空的单元为止。
h(k,i)=(h'(k)+f(i)) mod m,i=0,1,...,m-1 ,其中f(0)=0
3.1 线性探测法
函数f(i)是i的线性函数
h(k,i)=(h'(k)+i) mod m
相当于逐个探测每个单元

线性探测会存在一个问题,称之为一次群集。随着被占用槽的增加,平均查找时间也会不断增加。当一个空槽前有i个满的槽时,该空槽为下一个将被占用
槽的概率是(i+1)/m。连续被占用槽的序列会越来越长,平均查找时间也会随之增加。
如果表有一半多被填满的话,线性探测不是个好办法。
3.2 平法探测
平方探测可以取消线性探测中的一次群集问题。
h(k,i)=(h'(k)+c1i+c2i2) mod m
平方探测中,如果表的一半为空,并且表的大小是质数,保证能够插入一个新的元素。
平方探测会引起二次群集的问题。
3.3 双散列
双散列是用于开放定址法的最好方法之一。
h(k,i)=(h1(k)+ih2(k)) mod m
为能查找整个散列表,值h2(k)要与m互质。确保这个条件成立的一种方法是取m为2的幂,并设计一个总产生奇数的h2。另一种方法是取m为质数,并设计一个总是产生
较m小的正整数的h2。
例如取:
h1(k)=k mod m,h2(k)=1+(k mod m'),m'为略小于m的整数。
给定一个装填因子λ的开放定址散列表,插入一个元素至多需要1/(1-λ)次探查。
给定一个装填因子λ<1的开放定址散列表,一次成功查找中的期望探查数至多为(1/λ)ln(1/1-λ)。
4. 再散列
如果表的元素填得太满,那么操作的运行时间将开始消耗过长。一种解决方法是当表到达某个装填因子时,建立一个大约两倍大的表,而且使用一个相关的新散列函数,
扫描整个原始散列表,计算每个元素的新散列值并将其插入到新表中。
为避免开放定址散列查找错误,删除操作要采用懒惰删除。
代码
class HashEntry(object):
def __init__(self,key,value):
self.key=key
self.value=value
class HashTable(object):
_DELETED=HashEntry(None,None) #用于删除
def __init__(self,tablesize):
self._table=tablesize*[None]
self._n=0
def __len__(self):
return self._n
def __getitem__(self,key):
found,j=self._findSlot(key)
if not found:
raise KeyError
return self._table[j].value
def __setitem__(self,key,value):
found,j=self._findSlot(key)
if not found:
self._table[j]=HashEntry(key,value)
self._n+=1
if self._n>len(self._table)//2:
self._rehash()
else:
self._table[j].value=value
def __delitem__(self,key):
found,j=self._findSlot(key)
if found:
self._table[j]=HashTable._DELETED # 懒惰删除
def _rehash(self):
oldList=self._table
newsize=2*len(self._table)+1
self._table=newsize*[None]
self._n=0
for entry in oldList:
if entry is not None and entry is not HashTable._DELETED:
self[entry.key]=entry.value
self._n+=1
def _findSlot(self,key):
slot=self._hash1(key)
step=self._hash2(key)
firstSlot=None
while True:
if self._table[slot] is None:
if firstSlot is None:
firstSlot=slot
return (False,firstSlot)
elif self._table[slot] is HashTable._DELETED:
firstSlot=slot
elif self._table[slot].key==key:
return (True,slot)
slot=(slot+step)%len(self._table)
def _hash1(self,key):
return abs(hash(key))%len(self._table)
def _hash2(self,key):
return 1+abs(hash(key))%(len(self._table)-2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号