得力助手 Typora 与 OSS 图床
 Typora 安装与使用、
Typora插件、
OSS图床配置、
机器学习导论、
机器学习的基本思路、
机器学习实操的7个步骤
Typora 安装与使用、
Typora插件、
OSS图床配置、
机器学习导论、
机器学习的基本思路、
机器学习实操的7个步骤
“随便输入文字的时候,都是输入 asdf” ——程序员笑话
Typora 安装
安装教程
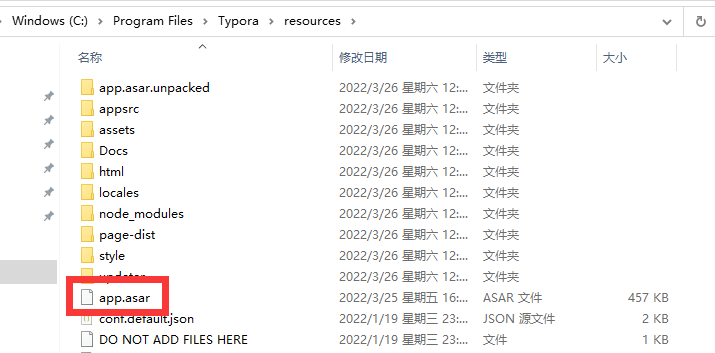
1. 先安装 typora-setup-x64-1.2.3.exe ,记下安装路径
2. 将 app.asar 替换到安装路径下的resources文件夹,替换掉app.asar文件
3. 重启typora
4. 输入邮箱、注册码
邮箱:123456@qq.com (随便写)
授权码: E8Q9Y5-KXMTL5-7578SL-4S5XKS
主题安装
安装教程:typora-latex-theme

Typora 使用
教程
教程视频:B站链接
教程下载:MarkDown教程.zip
图表:Draw Diagrams With Markdown - Typora Support
笔记
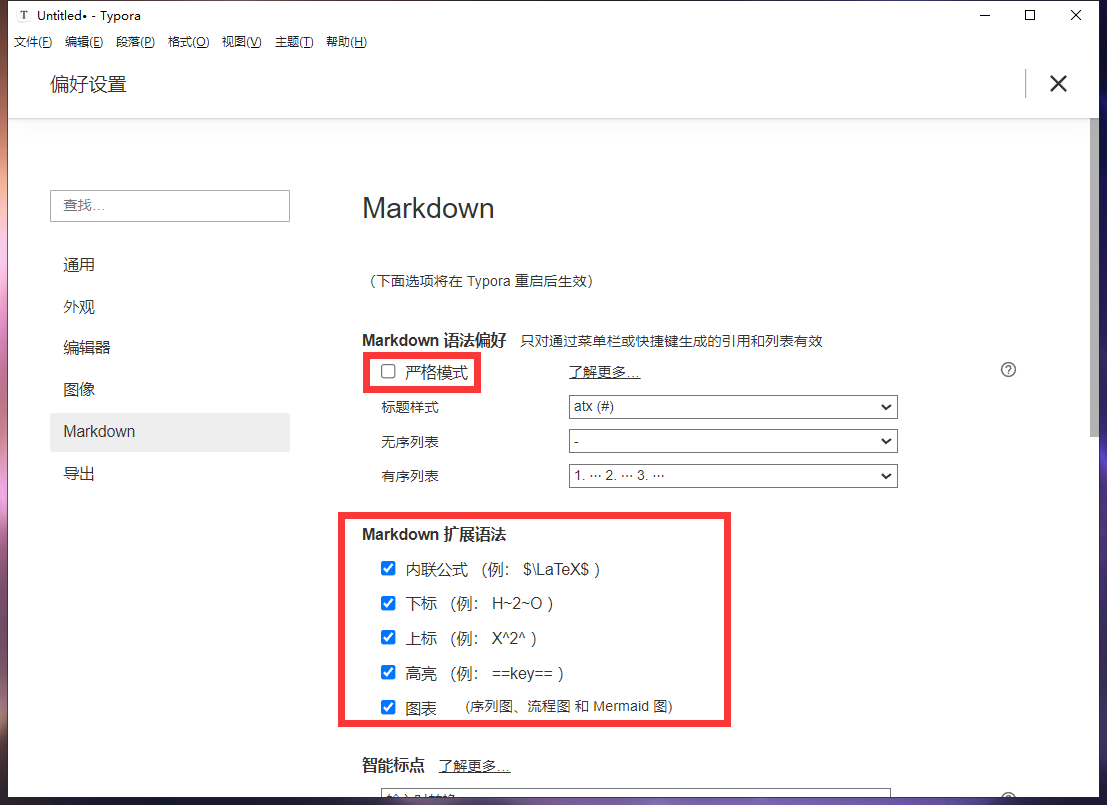
win + ; 表情符号
ctrl + t 插入表格
阿里云OSS图床
图片上传到oss有利于我们将文档拷贝到其他一些平台
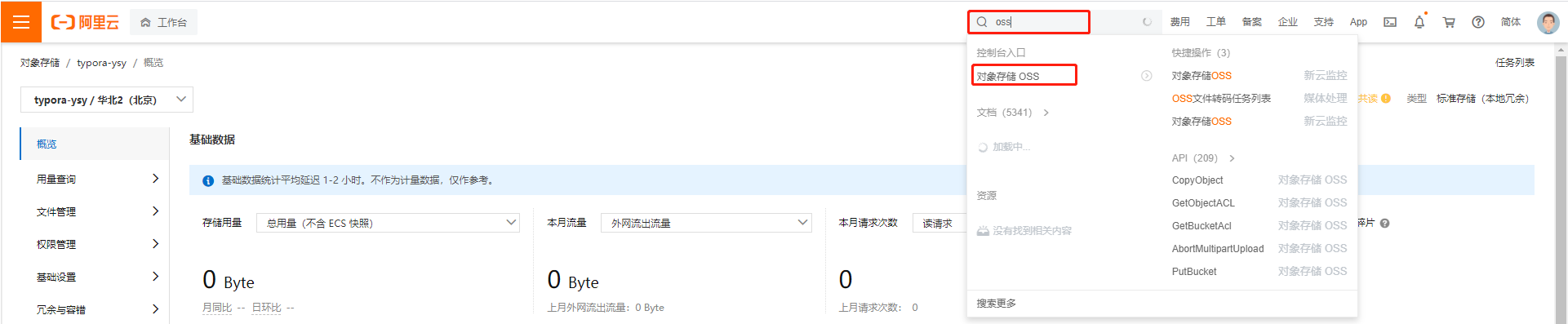
登录阿里云 获取oss Bucket
直接搜索oss,选择对象存储oss
点击创建Bucket
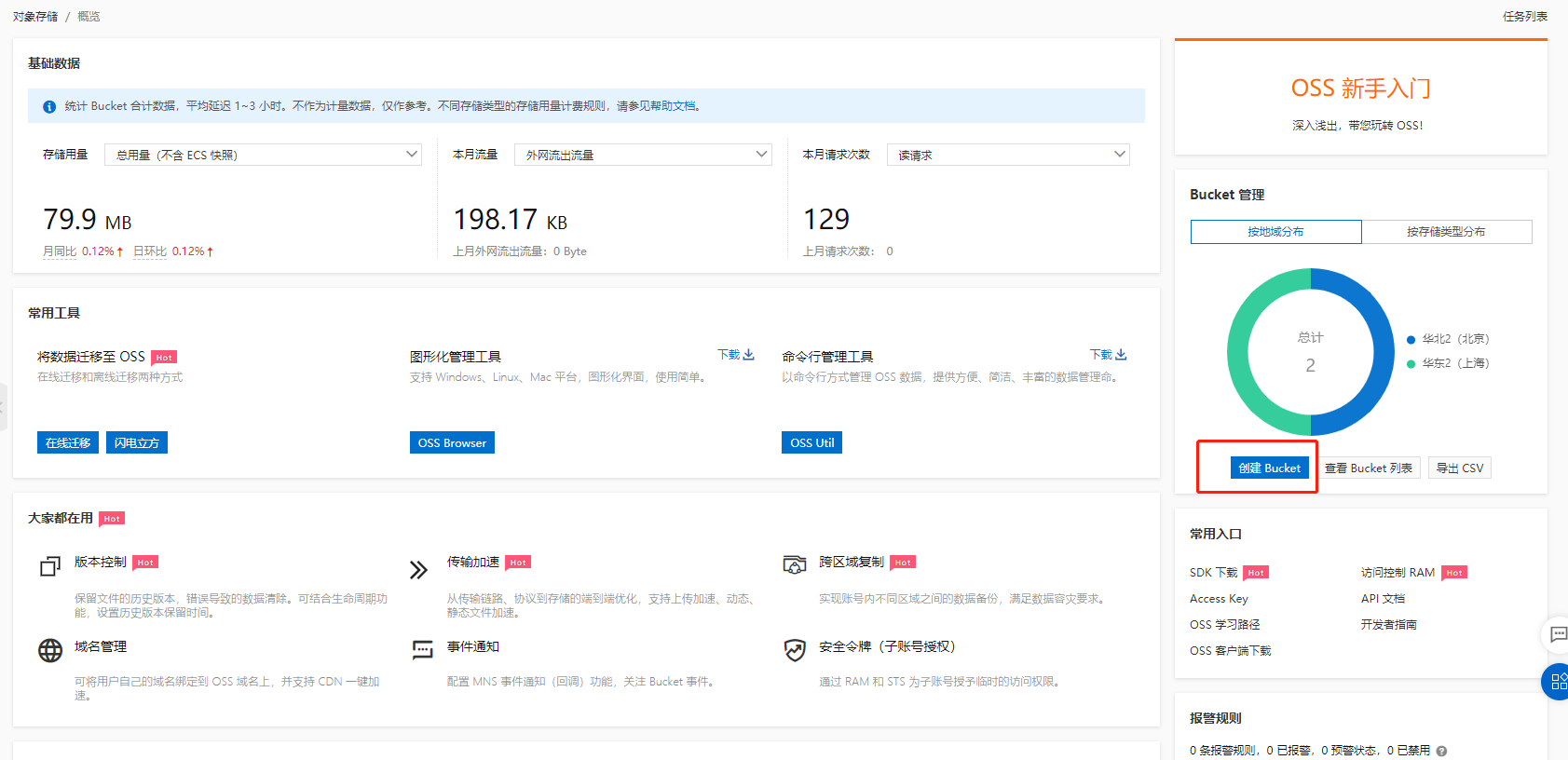
然后开始输入名称以及选择相关配置

进入AccessKey管理
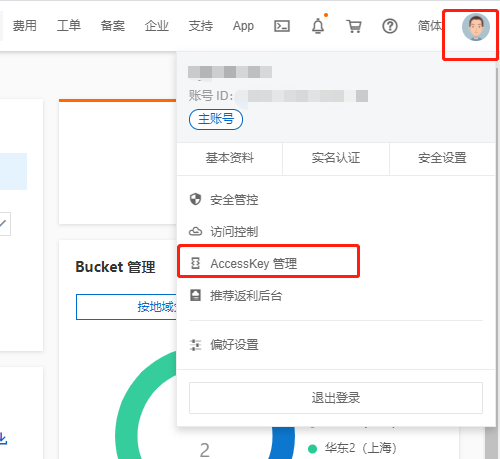
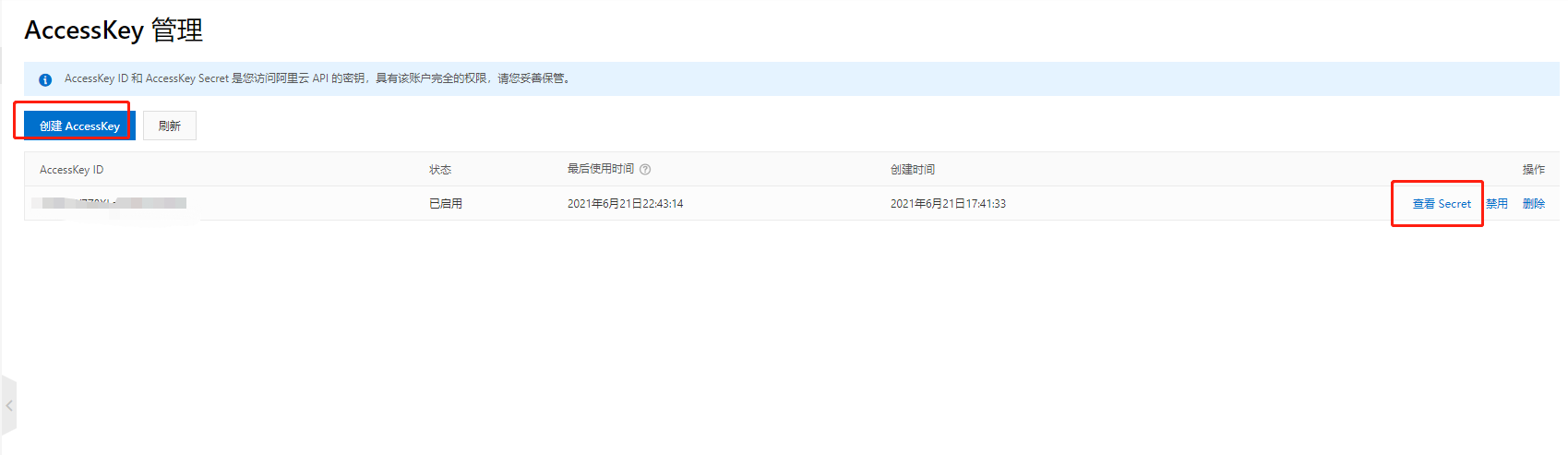
如果没有AccessKey 先创建,有的话就记录好key 跟 secret
下载图床工具
https://github.com/Molunerfinn/PicGo/releases
找好适合自己系统的版本进行下载安装即可
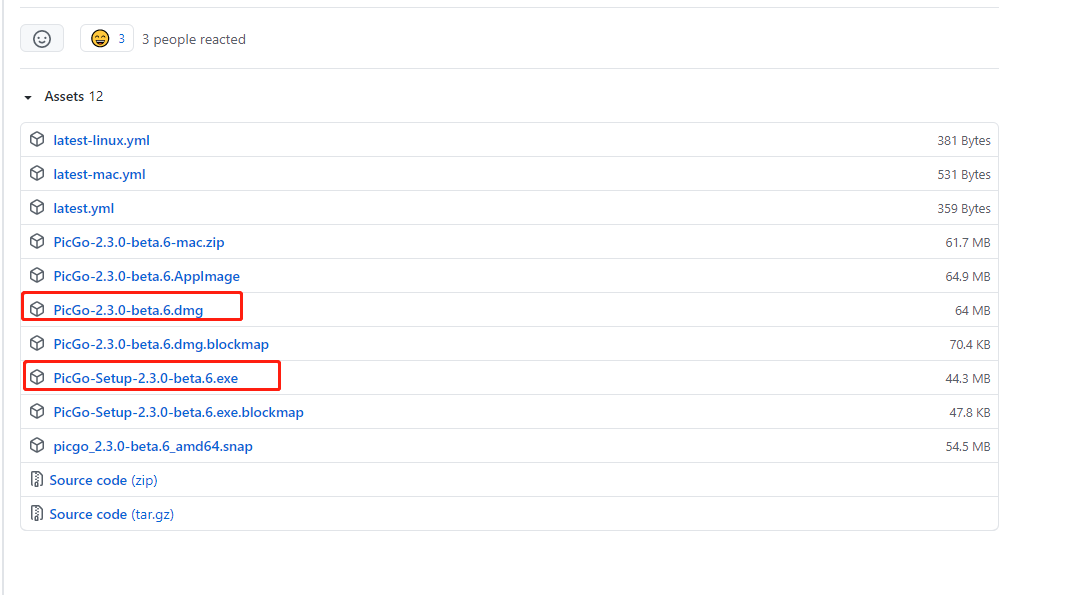
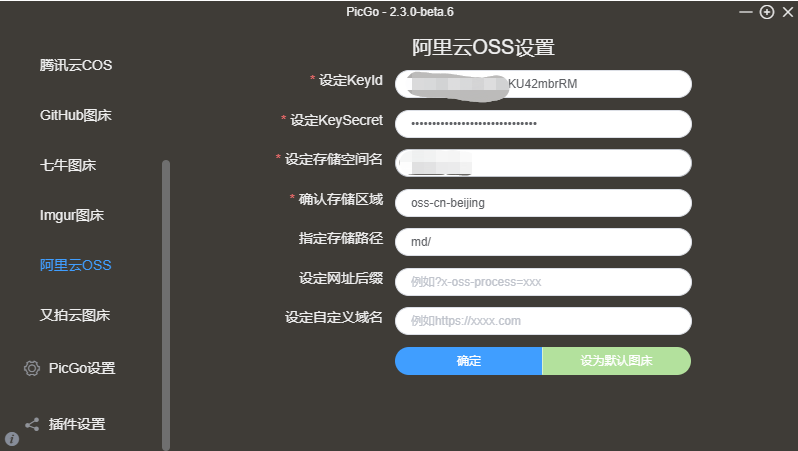
打开图床工具配置阿里云oss
具体配置按照提示来即可,配置完成选择设为默认图床
关于设定自定义域名 建议还是不要设置,设置之后反正没生效~
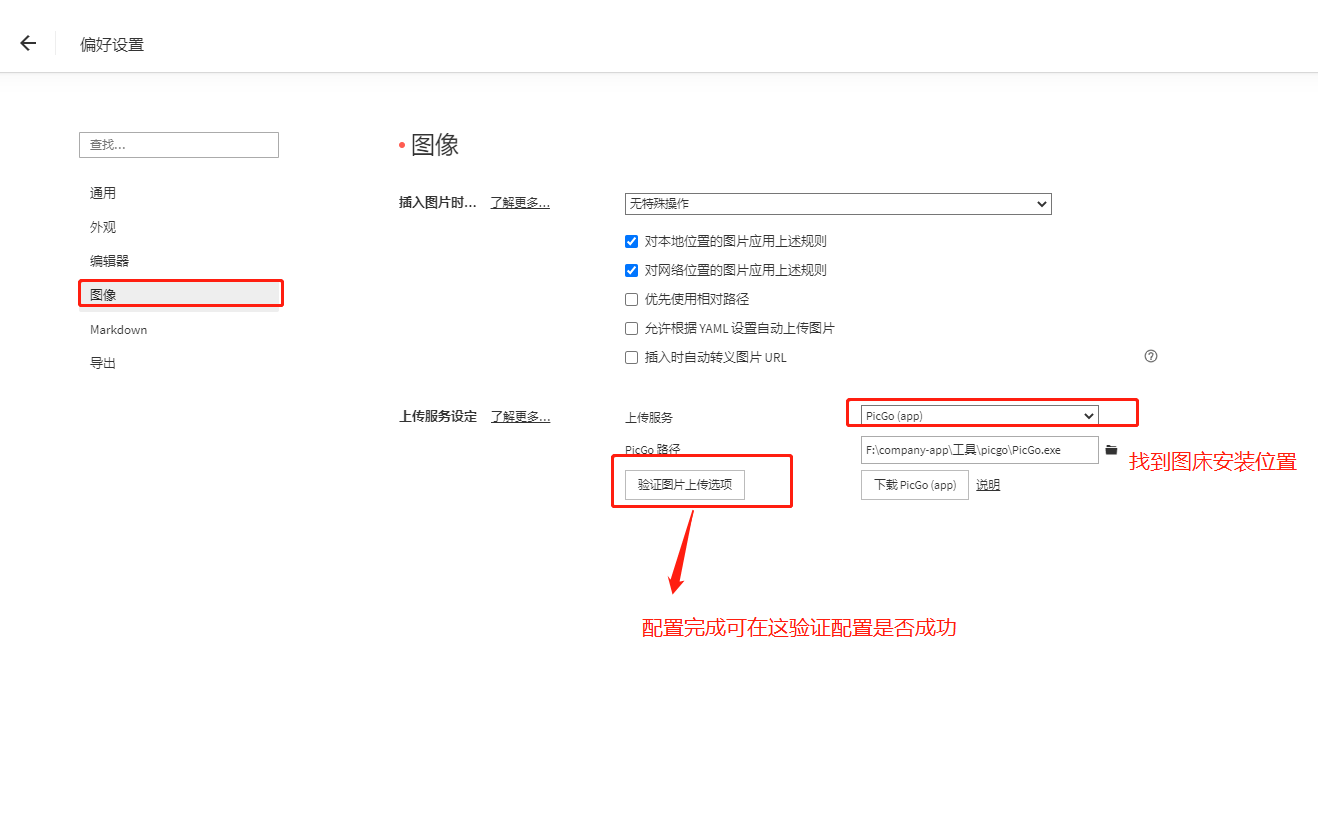
typora选择图床
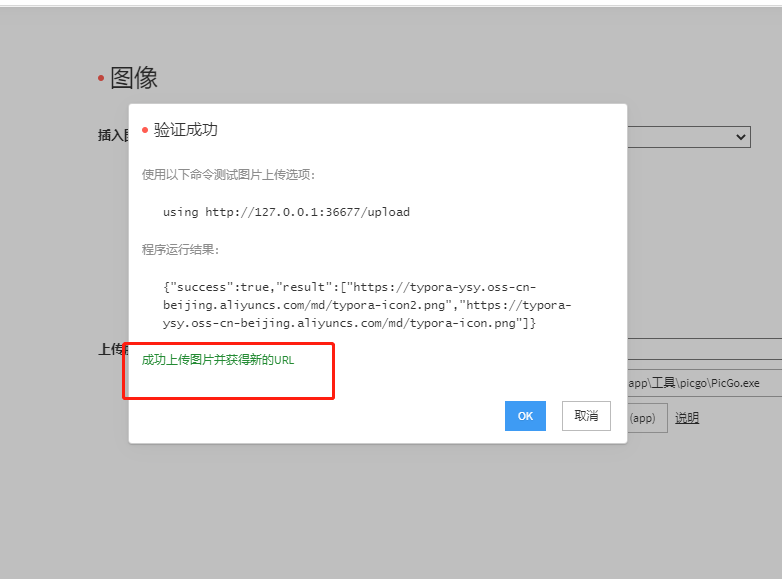
配置成功
这个时候在typora里面粘贴图片时会出现选项是否选择上传,或者图片右键选择上传
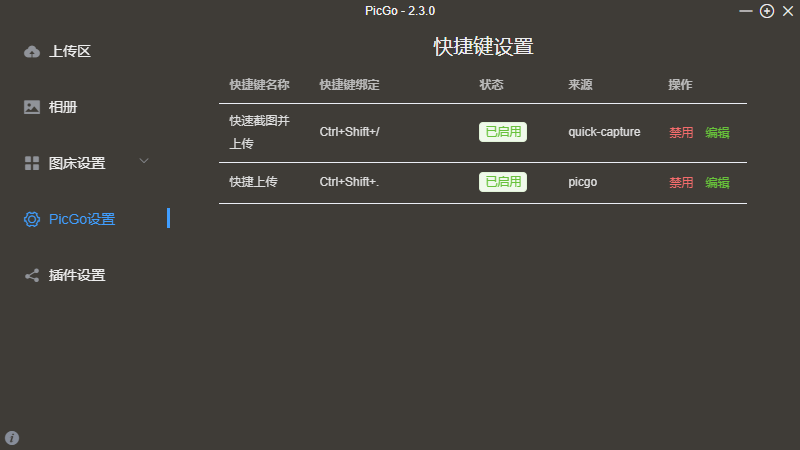
插件拓展⭐
安装三个插件,快速截图、重命名、图片压缩
PicGo/picgo-plugin-quick-capture: A quick capture screenshot plugin for PicGo (github.com)
gclove/picgo-plugin-super-prefix: A PicGo plugin for elegant file name prefix (github.com)
Redns/picgo-plugin-compression: 基于"色彩笔"的picgo图片压缩插件 (github.com)
Picgo 配置 json 地址 C:\Users\你的用户名\AppData\Roaming\picgo\data.json
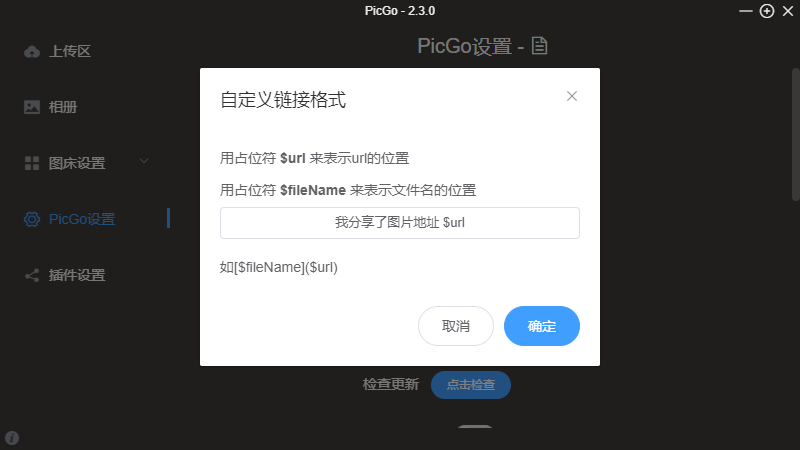
我分享了图片地址 https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/pic/2022/03/20220326150314.jpeg
机器学习导论
导论资料:https://easyai.tech/ai-definition/machine-learning/
机器学习研究和构建的是一种特殊算法(而非某一个特定的算法),能够让计算机自己在数据中学习从而进行预测。
所以,机器学习不是某种具体的算法,而是很多算法的统称。
机器学习包含了很多种不同的算法,深度学习就是其中之一,其他方法包括决策树,聚类,贝叶斯等。
深度学习的灵感来自大脑的结构和功能,即许多神经元的互连。人工神经网络(ANN)是模拟大脑生物结构的算法。
不管是机器学习还是深度学习,都属于人工智能(AI)的范畴。

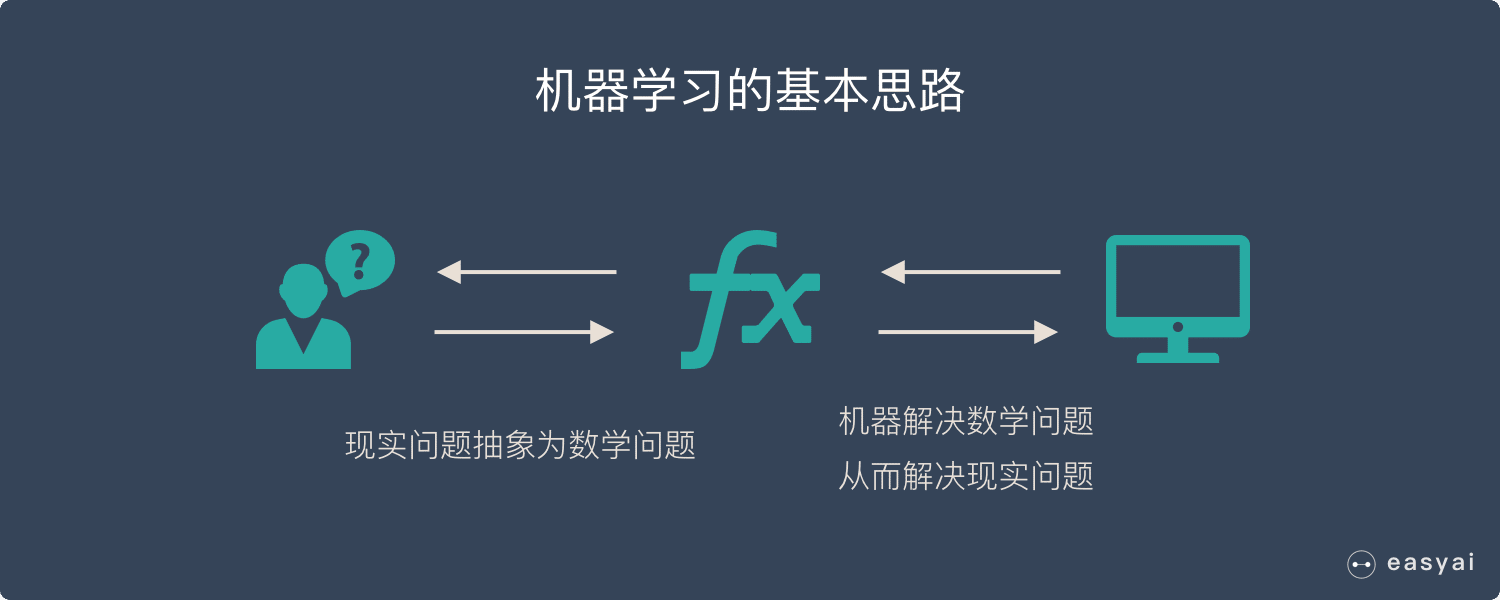
机器学习的基本思路
- 把现实生活中的问题抽象成数学模型,并且很清楚模型中不同参数的作用
- 利用数学方法对这个数学模型进行求解,从而解决现实生活中的问题
- 评估这个数学模型,是否真正的解决了现实生活中的问题,解决的如何?
机器学习实操的7个步骤
假设我们的任务是通过酒精度和颜色来区分红酒和啤酒,下面详细介绍一下机器学习中每一个步骤是如何工作的。
机器学习在实际操作层面一共分为7步:

步骤1:收集数据
我们在超市买来一堆不同种类的啤酒和红酒,然后再买来测量颜色的光谱仪和用于测量酒精度的设备。
这个时候,我们把买来的所有酒都标记出他的颜色和酒精度,会形成下面这张表格。
| 颜色 | 酒精度 | 种类 |
|---|---|---|
| 610 | 5 | 啤酒 |
| 599 | 13 | 红酒 |
| 693 | 14 | 红酒 |
| … | … | … |
这一步非常重要,因为数据的数量和质量直接决定了预测模型的好坏。
步骤2:数据准备
在这个例子中,我们的数据是很工整的,但是在实际情况中,我们收集到的数据会有很多问题,所以会涉及到数据清洗等工作。
当数据本身没有什么问题后,我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。

关于数据准备部分,还有非常多的技巧,感兴趣的可以看看《AI 数据集最常见的6大问题(附解决方案)》
步骤3:选择一个模型
研究人员和数据科学家多年来创造了许多模型。有些非常适合图像数据,有些非常适合于序列(如文本或音乐),有些用于数字数据,有些用于基于文本的数据。
在我们的例子中,由于我们只有2个特征,颜色和酒精度,我们可以使用一个小的线性模型,这是一个相当简单的模型。
步骤4:训练
大部分人都认为这个是最重要的部分,其实并非如此~ 数据数量和质量、还有模型的选择比训练本身重要更多(训练知识台上的3分钟,更重要的是台下的10年功)。
这个过程就不需要人来参与的,机器独立就可以完成,整个过程就好像是在做算术题。因为机器学习的本质就是将问题转化为数学问题,然后解答数学题的过程。
步骤5:评估
一旦训练完成,就可以评估模型是否有用。这是我们之前预留的验证集和测试集发挥作用的地方。评估的指标主要有 准确率、召回率、F值。
这个过程可以让我们看到模型如何对尚未看到的数是如何做预测的。这意味着代表模型在现实世界中的表现。
步骤6:参数调整
完成评估后,您可能希望了解是否可以以任何方式进一步改进训练。我们可以通过调整参数来做到这一点。当我们进行训练时,我们隐含地假设了一些参数,我们可以通过认为的调整这些参数让模型表现的更出色。
步骤7:预测
我们上面的6个步骤都是为了这一步来服务的。这也是机器学习的价值。这个时候,当我们买来一瓶新的酒,只要告诉机器他的颜色和酒精度,他就会告诉你,这时啤酒还是红酒了。
拓展 Gitbook
Gitbook 适合编写文档,可用于后期的知识库整理。(图片来源:小刘)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号