
Jacoco增量代码覆盖率
这篇文章写得太好了,收藏,转至https://blog.csdn.net/rr18758236029/article/details/109318224
文章结构
背景
Jacoco简介
Jacoco 增量代码覆盖率设计方案
Jacoco增量代码覆盖率+持续交付
总结
一、背景
需求测试过程中,测试主要依靠需求及一些测试经验来主观保证质量。为了解决测试度量不清晰的问题,测试用jacoco从代码层面衡量测试覆盖率。分析未覆盖部分代码,从而反推前期测试设计是否重复,没有覆盖到的代码是否是测试设计的盲点。代码覆盖率可以作为测试自我审视的重要工具之一。
jacoco代码覆盖率统计的是全量代码覆盖率,报告冗余,影响我们对报告的分析和查看。为了更精准衡量测试范围和评估影响面,我们做了改造,使jacoco报告计算增量代码覆盖率
功能测试,接口自动化测试,单元测试都能计算到覆盖率里面。支持通过悟空持续集成发布和预发环境手动部署两种场景下的覆盖率收集。
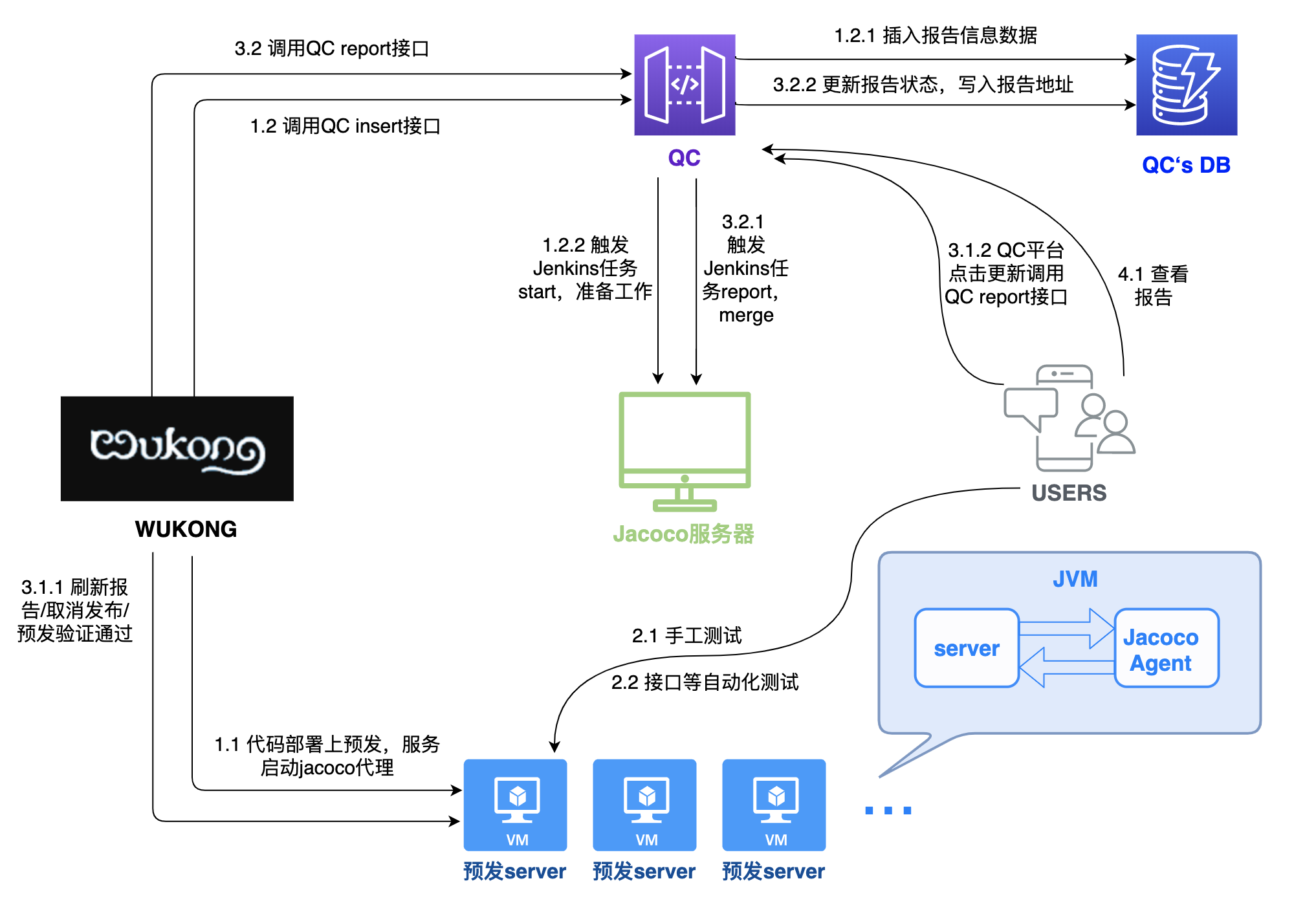
整体交互流程图:
覆盖率结果:

二、JaCoCo简介
JaCoCo是一个开源的覆盖率工具(官网地址:https://www.eclemma.org/jacoco/),针对的语言为java
工作步骤:
对Java字节码进行插桩,有on-the-fly和offline两种方式
执行测试用例,收集程序执行轨迹信息,支持通过dump讲操作记录从服务端传输到本地。
数据处理器结合程序执行轨迹信息和代码结构信息分析生成代码覆盖率报告
结合源码和编译后的文件,可以将代码覆盖率报告图形化展示出来,如html,xml等文件格式
经过比较,我们选择的插桩模式是on-the-fly模式。该模式无需提前进行字节码插桩,只需要JAVA_OPTS中增加-javaagent参数,该参数会被AgentOptions的getVMArgument方法加载。参数重制定jacocoAgent.jar文件,就可以在程序启动时启动Instrumentation的代理程序,代理程序再通过Class Loader装载class前判断是否转换修改class文件将统计代码插入class
三、JaCoCo增量代码覆盖率设计方案
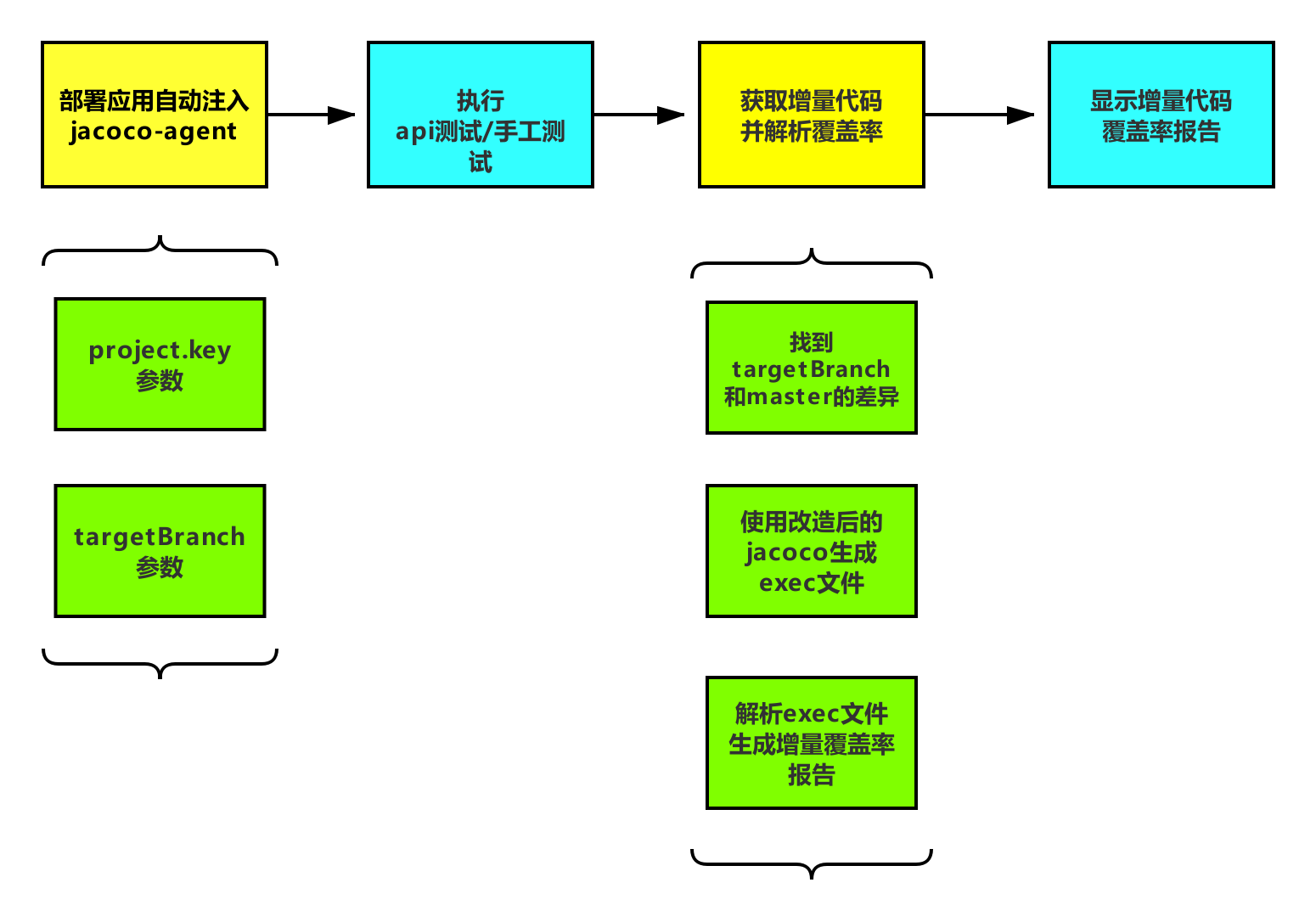
JaCoCo增量代码覆盖率设计方案是基于JaCoCo做相应改造,生成我们所需要的覆盖率数据。这里面主要需要解决的点在于获取增量代码并解析生成覆盖率上。
改造可以拆分成以下几个步骤:
获取测试完成后的exec文件(二进制文件,里面欧探针的覆盖执行信息)
获取基线提交和被测提交之间的差异代码
通过指定代码仓库名(project.key)和开发分支名(branch),解析开发分支和master之间的差异(数据需要精确到方法为度)
改造JaCoCo,是它支持仅对差异代码生成覆盖率报告
具体实现
1. 获取增量数据
这部分涉及到对git的操作和对java文件的语法解析,主要用JGit和JavaPaser实现:JGit是一个用于操作git的Java库,支持使用代码操作git,支持我们获得指定分支和master之间的差异,这里有一篇非常详细的JGit介绍,感兴趣的同学可以自行查阅http://qinghua.github.io/jgit/;JavaPaser是一个开源的Java语法解析库https://github.com/javaparser,可以将java源码解析为一颗语法树,分析语法树可以获得Java代码中的类,方法和方法入参等。
部分代码片段如下:
private static List<DiffResult> getDiffResult (Repository repository, String projectName, String oldCommitSha, String newCommitSha) throws IOException, GitAPIException {
List<DiffResult> results = new ArrayList<>();
List<DiffEntry> list = diff4CommitOfJava(repository.getDirectory().getPath(),
oldCommitSha,
newCommitSha);
list.stream()
//过滤,只取add和modify的内容
.filter(diffEntry -> (DiffEntry.ChangeType.ADD == diffEntry.getChangeType() ||
DiffEntry.ChangeType.MODIFY == diffEntry.getChangeType()))
.forEach(diffEntry -> {
DiffResult diffResult = new DiffResult();
HashMap<String,List<Method>> changedMethods = MethodDiff.methodDiffInClass(BlobUtils.getContent(repository,ObjectId.fromString(oldCommitSha),diffEntry.getOldPath())
, BlobUtils.getContent(repository,ObjectId.fromString(newCommitSha),diffEntry.getNewPath()));
diffResult.setPath(diffEntry.getNewPath());
diffResult.setClassName(diffEntry.getNewPath().substring(diffEntry.getNewPath().lastIndexOf("/")+1,diffEntry.getNewPath().length()));
diffResult.setEntryType(diffEntry.getChangeType().toString());
try {
RevCommit oldCommit = new RevWalk(repository).parseCommit(ObjectId.fromString(oldCommitSha));
RevCommit newCommit = new RevWalk(repository).parseCommit(ObjectId.fromString(newCommitSha));
...
} catch (IOException e) {
LOGGER.error("commitSHA转换为RevCommit失败 {}",e);
}
diffResult.setNewId(diffEntry.getNewId().name());
diffResult.setOldId(diffEntry.getOldId().name());
diffResult.setChangeMethods(changedMethods);
results.add(diffResult);
});
return results;
}
2.改造JaCoCo
获取到增量数据之后,需要对JaCoCo进行改造,主要包括agent,dump和report三个模块
Agent
由于获取增量数据需要额外两个参数,需要扩展AgentOptions里可识别对参数,如下代码块,再VALID-OPTIONS里的参数都会被JaCoCo识别,可以增加自己需要的参数
private static final Collection<String> VALID_OPTIONS = Arrays.asList(
//在这里增加需要扩展的参数
DESTFILE, APPEND, INCLUDES, EXCLUDES, EXCLCLASSLOADER,
INCLBOOTSTRAPCLASSES, INCLNOLOCATIONCLASSES, SESSIONID, DUMPONEXIT,
OUTPUT, ADDRESS, PORT, CLASSDUMPDIR, JMX,PROJECT_KEY,BRANCH);
......
/**
* New instance parsed from the given option string.
*
* @param optionstr
* string to parse or <code>null</code>
*/
public AgentOptions(final String optionstr) {
this();
if (optionstr != null && optionstr.length() > 0) {
for (final String entry : OPTION_SPLIT.split(optionstr)) {
final int pos = entry.indexOf('=');
if (pos == -1) {
throw new IllegalArgumentException(format(
"Invalid agent option syntax \"%s\".", optionstr));
}
final String key = entry.substring(0, pos);
if (!VALID_OPTIONS.contains(key)) {
throw new IllegalArgumentException(format(
"Unknown agent option \"%s\".", key));
}
final String value = entry.substring(pos + 1);
setOption(key, value);
}
validateAll();
}
}
Dump
在Dump数据时需要增加一步,获取增量数据
...
try {
//该处hookfor增量代码覆盖率统计时需要
ExtraData.setAddedData(key, targetBranch);
final ExecFileLoader loader = client.dump(address, port);
if (dump) {
log(format("Dumping execution data to %s",
destfile.getAbsolutePath()));
loader.save(destfile, append);
}
} catch (final IOException e) {
throw new BuildException("Unable to dump coverage data", e,
getLocation());
}
...
/**
* 向diff接口请求增量数据
*/
public class ExtraData {
public static List<JacocoClass> ADD_DATA;
public static void setAddedData(String key,String targetBranch) throws IOException {
String url = String.format("http://qc.beibei.com.cn/api/gitDiff/jacocoClass?appKey=XXX&key=%s&targetBranch=%s",key,targetBranch);
List<JacocoClass> addedData = HttpUtil.get4Jacoco(url);
ADD_DATA = addedData;
}
}
Report
在生成报告时只对增量数据做处理,由此生成增量覆盖率报告。JaCoCo对exec文件的解析主要是在Analyzer类的analyzeClass(final byte[] source)方法,这里面会调用createAnalyzingVisitor方法,生成一个用于解析的ASM类访问器,核心代码为下
/**
* Analyzes the class given as a ASM reader.
*
* @param reader reader with class definitions
*/
public void analyzeClass(final ClassReader reader) {
//仅增量的类才会采集覆盖数据
if (null == ExtraData.ADD_DATA) {
final ClassVisitor visitor = createAnalyzingVisitor(
CRC64.classId(reader.b), reader.getClassName());
reader.accept(visitor, 0);
}else if (HookUtil.isHookedClass(reader.getClassName(), ExtraData.ADD_DATA)) {
final ClassVisitor visitor = createAnalyzingVisitor(
CRC64.classId(reader.b), reader.getClassName());
reader.accept(visitor, 0);
}
}
对方法级别的探针计算逻辑是在ClassProbesAdater类的visitMethod方法里面,我们只需要改造visitMethod方法,使它只对提取出的每个类的新增或变更方法做解析,非指定累和方法不做处理,核心代码如下:
@Override
public final MethodVisitor visitMethod(final int access, final String name,
final String desc, final String signature, final String[] exceptions) {
//无增量数据,不做增量覆盖率统计操作
if (null == ExtraData.ADD_DATA) {
return cv.visitMethod(access, name, desc, signature, exceptions);
}
//当前方法为增量变更方法,需要做覆盖率统计操作
else if (HookUtil.isHookedMethod(this.name,name, MethodUtil.getDesc4Diff(desc), ExtraData.ADD_DATA,"")) {
System.out.println("hookedMethod:"+name);
final MethodProbesVisitor methodProbes;
final MethodProbesVisitor mv = cv.visitMethod(access, name, desc,
signature, exceptions);
if (mv == null) {
// We need to visit the method in any case, otherwise probe ids
// are not reproducible
methodProbes = EMPTY_METHOD_PROBES_VISITOR;
} else {
methodProbes = mv;
}
return new MethodSanitizer(null, access, name, desc, signature,
exceptions) {
@Override
public void visitEnd() {
super.visitEnd();
LabelFlowAnalyzer.markLabels(this);
final MethodProbesAdapter probesAdapter = new MethodProbesAdapter(
methodProbes, ClassProbesAdapter.this);
if (trackFrames) {
final AnalyzerAdapter analyzer = new AnalyzerAdapter(
ClassProbesAdapter.this.name, access, name, desc,
probesAdapter);
probesAdapter.setAnalyzer(analyzer);
methodProbes.accept(this, analyzer);
} else {
methodProbes.accept(this, probesAdapter);
}
}
};
} else {
return cv.visitMethod(access, name, desc, signature, exceptions);
}
}
3.同一个分支多次部署报告合并
在实际使用过程中,开发往往会在同个分支上频繁修改代码并多次部署,会生成多分报告,不幸的是,JaCoCo官方提供的merge功能,针对的是两份源码相同生成的报告,开发代码有变更无法合并,也无法统计处最终的覆盖率数据,可用率大大下降
针对该问题,解决思路是:
V1版本的代码部署测试后生成增量报告R1,更新后的代码版本V2部署测试后生成增量报告R2,使用Diff服务查找V1和V2之间的差异,记为D
我们认为,如果是V1和V2没有改动的部分,如果V1覆盖到了,即使V2中没有覆盖,也认为是被覆盖的,因此,统计R2中覆盖的部分F2,同时去除不在D中的部分,记为F2‘。
将R2和F2’合并,修改R2中美覆盖但是F2‘中覆盖到的数据,生成最终覆盖率报告。
这部分脚本是python实现的,使用爬虫框架Beautiful Soup https://cuiqingcai.com/1319.html,部分核心代码如下:
def filterFc(fcpc, diffResult):
"""
:param fcpc: .java.html中的fc/pc的行
:param diffResult: diff结果
:return: 不在diff结果里的fc/pc
"""
for fpc in fcpc:
for diffRe in diffResult:
if fpc['path'].strip('.html') == diffRe['path'] and diffRe[
'beginLine'] < int(fpc['line'].strip('L')) < diffRe['endLine']:
break
jafc.append(fpc)
break
return jafc
def modifyHtml(jafc, path, path_new):
"""
修改当前报告中特定的行
:param jafc: 不在diff结果里的fc/pc
:param path: 前一次报告路径
:param path_new: 当前报告路径
"""
total = 0
for jaf in jafc:
if os.path.exists(jaf['path'].replace(path, path_new)):
soup_old = BeautifulSoup(open(jaf['path']), features="lxml")
findSpan_old = soup_old.find(attrs={'id': jaf['line']})
soup = BeautifulSoup(open(jaf['path'].replace(path, path_new)), features="lxml")
findSpan = soup.find('span', text=findSpan_old.text)
if findSpan is not None:
if findSpan['class'] == [u'nc']:
findSpan['class'] = [u'fc']
print findSpan
total = total + 1
html = soup.prettify(soup.original_encoding)
with open(jaf['path'].replace(path, path_new), "wb") as file:
file.write(html)
print "total:" + str(total)
return total
有了不同代码版本的合并功能后,我们在每次生成报告后,都拿相同开发分支且更新时间降序排列第二(第一是当前这份报告)的报告进行合并,最终生成合并后的总覆盖率报告。
4.效果
至此,我们就可以获得增量代码覆盖率报告,报告只会对变更的方法进行覆盖率统计,效果如图,包括从包、类、方法、代码各个级别的报告:


5.报告解读
首先我们需要知道报告中各种标记的含义,代码的背景颜色代表这一行的行覆盖情况:
红色背景:这一行没有任何指令被执行;
黄色背景:这一行有部分指令被执行;
绿色背景:这一行的所有指令都被执行了;
代码前方的菱形则代表这一行的分支覆盖情况,在if-else或者switch等逻辑分支语句前会出现:
红色菱形:这一行没有分支被执行;
黄色菱形:这一行有部分分支被执行;
绿色菱形:这一行的所有分支都被执行了;
(1)精确定位代码逻辑错误
如何根据JaCoCo报告快速并且准确的定位问题?举个栗子:
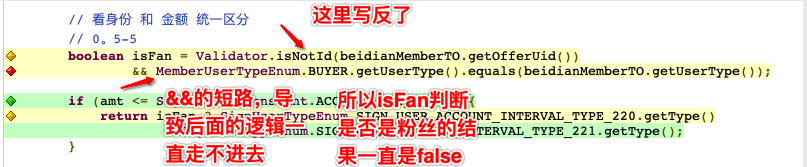
这是一个判断是否是粉丝的代码片段,在两个判断语句都为真的情况下为真。在功能测试时,测试了粉丝和非粉丝的场景,生成的报告结果如上图。显然,这个分支语句始终没有完全覆盖,并且,&&后半段的分支是完全没有跑到的。为什么呢?简单的推理一下,一定是&&前半部分的代码逻辑错误(第一行),导致这部分判断结果一直为false,结合&&的短路原理,&&后半部分的逻辑才会一直走不进去。由此,我们可以快速定位到是第一行代码有bug。
(2)快速发现测试遗漏or冗余代码
在测试过程中,出现大量代码未覆盖的情况怎么办?很简单,去找开发了解这部分的代码逻辑:如果是测试遗漏的,反向补充用例,有目标的查漏补缺;如果是废弃代码,则提醒开发删除,有效去除项目中的冗余代码。
四、JaCoCo增量代码覆盖率+持续交付
目前我们的增量代码覆盖率工具已经集成到持续交付平台 Wukong 和测试平台 qc。
具体运作方式:

接入Wukong的应用,在部署时就会初始化一条数据记入db,这条记录包含了部署的必要信息,初始状态为“等待测试”;同时,在JaCoCo专属的服务器上也会开始执行拉代码、编译等操作,为后续生成报告做准备。
部署之后,在测试过程中,点击刷新报告,在JaCoCo专属的服务器上开始运行生成增量覆盖率报告任务;在任务结束后会将报告地址写入db,同时钉钉通知报告生成状态和报告地址,此时报告状态被更新为“测试中”。
在Wukong上取消发布/验证通过后,自动再次运行生成增量覆盖率报告任务,更新报告状态为“测试完成”,防止在部署过程中未点击过刷新报告的数据被遗漏。
qc平台覆盖率结果一览:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k1kxKEln-1603796132232)(/Users/chenxiwen/Library/Application Support/typora-user-images/image-20201027185501049.png)]
五、总结
至此,我们的JaCoCo+持续交付流程已经非常完善了:
接入过程开发无感知,不需要修改代码,降低推广难度;
测试过程中如果需要,也支持多次更新报告;
多次部署,合并为一份报告,方便后续进行测试分析;
整个流程全自动收集,即使是没有测试参与的项目,覆盖率数据也尽在掌握。
参考资料:jacoco官网
————————————————
版权声明:本文为CSDN博主「咕咕荣」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/rr18758236029/article/details/109318224

 浙公网安备 33010602011771号
浙公网安备 33010602011771号