python——函数
函数
1、先定义后调用;定义阶段,只检测语法不执行代码。 2、可以返回任意类型的数据(元组,字典,函数)。 3、如果没有return默认返回None。 4、返回多个值,要用括号括起来,以逗号隔开。
函数的三种形式:
1、 无参函数 2、 有参函数(依赖于调用者传入参数) 3、 空函数 (函数体为pass)
执行函数的两种形式:
1、语句形式:直接调用函数,输出语句的执行结果 2、表达式形式:得到的是return的结果
执行函数得到的结果都是函数的返回值
实例:
def func(): print('from func') func() #语句形式 res=func() #表达式形式 print(res)
参数:
分类:
形参:位置参数、默认参数、*args、命名关键字参数、**kwargs(定义在*后面的位置参数和默认参数叫作命名关键字参数;用来限制实参必须以关键字的形式传值。;默认参数通常要定义成不可变类型)
实参:位置参数、关键字参数
命名关键字参数:
例子:按说默认参数要在*args前面,但是下面这个是命名关键字参数。
def register(*args, name='egon', age): print(args) print(name) print(age) register(name='egon',age=18)
可变长参数
按位置定义的可变长度的实参: 由*接收,保存成元组类型。 按关键字定义的可变长度的实参:由**接收,保存成字典的形式。
(英文单词:Positional argument 位置参数)
可变长实质:
def index(name, group): print('welcome %s to index page, group is: %s' %(name, group)) def wrapper(*args, **kwargs): index(*args, **kwargs) # *,**分别把接收到的位置参数和关键字参数拆开, # 结果:index(1,2,3,z=3,y=2,x=1) wrapper(1,2,3,x=1,y=2,z=3)
结果:
TypeError: index() got an unexpected keyword argument 'x' #因为传给index函数的参数不止两个
名称空间
三者的加载顺序: 内置名称空间==》全局名称空间==》局部名称空间
取值的顺序: 局部名称空间==》全局名称空间==》内置名称空间
名称空间介绍:
内置名称空间:解释器启动就会生成
全局名称空间:文件级别定义的名字属于全局名称空间
局部名称空间:定义在函数内部的名字; 调用函数时生效,调用结束失效。
作用域
全局作用域:内置名称空间与全局名称空间的名字属于全局范围(在整个文件的任意一个位置都能被引用)
局部作用域:局部名称空间的名字属于局部范围(只在函数内部可以被引用,局部有效)
易误导:
dic={'x':1}
l=[1,2,3]
salary=1000
def foo():
dic['x']=2 #修改了在全局名称空间中定义的dic字典
dic['y']=3
l.append(4)
global salary
salary=0
foo()
print(dic)
print(l)
print(salary)
函数是第一对象
1、 函数是第一类对象:指的是函数可以被当做数据传递(因此可以得出下面几条结论)
2、 可以当做函数的参数或返回值
3、 可以被引用(f=func)
4、 函数可以当做容器数据类型的元素:(字典的value) **
def select(): print('select function') func_dic={ 'select':select, #函数作为字典的值 } func_dic['select']() #用键取到值(值是函数)后,加上括号就可以执行。
总结、感想:
函数是一个个的功能模块,字典相当于Django的路由, while循环是逻辑。这段代码中while循环是图纸,函数和字典是工具
闭包函数
内部函数:函数内部定义的函数。
闭包函数:1 内部函数 2 包含对外部作用域而非全局作用域的引用
闭包函数的特点:
1、自带作用域
2、延迟计算
闭包函数的实例:
def func(): name='egon' x=1 def bar(): print(name) print(x) return bar f=func() print(f.__closure__) #查看闭包函数引用的名字;验证闭包函数 print(f.__closure__[0].cell_contents) #查看闭包函数引用的第一个名字的值。 f()
装饰器
一:开放封闭原则,对扩展是开放的,对修改是封闭的
二:装饰器可以是任意可调用对象,被装饰的对象也可以是任意可调用对象,
三:装饰器的功能是:
在不修改被装饰对象源代码以及调用方式的前提下添加新功能
装饰器实例:
计算打开网页的时间:
import time import random #装饰器 def timmer(func): def wrapper(*args,**kwargs): #*,** 接收被装饰函数的参数。 start_time = time.time() res=func(*args,**kwargs) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) return res #被装饰的函数return的内容。 return wrapper #被装饰函数 def home(name): time.sleep(random.randrange(1,3)) print('welecome to %s HOME page' %name) return 123123123123123123123123123123123123123123 home() #home=timmer(home)
1、迭代器:
1、Zip,min ,max 都是迭代器。
2、数字不可迭代。
什么是可迭代对象:
含有__iter__方法就是可迭代对象。
什么是迭代器:
执行__iter__()方法得到的结果就是迭代器(可以用next取值)
d={'a':1,'b':2,'c':3}
i=d.__iter__() #i叫迭代器,d叫做可迭代对象。
print(i)
print(i.__next__())
print(i.__next__())
next 触发迭代器的执行。
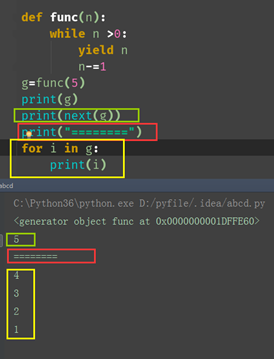
def func(n): while True: yield n n-=1 g=func(5) print(next(g))
查看是否可迭代:
# print(hasattr(d,'__iter__')) #适合python3
For取值
for i in d: print(i)
while取值
obj=d.__iter__() while True: try: print(obj.__next__()) except StopIteration: break
2、生成器
- 生成器:包含yield关键字的函数执行得到的结果。
- 生成器本质就是迭代器。
- 生成器的用途:模拟管道,惰性计算。
Yield的作用:把__iter__和__next__方法封到函数里。
Yield的表达式形式
send
Send基于暂停的yield,给yield传一个值,再继续往下走。
表达式形式的yield,第一件事应该是初始化,让生成器走到一个暂停的位置。
写个装饰器:初始化生成器。给多个生成器使用。
def init(func): def wrapper(*args,**kwargs): x=func(*args,**kwargs) next(x) return x return wrapper @init def eater(name): print('%s please ready' % name) food_list=[] while True: food = yield food_list food_list.append(food) print('please %s eat %s' %(name,food)) def make_food(people,n): for i in range(n): people.send('food%s' %i) eater('alex').send('tudou') make_food(eater('alex'),5)
应用:grep –rl ‘root’ /etc
Day22 ==》3面向过程编程




#!/usr/bin/env python # coding:utf-8 import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper #阶段一:递归地找文件的绝对路径,把路径发给阶段二。 def search(target,start_path): 'search file obspath' g = os.walk(start_path) for par_dir,_,files in g: #print(par_dir,files) for file in files: file_path = r'%s\%s' % (par_dir,file) target.send(file_path) #阶段二:收到文件路径,打开文件获取对象,把文件对象发给阶段三。 @init def opener(target): 'get file obj: f=open(filepath' while True: file_path=yield with open(file_path) as f: target.send((file_path,f)) #需要以元组的形式 #阶段三:收到文件对象,for循环读取文件的每一行内容,把每一行内容发给阶段四. @init def cat(target): 'read file' while True: filepath,f=yield for line in f: target.send((filepath,line)) #阶段四:收到一行内容,判断root是否在这一行中,如果在,则把文件名发给阶段五。 @init def grep(target,pattern): 'grep function' while True: filepath,line=yield if pattern in line: target.send(filepath) #阶段五: @init def printer(): 'print function' while True: filename=yield print(filename) start_path=r'd:\dddd' search(opener(cat(grep(printer(),'root'))),start_path)
厨师做包子给吃货(yield,面向过程,)
#!/usr/bin/env python #coding:GBK #厨师 , count:造多少个包子 import time import random def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper def producer(target,count): for i in range(count): time.sleep(random.randrange(1,3)) print('\033[35m厨师造好的包子%s\033[0m'%i) target.send('baozi%s' %i) #吃货 @init def consummer(name): while True: food=yield time.sleep(random.randrange(1,3)) print('\033[36m%s start to eat %s\033[0m' %(name,food)) producer(consummer('alex'),4) #************************* def producer(count): res=[] for i in range(count): res.append('baozi%s' %i) return res # print(producer(4)) def consumer(name,res): for i in res: print('%s吃%s'%(name,i)) consumer('alex',producer(4))
3、列表解析
print([i for i in range(10) if i>5])
s='hello' res=[i.upper() for i in s] print(res) l=[1,31,73,84,57,22] l_new=[] for i in l: if i > 50: l_new.append(i) print(l_new) print([i for i in l if i > 50]) #列表解析
l1=['x','y','z'] l2=[1,2,3] l3=[(a,b) for a in l1 for b in l2] print(l3) print('\n'.join([''.join(['%s*%s=%-2s '%(y,x,x*y)for y in range(1,x+1)])for x in range(1,10)]))
4、生成器表达式(元组)
a=(i for i in range(10) if i > 5) print(next(a))
g=(i for i in range(10000000000) ) #生成器表达式,语法和列表解析一样#得到的结果是生成器#生成器就是迭代器 print(g) print(next(g)) print(next(g)) print(next(g)) print(g.__next__())
5、三元表达式:
格式:
Res = True if 1>2 else False
def f(x,y): return x - y if x>y else abs(x-y) #如果x大于y就返回x-y的值 ,否则就返回x-y的绝对值 print(f(3,4))
6、拉链函数
salaries={'egon':3000,
'alex':90000000,
'wupeiqi':10000,
'yuanhao':2000}
print(max(salaries)) #默认按key,z最大。
print(max(salaries.values())) #找出最大的values
res=zip(salaries.values(),salaries.keys()) #拉链函数。
print(max(res)[-1])
7、列表推倒式:
#列表推导式是利用其他列表创建新列表的一种方法。
1、求总价格
1、文件a.txt内容:每一行内容分别为商品名字,价钱,个数;
要求一:使用列表解析,从文件a.txt中取出每一行,做成下述格式:[{‘name’:'apple','price':10,'count':3},{...},{...},...]
要求二:求出总共消费了多少钱(5分)
apple 10.3 3 tesla 100000 1 mac 3000 2 lenovo 30000 3 chicken 10 3
答案
with open(r'inspectionProfiles\0621a.txt','r') as f: l=[float(line.split()[1])*int(line.split()[2]) for line in f] ==》由[换成(,就变成了生成器,然后由next取值,sum是自带next功能的函数。 print(sum(l)) =>with代码段执行完,文件就关闭。所以这个print必须在with代码段下面。
第二种方式:将数据做成字典类型,进行处理
goods_info=[] with open(r'inspectionProfiles\0621a.txt','r') as f: for line in f: l = line.split() goods_info.append({'name':l[0],'price':l[1],'count':l[2]}) print(goods_info)
2、求1到10每个数的平方
# a=[x*x for x in range(10)] # print(a)
3、求出1到10的2次方幂中能被3整除幂。
在推导式中添加一个if就可以完成:
# b=[x*x for x in range(10) if x % 3 ==0] #for循环取值后放到左边,再if判断。 # print(b)
4、两个for循环的列表推导式
# c=[(x,y) for x in range(3) for y in range(3)] # print(c) # d=[[x,y] for x in range(2) for y in range(2)] print(d) #结果:[[0, 0], [0, 1], [1, 0], [1, 1]] e=[x*y for x in range(2) for y in range(2)] print(e) #结果:[0, 0, 0, 1] #—————————————————————————————————————— # a=(x*x for x in range(10)) #小括号中有for循环就是生成器 # print(a.__next__()) # print(a.__next__())
9、匿名函数:
#有名函数如果只需要调用一次,要关闭,避免占用内存。
func=lambda x:x**2 print(func(2))
f1=lambda x,y:x+y print(f1(2,5))
ff=lambda x:x>1 print(ff(3))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号