GlusterFS学习之路(一)GlusterFS初识
-
一、GlusterFS简介
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
-
二、GlusterFS架构特性
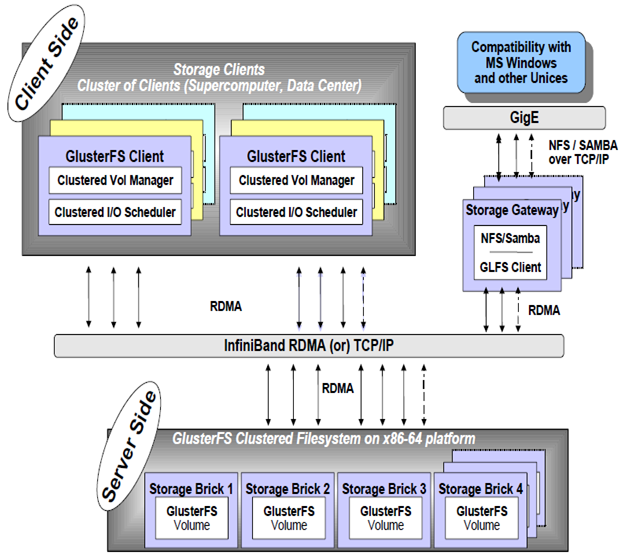
从这个图中, 我们可以得到如下的信息:
1、无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是某个文件或某个区块存储的位置。传统分布式文件系统大都会设置元数据服务器或者功能相近的管理服务器,主要作用就是用来管理文件与数据区块之间的存储位置关系。相较其他分布式文件系统而言,GlusterFS并没有集中或者分布式的元数据的概念,取而代之的是弹性哈希算法。集群中的任何服务器和客户端都可以利用哈希算法、路径及文件名进行计算,就可以对数据进行定位,并执行读写访问操作。
这种设计带来的好处是极大的提高了扩展性,同时也提高了系统的性能和可靠性;另一显著的特点是如果给定确定的文件名,查找文件位置会非常快。但是如果要列出文件或者目录,性能会大幅下降,因为列出文件或者目录时,需要查询所在节点并对各节点中的信息进行聚合。此时有元数据服务的分布式文件系统的查询效率反而会提高许多。
2、client 和 服务器之间可以通过 RDMA 来进行数据通讯。
3、InfiniBand 将是需要重点考虑和采用的方案, 他可以有效提高数据的传输效率
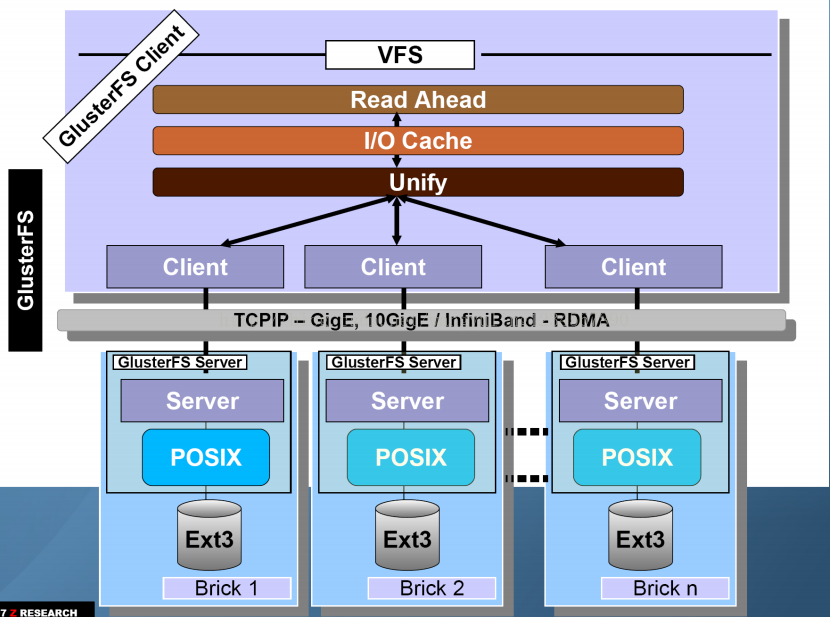
从中我们可以知道:
(1) client and server 的设计是高度模块化的
(2)client 的复杂度比 server 要大, 客户端需要考虑的问题很多, 比如 Read Ahead, I/O Cache, Stripe, Unify, Replicate(AFR) 等。
3、服务器间的部署
在之前的版本中服务器间的关系是对等的,也就是说每个节点服务器都掌握了集群的配置信息,这样做的好处是每个节点度拥有节点的配置信息,高度自治,所有信息都可以在本地查询。每个节点的信息更新都会向其他节点通告,保证节点间信息的一致性。但如果集群规模较大,节点众多时,信息同步的效率就会下降,节点信息的非一致性概率就会大大提高。因此GlusterFS未来的版本有向集中式管理变化的趋势。
-
三、客户端访问流程
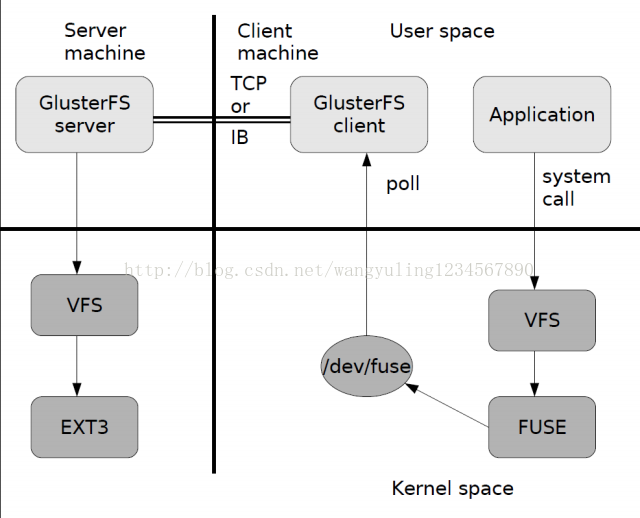
1. 首先是在客户端, 用户通过glusterfs的mount point 来读写数据, 对于用户来说, 集群系统的存在对用户是完全透明的, 用户感觉不到是操作本地系统还是远端的集群系统。
2. 用户的这个操作被递交给 本地linux系统的VFS来处理。
3. VFS 将数据递交给FUSE 内核文件系统:在启动 glusterfs 客户端以前, 需要想系统注册一个实际的文件系统FUSE,如上图所示,该文件系统与ext3在同一个层次上面, ext3 是对实际的磁盘进行处理, 而 fuse 文件系统则是将数据通过 /dev/fuse 这个设备文件递交给了glusterfs client端。所以, 我们可以将 fuse 文件系统理解为一个代理。
4. 数据被 fuse 递交给 Glusterfs client 后, client 对数据进行一些指定的处理(所谓的指定,是按照client 配置文件据来进行的一系列处理, 我们在启动glusterfs client 时 需 要 指 定 这 个 文 件 , 其 默 认 位 置 :/etc/glusterfs/client.vol)。
5. 在glusterfs client的处理末端, 通过网络将数据递交给 Glusterfs Server, 并且将数据写入到服务器所控制的存储设备上。
这样, 整个数据流的处理就完成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号