【第十三课】监控Linux系统状态
1、查看系统负载命令:w、uptime
[root@localhost ~]# w
23:38:24 up 33 days, 1:03, 1 user, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.56.1 Fri16 0.00s 0.95s 0.00s w
[root@localhost ~]# uptime
23:38:38 up 33 days, 1:03, 1 user, load average: 0.00, 0.01, 0.05
**load average****:1分钟内系统的平均负载值,5分钟内系统的平均负载值,15分钟内系统的平均负载值
这个值的意义是,单位时间段内CPU活动进程数。这个值越大就说明服务器压力越大。一般情况下这个值不超过服务器cpu数量就没有关系。假设服务器的cpu数量为8,那么这个值若小于8,就说明当前服务器没有压力,否则就要关注一下了。那么如何查看服务器有几个cpu呢?
[root@localhost ~]# cat /proc/cpuinfo |grep processor #查看cpu核数
processor : 0
[root@localhost ~]# cat /proc/cpuinfo |grep processor |wc -l
1
[www@wef66fxcdgkbsdsd790fd9z ~]$ cat /proc/cpuinfo |grep processor|wc -l #线上环境使用了4核
4
2、vmstat详解
[root@localhost ~]# vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 1540 126124 0 600364 0 0 0 1 4 12 0 1 99 0 0
0 0 1540 126124 0 600364 0 0 0 0 165 286 0 0 100 0 0
2 0 1540 126124 0 600364 0 0 0 0 152 280 0 0 100 0 0
1 0 1540 126124 0 600364 0 0 0 0 157 276 0 1 99 0 0
1 0 1540 126124 0 600364 0 0 0 0 166 281 1 0 99 0 0
①procs 显示进程相关信息
r:表示运行和等待cpu时间片的进程数。如果长时间大于服务器cpu的个数,则说明cpu不够用了
b:表示等待资源的进程数。比如,等待I/O、内存等,这列的值如果长时间大于1,则需要关注一下了
②memory 内存相关信息
swpd:表示切换到交换分区中的内存数量
free:当前空闲的内存数量
buff:缓冲大小,(即将写入磁盘的)
cache:缓存大小,(从磁盘中读取的)
③swap 内存交换情况
si:由交换区写入到内存的数据量
so:由内存写入到交换区的数据量
④io 磁盘使用情况
bi:从块设备读取数据的量(读磁盘)
bo:从块设备写入数据的量(写磁盘)
⑤system 显示采集间隔内发生的中断次数
in:表示在某一时间间隔中观测到的每秒设备中断数
cs:表示每秒产生的上下文切换次数
⑥CPU 显示cpu的使用状态
us:显示用户下所花费cpu时间的百分比
sy:显示系统花费cpu时间百分比
id:表示cpu处于空闲状态的时间百分比
wa:表示I/O等待所占用cpu时间百分比
st:表示被偷走的cpu所占百分比(一般都为0,不用关注)
以上介绍的各个参数中,比较关注r列、b列、wa列。IO部分的bi以及bo也是经常参考的对象。如果磁盘io压力很大时,这两列的数值会比较高。另外当si、so两列的数值比较高,并且在不断变化时,说明内存不够用了,内存中的数据会频繁交换到swap分区中,这样往往对系统的性能产生影响。
3、top动态查看负载
这个命令用于动态监控进程所占系统资源,每隔3s变一次。它的特点是把占用系统资源(CPU,内存,磁盘IO等)最高的进程放到最前面。top命令打印出了很多信息,包括系统负载(loadaverage)、进程数(Tasks)、cpu使用情况、内存使用情况及交换分区使用情况。需要关注的有几项:%CPU、%MEM、COMMAND。RES为进程所占内存大小,而%MEM为使用内存百分比。在top状态下,按“shift+m”,可以按照内存使用大小排序。按数字1可以列出各颗cpu的使用状态。
top - 15:06:39 up 38 days, 15:09, 1 user, load average: 0.45, 0.49, 0.52
Tasks: 328 total, 2 running, 326 sleeping, 0 stopped, 0 zombie
%Cpu0 : 12.0 us, 6.7 sy, 0.0 ni, 80.7 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu1 : 4.3 us, 3.3 sy, 0.0 ni, 91.7 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu2 : 13.0 us, 5.7 sy, 0.0 ni, 81.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu3 : 10.0 us, 4.0 sy, 0.0 ni, 84.6 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
KiB Mem : 8010096 total, 195140 free, 1800572 used, 6014384 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 5398572 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24423 www 20 0 586460 38764 24164 S 5.0 0.5 55:44.43 php-fpm
24333 www 20 0 586392 39308 24748 S 4.7 0.5 55:58.71 php-fpm
24328 www 20 0 586336 41876 27360 S 4.3 0.5 55:35.53 php-fpm
24483 www 20 0 586480 37964 23388 S 2.0 0.5 55:41.00 php-fpm
24310 www 20 0 586356 38540 24008 S 1.0 0.5 55:38.32 php-fpm
24311 www 20 0 588468 41120 26536 S 1.0 0.5 56:00.00 php-fpm
24324 www 20 0 586448 39064 24348 S 1.0 0.5 56:09.32 php-fpm
24332 www 20 0 587924 40548 26608 S 1.0 0.5 55:37.79 php-fpm
24341 www 20 0 586456 38224 23572 S 1.0 0.5 56:06.65 php-fpm
24361 www 20 0 586324 38576 24020 S 1.0 0.5 56:12.87 php-fpm
24366 www 20 0 586388 37864 23468 S 1.0 0.5 55:34.51 php-fpm
PID:进程ID号
USER:用户名
PR:priority其取值范围是0~39,进程优先级,PR值越小,优先级越高
NI:nice,表示进程优先级状态的值,其取值范围是-20~19,一共40个级别。这个值越小,表示进程优先级越高,而值越大,表示优先级越低。
PR+NI=20
VIRT:虚拟内存多大
RES:实际内存使用
SHR:共享内存
S:进程状态
TIME+:cpu占用时长
top -bn1表示非动态打印系统资源使用情况,可以用在shell脚本中。和tip命令的区别就是,它一次性全部把所有信息输出出来而非动态显示。
iostat -x 1 10 查看io,看%until 表示有多少没有写入磁盘,等待需要写入磁盘的,如果过高,就要查看进程了。
没有iostat命令可以安装:sysstat-9.0.4-31.el6.i686
4、sar命令(监控网卡流量)
[root@localhost ~]# yum install -y sysstat #如果没有sar命令,需要安装sysstat
[www@localhost ~]$ sar -n DEV #查看网卡流量
Linux 3.10.0-693.21.1.el7.x86_64 (localhost) 07/07/2018 _x86_64_ (4 CPU)
12:00:01 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
12:10:01 AM eth0 782.73 391.12 642.35 80.69 0.00 0.00 0.00
12:10:01 AM lo 182.90 182.90 55.27 55.27 0.00 0.00 0.00
12:20:01 AM eth0 762.37 384.97 619.17 78.28 0.00 0.00 0.00
12:20:01 AM lo 182.80 182.80 55.26 55.26 0.00 0.00 0.00
12:30:01 AM eth0 815.71 414.54 662.49 84.65 0.00 0.00 0.00
12:30:01 AM lo 184.49 184.49 60.96 60.96 0.00 0.00 0.00
12:40:01 AM eth0 731.05 354.88 609.65 71.97 0.00 0.00 0.00
12:40:01 AM lo 179.47 179.47 51.47 51.47 0.00 0.00 0.00
12:50:01 AM eth0 699.75 345.80 575.08 72.07 0.00 0.00 0.00
12:50:01 AM lo 177.91 177.91 51.58 51.58 0.00 0.00 0.00
01:00:02 AM eth0 672.47 319.08 553.33 76.75 0.00 0.00 0.00
01:00:02 AM lo 178.08 178.08 58.16 58.16 0.00 0.00 0.00
01:10:01 AM eth0 537.61 287.04 409.51 53.91 0.00 0.00 0.00
01:10:01 AM lo 174.22 174.22 39.61 39.61 0.00 0.00 0.00
01:20:01 AM eth0 450.01 250.07 325.20 49.19 0.00 0.00 0.00
01:20:01 AM lo 171.17 171.17 37.62 37.62 0.00 0.00 0.00
01:30:01 AM eth0 506.51 257.61 394.53 48.44 0.00 0.00 0.00
01:30:01 AM lo 170.50 170.50 37.90 37.90 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: eth0 108.23 87.20 27.30 25.59 0.00 0.00 0.00
Average: lo 11.34 11.34 61.10 61.10 0.00 0.00 0.00
- IFACE:表示设备名称
- rxpck/s:表示每秒进入收取的包的数量,单位为"个"
- txpck/s:表示每秒发送出去的包的数量,单位为"个"
- rxkb/s:表示每秒收取的数据量,单位为kb
- txkb/s:表示每秒发送的数据量,单位为kb
如果有一天服务器的丢包很严重,此时应观察这个网卡流量是否异常,如果rxpck/s那一列的数值大于4000,或者rxkb/s那列大于5000,则很有可能是被攻击了,正常的服务器网卡流量不会高于这么多,除非是自己在拷贝数据。
实时查看网卡流量每秒打印,打印5次:sar -n DEV 1 5
[www@localhost ~]$ sar -n DEV 1 2
Linux 3.10.0-862.3.2.el7.x86_64 (localhost) 07/07/2018 _x86_64_ (2 CPU)
03:21:47 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:21:48 PM eth0 126.00 101.00 54.70 54.87 0.00 0.00 0.00
03:21:48 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:21:48 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:21:49 PM eth0 66.00 59.00 5.15 5.41 0.00 0.00 0.00
03:21:49 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: eth0 100.60 85.80 28.03 18.35 0.00 0.00 0.00
Average: lo 8.00 8.00 3.49 3.49 0.00 0.00 0.00
另外也可以查看某一天的网卡流量历史,使用-f选项,后面跟文件名。sar的库文件在/var/log/sa/目录下:默认该目录下文件保留时长为30天
[www@localhost ~]$ sar -n DEV -f /var/log/sa/sa01
Linux 3.10.0-693.5.2.el7.x86_64 (localhost) 07/01/2018 _x86_64_ (2 CPU)
12:00:01 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
12:10:01 AM eth0 49.80 24.46 41.21 15.63 0.00 0.00 0.00
12:10:01 AM lo 8.97 8.97 0.88 0.88 0.00 0.00 0.00
12:20:01 AM eth0 50.09 24.56 41.44 15.94 0.00 0.00 0.00
12:20:01 AM lo 8.93 8.93 0.87 0.87 0.00 0.00 0.00
12:30:01 AM eth0 50.02 24.68 41.45 15.93 0.00 0.00 0.00
......
ls /var/log/sa/会看到有两种不同的文件,一个是以sa开头加日期,一个是sar开头加日期,其中sa加日期的文件为二进制文件,是不能直接cat查看,只能用sar -f查看,另外一种sar加日期的文件是可以直接cat的。他们都是记录的系统状态历史信息。
也可以使用sar查看历史负载:sar -q,每隔1s打印,打印10次:sar -q 1 10
[www@localhost ~]$ sar -q
Linux 3.10.0-862.3.2.el7.x86_64 (localhost) 07/06/2018 _x86_64_ (2 CPU)
12:00:01 AM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
12:10:01 AM 3 356 0.12 0.07 0.05 0
12:20:01 AM 16 354 0.01 0.05 0.05 1
12:30:01 AM 15 354 0.00 0.02 0.05 0
12:40:01 AM 3 362 0.00 0.01 0.05 0
12:50:01 AM 6 353 0.00 0.02 0.05 0
ldavg-1 :1分钟负载
ldavg-5 :5分钟负载
ldavg-15:15分钟负载
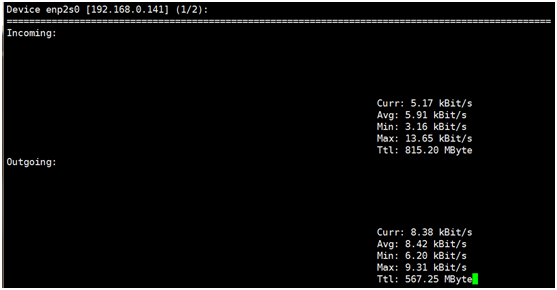
5.nload命令(监控网卡流量)
[root@localhost ~]# yum install -y epel-release nload
[root@localhost ~]# nload
(1/2):表示有2个网卡,可以用箭头进行来回切换
- Curr:当前流量
- Avg:平均流量
- Min:最小流量
- Max:最大流量
- Ttl:总共流量
6、iostat iotop(监控IO性能)
[www@localhost ~]$ iostat -x
Linux 3.10.0-693.5.2.el7.x86_64 (loccalhost) 07/07/2018 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.89 0.00 0.66 0.18 0.00 98.27
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 3.24 0.02 9.94 0.46 64.19 12.99 0.42 42.13 17.21 42.17 0.55 0.55
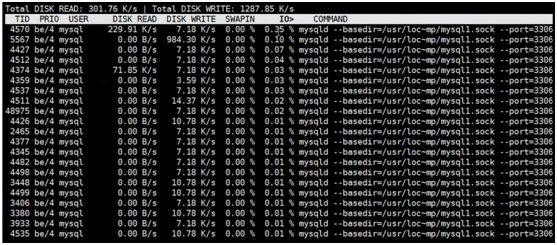
**%util****:表示磁盘IO等待比例。这个数值过大,说明磁盘IO拥堵。说明rkB/s和wkB/s也会增大,如果只是单纯%util较大,说明可能磁盘存在问题。
当发现磁盘IO很忙,需要查看某个进程在读写,就可以使用iotop**
[root@localhost ~]# yum install -y iotop
[root@localhost ~]# iotop #可以看到是mysql进程在进行读写
7、free(查看内存使用,默认单位是kb)
[www@localhost ~]$ free -m
total used free shared buff/cache available
Mem: 3790 308 153 128 3328 3050
Swap: 0 0 0
total:内存总大小
used:已经使用的内存
free:空闲内存
available:可用内存,包含free和buffer/cache剩余部分
total=used+free+buff/cache
系统启动完毕后,会先拿出一部分内存分给buffer、cache,缓存用来随时提供给程序使用。如果程序不用时,那这部分内存就空闲。写入磁盘数据时,会把数据写入buffer,缓冲。cache是从磁盘读取数据,先放到缓存中。
磁盘-->内存(cache)-->cpu
cpu-->内存(buffer)-->磁盘
8、ps(查看系统进程)
常用:ps -elf ps -axu
选项:
-a:显示所有终端机下执行的程序,除了阶段作业领导者之外。
a:显示现行终端机下的所有程序,包括其他用户的程序。
-A:显示所有程序。
-c:显示CLS和PRI栏位。
c:列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示。
-C<指令名称>:指定执行指令的名称,并列出该指令的程序的状况。
-d:显示所有程序,但不包括阶段作业领导者的程序。
-e:此选项的效果和指定"A"选项相同。
e:列出程序时,显示每个程序所使用的环境变量。
-f:显示UID,PPIP,C与STIME栏位。
f:用ASCII字符显示树状结构,表达程序间的相互关系。
-g<群组名称>:此选项的效果和指定"-G"选项相同,当亦能使用阶段作业领导者的名称来指定。
g:显示现行终端机下的所有程序,包括群组领导者的程序。
-G<群组识别码>:列出属于该群组的程序的状况,也可使用群组名称来指定。
h:不显示标题列。
-H:显示树状结构,表示程序间的相互关系。
-j或j:采用工作控制的格式显示程序状况。
-l或l:采用详细的格式来显示程序状况。
L:列出栏位的相关信息。
-m或m:显示所有的执行绪。
n:以数字来表示USER和WCHAN栏位。
-N:显示所有的程序,除了执行ps指令终端机下的程序之外。
-p<程序识别码>:指定程序识别码,并列出该程序的状况。
p<程序识别码>:此选项的效果和指定"-p"选项相同,只在列表格式方面稍有差异。
r:只列出现行终端机正在执行中的程序。
-s<阶段作业>:指定阶段作业的程序识别码,并列出隶属该阶段作业的程序的状况。
s:采用程序信号的格式显示程序状况。
S:列出程序时,包括已中断的子程序资料。
-t<终端机编号>:指定终端机编号,并列出属于该终端机的程序的状况。
t<终端机编号>:此选项的效果和指定"-t"选项相同,只在列表格式方面稍有差异。
-T:显示现行终端机下的所有程序。
-u<用户识别码>:此选项的效果和指定"-U"选项相同。
u:以用户为主的格式来显示程序状况。
-U<用户识别码>:列出属于该用户的程序的状况,也可使用用户名称来指定。
U<用户名称>:列出属于该用户的程序的状况。
v:采用虚拟内存的格式显示程序状况。
-V或V:显示版本信息。
-w或w:采用宽阔的格式来显示程序状况。
x:显示所有程序,不以终端机来区分。
X:采用旧式的Linux i386登陆格式显示程序状况。
-y:配合选项"-l"使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位 。
-<程序识别码>:此选项的效果和指定"p"选项相同。
--cols<每列字符数>:设置每列的最大字符数。
--columns<每列字符数>:此选项的效果和指定"--cols"选项相同。
--cumulative:此选项的效果和指定"S"选项相同。
--deselect:此选项的效果和指定"-N"选项相同。
--forest:此选项的效果和指定"f"选项相同。
--headers:重复显示标题列。
--help:在线帮助。
--info:显示排错信息。
--lines<显示列数>:设置显示画面的列数。
--no-headers:此选项的效果和指定"h"选项相同,只在列表格式方面稍有差异。
--group<群组名称>:此选项的效果和指定"-G"选项相同。
--Group<群组识别码>:此选项的效果和指定"-G"选项相同。
--pid<程序识别码>:此选项的效果和指定"-p"选项相同。
--rows<显示列数>:此选项的效果和指定"--lines"选项相同。
--sid<阶段作业>:此选项的效果和指定"-s"选项相同。
--tty<终端机编号>:此选项的效果和指定"-t"选项相同。
--user<用户名称>:此选项的效果和指定"-U"选项相同。
--User<用户识别码>:此选项的效果和指定"-U"选项相同。
--version:此选项的效果和指定"-V"选项相同。
--widty<每列字符数>:此选项的效果和指定"-cols"选项相同。
[root@localhost ~]# ps -elf |head -n 5
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 31307 ep_pol May31 ? 00:01:56 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
1 S root 2 0 0 80 0 - 0 kthrea May31 ? 00:00:00 [kthreadd]
1 S root 3 2 0 80 0 - 0 smpboo May31 ? 00:12:12 [ksoftirqd/0]
1 S root 5 2 0 60 -20 - 0 worker May31 ? 00:00:00 [kworker/0:0H]
[root@localhost ~]# ps axu |head -n 5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 125228 3408 ? Ss May31 1:56 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
root 2 0.0 0.0 0 0 ? S May31 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S May31 12:12 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< May31 0:00 [kworker/0:0H]
PID****:进程的id
STAT****:表示进程的状态,进程状态分为以下几种(不要求记住,但要了解)
D:不能中断的进程(通常为IO),当CPU****负载高,而使用率不高,可以查看是否进程状态为D的数量是否较多,该数量较多会影响系统负载值。
R****:run状态的进程,正在运行中的进程
S****:sleep状态的进程,通常情况下,系统中大部分进程都是这个状态
T****:已经停止或者暂停的进程
W****:表示没有足够的内存页分配
X****:已经死掉的进程
Z****:僵尸进程,杀不掉,打不死的垃圾进程,占用系统一小点资源,不过没有关系,如果太多的话就存在问题。
<****:高优先级进程
N****:低优先级进程
L****:在内存中被锁了内存分页
s****:主进程
l****:多线程进程
+****:代表在前台运行的进程
9、netstat(查看网络状态)
netstat命令用来打印网络连接状况、系统所开放的端口、路由表等信息。
netstat -lnp:打印当前系统启动哪些端口
[root@localhost ~]# netstat -lntp #打印当前系统启动哪些端口,-t表示只查看tcp的端口,不加-t表示查看所有的端口
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 5106/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 5106/nginx: master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 734/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 818/master
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 25837/php-fpm: mast
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 43059/mysqld
tcp6 0 0 :::22 :::* LISTEN 734/sshd
tcp6 0 0 ::1:25 :::* LISTEN 818/master
tcp6 0 0 :::2377 :::* LISTEN 977/dockerd
tcp6 0 0 :::7946 :::* LISTEN 977/dockerd
udp 0 0 0.0.0.0:4789 0.0.0.0:* -
udp 0 0 127.0.0.1:323 0.0.0.0:* 513/chronyd
udp6 0 0 :::7946 :::* 977/dockerd
udp6 0 0 ::1:323 :::* 513/chronyd
Active UNIX domain sockets (only servers)
Proto RefCnt Flags Type State I-Node PID/Program name Path
unix 2 [ ACC ] STREAM LISTENING 22022 981/docker-containe /var/run/docker/containerd/docker-containerd-debug.sock
还可以使用组合命令来查看TCP的状态统计。关注ESTABLISHED这个数值如果较大,说明网站较忙,1000以内可以接受。并发较高
[www@localhost ~]$ netstat -an | awk '/^tcp/{++sta[$NF]} END {for(key in sta) print key , sta[key]}'
LISTEN 8
ESTABLISHED 5
TIME_WAIT 173
10、lsof :列出当前系统打开文件的工具(list open files)*
(1)获取网络信息
使用-i显示所有连接
[root@localhost ~]# lsof -i
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
chronyd 513 chrony 1u IPv4 14838 0t0 UDP localhost:323
chronyd 513 chrony 2u IPv6 14839 0t0 UDP localhost:323
sshd 734 root 3u IPv4 16833 0t0 TCP *:ssh (LISTEN)
sshd 734 root 4u IPv6 16835 0t0 TCP *:ssh (LISTEN)
master 818 root 13u IPv4 17273 0t0 TCP localhost:smtp (LISTEN)
master 818 root 14u IPv6 17274 0t0 TCP localhost:smtp (LISTEN)
dockerd 977 root 21u IPv6 22761 0t0 TCP *:2377 (LISTEN)
dockerd 977 root 26u IPv6 22776 0t0 TCP *:7946 (LISTEN)
dockerd 977 root 28u IPv6 22777 0t0 UDP *:7946
nginx 5106 root 6u IPv4 1433341 0t0 TCP *:http (LISTEN)
nginx 5106 root 7u IPv4 1433342 0t0 TCP *:webcache (LISTEN)
php-fpm 25837 root 6u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25838 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25839 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25840 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25841 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25842 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25843 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
nginx 25857 nginx 6u IPv4 1433341 0t0 TCP *:http (LISTEN)
nginx 25857 nginx 7u IPv4 1433342 0t0 TCP *:webcache (LISTEN)
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
mysqld 43059 mysql 14u IPv4 916196 0t0 TCP *:mysql (LISTEN)
使用-i 4仅获取IPv4流量
[root@localhost ~]# lsof -i 4
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
chronyd 513 chrony 1u IPv4 14838 0t0 UDP localhost:323
sshd 734 root 3u IPv4 16833 0t0 TCP *:ssh (LISTEN)
master 818 root 13u IPv4 17273 0t0 TCP localhost:smtp (LISTEN)
nginx 5106 root 6u IPv4 1433341 0t0 TCP *:http (LISTEN)
nginx 5106 root 7u IPv4 1433342 0t0 TCP *:webcache (LISTEN)
php-fpm 25837 root 6u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25838 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25839 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25840 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25841 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25842 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
php-fpm 25843 apache 0u IPv4 1491295 0t0 TCP localhost:cslistener (LISTEN)
nginx 25857 nginx 6u IPv4 1433341 0t0 TCP *:http (LISTEN)
nginx 25857 nginx 7u IPv4 1433342 0t0 TCP *:webcache (LISTEN)
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
mysqld 43059 mysql 14u IPv4 916196 0t0 TCP *:mysql (LISTEN)
仅显示TCP连接(同理可获得UDP连接)
也可以通过在-i后提供对应的协议来仅仅显示TCP或者UDP连接信息。
[root@localhost ~]# lsof -iUDP
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
chronyd 513 chrony 1u IPv4 14838 0t0 UDP localhost:323
chronyd 513 chrony 2u IPv6 14839 0t0 UDP localhost:323
dockerd 977 root 28u IPv6 22777 0t0 UDP *:7946
使用-i:port来显示与指定端口相关的网络信息
也可以通过端口搜索,这对于要找出什么阻止了另外一个应用绑定到指定端口实在是太棒了。
[root@localhost ~]# lsof -i:22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 734 root 3u IPv4 16833 0t0 TCP *:ssh (LISTEN)
sshd 734 root 4u IPv6 16835 0t0 TCP *:ssh (LISTEN)
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
使用@host来显示指定到指定主机的连接
在检查是否开放连接到网络中或互联网上某个指定主机的连接时十分有用。
[root@localhost ~]# lsof -i@192.168.56.11
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
使用@host:port显示基于主机与端口的连接
也可以组合主机与端口的显示信息。
[root@localhost ~]# lsof -i@192.168.56.11:22
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
(2)找出监听端口
找出正等候连接的端口。
[root@localhost ~]# lsof -i -sTCP:LISTEN
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 734 root 3u IPv4 16833 0t0 TCP *:ssh (LISTEN)
sshd 734 root 4u IPv6 16835 0t0 TCP *:ssh (LISTEN)
master 818 root 13u IPv4 17273 0t0 TCP localhost:smtp (LISTEN)
master 818 root 14u IPv6 17274 0t0 TCP localhost:smtp (LISTEN)
dockerd 977 root 21u IPv6 22761 0t0 TCP *:2377 (LISTEN)
dockerd 977 root 26u IPv6 22776 0t0 TCP *:7946 (LISTEN)
找出已建立的连接
[root@localhost ~]# lsof -i -sTCP:ESTABLISHED
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
sshd 34937 root 3u IPv4 1958031 0t0 TCP swarm-manager:ssh->192.168.56.1:61856 (ESTABLISHED)
(3)用户信息
使用-u显示指定用户打开了什么
[root@localhost ~]# lsof -u nginx
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 25857 nginx cwd DIR 8,3 265 64 /
nginx 25857 nginx rtd DIR 8,3 265 64 /
nginx 25857 nginx txt REG 8,3 1132976 738655 /usr/sbin/nginx
杀死指定用户所做的一切事情
[root@localhost ~]# kill -9 `lsof -t -u mysql`
(4)命令和进程
可以查看指定程序或进程由什么启动,这通常会很有用,而你可以使用lsof通过名称或进程ID过滤来完成这个任务。下面列出了一些选项:
使用-c查看指定的命令正在使用的文件和网络连接
[root@localhost ~]# lsof -c php-fpm
使用-p查看指定进程ID已打开的内容
[root@localhost ~]# lsof -p 25843
-t选项只返回PID
[root@localhost ~]# lsof -t -c nginx
5106
25857
(5)文件和目录
通过查看指定文件或目录,你可以看到系统上所有正与其交互的资源——包括用户、进程等。
显示与指定目录交互的所有一切
[root@localhost ~]# lsof /var/log/messages/
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsyslogd 492 root 6w REG 8,3 863866 17552622 /var/log/messages
显示与指定文件交互的所有一切
[root@localhost ~]# lsof /var/log/cron
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsyslogd 492 root 4w REG 8,3 42911 17552620 /var/log/cron
(6)高级用法
与tcpdump类似,当你开始组合查询时,它就显示了它强大的功能。
显示nginx连接到192.168.56.11所做的一切
[root@localhost ~]# lsof -u nginx -i @192.168.56.11
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 25857 nginx cwd DIR 8,3 265 64 /
nginx 25857 nginx rtd DIR 8,3 265 64 /
nginx 25857 nginx txt REG 8,3 1132976 738655 /usr/sbin/nginx
nginx 25857 nginx mem REG 8,3 27616 17547606 /usr/lib64/perl5/vendor_perl/auto/nginx/nginx.so
同时使用-t和-c选项以给进程发送 HUP 信号
# kill -HUP `lsof -t -c sshd`
lsof +L1显示所有打开的链接数小于1的文件
这通常(但不总是)表示某个攻击者正尝试通过删除文件入口来隐藏文件内容。
[root@localhost ~]# lsof +L1
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NLINK NODE NAME
mysqld 43059 mysql 4u REG 8,3 0 0 16939513 /var/tmp/ibiJ3IU3 (deleted)
mysqld 43059 mysql 5u REG 8,3 0 0 17225230 /var/tmp/ibAhlMEQ (deleted)
mysqld 43059 mysql 6u REG 8,3 0 0 16952289 /var/tmp/ibODsPoD (deleted)
mysqld 43059 mysql 7u REG 8,3 0 0 17616006 /var/tmp/ibqYeF3c (deleted)
mysqld 43059 mysql 11u REG 8,3 0 0 17635488 /var/tmp/ibGYCrRc (deleted)
11.抓包工具tchdump
有时候我们需要查看某个网卡都有哪些数据包,尤其是当你初步判定服务器上有流量攻击时,此时使用抓包工具来抓一下数据包,就可以知道有哪些ip在攻击了。
[root@localhost ~]# yum install -y tcpdump
[root@localhost ~]# tcpdump -nn -i eth0
00:42:51.396212 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 141808:142084, ack 1, win 473, length 276
00:42:51.396380 IP 192.168.56.1.53338 > 192.168.56.11.22: Flags [.], ack 142084, win 16110, length 0
00:42:51.396396 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 142084:142264, ack 1, win 473, length 180
00:42:51.396579 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 142264:142540, ack 1, win 473, length 276
00:42:51.396703 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 142540:142720, ack 1, win 473, length 180
00:42:51.396977 IP 192.168.56.1.53338 > 192.168.56.11.22: Flags [.], ack 142720, win 16383, length 0
00:42:51.396989 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 142720:142900, ack 1, win 473, length 180
00:42:51.397119 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 142900:143176, ack 1, win 473, length 276
00:42:51.397206 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 143176:143356, ack 1, win 473, length 180
00:42:51.397370 IP 192.168.56.1.53338 > 192.168.56.11.22: Flags [.], ack 143356, win 16224, length 0
00:42:51.397386 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 143356:143536, ack 1, win 473, length 180
00:42:51.397539 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 143536:143812, ack 1, win 473, length 276
00:42:51.397714 IP 192.168.56.11.22 > 192.168.56.1.53338: Flags [P.], seq 143812:143992, ack 1, win 473, length 180
00:42:51.397875 IP 192.168.56.1.53338 > 192.168.56.11.22: Flags [.], ack 143812, win 16110, length 0
参数解析:
-i****:后面跟设备名称,如果像抓eht0网卡的包,后面则要跟eth0
-nn****:是让第3列和第4列显示成ip+port端口号形式,如果不加-nn则显示的是主机名+服务名称
host****:指定ip
prot****:指定端口
-c****:指定包数量
-w****:写入指定文件里
如果没有tcpdump这个命令,我们需要用“yum install -y tcpdump”命令去安装一下。上图中第3列和第4列显示的信息为哪一个ip+port在连接哪一个ip+port,后面的信息为该数据包的相关信息。
直接使用tcpdump -nn -i 网卡名称展示得太快,无法全面分析查看,所以将抓包结果输出到文件
tcpdump -nn -i eth0 -c 100 -w /tmp/1.cap
tcpdump -r /tmp/1.cap
- 案例使用:
(1)用tcpdump嗅探80端口的访问哪个ip最高
[root@localhost ~]# tcpdump -i eth0 -tnn dst port 80 -c 100 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr |head -20
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
100 packets captured
102 packets received by filter
0 packets dropped by kernel
41 IP 192.168.100.171
29 IP 120.27.173.9
15 IP 120.27.173.8
9 IP 120.27.173.41
6 IP 120.27.173.35
(2)蜘蛛分析,查看是哪些蜘蛛在抓取内容
[root@localhost ~]# tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C57 packets captured
57 packets received by filter
0 packets dropped by kernel
(3)查看数据库执行的sql
[root@localhost ~]# tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号