
[数据结构 - 第6章] 树之概念
一、树的定义
1.1 定义
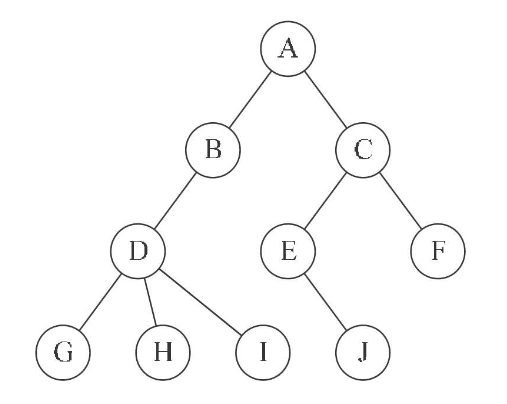
树(Tree)是 n(n>=0) 个结点的有限集。 n=0 时称为空树。在任意一棵非空树中,有且仅有一个特定的称为根的结点。当 n>1 时,其余结点可分为 m (m>0) 个互不相交的有限集 T1、T2、……、Tm。其中每一个集合本身又是一棵树,并且称为根的子树(SubTree),如下图所示:
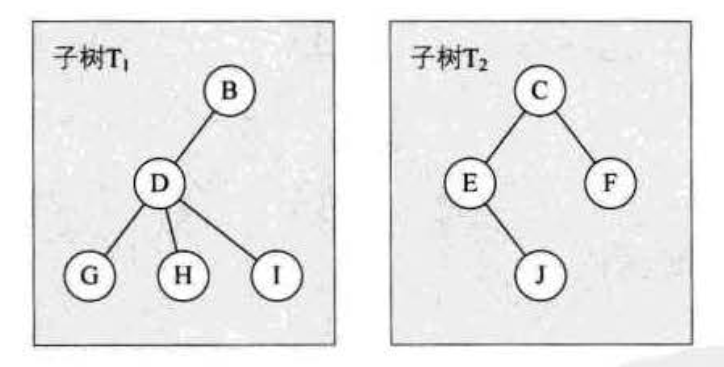
其中根结点 A 有两个子树:
1.2 节点分类
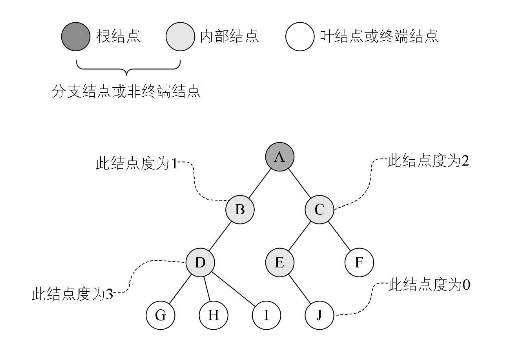
树的结点包含一个数据元素及若干指向其子树的分支。结点拥有的的子树数称为结点的度。度为 0 的称为叶结点或者终端结点;度不为 0 的结点称为非终端结点或者分支结点。除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。如下图所示,因为这棵树结点的度的最大值是结点 D 的度,为 3,所以树的度也为 3 。
1.3 结点间关系
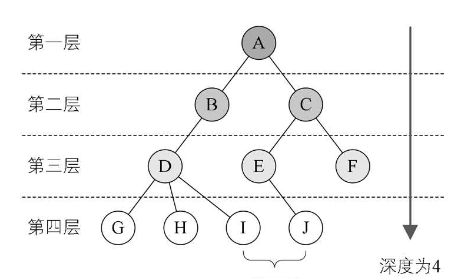
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent) 。同一个双亲的孩子之间互称兄弟。结点的祖先是从根到该结点所经分支上的所有结点。所以对于 H 来说,D、B、A 都是它的祖先 。反之,以某结点为根的子树中的任一结点都称为该结点的子孙。B的子孙有 D、G、H、I,如下图所示:
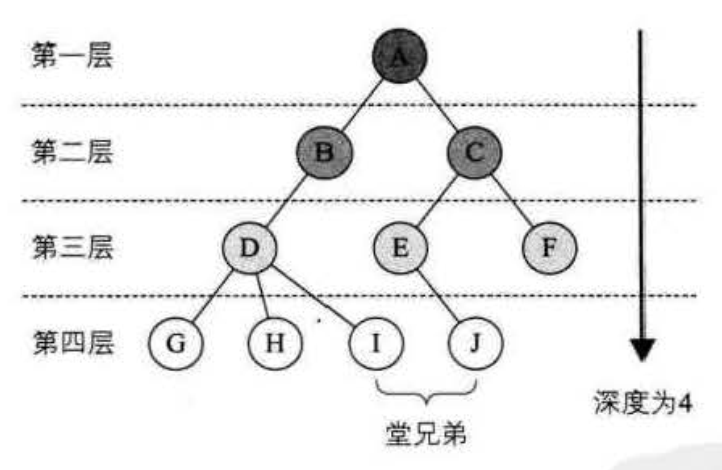
1.4 结点的层次
结点的层次(Level)从根开始定义起,根为第一层,根的孩子为第二层,其双亲在同一层的结点互为堂兄弟。显然下图中的 D、E、F 是堂兄弟,而 G、H、丨、J 也是。树中结点的最大层次称为树的深度(depth),当前树的深度为4。
如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。
二、树的抽象数据类型
相对于线性结构,树的操作就完全不同了,这里我们给出一些基本和常用操作。

三、树的存储结构
我们这里要介绍三种不同的表示法:双亲表示法、孩子表示法、孩子兄弟示法。
3.1 双亲表示法
我们假设以一组连续空间存储树的结点,同时在每个结点中,附设一个指示器指示其双亲结点在链表中的位置。也就是说,每个结点除了知道自己是谁以外,还知道它的双亲在哪里。它的结点结构为下图所示:
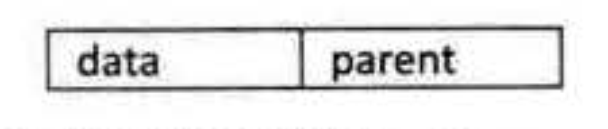
其中 data 是数据域,存储结点的数据信息。而 parent 是指针域,存储该结点的双亲在数组中的下标。以下是我们的双亲表示法的结点结构定义代码:
/* 树的双亲表示法的结点结构定义 */
#define MAX_TREE_SIZE 100
typedef int ElemType; // 树结点的数据类型
typedef struct PTNode //结点结构
{
ElemType data;
int parent; // 父结点位置
}PTNode;
typedef struct // 树结构
{
PTNode nodes{MAX_TREE_SIZE};
int r, n; // 根结点位置,结点数
}Tree;
思路:由于根节点是没有双亲的,所以我们约定根节点的指针域设置为 -1。这也意味着我们所有节点都存有它双亲的位置。树结构和树双亲表示法如下所示:
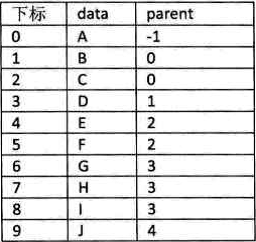
这样的存储结构,我们可以根据结点的 parent 指针很容易找到它的双亲结点,所用的时间复杂度为 〇(1),直到 parent 为 -1 时,表示找到了树结点的根。
总结
优点:该存储方式根据结点的 parent 指针很容易找到它的双亲结点,时间复杂度为 O(1)。
缺点:如果需要知道某个结点的所有孩子,需要遍历整棵树。
3.2 孩子表示法
仔细观察,我们为了要遍历整棵树,把每个结点放到一个顺序存储结构的数组中是合理的,但每个结点的孩子有多少是不确定的,所以我们再对每个结点的孩子建立一个单链表体现它们的关系。
这就是我们要讲的孩子表示法。具体办法是,把每个结点的孩子结点排列起来, 以单链表作存储结构,则 n 个结点有 n 个孩子链表,如果是叶子结点则此单链表为空。然后 n 个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中,如下图所示:
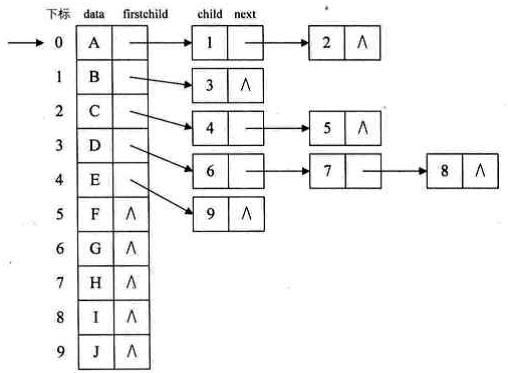
为此,设计两种结点结构,一个是孩子链表的孩子结点,如下图所示。

其中 child 是数据域,用来存储某个结点在表头数组中的下标。next 是指针域,用来存储指向某结点的下一个孩子结点的指针。另一个是表头数组的表头结点,如下图所示:

其中 data 是数据域,存储某结点的数据信息。firstchild 是头指针域,存储该结点的孩子链表的头指针。
以下是我们的孩子表示法的结构定义代码:
/* 树的孩子表示法结构定义 */
#define MAX_TREE_SIZE 100
typedef int TElemType;
typedef struct CTNode //子结点结构
{
struct CTNode *next;
int child;
}CTNode, *ChildPtr;
typedef struct //表头结构
{
TElemType data;
ChildPtr firstchild;
}CTChain;
typedef struct //树结构
{
CTChain nodes{ MAX_TREE_SIZE };
int r, n; //根结点位置,结点数
}Tree;
总结
缺点: 如果需要知道某个结点的双亲,需要遍历整棵树
改进:孩子兄弟表示法
3.3 孩子兄弟表示法
刚才我们分别从双亲的角度和从孩子的角度研究树的存储结构,如果我们从树结点的兄弟的角度又会如何呢?当然,对于树这样的层级结构来说,只研究结点的兄弟是不行的,我们观察后发现,任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。
结点结构如下图所示:

其中 data 是数据域,firstchild 为指针域,存储该结点的第一个孩子结点的存储地址,rightsib 是指针域,存储该结点的右兄弟结点的存储地址。
孩子兄弟表示法的结构定义代码如下:
/* 树的孩子兄弟表示法结构定义 */
typedef struct CSNode
{
TElemType data;
struct CSNode *fristchild, *rightsib;
} CSNode, *CSTree;
这种方法实现的示意图如下图所示。
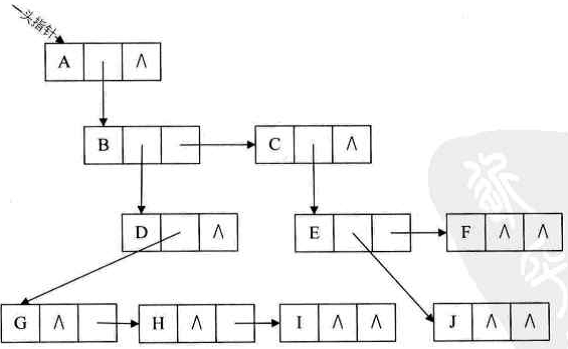
这种表示法,给查找某个结点的某个孩子带来了方便,只需要通过 fistchild 找到此结点的长子,然后再通过长子结点的 rightsib 找到它的二弟,接着一直下去,直到找到具体的孩子。当然,如果想找某个结点的双亲,完全可以再增加一个 parent 指针域来解决快速查找双亲的问题,这里就不再细谈了。
总结
优点: 可以把一棵复杂的树变成一棵二叉树,这样就可以充分利用二叉树的特性和算法来处理这棵树了。
参考:
《大话数据结构 - 第6章》 树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号