day02_20190106 基础数据类型 编码
太白的学习目录 https://www.cnblogs.com/jin-xin/p/9076242.html
编码 上
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字(010101).如果我们想保存数据,首先得将我们的数据进行一些处理,最终得转换成010101才能让计算机识别。
所以必须经过一个过程:
字符(str)--------(编码过程)------->数字(bytes 二进制字符串 类似str)
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
1、ASCII:最初版本的编码方式:(支持对英文字母、数字、特殊字符等进行编码)
ASCII码是上个世纪最流行的编码体系之一,至少在西方是这样。下图显示了ASCII码中编码单元是怎么映射到字符上的。
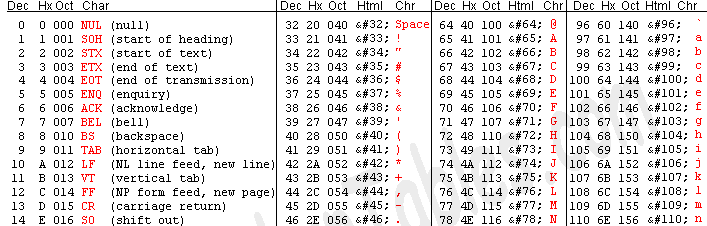
最开始:
0000 0001 256种可能。 0000 0001 8位 = 1个字节(bytes)。
s1 = 'hello1' 6个字节 ,一个字节表示一个字符。
h-------->01101000 e-------->01100101 l -------->01101100 l -------->01101100 o -------->01101111 1 --------> 00110001
2、GBK:为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符;为了满足其他国家,各个国家纷纷定制了自己的编码。日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
只包含:本国语言(中文汉字、中文特殊字符等)和对ASCII的映射(支持对英文字母、数字、特殊字符等进行编码)
GBK是GB2313的升级版 支持21000+个汉字
3、unicode:万国码。把全世界所有的文字都记录起来。(2~4个字节,已经收录了136690个字符,还在一直不断扩张中。。。)
起初:一个字符两个字节 (只能表示256*256个)
h: 01101000 01101000 中:01101000 01101000
不够用升级:一个字符四个字节
h: 01101000 01101000 01101000 01101000 中: 01111000 01101000 01101000 01101000
浪费空间,浪费流量
Unicode包含了跟全球所有国家编码的映射关系,解决了字符与二进制(bytes)的对应关系、但是使用Unicode表示一个字符,太浪费空间。例如利用Unicode表示“Python”需要12个字节才能表示,比原来Ascll表示增加了1倍
由于计算机的内存比较大。并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
4、utf-8: 最少用8位一个字节表示一个字符。
为了解决存储和网络传输的问题,出现了 Unicode Transformation Format,学术名:UTF
h: 01101000 ASCII 英文字符:1个字节表示
Tú.: 01101000 01101000 欧洲语系:一个字符2个字节表示
中: 01101000 01101100 01101000 东亚:一个字符用3个字节表示。
'中国 I LOVE YOU' utf-8的编码方式: 14个字节
单位转化:
8bit == 1bytes (字节) 1024bytes == 1KB 1024KB == 1MB 1024MB == 1GB 1024GB == 1TB
Python3文件存储和传输时默认是UTF-8编码方式的;加载进入内存里时Python3解释器把utf-8文件默认解码(decode)成Unicode ; 编写Python3文件时默认编码是Unicode(内存中),存储的时候编码成(encode)utf-8文件; 只有Python3是这样的!!!
# 例子一: 在python3中有两种字符串类型str和bytes 转换 :str ------编码(Unicode或者utf-8)---->bytes
s1 = '中国' # 当程序执行时,'中国'会被以unicode形式保存新的内存空间中,(加载到内存 默认已经Unicode的编码了 已经变成bytes了)
# unicode ---> utf-8
#s指向的是unicode,因而可以编码成任意格式,都不会报encode错误
b1 = s1.encode('utf-8') # 编码
print(b1,type(b1))
# utf-8 ----> unicode
s2 = b1.decode('utf-8') # 解码
print(s2,type(s2)) #Python2里面的Unicode类型变成str了
例子二:
s1 = '中国'
b1 = s1.encode('gbk') # gbk编码
print(b1)
# gbk----> unicode
s2 = b1.decode('gbk') # 解码
print(s2)
例子三:
# gbk ---> utf-8
b1 = b'\xd6\xd0\xb9\xfa'
s1 = b1.decode('gbk') # unicode
b2 = s1.encode('utf-8')
print(b2)


1, 不同密码本(编码方式 GBK、UTF-8等等)之间不能互相识别。报错,乱码。 2, 数据的存储或者网络传输不能用unicode的密码本进行编码。 python3x 环境: str类型内部编码方式为Unicode。 所以:str类数据不能直接存储硬盘,或者网络传输。 例子:str: 操作方法 bytes: 拥有和str相同的操作方式 str与bytes是相似的类型 str1 = 'barry' print(str1.upper()) #bytes b1 = b'barry' print(b1.upper()) str类型内部编码方式为Unicode。 bytes类型内部编码方式为非Unicode。 英文: str: 表现形式:'alex' 内部编码:unicode bytes: 表现形式:b'alex' 内部编码:非unicode 中: str: 表现形式:'alex' 内部编码:unicode bytes: 表现形式:b'\xe4\xb8\xad\xe5\x9b\xbd' 内部编码:非unicode
四、 数据类型的转换
bool <---> int
str <---> int
s1 = '100' 全部由数字组成的str ---> int
int(s1)
str(100)
str <---> bool 非空即True '' 空即False
五、基础数据类型 str
1、字符串的索引与切片。
索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。
a = 'ABCDEFGHIJK' print(a[0]) print(a[3]) print(a[5]) print(a[7])
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(原则就是顾首不顾尾)。
a = 'ABCDEFGHIJK' print(a[0:3]) print(a[2:5]) print(a[0:]) #默认到最后 print(a[0:-1]) # -1 是列表中最后一个元素的索引,但是要满足顾头不顾腚的原则,所以取不到K元素 print(a[0:5:2]) #加步长
print(a[5:0:-2]) #反向加步长
2、字符串常用方法。对字符串进行的任何操作都会形成一个新字符串,与原字符串无关。
1. 英文字母大小写切换 (upper()全大写 lower() 全小写 )
username = input('请输入用户名') password = input('请输入密码') code = 'afREd'.upper() your_code = input('请输入验证码:').upper() if code == your_code: if username == 'barry' and password == '123': print('登录成功') else: print('验证码错误')
2. strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符、制表符)或字符序列。 ( lstrip()只去掉左边的、 rstrip()只去掉右边的 )
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
strip()方法语法:str.strip([chars]);
chars -- 移除字符串头尾指定的字符序列。
返回移除字符串头尾指定的字符生成的新字符串。
s1 = ' \talex\n' s2 = 'ewareelexqw' s3 = '\talex ' s4 = 'alex\talex' s5 = s1.strip() s6 = s2.strip('qwe') # 相当于字符串两边 移除列表中的['qwe','qw','we','q','w','e'] s7 = s3.strip() s8 = s4.strip() print(s5) #alex print(s6) #areelex print(s7) #alex print(s8) #alex alex
username = input('请输入用户名').strip() password = input('请输入密码').strip() if username == 'barry' and password == '123': print('登录成功')
3. find和index方法
find 通过元素找索引,找到用第一个则返回,找不到返回-1
index 通过元素找索引,找到用第一个则返回,找不到则报错
s1 = '周末2期python期' # i = s1.find('w') i = s1.find('期',4,) #从索引为4的下标开始找 # i = s1.index('w') print(i)
# ret6 = a4.find("fjdk",1,6)
# print(ret6) # 返回的找到的元素的索引,如果找不到返回-1
# ret61 = a4.index("fjdk",4,6)
# print(ret61) # 返回的找到的元素的索引,找不到报错。
4. split() 默认(可指定分隔符)以空格为分割,返回一个列表。( str ----> list 可以将字符串变为列表)
s1 = 'alex wusir 太白 日天' l1 = s1.split() print(l1) #['alex', 'wusir', '太白', '日天'] s12 = 'alex:wusir:太白:日天' l2 = s12.split(':') print(l2) #['alex', 'wusir', '太白', '日天'] # 指定分隔次数 s11 = ':alex:wusir:太白:日天' l3 = s11.split(':', 2) print(l3) #['', 'alex', 'wusir:太白:日天']
5. splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
方法语法:str.splitlines([keepends])
参数说明: keepends - - 在输出结果里是否保留换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符。
返回值:返回一个包含各行作为元素的列表。
# !/usr/bin/python str1 = 'ab c\n\nde fg\rkl\r\n' print(str1.splitlines()) #['ab c', '', 'de fg', 'kl'] str2 = 'ab c\n\nde fg\rkl\r\n' print(str2.splitlines(True)) #['ab c\n', '\n', 'de fg\r', 'kl\r\n']
6. join 合并列表里的字符串成为一个大字符串
l1 = ['alex', 'wusir', '太白', '日天'] # s2 = '_'.join(l1) s2 = '*'.join(l1) # 前提条件:此列表必须全部是有字符串元素组成 # s2 = ''.join(l1) print(s2)
7. replace 默认全部替换 也可以设置替换次数
s1 = 'python深圳分校 深圳是一个很美丽的城市,我爱深圳' # s2 = s1.replace('深圳', '北京') s2 = s1.replace('深圳', '北京', 1) #只替换一次 print(s2)
8. format
# # 第一种 # msg = '我叫{} 今年{} 性别{}'.format('太白', '18', '男') # print(msg) # # 第二种 # msg = '我叫{0} 今年{1} 性别{2},我依然叫{0}'.format('太白', '18', '男') # print(msg) # # 第三种 msg = '我叫{name} 今年{age} 性别{sex}'.format(name='太白', sex='男',age='18',) print(msg)
9. count 计算某个元素出现的次数
s1 = 'barryafdfdafdaaa' i = s1.count('a') print(i)
# ret3 = a1.count("a",0,4) # 可切片
# print(ret3)
10. is 系列
name = 'taibai123' # print(name.isalnum()) #字符串由字母或数字组成 # print(name.isalpha()) #字符串只由字母组成 # print(name.isdigit()) #字符串只由数字组成
11. startswith 判断以...为开始 endswith 判断以...为结尾
s1 = '太白barry' print(s1.startswith("太")) print(s1.startswith("b",2,5)) #下表为2的元素开始 至 下标为5的元素 为止 顾头不顾尾 print(s1.startswith("ba",2,5))
12. len 内置函数
# s1 = 'fjdsklfsjafldsfjskladfjsladfjldksa' # print(len(s1)) s1 = 'python2期' # while count = 0 while count < len(s1): print(s1[count]) count += 1 # for 循环 # for 变量 in iterable: # pass for i in s1: print(i,type(i)) for i in s1: print(i + 'sb')
13 .其它方法
name = 'abC' #captalize,swapcase,title print(name.capitalize()) #首字母大写 Abc print(name.swapcase()) #大小写翻转 ABc msg='taibai say hi' print(msg.title()) #每个单词的首字母大写 Taibai Say Hi # 内同居中,总长度,空白处填充 a1 = 'haha' ret2 = a1.center(20,"*") print(ret2) #********haha********
六、基础数据类型 list(tuple)
str数据类型这么强大 为什么要引入list?
如:str类型:'alex123'
1,存储少量数据。 2,数据类型单一。
容器类的数据类型:基础数据类型之一:list。
l1 = [1,'alex',True,[1,2,3], ().....]
列表可以存储大量的数据,列表是有顺序的。列表有索引,切片,切片(步长)
当你需要大量数据进行存储,并且是按照一定顺序,考虑到list
# 索引,切片。 顾首不顾尾:首从索引0开始,尾从索引-1开始。
l1 = [100, 'alex', True, [1,2,3]] print(l1[0],type(l1[0])) #100 <class 'int'> print(l1[-2]) #True print(l1[:3]) #[100, 'alex', True]
列表的常用操作方法.增删改查其他操作
l1 = ['alex', 'wusir', '太白金星','日天', '女神'] # 1、append 追加 ret01 = l1.append(666) print(ret01) #None print(l1) #['alex', 'wusir', '太白金星', '日天', '女神', 666] # 2、insert插入 insert(索引,元素) ret02=l1.insert(1,'日天') print(ret02)#None print(l1)#['alex', '日天', 'wusir', '太白金星', '日天', '女神', 666] # 3、extend 迭代着追加 l1.extend('abc') ret03=l1.extend([1,2,3]) print(ret03)#None print(l1) #['alex', '日天', 'wusir', '太白金星', '日天', '女神', 666, 'a', 'b', 'c', 1, 2, 3]
l1 = ['alex', 'wusir', '太白金星','日天', '女神'] # 1、pop 按照索引删除 有返回值 # ret = l1.pop(-1) # print(ret) #女神 并返回该索引值 # 2、remove 按照元素删除 # ret1 = l1.remove('alex') # print(l1,ret1) #['wusir', '太白金星', '日天', '女神'] None # 3、clear # l1.clear() # print(l1) #[] # 4、del del l1[0] # 按照索引删除 print(l1) del l1[:2] # 按照切片删除 print(l1) del l1 # print(l1)
l1 = ['alex', 'wusir', '太白金星','日天', '女神'] # 按照索引改值 l1[1] = 'sb' print(l1) #['alex', 'sb', '太白金星', '日天', '女神'] # 按照切片改值 l1[:3] = 'haxi' print(l1) #['h', 'a', 'x', 'i', '日天', '女神']
# 四、查:可以索引切片 for循环 l1 = ['alex', 'wusir', '太白金星','日天', '女神'] for i in l1: print(i)
其他操作方法
l1 = ['alex', 'wusir', '太白金星','日天', '女神'] 1、元素个数 print(len(l1)) 2、count 次数 ret = l1.count('太白金星') print(ret) 3、index 通过元素找索引,找不到报错 # ret = l1.index('日天1') # print(ret) 4、sort与reverse l2 = [5, 6, 4, 0, 9, 1, 7, 8] l2.sort() # 从小到大 l2.sort(reverse=True) # 从大到小 l2.reverse() # 翻转 print(l2)
列表的嵌套
l1 = [1, 2, 'taibai', [1, 'alex', 3, ]] ''' 1, 将l1中的'taibai'变成大写并放回原处。 2,给小列表[1,'alex',3,]追加一个元素,'老男孩教育'。 3,将列表中的'alex'通过字符串拼接的方式在列表中变成'alexsb'。 ''' l1[2] = l1[2].upper() l1[-1].append('老男孩教育') l1[3][1] = l1[3][1] + 'sb' print(l1)
# range 可以视为一个可控的数字范围的列表,多于for循环结合。 # for i in range(1,10): # [1,2,3,4,...9] # print(i) # for i in range(20): # [0,1,2,3,4,...19] # print(i) for i in range(0,10,2): print(i) print(range(10)) for i in range(10, 1, -1): print(i) # range 打印列表的索引 l1 = ['alex', 'wusir', '太白金星','日天', '女神'] for index in range(len(l1)): print(index)
元组: 基础数据类型之一:tuple
# 存储数据,重要的数据。元组不可以增删改,可以查询,元组的子集可以修改 。元组也有索引切片。
tu1 = (100, True, [1,2,3]) print(tu1[0]) for i in tu1: print(i) tu1[-1].append(666) print(tu1) #(100, True, [1, 2, 3, 666])
七、基础数据类型 dict
有了列表,why还要使用字典?
1,列表的数据量越大,查询速度越慢。2,列表存储的数据没有什么关联性。
基础数据类型之dict eg:dic = {'name': 'barry'} 字典是以键值对的形式存储的。
字典的键key:必须是不可变得数据类型:int str
字典的值:任意数据类型 变量,对象。
字典可以存储大量的数据,而且字典的查询速度非常快。
字典的key 唯一的不重复的。
字典 3.5之前是无序的,字典在3.5之后是有序的初始化时的顺序。
构建数据类型:大量的关系型数据时,要到字典。
数据类型的划分:
可变的(不可哈希)数据类型:list dict set
不可变(可哈希)的数据类型:tuple str int bool
# 1、增:有则修改,无则增加 dic = {'name': 'alex', 'age': 46, 'sex': 'laddyboy'} dic['high'] = 175 dic['name'] = '日天' # 有则不变,无则增加 dic.setdefault('weight',200) dic.setdefault('age',73) print(dic) # 2、删除: (pop、clear、del) dic = {'name': 'alex', 'age': 46, 'sex': 'laddyboy'} ret = dic.pop('name')#按照key删除键值对,有返回值 返回值为删除键的值 print(ret,dic)#alex {'age': 46, 'sex': 'laddyboy'} dic.clear()#清空该字典的所有值 不删字典 print(dic) #{} #del dic #删除整个字典 # del dic['name'] #删除某个值 # 3、改 dic = {"name":"jin","age":18,"sex":"male"} dic['name'] = '日天' #修改单个值 dic2 = {"name":"alex","weight":75} dic2.update(dic) # 将dic的键值对覆盖添加到dic2中,dic不变。 print(dic,dic2)#{'name': '日天', 'age': 18, 'sex': 'male'} {'name': '日天', 'weight': 75, 'age': 18, 'sex': 'male'} # 4、查 dic = {'name': 'alex', 'age': 46, 'sex': 'laddyboy'} print(dic['name']) # print(dic['name1']) #KeyError: 'name1' ret01 = dic.get('name1') #None ret02 = dic.get('name1', '没有此键') ret03 = dic.get('name') print(ret01,ret02,ret03) #None 没有此键 alex
5、其他方法:
dic = {'name': 'alex', 'age': 46, 'sex': 'laddyboy'}
for key in dic:
print(key,dic[key])
#name alex
#age 46
#sex laddyboy
# dic.keys() dic.values() dic.items()
print(dic.keys(),type(dic.keys())) #dict_keys(['name', 'age', 'sex']) <class 'dict_keys'>
for key in dic.keys():
print(key,type(key))
for value in dic.values():
print(value)
print(dic.items()) # dict_items([('name', 'alex'), ('age', 46), ('sex', 'laddyboy')])
for k,v in dic.items():
print(k,v)
print(list(dic.items())) #[('name', 'alex'), ('age', 46), ('sex', 'laddyboy')]
6、嵌套
dic = { 'name_list': ['张三', '李四', 'BARRY'], 1:{'name':'taibai', 'age': 18}, 'barry': {} } # 1,给列表追加一个值:'王五' dic['name_list'].append('王五') print(dic) # 2,将BARRY 变成全部小写 print(dic['name_list'][-1].lower()) dic['name_list'][-1] = dic['name_list'][-1].lower() print(dic) # 3,给{'name':'taibai', 'age': 18} 增加一个键值对 sex: 男。 print(dic[1]) dic[1]['sex'] = '男' print(dic)
八、基础数据类型的补充(汇总)。
int str bool list tuple dict
# 数据类型的转换。
分别赋值
a, b = 1, 4 print(a,b) #1 4 c, d = (1,4) print(c,d) #1 4 e, f = [[1,2,3],'alex'] print(e,f)#[1, 2, 3] alex
list 列表的一个坑
l1 = [11, 22, 33, 44, 55] # 将列表中索引为奇数位的元素删除 # 正常思路(错误示范): for index in range(len(l1)): if index % 2 == 1: del l1[index] print(l1) # 方法一: del l1[1::2] print(l1) # 方法二: # 倒叙删除 for index in range(len(l1)-1,-1,-1): # index -= 1 if index % 2 == 1: l1.pop(index) print(l1) # 总结:对于列表来说,你在循环一个列表时,不要改变列表的大小,会影响你的最终结果
字典的一个坑
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': '太白'}
# 将字典的键中含有k元素的所有键值对删除
for key in dic:
if 'k' in key:
dic.pop(key)
print(dic)
# 满足条件的key添加到一个新列表中,循环列表删除相应的键值对。
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
print(l1)
for i in l1:
dic.pop(i)
print(dic)
1, 不同密码本(编码方式 GBK、UTF-8等等)之间不能互相识别。报错,乱码。 2, 数据的存储或者网络传输不能用unicode的密码本进行编码。 python3x 环境: str类型内部编码方式为Unicode。 所以:str类数据不能直接存储硬盘,或者网络传输。 例子:str: 操作方法 bytes: 拥有和str相同的操作方式 str与bytes是相似的类型 str1 = 'barry' print(str1.upper()) #bytes b1 = b'barry' print(b1.upper()) str类型内部编码方式为Unicode。 bytes类型内部编码方式为非Unicode。 英文: str: 表现形式:'alex' 内部编码:unicode bytes: 表现形式:b'alex' 内部编码:非unicode 中: str: 表现形式:'alex' 内部编码:unicode bytes: 表现形式:b'\xe4\xb8\xad\xe5\x9b\xbd' 内部编码:非unicode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号