
8.Kubernetes Service(服务)
1.概述
Service也是Kubernetes里的最核心的资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个“微服务”,之前我们所说的Pod、RC等资源对象其实都是为这节所说的“服务”------Kubernetes Service作“嫁衣”的。图1.12显示了Pod、RC与Service的逻辑关系。
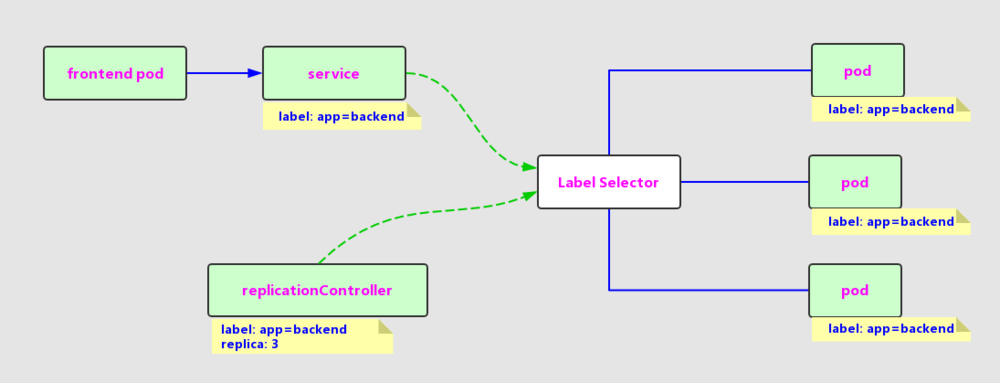
Pod、RC与Service的关系
从图中我们看到,Kubernetes的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过Label Selector来实现“无缝对接”的。而RC的作用实际上是保证Service的服务能力和服务质量始终处于预期的标准。
通过分析、识别并建模系统中的所有服务为微服务-----Kubernetes Service,最终我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过TCP/IP进行通信,从而形成了我们强大而又灵活的弹性网格,拥有了强大的分布式能力、弹性扩展能力、容错能力,于此同时,我们的程序架构也变得简单和直观许多,如图1.13所示。
Kubernetes所提供的微服务网格架构
既然每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务,那么客户端如何来访问它们呢?一般的做法是部署一个负载均衡器(软件或硬件),为这组Pod开启一个对外的服务端口如8000端口,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端就可以通过负载均衡器的对外IP地址+服务端口来访问服务,而客户端的请求最后会被转发转发到哪个Pod,则由负载均衡器的算法所决定。
Kubernetes也遵循了上述常规做法,运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部shi xian实现服务的负载均衡与会话机制。但Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡的IP地址,而是每个Service分配了全局唯一的虚拟IP地址,这个虚拟IP地址被称为Cluster IP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
我们知道,Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内。它的Cluster IP不会发生改变。于是,服务发现这个棘手的问题在Kubernetes的架构里也得到轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。现在想想,这真是一个很棒的设计。
说了这么久,下面我们动手创建一个Service,来加深对它的理解。首先我们创建一个名为tomcat-service.yaml的定义文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
ports:
- port: 8080
selector:
tier: frontend
上述内容定义了一个名为“tomcat-service”的Service,它的服务端口为8080,拥有“tier-frontend”这个Label的所有Pod实例都属于它,运行下面的命令进行创建:
# kubectl create -f tomcat-service.yaml
service "tomcat-service" created
注意到我们之前在tomcat-deployment.yaml里定义的Tomcat的Pod刚好拥有这个标签,所以我们刚才创建的tomcat-service已经对应到了一个Pod实例,运行下面的命令可以查看tomcat-service的Endpoint列表,其中172.17.1.3是Pod的IP地址,端口8080是Container暴露的端口:
# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.18.131:6443 15d
tomcat-service 172.17.1.3:8080 1m
你可能有疑问:“说好的Service的Cluster IP呢?怎么没有看到?”我们运行下面的命令即可看到tomcat-service被分配的Cluster IP及更多的信息:
# kubectl get svc tomcat-service -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2018-10-17T10:04:21Z
name: tomcat-service
namespace: default
resourceVersion: "10169415"
selfLink: /api/v1/namespaces/default/services/tomcat-service
uid: 04caf53f-d1f4-11e8-83a3-5254008f2a0b
spec:
clusterIP: 10.254.169.39
ports:
- port: 8080
protocol: TCP
targetPort: 8080
selector:
tier: frontend
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
在spec.ports的定义中,targetPort属性用来确定提供该服务的容器所暴露(EXPOSE)的端口号,即具体业务进程在容器内的targetPort上提供TCP/IP接入;而port属性则定义了Service的虚拟端口。前面我们定义Tomcat服务时,没有指定targetPort,则默认targetPort与port相同。
接下来,我们来看看Service的多端口问题。
很多服务都存在多个端口的问题,通常一个端口提供业务服务,另外一个端口提供管理服务,比如Mycat、Codis等常见中间件。Kubernetes Service支持多个Endpoint,在存在多个Endpoint的情况下,要求每个Endpoint定义一个名字区分。下面是Tomcat多端口的Service定义样例:
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
ports:
- port: 8080
name: service-port
- port: 8005
name: shutdown-port
selector:
tier: frontend
多端口为什么需要給每个端口命名呢?这就涉及Kubernetes的服务发现机制了,我们接下来进行讲解。
2.Kubernetes的服务发现机制
任何分布式系统都会涉及“服务发现”这个基础问题,大部分分布式系统通过提供特定的API接口来实现服务发现的功能,但这样做会导致平台的入侵性比较强,也增加了开发测试的困难。Kubernetes则采用了直观朴素的思路去解决这个棘手的问题。
首先,每个Kubernetes中的Service都有一个唯一的Cluster IP及唯一的名字,而名字是由开发者自己定义的,部署时也没有改变,所以完全可以固定在配置中。接下来的问题就是如何通过Service的名字找到对应的Cluster IP?
最早时Kubernetes采用了Linux环境变量的方式解决这个问题,即每个Service生成一些对应的Linux环境变量(ENV),并在每个Pod的容器在启动时,自动注入这些环境变量,以下是tomcat-service产生的环境变量条目:
TOMCAT_SERVICE_SERVICE_HOST=10.254.93.4
TOMCAT_SERVICE_SERVICE_PORT_SERVICE_PORT=8080
TOMCAT_SERVICE_SERVICE_PORT_SHUTDOWN_PORT=8005
TOMCAT_SERVICE_SERVICE_PORT=8080
TOMCAT_SERVICE_PORT=tcp://10.254.93.4:8080
TOMCAT_SERVICE_PORT_8080_TCP_ADDR=10.254.93.4
TOMCAT_SERVICE_PORT_8080_TCP=tcp://10.254.93.4:8080
TOMCAT_SERVICE_PORT_8080_TCP_PROTO=tcp
TOMCAT_SERVICE_PORT_8080_TCP_PORT=8080
TOMCAT_SERVICE_PORT_8005_TCP=tcp://10.254.93.4:8005
TOMCAT_SERVICE_PORT_8005_TCP_ADDR=10.254.93.4
TOMCAT_SERVICE_PORT_8005_TCP_PROTO=tcp
TOMCAT_SERVICE_PORT_8005_TCP_PORT=8005
上述环境变量中,比较重要的是前3条环境变量,我们可以看到,每个Service的IP地址及端口都是有标准的命名规范,就可以通过代码访问系统环境变量的方式得到所需的信息,实现服务调用。
考虑到环境变量的方式获取Service的IP与端口的方式仍然不太方便,不够直观,后来Kubernetes通过Add-On增值包的方式引入了DNS系统,把服务名作为dns域名,这样一来,程序就可以直接使用服务名来建立通信连接了。目前Kubernetes上的大部分应用都已经采用了DNS这些新型的服务发现机制,后面的章节中我们会讲述如何部署这套DNS系统。
3.外部系统访问Service的问题
为了更好深入地理解和掌握Kubernetes,我们需要弄明白Kubernetes里的“三种IP”这个关键问题,这三种分别如下。
- Node IP:Node节点的IP地址。
- Pod IP:Pod的IP地址。
- Cluster IP:Service的IP地址。
首先,Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,必须要通过Node IP进行通信。
其次,Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过,Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
最后,我们说说Service的Cluster IP,它也是一个虚拟的IP,但更像是一个“伪造”的IP网络,原因有以下几点。
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。
- Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。
- 在Kubernetes集群之内,Node IP网、Pod IP网与Clsuter IP之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。
根据上面的分析和总结,我们基本明白了:Service的Cluster IP属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾来了:实际上我们开发的业务系统中肯定多少由一部分服务是要提供給Kubernetes集群外部的应用或者用户来使用的,典型的例子就是Web端的服务模块,比如上面的tomcat-service,那么用户怎么访问它?
采用NodePort是解决上述问题的最直接、最常用的做法。具体做法如下,以tomcat-service为例,我们在Service的定义里做如下扩展即可(黑体字部分):
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31002
selector:
tier: frontend
其中,nodePort:31002这个属性表明我们手动指定tomcat-service的NodePort为31002,否则Kubernetes会自动分配一个可用的端口。接下来,我们在浏览器里访问https://<nodePort IP>:31002,就可以看到Tomcat的欢迎界面了,如图1.14所示。
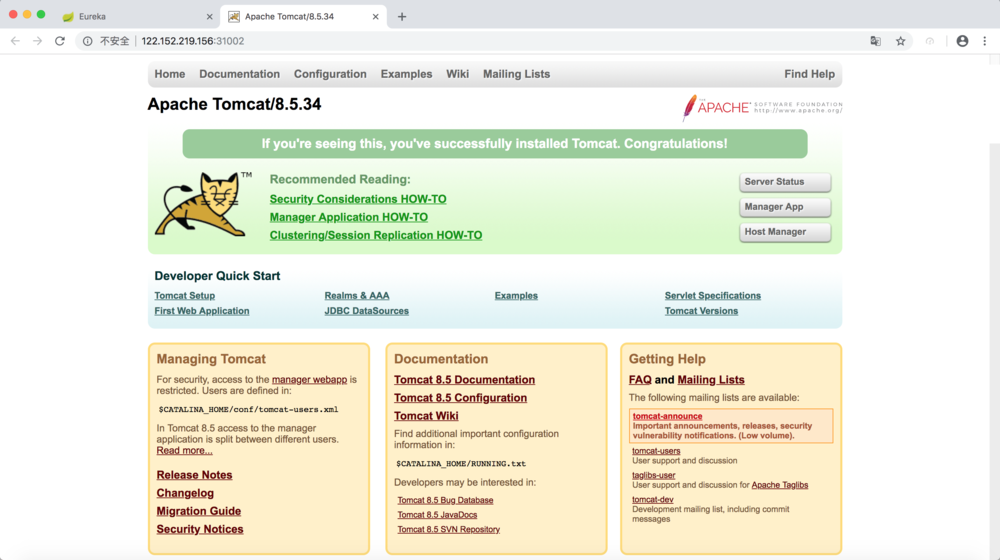
通过NodePort访问Service
NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口号即可访问此服务,在任意Node上运行netstat命令,我们就可以看到有NodePort端口被监听:
# netstat -tlp|grep 31002
tcp6 0 0 [::]:31002 [::]:* LISTEN 19043/kube-proxy
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需要访问此负载均衡器的IP地址,由负载均衡负责转发流量到后面某个Node的NodePort上。如图1.15所示。
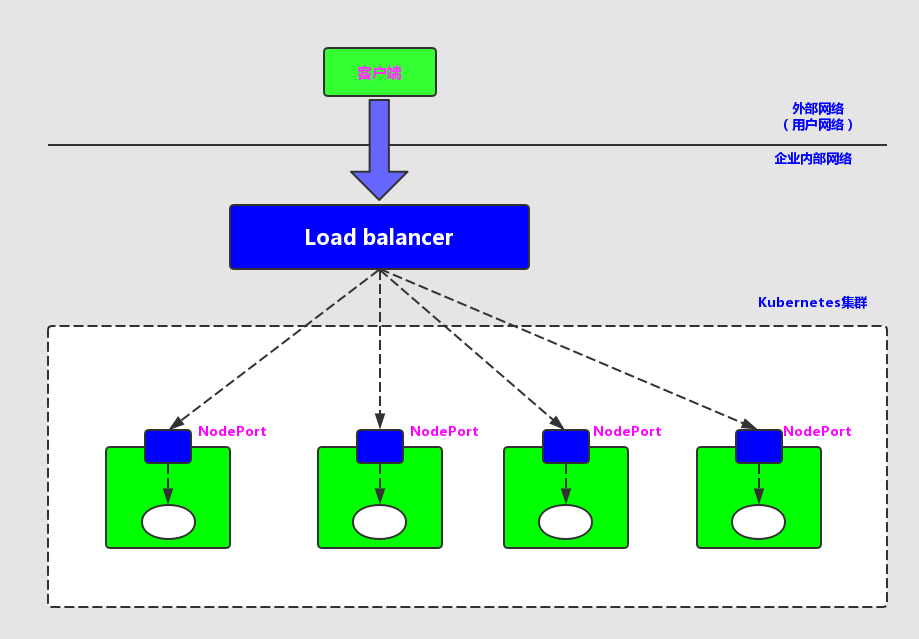
NodePort与Load balancer
图中的Load balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要配置一个对应的Load balancer实例来转发流量到后端的Node上,这的确增加了工作量及出错的概率。于是Kubernetes提供了自动化的解决方案,如果我们的集群运行在谷歌的GCE公有云上,那么只要我们把Service的type=NodePort改为type=LoadBalancer,此时Kubernetes会自动创建一个对应的Load balancer实例并返回它的IP地址供外部客户端使用。此时Kubernetes会自动创建一个对应的Load balancer实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到上述目的。此外,裸机上的类似机制(Bare Metal Service Load Balancers)也正在被开发。
链接:https://www.orchome.com/1339著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号