
Python爬虫学习(9):Selenium的使用
1 简介以及安装
Selenium 是什么?一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。换句话说叫 Selenium 支持这些浏览器驱动。Selenium支持多种语言开发,比如 Java,C,Ruby等等,有 Python 吗?那是必须的!哦这可真是天大的好消息啊。
Selenium 2,又名 WebDriver,它的主要新功能是集成了 Selenium 1.0 以及 WebDriver(WebDriver 曾经是 Selenium 的竞争对手)。也就是说 Selenium 2 是 Selenium 和 WebDriver 两个项目的合并,即 Selenium 2 兼容 Selenium,它既支持 Selenium API 也支持 WebDriver API。
安装:如果已经安装了pip,则可以直接通过它安装:
pip install selenium
文档: http://selenium-python.readthedocs.io/
2. 简单使用
2.1 打开浏览器
#!/usr/bin/python from selenium import webdriver browser=webdriver.Firefox() browser.get("http://www.baidu.com")
报错:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable may have wrong permissions.
程序执行错误,浏览器没有打开,那么应该是没有把 Firefox 驱动没有配置在环境变量里。下载驱动,然后将驱动文件路径配置在环境变量即可。
下载地址: https://github.com/mozilla/geckodriver/releases/
下载完成后将其加压到/usr/local/bin目录中,然后再在执行,我们看到直接就弹出浏览器并且其页面是百度。
2.2 发送数据
为了交互方便,就直接用ipython来进行下边的操作.。(如果没有,在centos7中可以直接安装:sudo yum install ipython)。
安装完成后就可以直接在命令中输入ipython启动ipython,然后就可以在其中输入python语句,并且带有tab补全功能。下边示例就是打开firefox
依次执行以下语:
In [1]: from selenium import webdriver In [2]: from selenium.webdriver.common.keys import Keys # 打开浏览器 In [3]: browser = webdriver.Firefox() # 其中 driver.get 方法会打开请求的URL,WebDriver 会等待页面完全加载完成之后才会返回,
# 即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。
# 注意:如果这里用到了特别多的 Ajax 的话,程序可能不知道是否已经完全加载完毕。 In [4]: browser.get("http://www.baidu.com")
然后我们通过firebug(firefox 中按F12),找出百度的输入框的名称。发现输入框的名称为: wd

接下来,我们通过selenium在这个输入框中输入值:
#通过元素名称找到页面输入框 In [5]: elem = browser.find_element_by_name("wd") #在输入框中输入查询内容 In [6]: elem.send_keys("selenium")
这时我们发现在页面中已经出现了查询值:
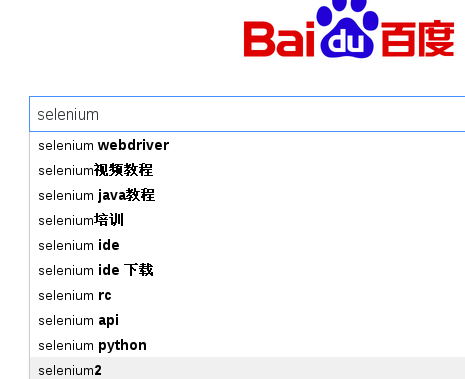
接着可以通过发送向下箭头指示让其在上述的选项中选择:
elem.send_keys(Keys.ARROW_DOWN)
然后我们可以通过selenium输入一个回车进行查询,结果可以直接在浏览器中查看。(是不是感觉很强大,通过语句操作浏览器)
In [7]: elem.send_keys(Keys.RETURN)
之后我们可以通过browser.page_source获得渲染后的页面
3. 交互
在前边的2.2部分已经说明一部分关于交互的使用。这里将更进一步说明。
3.1 元素的获取(详情请点这里: http://selenium-python.readthedocs.io/locating-elements.html)
当有如下定义的元素的时候:
<input type="text" name="passwd" id="passwd-id" />
我们可以通过以下几种方式定位到这个元素:
# 通过元素ID获取此元素 element = driver.find_element_by_id("passwd-id") # 通过元素的名称获取元素 element = driver.find_element_by_name("passwd") # 通过xpath获取元素 element = driver.find_element_by_xpath("//input[@id='passwd-id']") # 下边是其它的方法 find_element_by_tag_name find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
可以通过以下方法找到多个元素:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
注意:如果没有找到相应的元素的时候,会抛出NoSuchElementException异常。获取到的元素都用一个类表示,这就意味着,如果你用IDE的时候,给你自动提示很多的方法中不是每一个都能调用的。
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历,也可以在HTML中使用,xpath的知识点不多,如果要学习,请点击下边的地址:
3.2 选择
前边我们已经成功获取并进入到文本框中,现在我们来操作以下其它的元素。比如我们要出发下拉框,我们可以这样做:
# 获取下拉的元素 element = driver.find_element_by_xpath("//select[@name='name']") # 获取下拉中的所有选项 all_options = element.find_elements_by_tag_name("option") # 便利所有的选项,输出其值,并点击每一个选项 for option in all_options: print("Value is: %s" % option.get_attribute("value")) option.click()
当然上述不是最有效的方式,selenium提供一个类用于处理这种Slelect元素。以下方法可以凭借其方法名理解其有何用。也可以借助ipython中的help()来查看某个方法的作用以及其详细使用方法。
from selenium.webdriver.support.ui import Select select = Select(driver.find_element_by_name('name')) select.select_by_index(index) select.select_by_visible_text("text") select.select_by_value(value)
试想以下,我们可能拿selenium来做测试,可能需要对所有的选项都要测试,下边就可以获取素有的选项:
select = Select(driver.find_element_by_xpath("xpath")) all_selected_options = select.all_selected_options
3.3 提交
当你填写完成form表单之后,你会通过submit来提交表单。其中的一种方法是通过找到submit按钮,然后让你响应点击。
# 假设你的submit的id为ok driver.find_element_by_id("ok").click()
selenium提供了一个方便的submit()方法,当你通过表单元素调用submit()方法的时候就可以完成提交。
element.submit()
3.4 拖拽
你可以移动某个元素一定的距离,也可以将一个元素移动到另一个元素中去。
from selenium.webdriver import ActionChains element = driver.find_element_by_name("source") target = driver.find_element_by_name("target") action_chains = ActionChains(driver) action_chains.drag_and_drop(element, target).perform()
3.5 历史记录
在历史记录中前进或者后退
# 前进到前边的页面 driver.forward() # 后退到以前的一个页面 driver.back()
3.6 Cookies
可以通过以下方法来获取Cookies
# Go to the correct domain driver.get("http://www.example.com")# And now output all the available cookies for the current URL driver.get_cookies()
4. 等待
这是非常重要的一部分,现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。这会让元素定位困难而且会提高产生 ElementNotVisibleException 的概率。
所以 Selenium 提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待是指定某一条件直到这个条件成立时继续执行,隐式等待是等待特定的时间。
显式等待:
显示等待是设定一个时间段和一个条件,当超过这个时间段而设定的条件没有发生则会抛出异常,只有在规定的时间段内条件发生才算正常
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://somedomain/url_that_delays_loading") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
上诉例子说明在10秒时间内还没有发现ID为myDynamicElement的元素,则会抛出TimeoutException异常。实际上会每过500ms去执行条件,当发现了元素后就正确返回。
下边是可能用到的条件:
title_is title_contains presence_of_element_located visibility_of_element_located visibility_of presence_of_all_elements_located text_to_be_present_in_element text_to_be_present_in_element_value frame_to_be_available_and_switch_to_it invisibility_of_element_located element_to_be_clickable - it is Displayed and Enabled. staleness_of element_to_be_selected element_located_to_be_selected element_selection_state_to_be element_located_selection_state_to_be alert_is_present
隐藏等待:
当需要的元素当前不存在的时候需要等待多长时间。默认的设置时间为0。如果设置了隐式等待,则其在整个WebDriver的实例生存周期类有效。
from selenium import webdriver driver = webdriver.Firefox() driver.implicitly_wait(10) # seconds driver.get("http://somedomain/url_that_delays_loading") myDynamicElement = driver.find_element_by_id("myDynamicElement")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号