
时间复杂度O(n^2)和O(nlog n)差距有多大?
0. 时间复杂度
接触到算法的小伙伴们都会知道时间复杂度(Time Complexity)的概念,这里先放出(渐进)时间复杂度的定义:
假设问题规模是n,算法中基本操作重复执行的次数是n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得
其中c为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
常见的时间复杂度有(表格越靠后表示越不理想):
| 复杂度 | 名称 |
|---|---|
| O(1) | 常数阶 |
| O(logn) | 对数阶 |
| O(n) | 线性阶 |
| O(nlogn) | 线性对数阶 |
| O(n2) | 平方阶 |
| O(n3) | 立方阶 |
| O(nk) | k次方阶(k>3且k∈Z) |
| O(2n) | 指数阶 |
例如,我们熟悉的插入排序(Insertion Sort)算法的时间复杂度是O(n2),而合并排序(Merge Sort)算法的时间复杂度是O(nlogn)
那么这些复杂度之间的差距是怎么样的呢?有些小伙伴会疑问,自己写的算法虽然是高复杂度但是也用的好好的,为什么要纠结于这个概念呢?
我们不妨来探索一下今天的问题:O(n2)和O(nlogn)差距有多大?
1. O(n2)和O(nlogn)差距有多大?
我们知道,插入排序(Insertion Sort)算法的时间复杂度是O(n2),而合并排序(Merge Sort)算法的时间复杂度是O(nlogn),即当排序n个对象时,插入排序算法需要用时大约c1n2,而合并排序算法需要用时大约c2nlogn,其中c1和c2都是正常数且与n无关,且往往c1<c2。
稍微利用初等数学的知识,可以知道,对于任何n>=2,比较约c1n2和c2nlogn即比较c1n和c2logn。由于我们已知
以及
想要比较这两个值的大小,直观的看法就是比较两个不等式谁的差别“更多”。可以证明,当无论c1和c2差别多么显著,总存在充分大的N使得当n>N时,c1n>c2logn。
在Introduction to Algorithms中,作者举了一个很有趣的例子:
假设针对同一排序问题,用一台很快的电脑A运行插入排序,用一台很慢的电脑B运行合并排序,问题规模n=107:
两台电脑的差别如下,为了使A比B优势显著,作者假设电脑A性能比B强1000倍,并且B运行的代码更低效、且编译器更差(导致需要运行更多的指令):
| 电脑A | 电脑B | |
|---|---|---|
| 每秒运行指令数 | 1010 | 107 |
| 需要运行的指令总数 | 2n2 | 50nlogn |
这样,A完成任务需要:
而B完成任务需要:
可以看到,在这样的大规模的问题下,即便B计算机与A差距巨大,最终也只用了20分钟左右就完成排序,而A却需要5.5小时来完成。时间复杂度的差距可见一斑。
3. 总结
算法时间复杂度的量级差异,也许在小规模的问题下,表现差别不大。但是时间复杂度高的算法,对问题规模的变化更加敏感,因而当问题的规模变得很大的时候,靠拥有高阶时间复杂度的算法来求解并不可靠!
(更新)我从网络上找到了一个直观的各个阶的复杂度的对比,大家不妨参考一下:
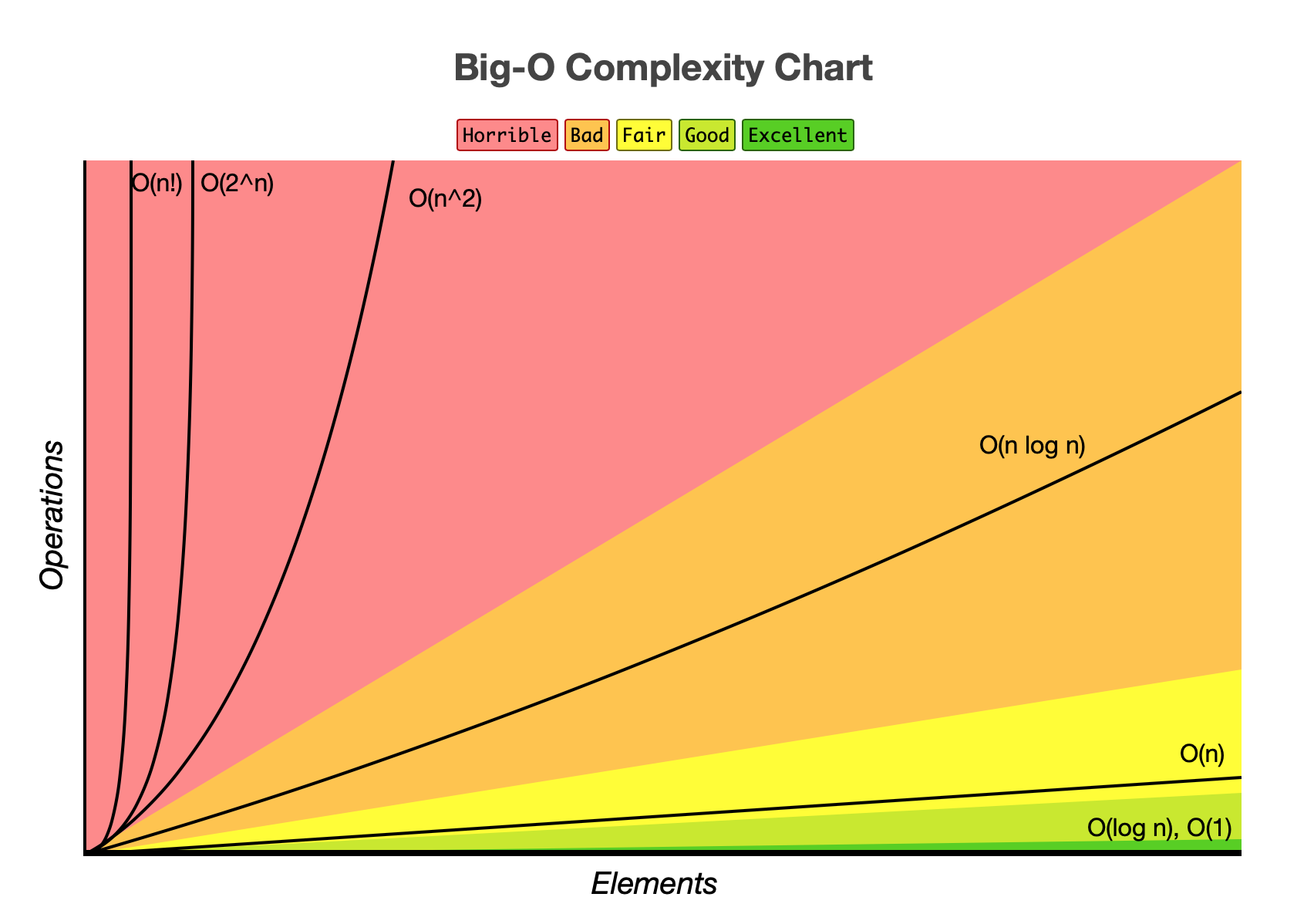
# 喜欢就点个赞、关注支持一下吧!
参考:
Thomas H. Cormen, et al., Introduction to Algorithms Part I 1.2
http://www.bigocheatsheet.com

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步