【大数据开发工程师】面试——HBase
HBase版本:2.2.4
架构
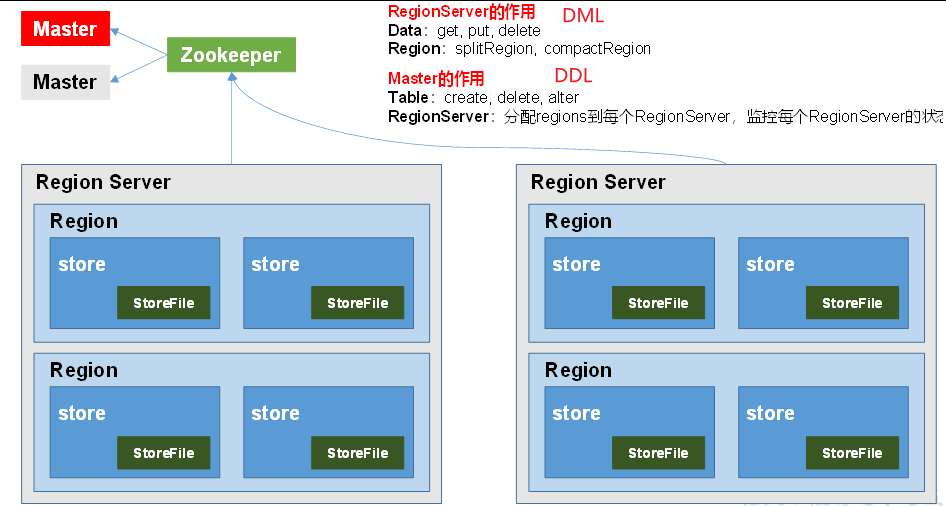
Region Server是Regoin的管理者,其实现类为HRegoinServer;它主要负责对数据的操作;compactRegoin + splitRegoin
Master是所有Regoin Server的管理者,其实现类为HMaster。它主要负责对表的操作;将Regoin分配给RegoinServer,监控每个RegoinServer的状态,实现负载均衡和故障转移。
zookeeper主要负责做master的高可用,元数据meta的入口,集群配置的维护等。负责与客户端的交互,所有客户端读写数据的入口,对数据的增删改查。(所以读写数据时,HMaster挂掉也没有关系)
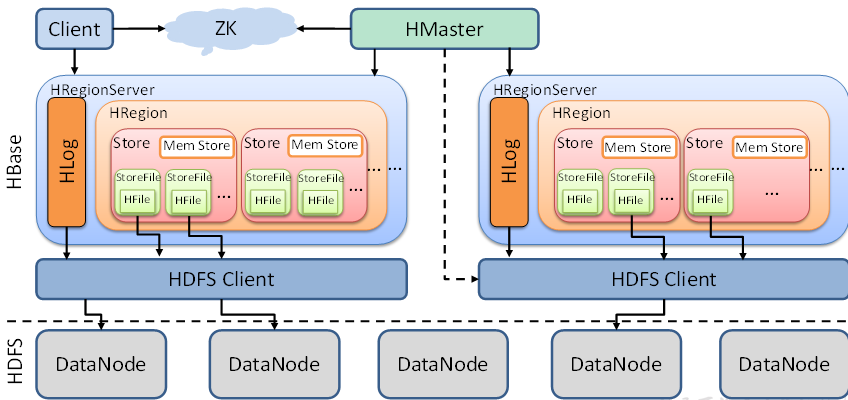
memstore会将数据排好序后,等达到刷写时机再请求调用HDFS Client刷写到StoreFile中,每刷写一次形成一个新的HFile;
StoreFile存储在HDFS上。HFile是其存储格式(类似Parquet,textFile等),是key-value;
Hlog也会写入到HDFS上。
API
org.apache.hadoop.hbase
读写流程
写流程
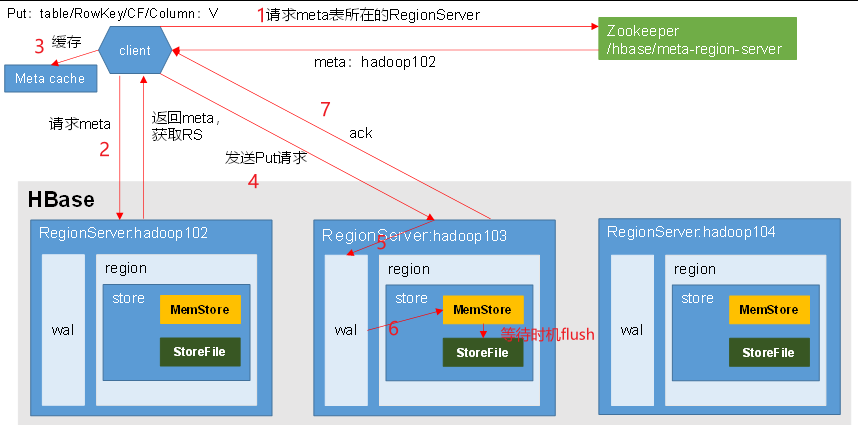
HBase有两个默认的表:meta、namespace。meta表里存有用户/系统表所在的位置,所在的RegoinServer。
zk记录了meta表在哪个RegoinServer上。

flush时机
- 内存
- 一个RegoinServer的所有memstore >= 堆内存*40%。 —— 阻塞写入,开始刷写,会停止其他的所有读写流程。
- 一个RegoinServer的所有memstore下限 >= 堆内存 * 40% * 0.95。—— 开始刷写,不停止其他读写流程。
- 单个Regoin的memstore >= 128M。当前这个Regoin开始刷写。
- 当WAL文件的数量>32个时(这个参数已经不给用户可见了),当前这个Regoin开始刷写。每个WAL文件的大小默认时128M,达到128M时就会形成一个新的文件。
- 时间
- 刷写时间间隔。—— 默认是1个小时,最后一条数据到达一个小时之后,开始刷写。
读流程
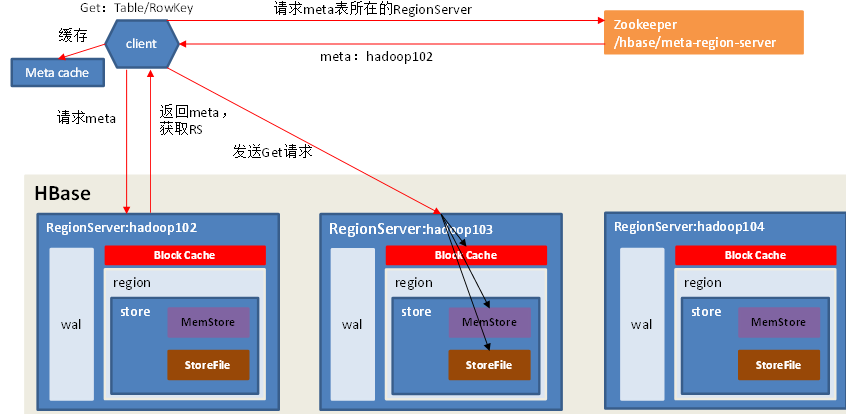
同时读memstore和磁盘,然后把storeFile里面的数据缓存到Block Cache里面,然后将memStore和BlockCache里面的内容做比较,返回时间戳大的内容。
要注意:存在Block Cache中后,就不会再读磁盘里面的这部分内容,但是要读磁盘里的其他内容。
rowKey设计原则
1. 唯一
2. 长度
3. 散列原则:预分区指定个数和范围后,将rowkey设计为:(123123123+2020-01-06).hash%分区数_123123123+2020-01-06
效果:把相同电话号码相同日期的信息放在同一个regoin里,在一个分区里,相同电话号码同一天的所有数据连续地存储在一个区域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号