MySQL(1)-索引总结
索引即用于快速定位数据的特征值,可以使用数据表中的某一/几列来作为索引。
1-1.1 分类
1-1.1.1 按结构
1)B+TREE
(1)定义
(2)匹配规则
-
全值匹配
-
匹配最左前缀(索引最左一列)
-
匹配最左前缀的前缀(索引最左一列的左前缀)
-
一个范围查询
即从索引最左开始,只能按顺序出现一个范围查询条件且位于最后
(3)失效情况
-
不是从最左匹配
-
跳过索引中的某几列匹配
-
某一列范围查询,则后面的列不能使用索引
InnoDB和MyISAM均使用B+TREE索引
2)HASH索引
(1)定义
为数据计算HASH值并存储与HASH表中,并采用拉链法解决HASH冲突
(2)匹配规则
使用HASH值定位bin的位置,再遍历链表来查找对应的数据
(3)失效情况
-
不能使用覆盖索引 因为索引节点的值只用于存储HASH值,不用于存储节点的值
-
有序的数据其对应的HASH值不一定有序,因而不能使用HASH索引提供ORDER BY,同样不支持范围查询
-
不能匹配列的前缀或某一列,因为HASH一般利用全部列进行计算得到
-
HASH冲突很多的数据不适用
自适应HASH
InnoDB中会对经常访问到的索引基于B-TREE索引构建HASH索引以进一步加快访问
自定义HASH
如果使用了B-TREE索引,且某一列的数据很长且适用于计算HASH值,那么可以使用HASH值来进行避免以避免其他类型(字符串匹配)的低效匹配
3)空间树索引R-TREE
索引无须前缀查询,且可以利用任意维度的列进行匹配,需要结合GIS相关函数
4)全文索引
不是单纯的匹配索引的值,而是匹配索引的关键词
1-1.1.2 按内容
-
单值索引
单个列构成的索引
-
组合索引
几个列有序构成的索引
-
聚簇索引
叶子节点同时存储了索引值、事务ID、回滚指针和对应的其他全部列数据,可以减少磁盘IO的次数
-
非聚簇索引
叶子节点只存储的索引的值及对应行数据的指针,需要根据指针再进行一次磁盘IO来得到行数据
-
覆盖索引
索引即包含了所有要查询的值
-
前缀索引
使用索引值中的前缀
1-1.1.3 按存储引擎
1)InnoDB
(1)主键
聚簇索引
如果以主键列为索引查询,那么只需要遍历索引树找到对应的条目(叶子节点)即可得到要查询的数据
(2)非主键
非聚簇索引
子节点中存储了索引+主键的值,那么需要根据主键再遍历一遍主键的索引树来查找对应的数据
2)MyISAM
全部采用非聚簇索引
子节点存储了索引+对应行数据的指针,那么在找到对应的叶子节点之后还需要根据指针再进行一次磁盘IO才可以找到要查询的数据
图片来自
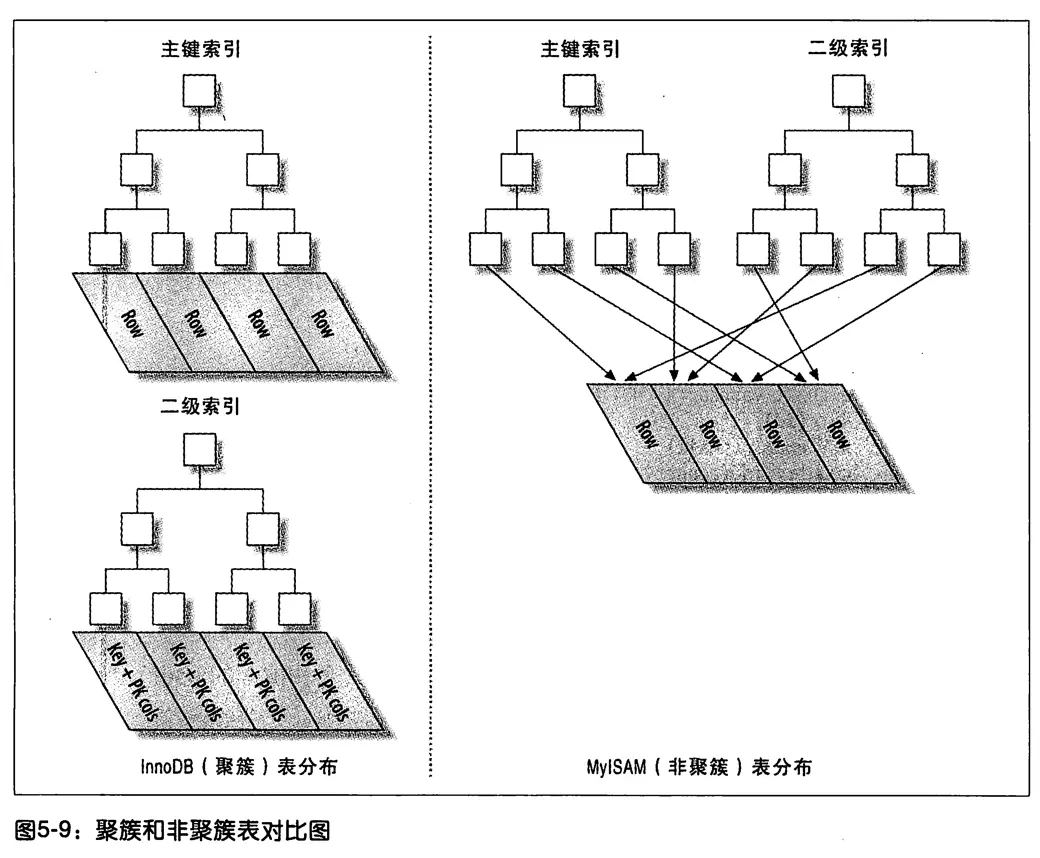
1-1.2 优势
-
二分查找加快访问速度
-
B-TREE可以提供额外的ORDER BY GROUP BY 辅助,也即是顺序IO
-
InnoDB利用索引可以避免全表扫描以减少行锁的加锁个数
1-1.3 失效场景
-
对要索引的列使用函数
-
使用
!=进行判断 -
使用 IS NULL判断
-
使用LIKE判断时将不确定部分也即%放在最左侧,形如
LIKE "%aa" -
ORDER BY时列的顺序不同于索引中列的顺序
1-1.4 常用命令
创建
CREATE INDEX indexName ON table_name (column_name);
添加
ALTER table tableName ADD INDEX indexName(columnName);
添加前缀索引(需要根据前缀的选择性来指定前缀的长度)
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
删除
DROP INDEX [indexName] ON mytable;
显示索引
SHOW INDEX FROM table_name; \G
修复/优化表
ALTER TABLE <table> ENGINE=<engine>;
1-2. 索引优化
1-2.1 查询流程
一条sql语句从客户端发出到服务端需要经历以下步骤才可以被执行
-
连接器
用于进行用户名、密码验证
-
分析器
对sql语句进行语法、语义上的验证
-
优化器
对sql语句按照mysql认为最优的策略生成执行方案
-
执行器
验证权限,按照执行方案调用存储引擎的接口执行sql查询
1-2.2 慢查询原因
1-2.2.1 冗余查询
1)多余行
进行范围查询时,是查询到所有的数据后再进行过滤,这样有可能导致查询了许多不必要的数据
可以使用LIMIT进行限制以返回更少的有用信息
2)多余列
尽量不使用select *,只查询必要的列
1-2.2.2 低效过滤
一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏依次如下
-
在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的
-
使用索引覆盖扫描(在Extra列中出现了Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL的server层完成的,但无须再回表查询记录,由于使用到了覆盖索引
-
由存储引擎层回表查询并返回数据给server层,然后在server层过滤不满足条件的记录(在Extra列中出现Using Where)
> MySQL的server层和存储引擎层是如何交互的 - 掘金 (juejin.cn)
1-2.2.3 优化器逆优化
mysql优化后的执行计划可能不是最优
1-2.3 慢查询优化
1-2.3.1 重构查询语句
如果一条sql可以被拆解为多条sql,且被拆分出的sql查询的结果可以被多次重用,那么可以用拆分后的多条sql来替代原来的一条查询任务繁重的sql
1-2.3.2 切分查询范围
如果要查询10000条记录,可以分为100组,每组查100条
1-2.4 分析查询
使用EXPLAIN关键字+sql语句即可对sql语句进行分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号