六种常见的系统架构
1、当前,常见的系统架构设计有以下几种:
- 单库单应用架构:这种架构在系统开发规范雏形初期,很多系统就有使用,相对是最简单的,小企业小系统就会用采用,尤其是做项目的公司;
- 内容分发架构:目前前端网页、图片、CSS、JS等这些静态资源用的相对较多;
- 读写分离架构:对于高并发的查询业务;
- 微服务架构:适用于把复杂的业务模式进行拆解;
- 多级缓存架构:利用缓存做出各种设计;
- 分库分表架构:解决单级数据库的瓶颈。
一、单库单应用架构
这种架构是最简单,我们在学习阶段,基本都会采取这种模式,除了专门针对各种架构的学习。
这种模式的设计图一般如下,
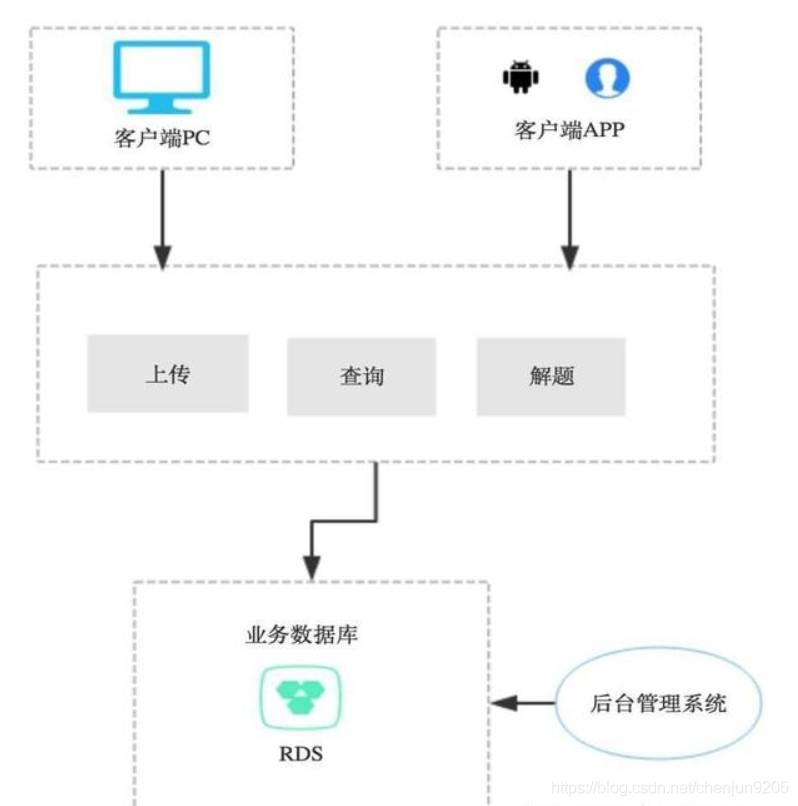
这种设计一般只有一个数据库,一个业务应用层,一个后台管理系统,所有的业务都是用业务层完成的,所有的数据也都是存储在一个数据库中,好一点会由数据库的同步,虽然比较简单,但是还是很实用的。
优点:结构简单、开发速度快、实现简单,用于产品的第一版等有原型验证需求。
缺点:性能较差、基本没有高可用、扩展性差,不适用于大规模部署、应用等生产环境。
二、内容分发架构
基本上所有的大型网站都或多或少地采用这种架构,常见的应用场景一般是采用CDN技术把网页、图片、css、js 等这些静态资源分发到离用户最近的服务器。
这种模式的设计一般如下。
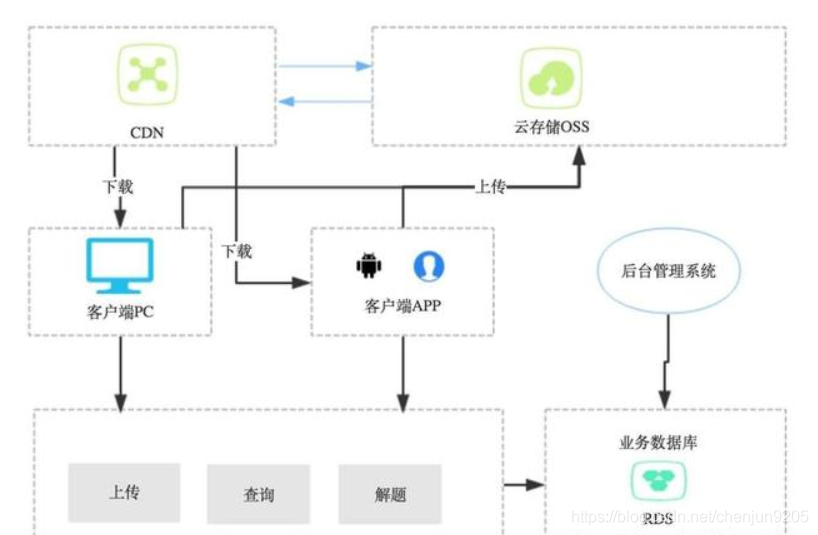
这种模式跟单库单应用的模式多了一个CDN、一个云存储OSS(如阿里云OSS)。
流程一般如下:
1、上传的时候,用户选择本地机器上的一个图片进行上传;
2、程序把这个图片上传到云存储OSS上,并返回该图片的一个URL;
3、程序把这个URL字符串存储在业务数据库中,上传完成;
4、查看的时候,程序从业务数据库得到该图片的URL;
5、程序通过DNS查询到这个URL的图片服务器;
6、智能DNS会解析这个URL,得到于用户最近的服务器(或集群)的地址A;
7、然后把服务器上的图片返回给程序;
8、程序显示该图片,查看完成。
由上可知,这个模式的关键是智能DNS,他能够解析出离用户最近的服务器,运行原理大致是:根据请求者的IP得到请求地点B,然后通过计算或者配置得到与B最近或通讯时间最短的服务器C,然后把C的IP地址返回给请求者。这种模式的优缺点如下:
优点:资源下载快,无需过多的开发与配置,同时也减轻了后端服务器对资源的存储压力,减少带宽的使用。
缺点:目前来说OSS、CDN的加个还是稍微优点贵的,只适用于中小规模的应用,另外由于网络传输延迟、CDN的同步策略等,会有一些一致性、更新慢方面的问题。
三、读写分离架构
这种模式主要解决单机数据库压力过大,从而导致业务缓慢甚至超时,查询影响时间变长的问题,也包括需要大量数据库服务器计算资源的查询请求,这个可以说是单库应用模式的升级版本,也是技术架构迭代演进过程中的必经之路。
设计图如下:
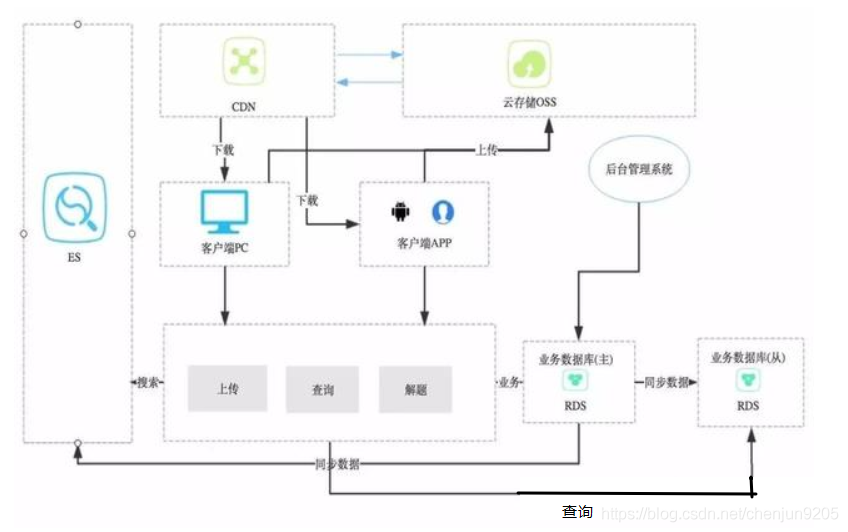
这种模式相比较单库应用模式来说,多了几个部分,一个是业务数据库的主从分离,一个是引入ES。
场景一:全文关键字检索
如果使用传统的数据库技术,大部分会使用like这种sql语句,高级一点的是先分词,然后通过分词index相关的记录。SQL语句的性能问题与全表扫描机制导致了非常严重的性能问题,现在基本上很少见到。
ES较Solr配置简单、使用方便,所以选用他。另外,ES支持横向扩展,理论上没有这个性能的瓶颈。同时,还支持各种插件、自定义分词器等,可扩展性较强。而且ES还能实现分页、排序、分组、页面等功能。
一般的流程如下:
- 服务端把一条业务数据落库;
- 服务器异步把该条数据发送到ES;
- ES把该条记录按照规则、配置放入自己的索引库;
- 客户端查询的时候,由服务端把这个请求发送到ES,得到数据后,根据需求拼接、组合数据,返回给客户端。
场景二:大量的普通查询
我们的业务中的大部分辅助性的查询,如:取钱的时候,先查询余额,根据用户的ID查询用户的记录,取得该用户最新的一条取钱记录,我们肯定是要天天用到的,而且用的还非常多。与此同时,我们的写入请求也是非常多,导致大量 的写入、查询操作到同一数据库,然后,数据库挂了,系统挂了,这就很难受了。因此,要求我们必须分散数据库的压力,一个在业界较成熟的方案就是数据库的读写分离,写的时候入主库,读的时候读分库。这样就把压力分散到不同 的数据库了,如果一个读库性能不行,扛不住的话,可以一主多从,横向扩展。
一般的流程如下:
- 服务端把一条业务数据落库;
- 服务器同步或异步半同步把该条数据复制到从库;
- 服务端读取数据的时候直接去从库读相应的数据。
优点:减少数据库的压力,理论上提供无限高的读性能,简介提高业务(写)的性能,专用的查询、索引、全文(分词)解决方案。
缺点:数据延迟,数据一致性的保证。
四、微服务架构
传统的软件开发到一定阶段,经常会遇到以下问题:
- 单级数据库请求量大量增加,导致数据库压力变大;
- 数据库一旦挂了,那么整个业务就都挂了;
- 业务代码越来越多,都在一个git里,越来越难以维护;
- 代码腐化严重,臭味越来越浓;
- 上线越来越频繁,经常是一个小功能的修改,就要整个大项目重新编译;
- 部门越来越多,该哪个部门改动大项目中的哪个东西,容易发生分歧;
- 其他一些外围系统直接连数据库。导致一旦数据库结构发生变化,所有相关系统都要通知,甚至对修改不敏感的系统也要通知;
- 每个应用服务器需要开通所有权限、网络、FTP、各种各样的,因为每个服务器部署的应用都是一样的;
- 作为架构师,无法把控这个系统了。
微服务模式的设计一般如下:
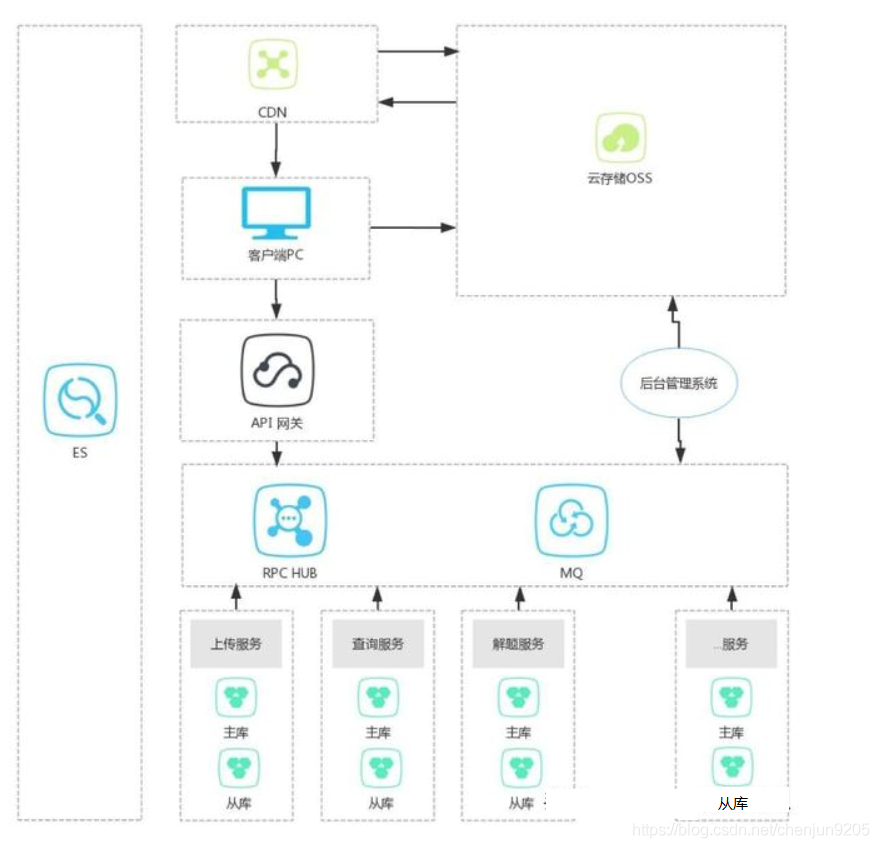
如图所示,把业务分块,做了垂直切分,切成了一个个独立的系统,每个系统各自衍化,有自己的库、缓存、ES等腐竹系统,系统之间的实时交互通过RPC,异步交互通过MQ,通过这种组合,共同完成整个系统功能。
对于问题一:由于拆分成多个子系统,系统的压力被分散了,而各个子系统都有自己的数据库实例,所有数据库的压力变小;
对于问题二:一个子系统A的数据库挂了,只是影响到系统A和使用系统A的那些功能,不会所有功能不可用,从而解决一个数据库挂了,导致所有的功能都不可用的情况;
对于问题三、四:也因为拆分得到了解决,各个子系统都有自己独立的git代码库,不会相互影响。通用的模块可通过库、服务、平台的形式解决;
对于问题五:子系统A发生改变,需要上线,那么我们只需要编译A,然后上线就可以了,不需要其他系统做同样的的事情;
对于问题六:顺应了康威定律,我部门该干什么,输出什么,也通过服务的形式暴露出来,我部门只管把我部的职责、软件功能做好就可以了;
对于问题七:所有需要我部数据的需求,都通过接口的形式发布出去,客户通过接口获取数据,从而屏蔽了底层数据库结构,甚至数据来源,我部只需保证我部的接口契约没有发生变化,新的需求增加新的接口,不会影响老的接口;
对于问题八:不同的子系统需要不同的权限,这个问题也优雅的解决了;
对于问题九:暂时控制住复杂性,我只需要控制好大方面,定义好系统边界、接口、大的流程,然后再分而治之、逐个击破、合纵连横。
在此,所有问题得到解决!
但是,副作用也随之而来,如RPC、MQ的超高稳定性、超高性能,网络延迟,数据一致性等问题,这个就不展开来讲了。
所以说,在这个模式来说,最难把握的是度,切记不要切分过细,我见过一个功能一个子系统,上百个方法分成上百个子系统的,真的是太过度了。实践中,一个比较可行的方法是:能不分就不分。
优点:相对高性能,可扩展性强,高可用,适用于中等以上规模公司架构。
缺点:复杂、度不好把握。指不仅需要一个能再高层把控大方向、大流程、总体技术的人,还需要能够针对各个子系统有针对性的开发。把握不好度或者滥用的话,这个模式适得其反!
五、多级缓存架构
这种模式是应对超高查询压力的普遍采用的一种策略,基本的思想就是在所有链路的地方,能加缓存就加缓存,设计如下:
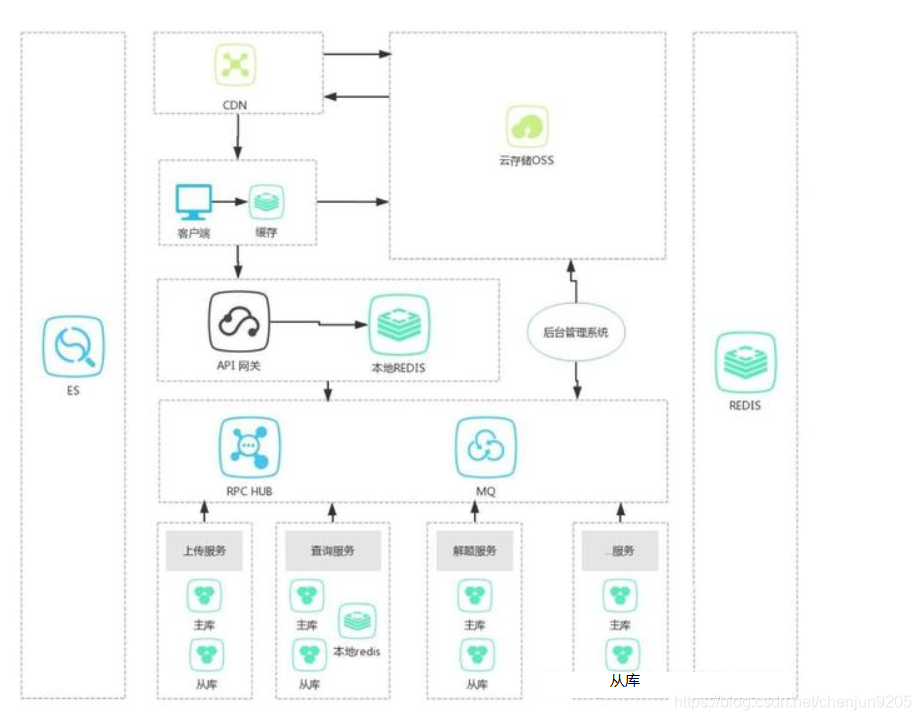
如图所示,一般在三个地方加入缓存,一个是客户端处,一个是API网关处,一个是具体的后端业务处。
客户端处缓存:这个地方加缓存可以说是效果最好的一个,不会延迟。因为不用经过很长的网络链条去后端业务处获取数据,从而导致加载时间过长,客户流失等损失,虽然有CDN的支持,但是从客户端到CDN还是有网络延迟的,虽然不大,具体的技术依据不同的客户端而定,对于WEB来讲,有浏览器本地的缓存、Cookie、Storage、缓存策略等技术;对于APP来讲,有本地数据库,本地文件,本地内存,进程内缓存支持,以上提到的各种技术有兴趣的同学可以继续开展学习,如果客户端缓存没有命中,那么会去后端业务拿数据,一般来讲,就会有个API网关,在这里加缓存也是非常重要的。
后端业务处理:Redis、Jvm等等。
实践中,要结合具体的实际情况,综合利用各级缓存技术,使得各种请求最大程度的在到达后端业务之前就被解决掉,从而减少后端服务器压力、减少占用带宽、增强用户体验。
优点:抗住大量读请求,减少后端压力。
缺点:数据一致性问题较为突出,容易发生雪崩,即:如果客户端缓存失效、API网关缓存失效,那么所有的大量请求瞬间压向后端业务系统,后果可想而知。
六、分库分表架构
这种模式主要解决单表写入、读取 、存储压力过大,从而导致业务缓慢甚至超时,交易失败,容量不够的问题。一般有水平切分和垂直切分两种,这里主要介绍水平切分。这个模式也是技术架构迭代演进的必经之路。
设计如图
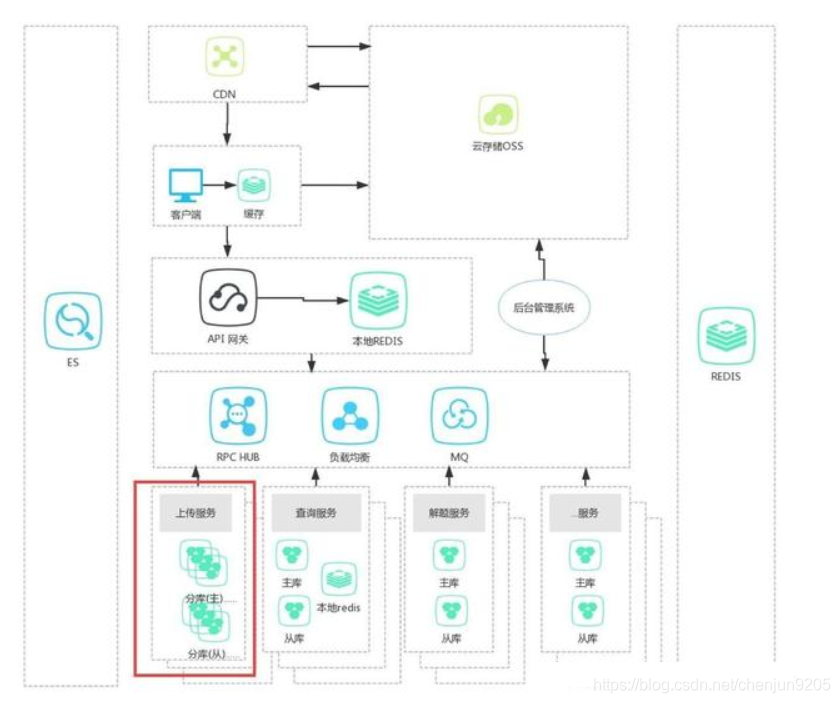
如上图,把一张表分到了几个不同的库中,从而分担压力。是不是很笼统?哈哈,那我们接下来就详细的讲解一下,首先澄清几个概念,如下:
主机:硬件,指一台物理机,或虚拟机,有自己的CPU,内存,硬盘等。
实例:数据库实例,如一个MySql服务进程,一个主机可以有多个实例,不同的实例有不同的进程,监听不同的端口。
库:指表的集合,如学校库,可能包含教师表、学生表、食堂表等等,这些表在一个库中。一个实例中可以有多个库,库与库之间用库名来区分。
表:库中的表,不必多说,不懂的就不用往下看了,不解释。
那么怎么把单表分散呢?到底怎么个分发呢?分发到哪里呢?以下是几个工作中的实践,分享一下:
主机:这是最主要的也是最重要的点,本质上分库分表是因为计算与存储资源不够导致的,而这种资源主要由物理机,主机提供的,毕竟没有可用的计算资源,怎么分效果都不是太好。
本文来自博客园,作者:it-小林,转载请注明原文链接:https://www.cnblogs.com/linruitao/p/15214577.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号