
机器学习框架的基本组成
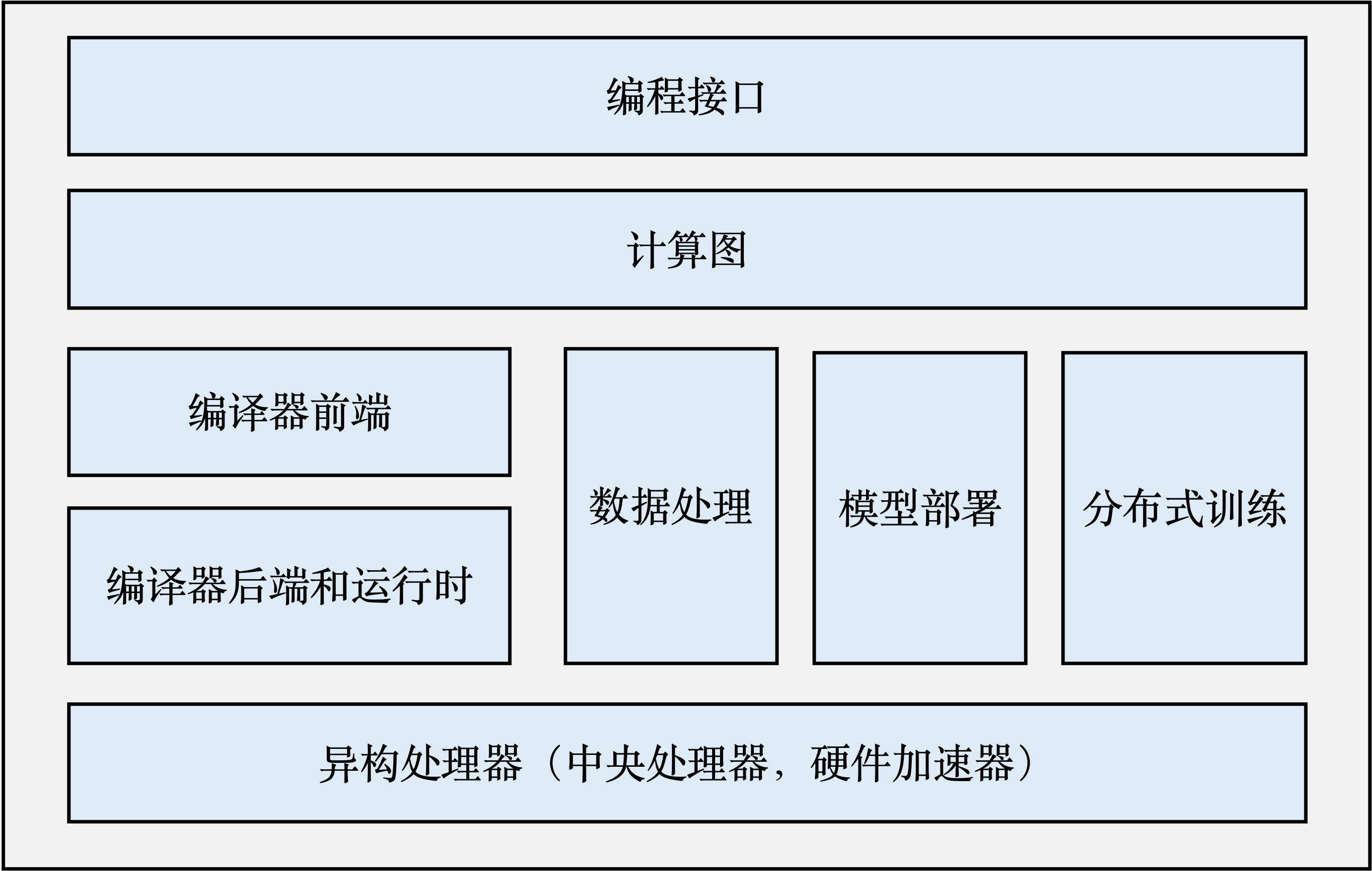
- 编程接口:一般用 Python 作为给用户的接口,主要原因就是简单易用、生态好;
- 计算图:计算图定义了用户的机器学习程序,比如有哪些 op、有哪些输入、输入长什么样、计算序列如何等,对于不同的编译器后端,有时候需要用 IR 来做优化,在 mlsys 中计算图就相当于是 IR;
- 编译器前端:前端的工作主要包括对程序的分析和优化。比如实现中间表示(IR)、自动微分、类型推导、静态分析等,在 mge 中 dispatcher 会对 tensor 做一些 transformation 应该就属于前端;
- 编译器后端和运行时:完成计算图的分析和优化后,机器学习框架进一步利用编译器后端和运行时实现针对不同底层硬件的优化。常见的优化技术包括分析硬件的L2/L3缓存大小和指令流水线长度,优化算子的选择或者调度顺序;
- 异构处理器:不同平台有不同的算子实现,甚至不同尺寸的算子也会有多个实现,这样可以充分利用异构处理器的性能。矩阵计算等操作的优化由硬件加速器完成;
- 数据处理:pytorch 和 megengine 有 dataloader,用来拉取 dataset,还有做一些处理:拼 batch、做 transform,也就是一些数据清洗、数据增强的工作;
- 模型部署:模型需要部署到硬件上才能 work,还有一些针对推理平台的模型算子优化;
- 分布式训练:用分布式计算节点来加速模型训练或者训练更大的模型。常见的有:
- 数据并行:不同节点处理不同的数据然后再 reduce;
- 模型并行:不同节点处理相同数据但是更新模型的不同参数部分;
- 混合并行:上面两个一起来。
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号