会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
machine_gun_lin
博客园
首页
新随笔
联系
管理
订阅
2023年8月13日
机器学习编译(三):张量程序案例 TensorIR
摘要: **使用张量程序抽象的目的是为了表示循环和相关的硬件加速选择,如多线程、特殊硬件指令的使用和内存访问。** # 1. 一个例子 使用张量程序抽象,我们可以在较高层的抽象制定一些与特定硬件无关的较通用的 IR 优化(计算优化)。 比如, 对于两个大小为 128×128 的矩阵 A 和 B,我们进行如下
阅读全文
posted @ 2023-08-13 12:16 machine_gun_lin
阅读(259)
评论(0)
推荐(0)
2023年8月7日
深度学习框架 —— 分布式训练
摘要: 现在深度学习的模型结构越来越大,参数动不动都是上亿甚至上千亿,这也对训练模型的资源量有很高的要求,显然单个机器上要训练这么大的网络是不现实的,因此学术界和工业界自然开始研究用分布式训练。也就是将一个机器学习模型任务拆分成多个子任务,并将子任务分发给多个计算节点,解决资源瓶颈。 # 1. 分布式训练概
阅读全文
posted @ 2023-08-07 11:48 machine_gun_lin
阅读(2684)
评论(0)
推荐(1)
2023年8月6日
深度学习编译器后端和运行时
摘要: 编译器前端将用户代码解析得到计算图 IR,并且做了一些和计算设备无关的通用优化。编译器后端做的优化就和具体的设备有关了(不同设备有不同的 allocator,不同的编程模型,比如英伟达的 CUDA),后端优化更加贴合硬件,会针对硬件特点为 IR 中的计算节点选择在硬件上的算子,然后为每个算子的输入输
阅读全文
posted @ 2023-08-06 19:02 machine_gun_lin
阅读(779)
评论(0)
推荐(0)
深度学习编译器前端技术概述
摘要: AI 编译器在前端经常会做一些静态分析,方便在前端做一些优化:自动微分等。  ## 中间表示(Intermediat
阅读全文
posted @ 2023-08-06 13:44 machine_gun_lin
阅读(718)
评论(0)
推荐(0)
2023年8月5日
计算图的生成
摘要: 主流机器学习框架都支持动态图和静态图。 动态图是即时编译的,也就是有一个 op 和输入之后立即发 kernel 执行计算得到结果并返回。 静态图是获取到整个程序结构之后构建了计算序列之后再进行计算的,比如有 op1、op2…. opn,还有输入 input1、input2…inputm,然后执行整个
阅读全文
posted @ 2023-08-05 23:21 machine_gun_lin
阅读(401)
评论(0)
推荐(0)
计算图
摘要: 机器学习程序从前端到后端需要编译成不同的 IR 来获得更好的优化性能,在 mlsys 中这个 IR 就是计算图。 对机器学习程序描述的调度执行、自动更新模型所需的梯度都需要依赖计算图。 一个计算图的逻辑结构大概是下图右边的前向部分: 
评论(0)
推荐(0)
机器学习工作流
摘要:  机器学习框架通常提供高层语言(比如 Python)作为给用户使用的接口,在 Python 层用户可以做的事有: -
阅读全文
posted @ 2023-08-05 23:15 machine_gun_lin
阅读(161)
评论(0)
推荐(0)
机器学习框架的基本组成
摘要: 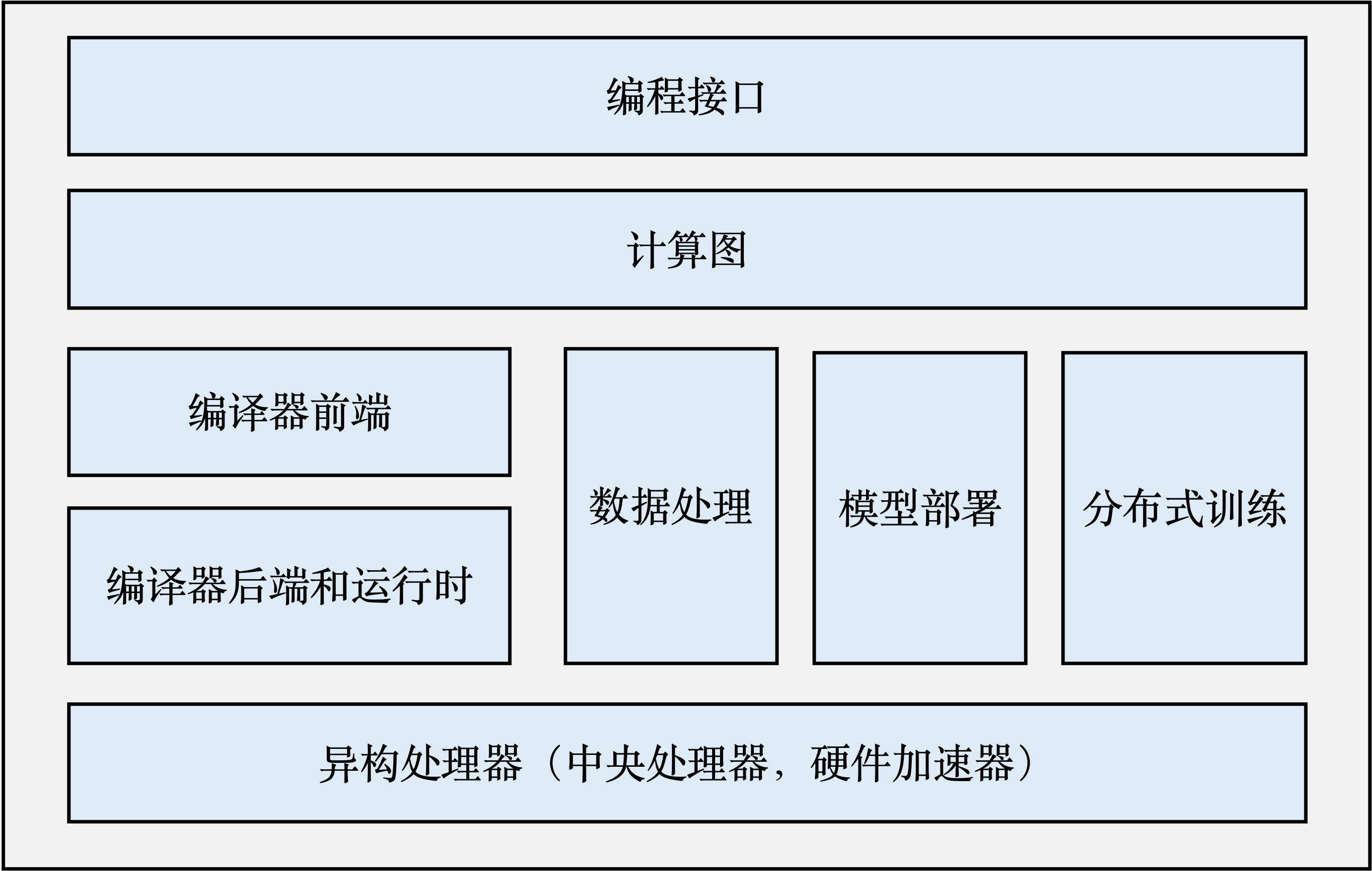 - 编程接口:一般用 Python 作为给用户的接口,主要原因就是简单易用、生态好; - 计算图:计算图定义了用户
阅读全文
posted @ 2023-08-05 23:12 machine_gun_lin
阅读(288)
评论(0)
推荐(0)
2023年8月4日
机器学习框架的目标
摘要: 1. 神经网路编程 神经网络需要一个共同的系统进行开发、训练和部署。 2. 自动微分 训练神经网络的过程本质上是模型参数的迭代,这些参数需要持续计算梯度(Gradients)迭代改经。梯度的计算往往需要结合训练数据、数据标注和损失函数(Loss Function)。手工计算梯度很麻烦,机器学习框架需
阅读全文
posted @ 2023-08-04 13:44 machine_gun_lin
阅读(95)
评论(0)
推荐(0)
2023年7月26日
升级 python 导致的坑
摘要: 编译 tvm 或者其他项目发现 cmake 版本 3.16 太低了(应该是 MegBrain 默认的版本),cmake 换到高版本发现 python 3.6 版本太低了(Ubuntu 18.04 的默认版本)导致没法 configure,升级到 python 3.8 之后又有一些坑,记录一下。 设置
阅读全文
posted @ 2023-07-26 14:07 machine_gun_lin
阅读(234)
评论(0)
推荐(0)
下一页
公告


 浙公网安备 33010602011771号
浙公网安备 33010602011771号