00.大型数据库技术课堂测试
1、完成科技查新基本信息填报功能,基本信息如下所示:
可参考https://chaxin.las.ac.cn/novelty/embed/kjcx.htm页面样式。
|
项目名称 |
平台编号 |
|
查新范围 |
□国内 □国外 |
|
查新目的 |
О立即查新 О成果查新 О其他查新 (单选框,选中某个选项,显示相应的多选框) 立即查新 □1.项目申报(国家级、省部级、学协会、其他) □2.中小企业创新基金(研发阶段、小试-中试、市场推广) □3.新产品 □4.技术引进 □5.技术吸收与创新 □6.其他 成果查新 □7.成果鉴定 □8.高新技术成果转化 □9.申报奖励(国家级、省部级、学协会、其他奖励) □10.高新技术企业认定 □11.其他 其他查新 □12.博士论文开题 □13.申报专利 □14.其他 |
|
查新项目的科学技术要点 |
充分反映出查新项目的概貌,简述项目的背景、技术问题、解决技术问题所采用的方案、主要技术特征、技术参数或指标、应用范围等相关技术内容。(要求限制500字) |
|
查新点个数 |
(必填) |
|
查新点1 |
|
|
查新点N(根据个数显示) |
|
|
参考检索词 |
(主题词、关键词、规范词、同义词、缩写、全称、化学名称、分子式、专利分类号等,国内外查新要分中英文列出。)如果有多个检索词要求点击按钮添加多个检索词文本框。 |
|
完成时间 |
说明:国内查新7个工作日(1个查新点),每增加1个查新点,查新费用增加300元,工作时间增加1个工作日;国内外查新10个工作日(1个查新点),每增加1个查新点,查新费用增加600元,工作时间增加3个工作日。(国内查新加急不得少于3个工作日,国内外查新加急不得少于5个工作日)。 加急费情况介绍: 收费:200元/工作日 时间:国内查新第一个查新点不得少于3个工作日,每增加一个点多一个工作日; 国内外查新第一个查新点不得少于5个工作日,每增加一个点多一个工作日;
正常:О7个工作日 加急:О |
|
学科分类 |
用文本下拉框显示,具体内容参考表后图1. |
|
产业分类 |
用文本下拉框显示,具体内容参考表后图2. |
|
备注 |
|
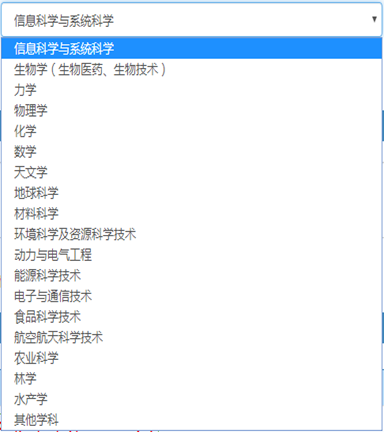
图1学科分类示意图

图2产业分类示意图
2、后台数据库要求使用HBASE数据库,并将新数据存入HBase新建表中。
3、实现从数据库中将新数据读出展示在前台页面。
二、评分等级:
A级:完成上述全部功能,并实现超额实现数据的删、修改、简单查询等功能。
B级:实现信息填报功能,未按要求实现全部功能。
C级:实现部分功能,可实现数据库连接,并在数据库中建立相应的表。
D级:安装成功Hbase,无法实现编程,可以实现手动建表。
package test.java; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class HdfsDemo { public static void main(String[] args) throws IOException { insert(); update(); read(); delete(); } //删除文件 private static void delete() throws IOException { //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) Configuration conf = new Configuration(); //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 FileSystem fs = FileSystem.get(conf); //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 Path path = new Path("/yinzhengjie.sql"); //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 boolean res = fs.delete(path, true); if (res == true){ System.out.println("===================="); System.out.println(path + "文件删除成功!"); System.out.println("===================="); } //释放资源 fs.close(); } //将数据追加到文件内容中 private static void update() throws IOException { //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) Configuration conf = new Configuration(); //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 FileSystem fs = FileSystem.get(conf); //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 Path path = new Path("/yinzhengjie.sql"); //通过fs的append方法实现对文件的追加操作 FSDataOutputStream fos = fs.append(path); //通过fos写入数据 fos.write("\nyinzhengjie".getBytes()); //释放资源 fos.close(); fs.close(); } //将数据写入HDFS文件系统 private static void insert() throws IOException { //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) Configuration conf = new Configuration(); //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 FileSystem fs = FileSystem.get(conf); //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 Path path = new Path("/yinzhengjie.sql"); //通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖! FSDataOutputStream fos = fs.create(path,true); //通过fos写入数据 fos.writeUTF("尹正杰"); //释放资源 fos.close(); fs.close(); } //在HDFS文件系统中读取数据 private static void read() throws IOException { //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) Configuration conf = new Configuration(); //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 FileSystem fs = FileSystem.get(conf); //这个path是指NameNode中的HDFS分布式系统中的路径映射(注意,我这里写的是主机名,你可以写IP,如果是测试环境的话需要在hosts文件中添加主机名映射哟!) Path path = new Path("hdfs://s101:8020/yinzhengjie.sql"); //通过fs读取数据 FSDataInputStream fis = fs.open(path); int len = 0; byte[] buf = new byte[4096]; while ((len = fis.read(buf)) != -1){ System.out.println(new String(buf, 0, len)); } } } /* 以上代码执行结果如下: 尹正杰 yinzhengjie ==================== /yinzhengjie.sql文件删除成功! ==================== */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号