Jvm故障问题排查以及Jvm调优总结
Jvm故障问题排查以及Jvm调优总结
为了学习jvm故障问题的排查,写了一个例子来验证,在我之前服务器上部署的一个音乐网站的项目里加了一段代码。
轻语音乐网站项目地址:https://github.com/Linliquan/springboot-music
如下:
在一个音乐搜索方法getSongRearch中加了一个for循环,循环一亿次创建HashMap对象。
项目启动部署后,在页面上模糊搜索歌曲“你”,发现搜索缓慢。
大约十几秒后才搜索出来
打印的日志:

排查过程:
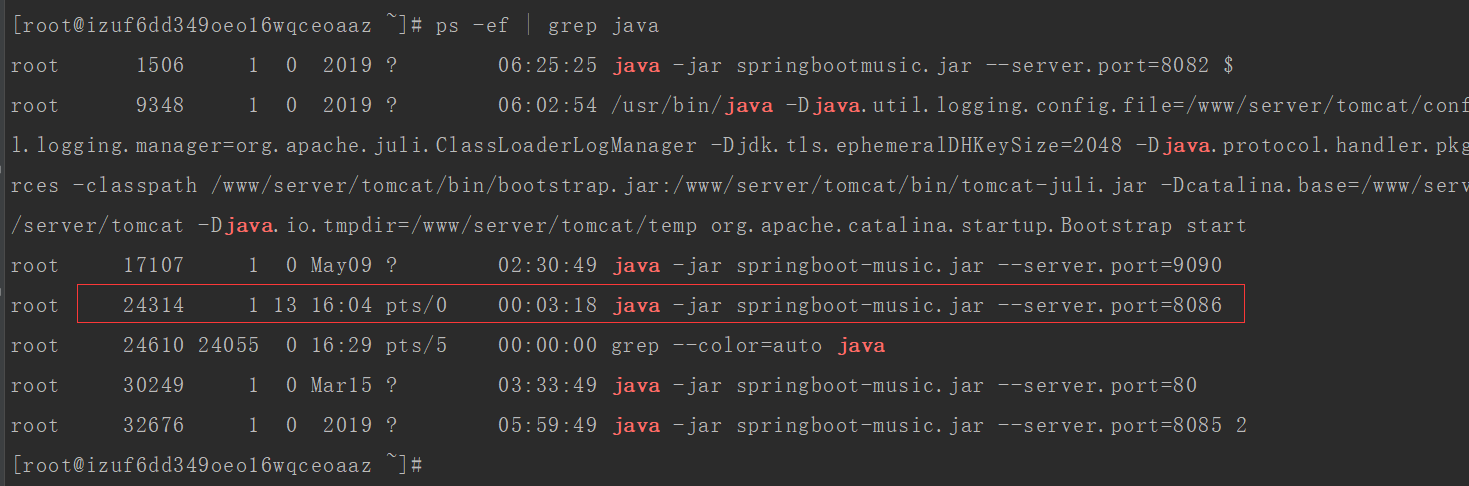
1. 使用 ps -ef | grep java 命令找到相应的进程pid,pid = 24314
2. 使用 top 命令,查看cup占用情况。如图,id为24314的进程,cpu占用率为99%
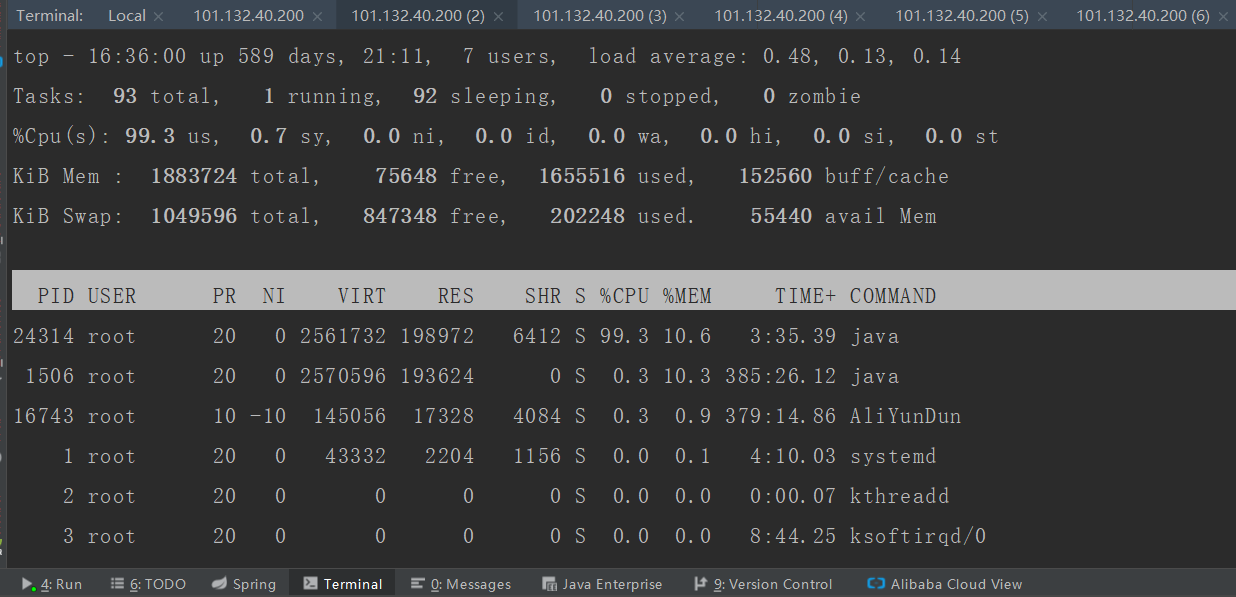
3. 使用 top -Hp pid 命令,查看 pid=24314 进程下的各个线程cpu占用情况。
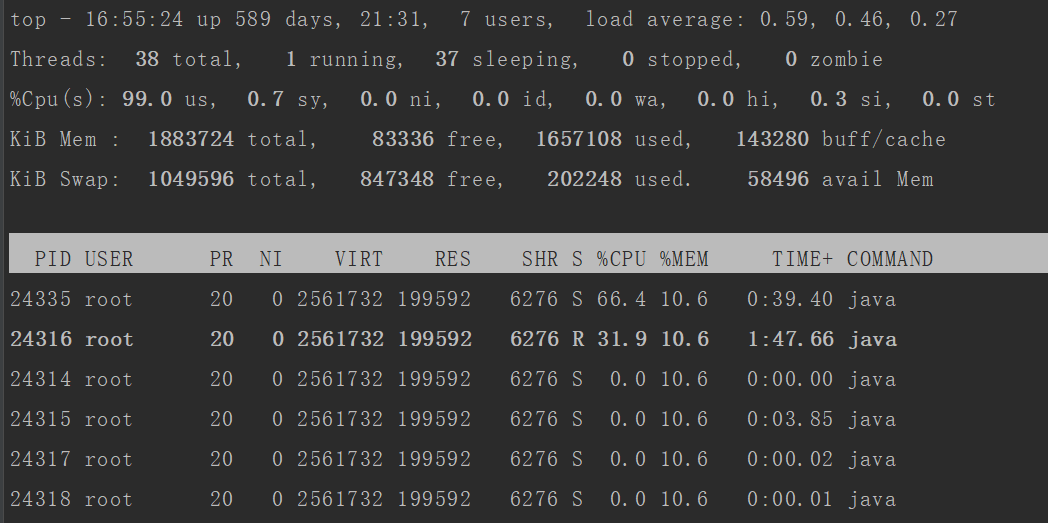
4. 使用 printf "%x" tid 命令,将占用cpu比较高的线程的 tid = 24335 转化为十六进制,34335的十六进制为 5f0f

5. 使用 jstack pid| grep 十六进制 -A20 命令,如 jstack 24314 | grep 5f0f -A20 打印20行线程的堆栈信息。
grep -A是显示匹配后和它后面的n行,-B是显示匹配行和它前面的n行,-C是匹配行和它前后各n行。
如图可以看到,MusicLinkController 的 getSongRearch 方法的第180行代码有问题,并且线程的状态为RUNNABLE。
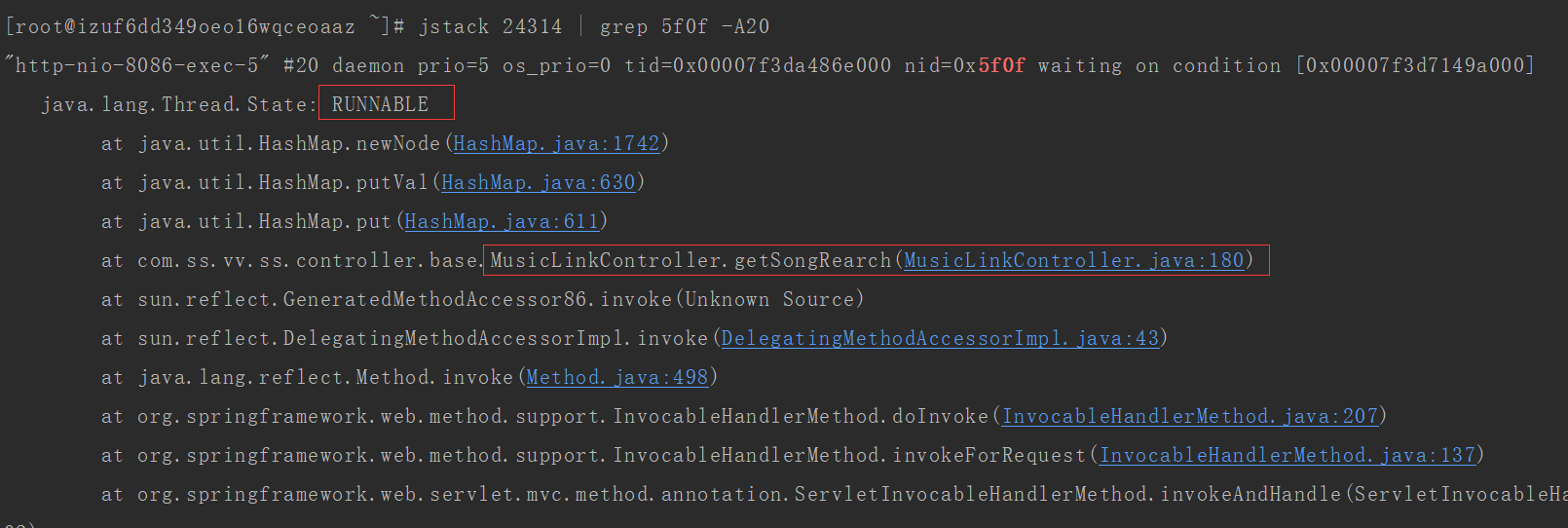
这样就可以找出相应有问题的代码
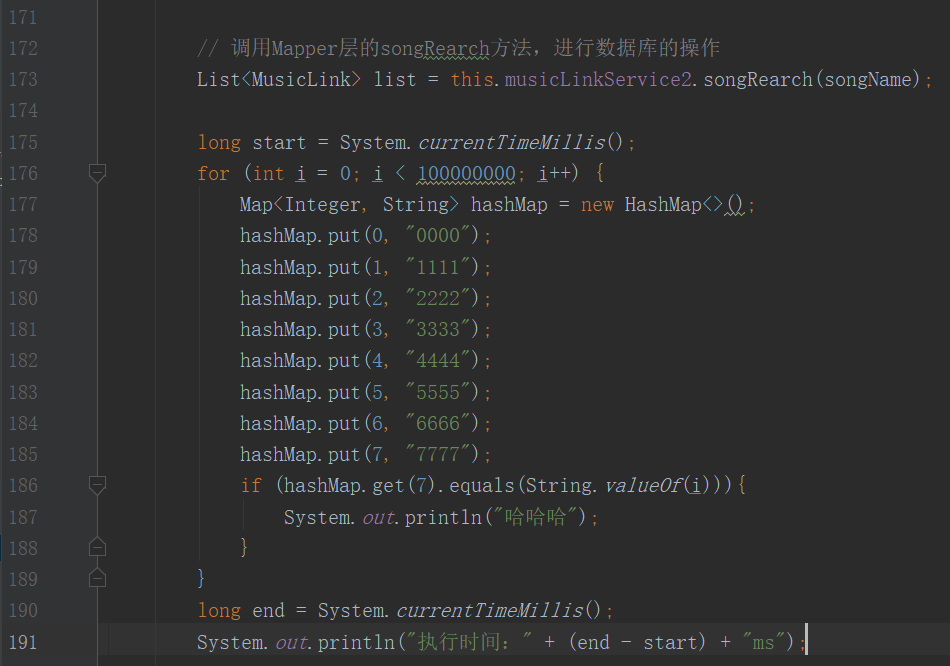
进一步排查:
1.使用 jmap -histo pid | head 命令,查看堆内存情况
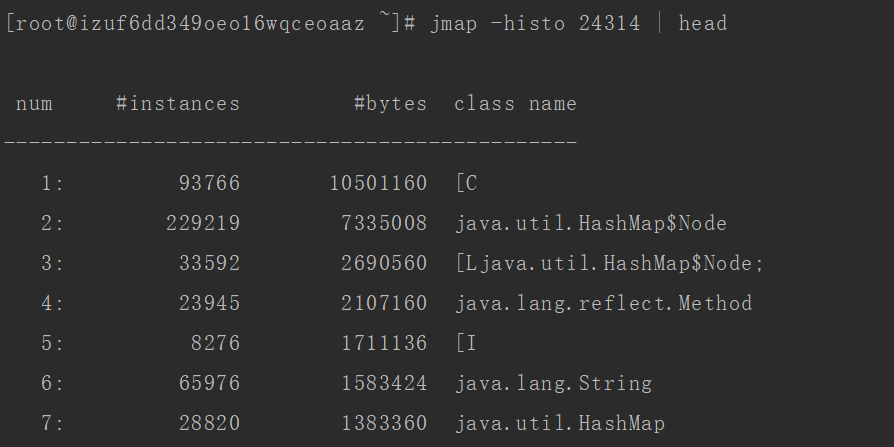
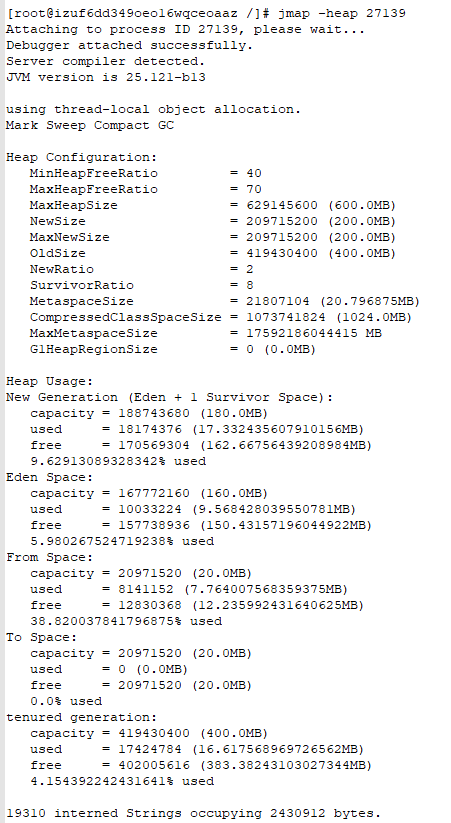
2.使用 jmap -heap pid,查看堆内存情况

3.使用 jstat -gc pid 命令,查看各个区内存使用情况

4.使用 jstat -gcutil 24314命令,查看各区容量使用率,如图老年代使用率为96.6%。

5.使用jstat -gc 24314 100 10,每隔100ms打印一次,打印5次

S0C:第一个幸存区的大小 S1C:第二个幸存区的大小 S0U:第一个幸存区的使用大小 S1U:第二个幸存区的使用大小 EC:伊甸园区的大小 EU:伊甸园区的使用大小 OC:老年代大小 OU:老年代使用大小 MC:方法区大小 MU:方法区使用大小 CCSC:压缩类空间大小 CCSU:压缩类空间使用大小 YGC:年轻代垃圾回收次数 YGCT:年轻代垃圾回收消耗时间 FGC:老年代垃圾回收次数 FGCT:老年代垃圾回收消耗时间 GCT:垃圾回收消耗总时间
年轻带分三个区:1个E,2个S区。
1.所有对象在E区分配内存,E区和2个S区初始化为空
2.E区满后,对象无法分配内存,触发GC
3.第一次GC,就是把E区活对象移到S0区
4.第二次GC,E区和S0区的活对象合并,往S1区转移
5.第三次GC,E区和S1区的活对象合并,往S0区转移,此后重复步骤:4,5
6.如果活对象存活时间达到一定长度或者根据动态年龄判定法,则转移到年老代。
由下图中也可以看得出来


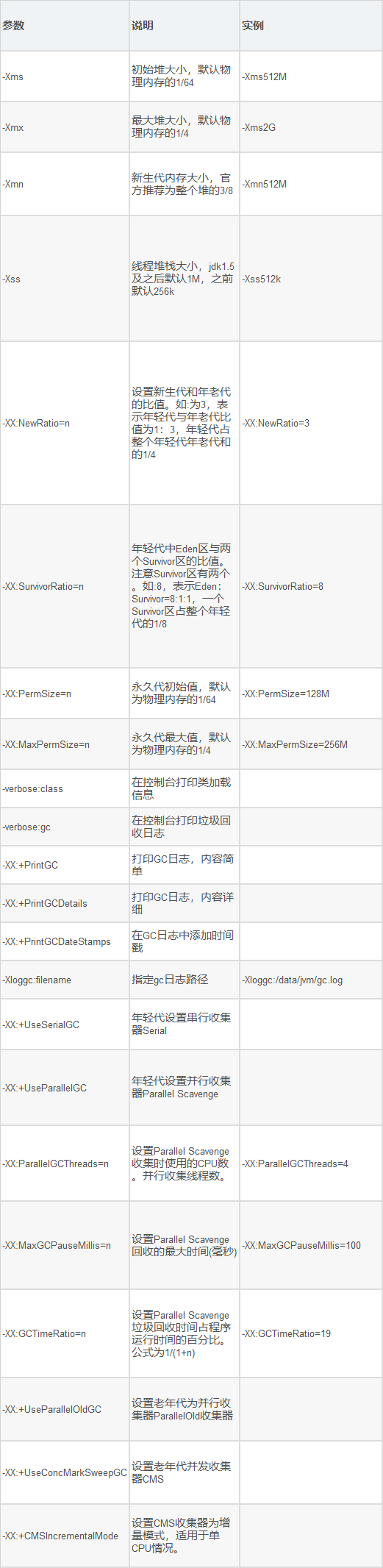
6.设置jvm参数
-Xms :初始堆大小,-Xmn:最大堆大小

7. 使用jmap -heap pid命令,可见新生代为200M,老年代为400M,且为1:2。
jvm参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号