
mysql 去除重复 Select中DISTINCT关键字的用法(查询两列,只去掉重复的一列)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。当查询两列时,使用distinct时,查询的两列必须都重复才行,如果我想只要第一列重复就去掉这行该怎么做呢?
问题如下:
select distinct test_name,info from test order by test_name desc,info limit 7;
这条查询语句的大概意思是:查询test_name和info列,test_name按降序排列,info按升序排列,并且显示前7行

明显distinct没起作用,因为它要两列都重复才行,而我想把346重复的行去掉。
这是我的表数据
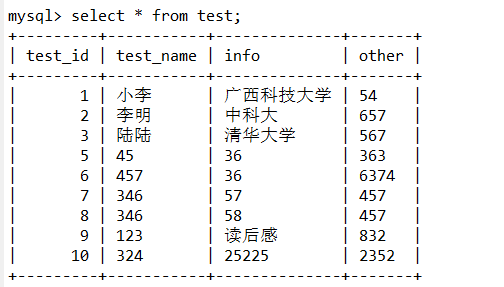
查mysql手册,发现可以用 count 和 group by 组合来实现
改进后的查询语句:select test_name,info,count(distinct test_name) from test group by test_name order by test_name desc,info limit 7;

ok了,不过多了一列count(distinct test_name),可以不管它
后面经过进一步的学习,发现更简洁的写法:select test_name,info from test group by test_name;

有一些数据我改了,但不影响这个功能的实现。
注意:group by 要放where之后,order by 、limit 之前
参考文章:https://blog.csdn.net/guocuifang655/article/details/3993612

