
系统性能优化二三事
工作中当一个业务系统被开发出来之后,经过多次迭代业务的发展处理逻辑会越来越复杂,同时访问量以及处理的数据也会相应的增多,系统的响应时间就会开始得逐渐加长。终于有一天用户忍受不了抱怨你的app或者页面要等好几十秒或者好几分钟才响应时你就迫切需要对你的系统进行一个性能的优化。
下面谈一下我对性能优化方面的一些观点和见解,包括分析系统为什么会慢,以及针对这些慢的情形如何选取更合理的解决方案。
系统为什么慢?
说起系统慢的原因能举的例子太多了,比如某人写的代码写得太烂了,这个sql查询写得太差了,循环调服务啊等等。那抛开个人编码的能力问题有没有一些是与系统本身的设计相关的呢。比如系统原先是一个单体应用,后面做了业务的垂直拆分拆出了N个子系统并且做了一个分布式的部署变成了一个分布式系统,那么系统的响应时间会不会因此变长呢。答案几乎是肯定的!为什么呢
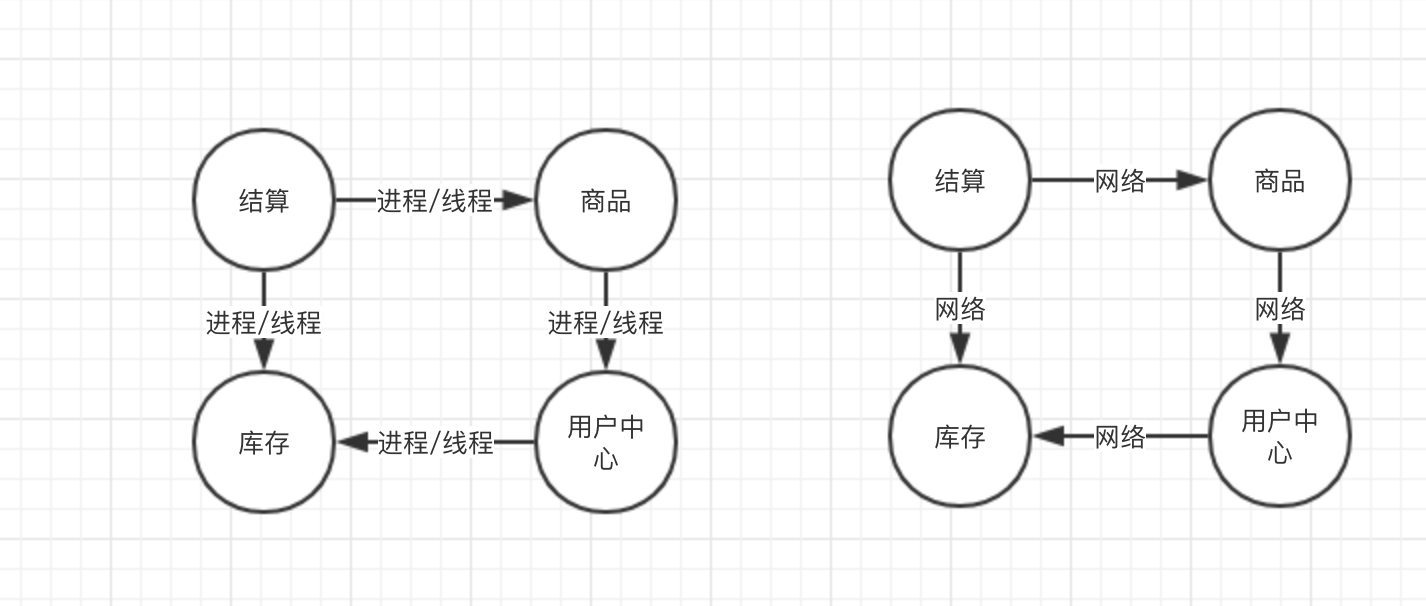
举一个电商系统的例子,左边是系统初期的样子,基本上所有业务模块都放在了一起,右边是后面做了业务的垂直拆分之后的样子。我们看到这些业务模块间的调用是由进程/线程变成了一个远程的RPC网络调用,这里就多出了网络响应时间(RT)的延迟 ,试想一个电商的成单过程要调商品、结算、库存、用户、积分等N个系统。假设每个RT时间都是2ms那么成单就有2Nms的时间是在等待数据传输。这里面还并没有算上这些N子系统的本身的处理时间并且它们很可能也会调用其它外部的子系统。所以你知道像阿里这样的公司在双11的之前为什么做全链路的优化了吧,其中一个原因是因为当一个单体应用被拆成一个分布式系统后调用链路变长了,并且每个链路至少多了一个RT的响应延迟。所以我们知道有时候系统变慢并不是某个开发的锅,而是因为系统架构导致的。对于这种情形我们就可以优化RT延迟,解决办法可以是申请专线或者把应用部署在同一个物理机房里面,反正原理就是不能让我们的数据走太长的路~。
从上面这个例子我们知道在做系统优化之前分析是第一步也是最重要的一步。说到分析有些问题可以在我们脑中进行思维逻辑推导分析就可以定位到问题的。但现实中绝大部分问题都是不行的!都是要用数据说话的!所以监控是很重要的,没有全链路的跟踪,只是靠猜做优化只会事倍功半!全链路的跟踪工具这里推荐一下大众点评cat https://github.com/dianping/cat 和 zipkin https://zipkin.io/
下面列几个常见的问题分析是如何做优化选型的和一些系统中你可能没有注意到有性能问题的地方。
大量读多少量写是主从还是缓存?
说到这个问题我相信很多人的第一反应的都是说主从,确实在我的工作经历中绝大部分人在这个问题第一反应也是主从,其中不乏包括一些在大厂待过并且工作经验是我一倍多的老前辈。我自己觉得主从还是缓存得看"量"有多大。这个"量"不是指有多少用户在访问,而是用户访问的这个数据到底有大。如果用户访问的这个数据很小,小到用缓存就可以放得下,我觉得这时用缓存是更好的方案。为什么?因为主从之间的数据同步延迟是一个很头疼的问题!特别是一主多从的情况下。。。。并且弄从库的成本会很高为了解决主从不同步的问题还需要调研一个数据中间件,并且性能还没有缓存高,落地成本大,时间长!只有在用户访问的数据量太大,大到不能用缓存放得下我觉得这时候才考虑用从库,并且要充分考虑数据不同步的影响!之前我看过58架构师沈剑的文章,他也提到58是用缓存来解决读多写少问题,读缓存,写主写时更新缓存,从库只作为数据备份作为容灾。然而工作中我也确实遇到过一个库的数据只有几千条但弄出了一个从库的经历,汗。。。。
依赖非常多的外部RPC服务时
我曾经遇到服务器端返回一个页面展示的数据要调用两位数的外部RPC服务,并且这个页面是用户经常访问到的而且页面数据还真不能做缓存,数据必须得实时刷。这个页面每次一有大促的时候必须得加机器并且加了还是有点扛不住的样子。后面优化这块代码的时候我发现有几个RPC服务不是相互依赖它们是各自返回部分的数据。我就把这几个RPC换成异步调用的形式,后面的性能就好很多了,虽然大促时还是要加机器,但cpu和响应时间指标比优化之前降了许多。这里用到的秘诀就是化同步为异步,化串行为并行。并且这一招在很多情况都是很有效果的!
如何配置线程池
线程池也是一个性能优化重点,线程池配置得好的话就能很好利用现代计算机的多核处理器去提升系统的性能,但是配置得不好的话,就不好说了~。线程池参数很重要的一个参数就是设置多少个线程。一般来说线程的数量是与你处理的任务特性是相关的,比如你的任务是重计算轻IO的话,那么你的线程数最好不要太多一般Ncpu + 1 或者Ncpu就够了。因为太多的线程会导致CPU竞争剧烈不停的进行上下文切换,这反而是事倍功半。如果是IO密集型任务的话则可以根据自已需要的配多一点线程比如2Ncpu。如果是混合型任务那最好把两者分开,独立用线程池是处理。另外如果你是用JAVA的话最好是去了解一下Executor的框架,看一下JDK的源码实现,因为JAVA有好几种线程池:FixedThreadPool,SingleThreadExecutor,CachedThreadPool,了解一下它们的适用情景对你的选型是很有好处的。同时你也要留意一下你部署机器的CPU核数,千万不要在单核的机器上启用多线程。另外要注意了单线程模型也并不一定代表性能底下哦,比如redis就是单线程模型。为什么高呢?其中一个原因是它没有CPU上下文切换啊。
DB查询性能优化
这一块我觉得要讲的东西非常多,有时间的话打算专门写一篇文章来介绍。这里略过鸟。。。
系统中陈旧的框架
不知道大家的项目里面是不是还有用c3p0连接池的,这个东西我在出来工作那会儿用过之后就再也没有用过了。因为这个线程池性能确实不高,并且工作中也经常报问题。后面我用的是druid再后来是spring-boot的tomcat-jdbc,hikaricp。因为技术总是不停的在前进,新的设计总是不断改良旧的设计。并且一些陈旧的框架后面就再没有更新了,比如c3p0吧,它是用JAVA语言写的它出来那会儿当时JDK用来同步操作还只能是synchronized,所以意味着当时语言特性影响限制它的性能上限。现在JDK和当时的相比可不一样了增加了并发包,从虚拟机到我们常用的数据结构和API都做了很多优化和改良。所以框架也是不断更新的才好。
了解熟悉你常用数据结构、中间件和系统网络知识。
比如redis是单线程模型,单线程意味着redis的所有任务都只能按顺序的一个个去处理,前面的没处理完后面就只能安静的等待着。前面的卡住后面就会有堆积,就会产生超时影响redis的性能,所以redis里面不能有重计算的操作和存大key,如果要存大key最好应用服务器自己压缩一下才存进去,一方面可以减少性能影响也可以节省带宽~。网络协议TCP和UDP这些就不用说了。HTTP和HTTPS两者的性能差异据说是4倍左右,因为HTTPS每次发接收报文都要加解密,运算耗费CPU。所以一些数据不敏感的是不是考虑用HTTP会好一点~。JAVA常用的数据ArrayList,LinkedList,Set,HashMap,Array,TreeMap这些低层的源码最好也看一下,了解一下适用场景,顺便也学习一下别人的代码。我举个例子之前我做算法题的时候有道题用HashMap和Array都是可以AC的,但是两者的出来的时间差了一个数量级,原因是HashMap和Array的低层实现导致的。HashMap低层是一个数组链表,并且存储的对象是Node结点,Hash冲突大的时候其时间复杂度就由O(1) 退化成O(n),并且还有一个不为人知的扩容过程,Array数组就是确定了每一次读取操作都O(1)。所以执行n次操作后两者的耗费的时间就是O(n)平方与O(n)的差别了。。。。不过HashMap在JAVA8终于做了改良,当链表的长度大于8的时候就换成了红黑树的存储这时复杂度降为了O(log(n)),这些你看下源码就一目了然。另外操作系统这块也是要了解的比如epoll select poll的区别,线程用户态内核态的切换等等。
养成良好的个人编码习惯和意识。
比如不要寄望在一个SQL里面做完所有的事情,因为通常是写一个复杂的SQL一分钟,可能优化你一年。调用N次RPC处理N个数据不如调一次RPC处理N个数据,因为可以节省了(N-1)的RT时间,同样对SQL查询也适用。多了解一下一些新语言的特性和设计思想比如forkJoin,JAVA8的lambda表达式,completefuture异步处理。或者有时间精力学习一下算法知识也是可以开阔一下你的思路。
另外普及一下性能优化逃不开的一个原理就是木桶原理,就是系统的整体性能的好坏不是取决于你最好的那部分,而是最差的那部分·-·。这部分可能是在你系统内部也可能是外部。所以性能优化的路很长很长很长很长长长。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号