
一. 什么是Kafka
面向数据流的生产,转换,存储,消费的整体流处理平台。(分布式流处理平台)
Kafka是基于zookeeper的分布式消息系统。
Kafka具有高吞吐率、高性能、实时及高可靠等特点。
二、Kafka特性
1、发布和订阅数据的流,类似于消息队列,消息系统
2.、分布式流处理平台
3、当数据产生的时候,对数据处理
4、吞吐量高但不保证消息有序。(保证Partition内的消息有序)
三、Kafka应用于
1. 构建数据流管道,应用直接有比较强的应用关系
2、构建实时数据处理应用,能够转换或者响应数据流
3、日志收集或流式系统
4、消息系统
5、用户活动跟踪或运营指标监控
四 Kafka基本概念
Producer:消息和数据的生产者,向Kafka的一个topic发布消息的进程/代码/服务
Consumer: 消息和数据的消费者,订阅数据(Topic)并且处理发布的消息的进程/代码/服务
Consumer Group:逻辑概念,对于同一个topic,会广播给不同的group,一个group中,只有一个consumer可以消费该消息。
Broker:物理概念,Kafka集群中的每个Kafka节点
Topic:逻辑概念,Kafka消息的类别,对数据进行区分、隔离。由多个Partitions组成。
Partition:物理概念,Kafka下数据储存的基本单元。一个Topic数据,会被分散存储到多个Partition,每一个Partition是有序的。
1)每一个Topic被切分为多个Partitions
2)消费者数目少于或等于Partition的数目
3)Broker Group中的每一个Broker保存Topic的一个或多个Partitions
4)Consumer Group中的仅有一个Consumer读取Topic的一个或者多个Partitions,并且是唯一的Consumer
Replication:同一个Partition可能会有多个Replica,多个Replica之间数据是一样的
1)当集群中的有Broker挂掉的情况,系统可以主动的使用Replicas提供服务
2)系统默认设置每一个Topic的replication系数为1,可以在创建Topic时单独设置
Replication特点
1)Replication的基本单位是Topic的Partition
2)所有的读和写多从Leader进,Followers只是做为备份
3)Follower必须能够及时复制Leader的数据
4) 增加容错性与可扩展性
Replication Leader:一个Partition的多个Replica上,需要一个Leader负责该Partition上与Producer和Consumer交互
ReplicaManager:负责管理当前broker所有分区和副本的信息,处理KafkaController发起的一些请求,副本状态的切换、添加/读取消息等。
五、Kafka基本结构
Producer Api
Consumer Api
Streams Api
Connectors Api
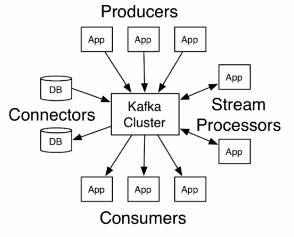
Kafka客户端API类型
AdminClient AIP: 允许管理和检测Topic、broker以及其它kafka对象。
Producer Api: 发布消息到1个或多个topic
Consumer Api: 订阅一个或多个topic,并处理产生的消息。
Streams Api:高效的将输入流转换到输出流
Connectors Api: 从一些源系统或应用程序中拉取数据到kafka
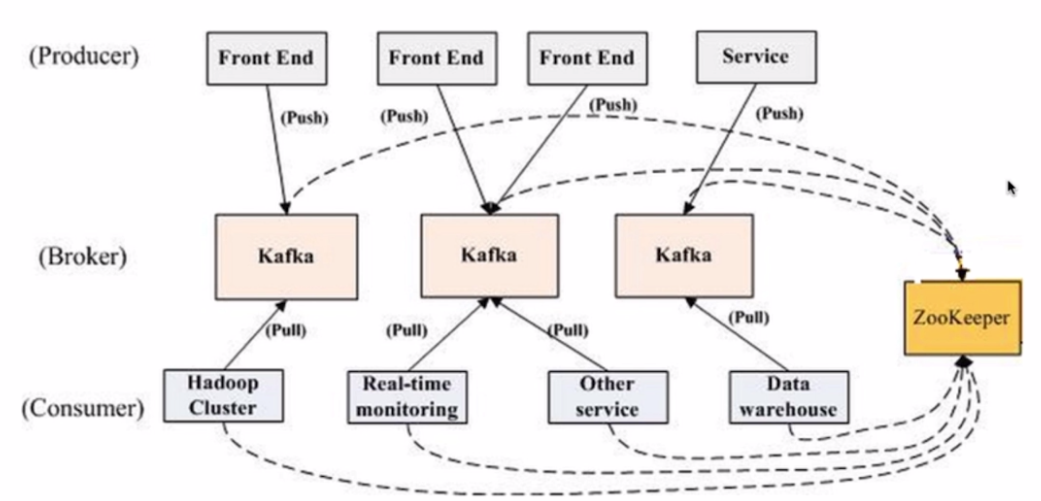
六、Kafka消息结构

七、Kafak特点
分布式
多分区
多副本
多订阅者
基于Zookeeper调度
高性能
高吞吐量
低延迟
高并发
时间复杂度为O(1)
持久性和可扩展性
数据可持久化
容错性
支持在线水平扩展
消息自动平衡
八、Kafka高性能的原因
顺序写,Page Cache空中接力,高效读写
顺序写: 顺序写盘,磁盘的利用率高
Page Cache空中接力:
高性能高吞吐
后台异步、主动Flush
预读策略IO调度
九、Kafka吞吐量大的原因
日志顺序读写和快速检索
Partition机制
批量发送接收及数据压缩机制
通过sendfile实现零拷贝原则。
十、Kafka底层原理之日志
kafka的日志是以Partition为单位进行保存。
日志目录格式为Topic名称+数字。
日志文件格式是一个”日志条目“ 序列。
每条日志消息由4字节整性与N字节消息组成

日志分段
每个Partition的日志会分为N个大小相等的segment中(如对1G进行分段)
每个segment中消息数量不一定相等。
每个Partition只支持顺序大写。(磁盘读写速度可能会比内存高,有时甚至10倍以上)
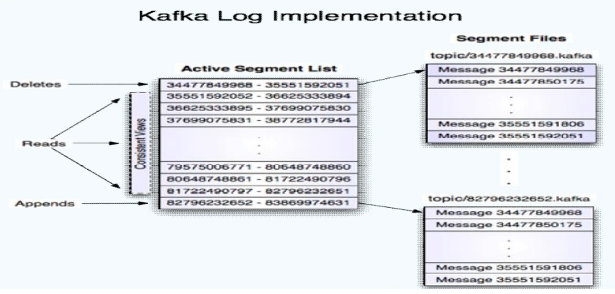
segment存储结构
Partition会将消息添加到最后一个segment上。
当segment达到一定阀门会flush到磁盘上。
segment文件分为两个部分: index(.index 文件)和data(.log文件)

index构建了完整的序列,序列里存的是offset的元数据,当读取以后,根据消息的元数据,去log中读取数据。offset指的是每条消息的起始位置。
下图描述了index文件和log文件的关系。

日志读操作
首先需要在存储的数据中找出segment文件。
然后通过全局offset计算segment中的offset
通过index中的offset寻找具体数据内容。
日志写操作
日志允许串行的追加消息到文件最后,
当日志文件达到阈值则滚动到新文件上。
kafka高性能核心pagecache和zerocopy原理
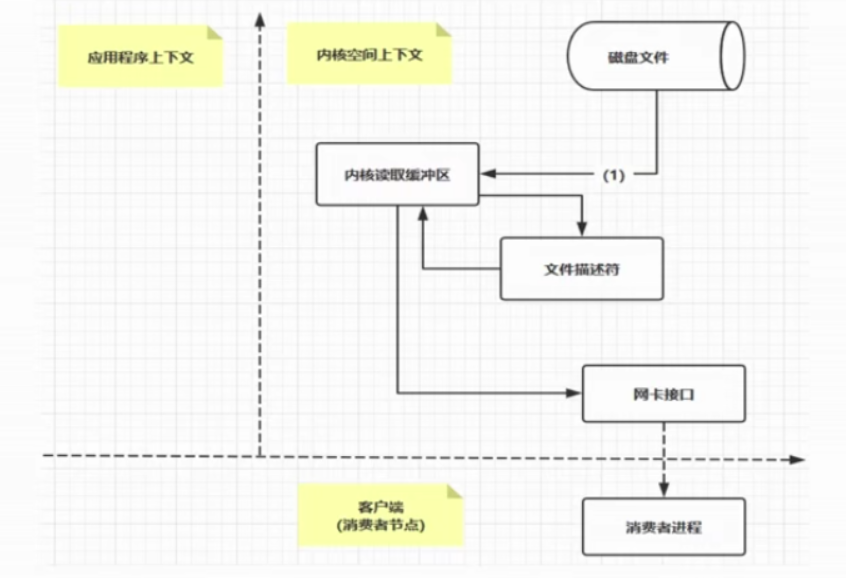
下图是从磁盘读取文件,然后写给另外一端的程序的过程
左边是应用程序上下文,右边是内核空间上下文
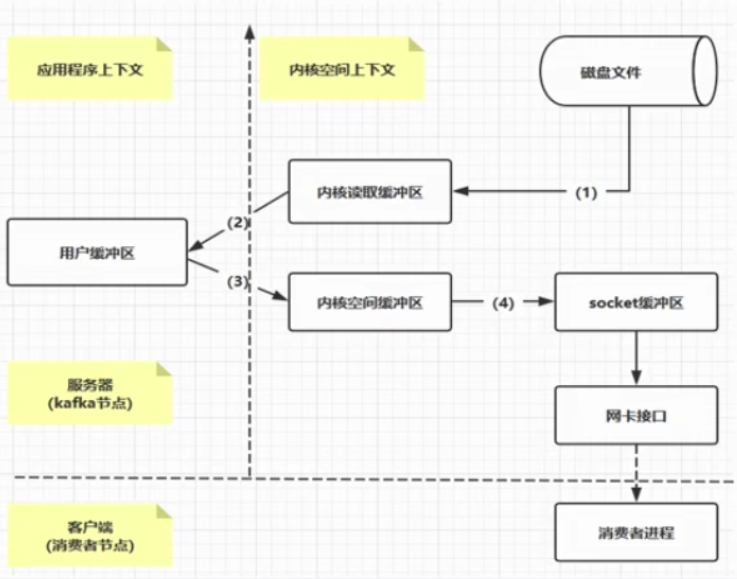
Pagecache是操作系统实现的磁盘缓存机制,以此减少对磁盘IO的操作。具体的操作是把磁盘的数据缓存在内存中,把对磁盘的访问变成对内存的访问。
(1) 操作系统将磁盘文件写入“内核读取缓冲区”
(2) 从用户缓冲区读取操作系统的内核缓冲区数据。
如果要将数据传入到另外一个应用,则继续下面的步骤
(3) 用户缓冲区再到内核空间缓冲区
(4) 内核空间缓冲区到socket缓冲区,然后到网卡接口,再到消费者进程。
以上流程发生了4次拷贝操作。
零拷贝(Kafka使用了零拷贝zerocopy)
将磁盘文件数据
操作系统将磁盘文件写入“内核读取缓冲区”,然后直接到网卡接口,到消费者进程。这个过程就是zerocopy。
也就是zerocopy只是将磁盘文件数据复制到页面缓存中1次,然后将数据从页面缓存直接发送到网络中。
十一、消费者组与消费者
kafka消费者是kafka消费的单位
单个Partition只能由消费者组中某个消费者消费。
消费者组中的单个消费者可以消费多个Partition。
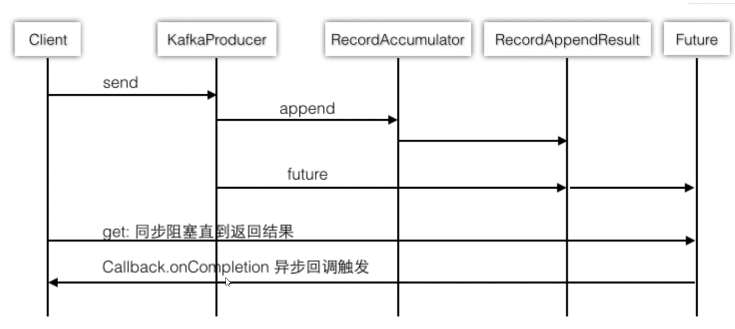
十二、Producer客户端
kafka Producer客户端
时序图:
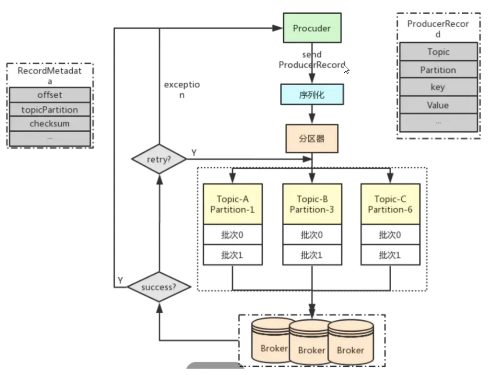
流程图:
十三、kafka如何保证顺序性
Kafka的特性只支持单Partition有序
使用kafka key + offset可以做到业务有序
十四、kafka topic删除做了哪些事情
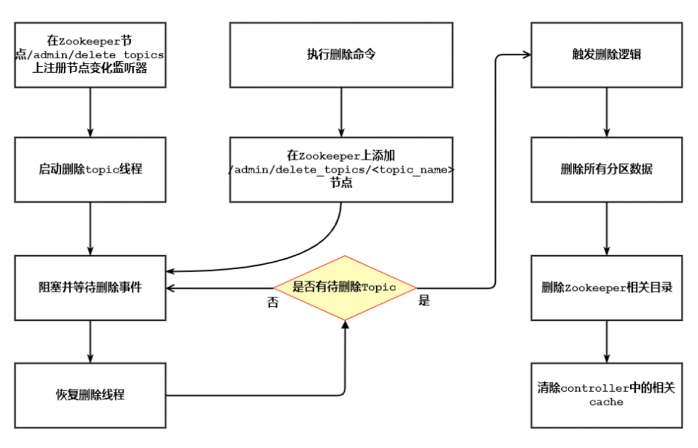
Kafka的Topic删除存在的问题比较多
建议设置auto.create.topics.enable = false;
建议设置delete.topic.enable=true
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号