
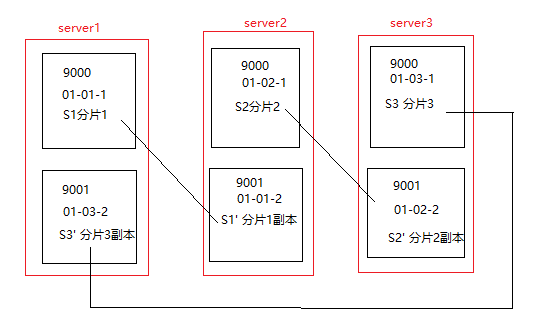
三条服务器,每台服务器安装两个clickhouse实例
一、服务器规划
单机两个clickhouse实例安装,参考Clickhouse 单机双实例
zookeeper集群安装,参考: Zookeeper 集群搭建--单机伪分布式集群
我这里用的是三台服务器,分别为第一台sever1 118.xx.xx.101,第二台 server2 49.xx.xx.125, 第三台server3 110.xx.xx.67
二、配置
1、集群配置 config.xml
<remote_servers>
<perftest_3shards_2replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server1</host>
<port>9000</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
<replica>
<host>server2</host>
<port>9001</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server2</host>
<port>9000</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
<replica>
<host>server3</host>
<port>9001</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>server3</host>
<port>9000</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
<replica>
<host>server1</host>
<port>9001</port>
<user>larrylin2</user>
<password>123456</password>
</replica>
</shard>
</perftest_3shards_2replicas>
</remote_servers>
2、zk集群配置 config.xml
<zookeeper>
<node>
<host>server1</host>
<port>2181</port>
</node>
<node>
<host>server2</host>
<port>2181</port>
</node>
<node>
<host>server3</host>
<port>2181</port>
</node>
</zookeeper>
3、副本配置 config.xml
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>01-01-1</replica>
</macros>
另外5个实例的副本配置分别为
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>01-01-2</replica>
</macros>
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>01-02-1</replica>
</macros>
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>01-02-2</replica>
</macros>
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>01-03-1</replica>
</macros>
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>01-03-2</replica>
</macros>
4、用户配置 users.xml
<users>
<larrylin2>
<password>123456</password>
<networks incl="networks" replace="replace">
<ip>0.0.0.0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</larrylin2>
</users>
三、创建本地表
CREATE TABLE IF NOT EXISTS default.test_local ON CLUSTER 'perftest_3shards_2replicas' (
ts_date Date,
ts_date_time DateTime,
user_id Int64,
event_type String,
site_id Int64,
groupon_id Int64,
category_id Int64,
merchandise_id Int64,
search_text String
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/test_local','{replica}')
PARTITION BY ts_date
ORDER BY (ts_date,toStartOfHour(ts_date_time),site_id,event_type)
SETTINGS index_granularity = 8192;
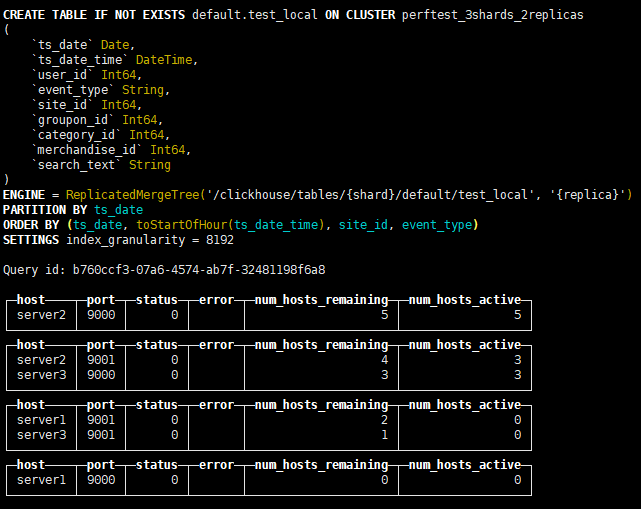
ON CLUSTER 表示分布式DDL, 一次执行所有实例上创建同样的本地表。
perftest_3shards_2replicas为集群名称
{shard} 分片标识符
{replica} 副本标识符,来自config.xml 中的macros
ReplicatedMergeTree引擎接收两个参数:
1、ZK中该表相关数据的存储路径,Clickhouse官方建议格式 /clickhouse/tables/{shard}/[database_name]/[table_name]
2、副本名称,一般用{replica}
四、ZK路径的znode结构和内容
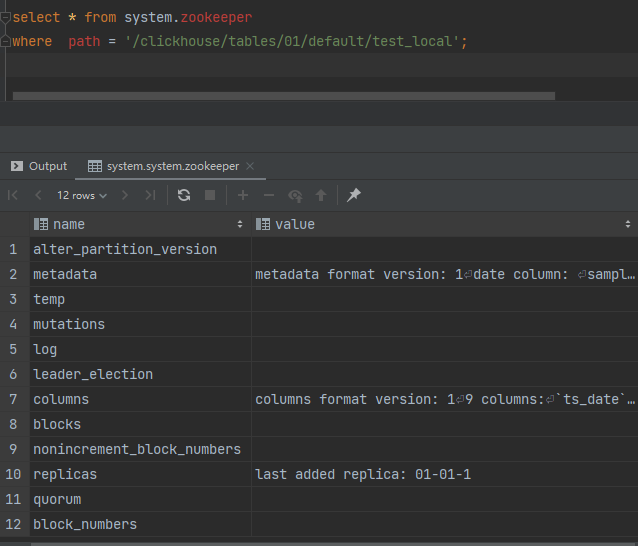
metadata的value值
metadata format version: 1 date column: sampling expression: index granularity: 8192 mode: 0 sign column: primary key: ts_date, toStartOfHour(ts_date_time), site_id, event_type data format version: 1 partition key: ts_date granularity bytes: 10485760
colums的value值
columns format version: 1 9 columns: `ts_date` Date `ts_date_time` DateTime `user_id` Int64 `event_type` String `site_id` Int64 `groupon_id` Int64 `category_id` Int64 `merchandise_id` Int64 `search_text` String
ReplicatedMergeTree引擎在ZK中存储了大量的数据,包括表结构信息,元数据、操作日志、副本状态、数据块校验值、数据part merge过程中的选主信息等。
ZK在复制表机制下有元数据存储、日志框架、分布式协调器服务三种角色,任务很重,所以要保证ZK集群的可用性以及资源(尤其是硬盘资源)。
五、创建分布式表
CREATE TABLE IF NOT EXISTS default.test_all ON CLUSTER 'perftest_3shards_2replicas' AS default.test_local ENGINE = Distributed(perftest_3shards_2replicas, default, test_local,rand());

Distributed引擎需要以下几个参数
1) 集群标识符
2)本地表所在的数据库名称
3) 本地表名称
4)分片键sharding key(可选)
该键与config.xml 中配置的分片权重(weight) 一同决定写入分布式表时的路由。它可以时表中的一列原始数据(如site_id),也可以是函数调用的结果,如上面的SQL语句采用了随机值rand()。 注意该键要尽量保证数据均匀分布,另外一个常用的操作是采用区分度较高的列的哈希值,如intHash64(user_id).
直接写分布式表的优点自然是可以让clickhouse控制数据到分片的路由,
缺点:
数据是先写到一个分布式表的实例中缓存起来,再逐渐分发到各个分片上去,实际是双写了数据(写入放大),浪费资源。
数据写入默认是异步的,短时间内可能造成不一致。
目标表中会产生较多的小parts,使merge(即compaction)过程压力增大。
相对而言,直接写本地表是同步操作,更快,parts的大小也比较合适,但是要求应用层额外实现路由逻辑,如轮询或者随机等。
六、验证
在第一台9000中增加数据
insert into test_local (ts_date, ts_date_time, user_id, event_type, site_id,
groupon_id, category_id, merchandise_id,
search_text)
values ('2021-11-11','2021-11-11 10:00:00',5,'stand',1,1,1,1,'world');
可以看到数据已经添加select * from test_local where user_id= 5; 
查询分布式表
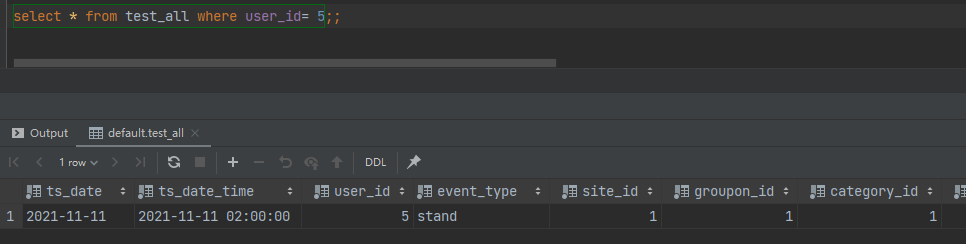
在另外一台查看本地表 select * from test_local where user_id= 5;
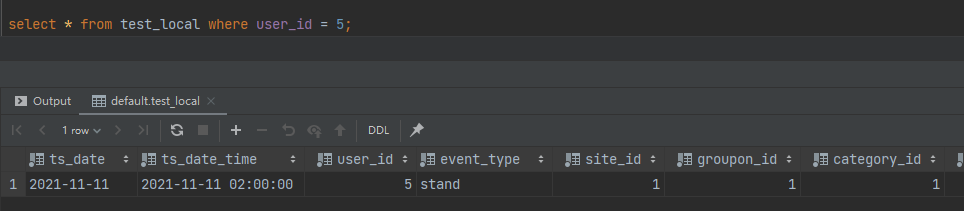
说明数据已经复制到副本了。
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号