
一、Spark下载
进入官网下载需要的版本: http://archive.apache.org/dist/spark/
官网下载地址太慢,建议在Apache国内镜像下载
地址1:http://mirror.bit.edu.cn/apache/
地址2:https://mirrors.tuna.tsinghua.edu.cn/apache
地址2貌似速度快一些
hadoop、hbase等Apache旗下的大多都可以
我这里下载的版本时: spark-2.4.7-bin-hadoop2.6.tgz
1、下载后解压
cd /home/tools/spark2
tar -zxvf spark-2.4.7-bin-hadoop2.6.tgz
2、启动spark
/home/tools/spark2/spark-2.4.7-bin-hadoop2.6/bin
./spark-shell
启动成功后如下图所示:
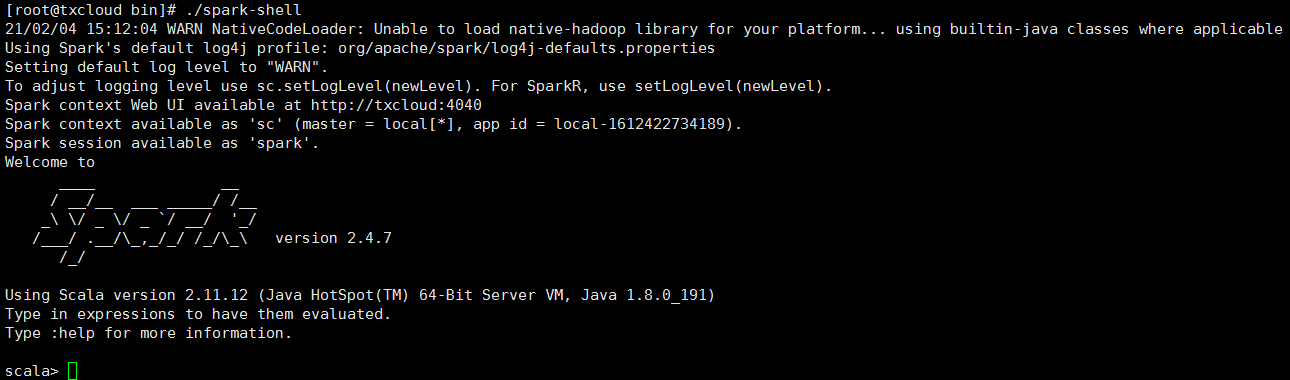
二、使用Spark统计文本的行数
1、数据准备
创建文件 /home/data/helloSpark, 内容如下图所示
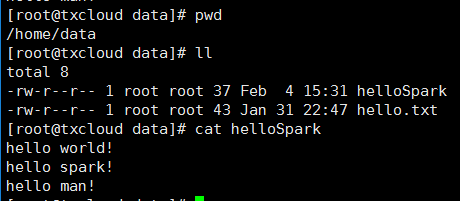
2、统计文本的行数
var lines=sc.textFile("/home/data/helloSpark") 加载文件的内容。
lines.count() 进行统计行数

3、统计单词个数
scala> var file=sc.textFile("/home/data/helloSpark")
scala> var wordCounts = file.flatMap(line => line.split(" ")).map((word => (word,1))).reduceByKey(_+_)
scala> wordCounts.collect
res3: Array[(String, Int)] = Array((spark!,1), (man!,1), (hello,3), (world!,1))

另外一个统计Words的代码,分别使用Java和Scale代码进行统计
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号