
一、设计
1、海量日志收集架构设计(ELK)
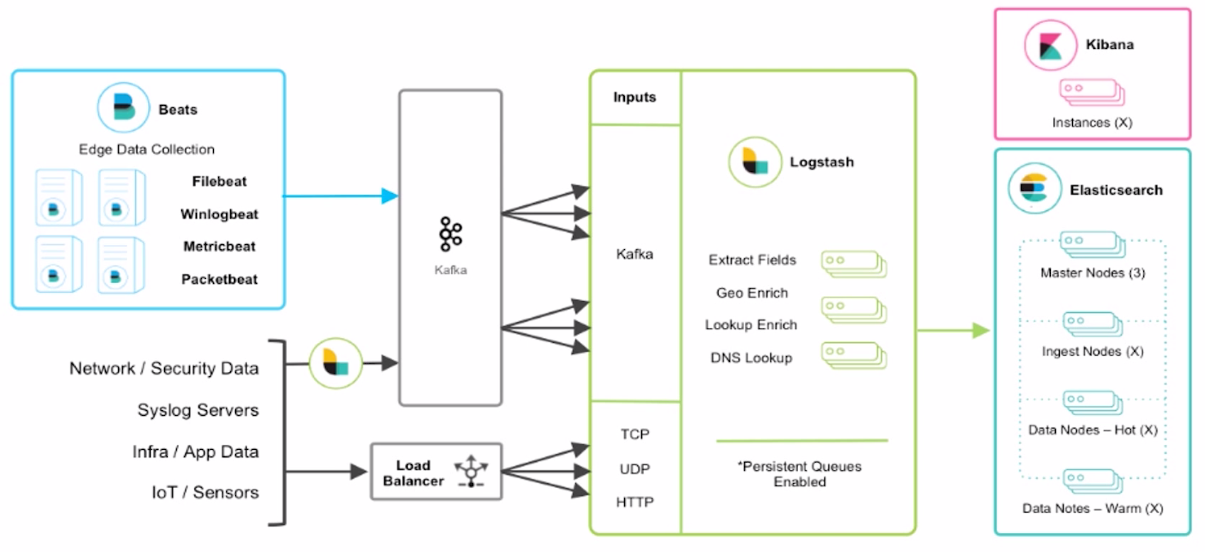
Beats: 主要用于收集日志
Filebeat: 监控文件的变更,将变更抓取出来。然后输出到其它地方。(使用Filebeat将收集过来数据转储到Kafka)
Logstash: 对日志进行过滤。对过滤的数据存储到Elasticsearch
Kibana: ElasticSearch通过Kibana进行数据展示。
Kafka: 用到Kafka是为了海量数据的数据,业务高峰期通过Kafka做一个缓冲。
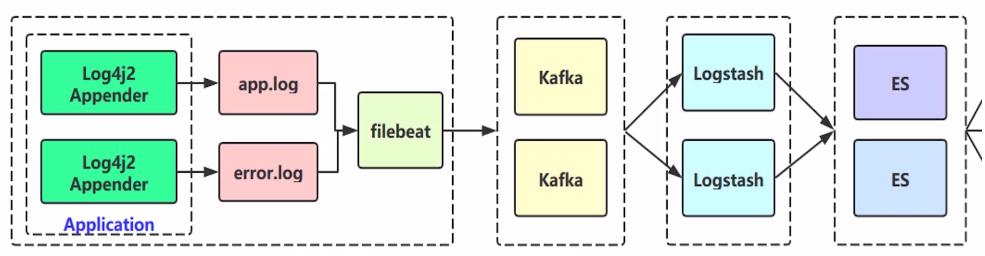
架构设计2
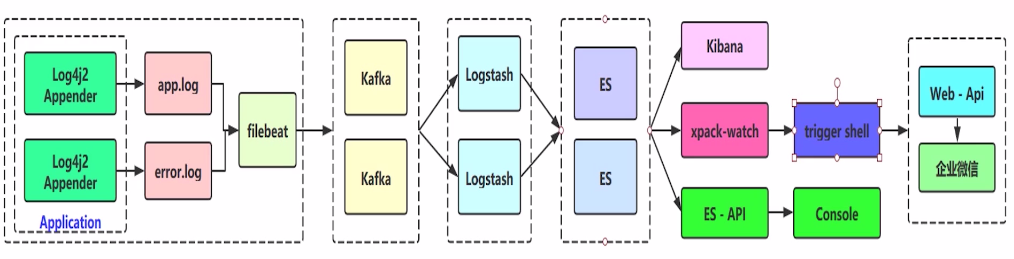
架构设计3
二、工程搭建
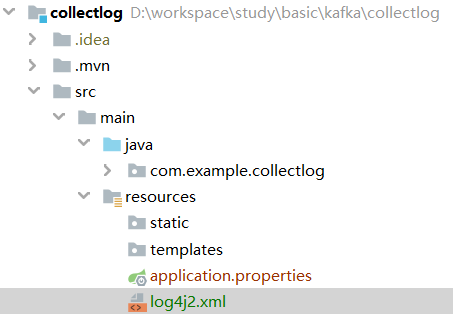
1、创建工程collectlog
2、引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<!-- 排除 spring-boot-starter-logging, 底层为logback-->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
3、增加日志配置文件
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO" schema="Log4J-V2.0.xsd" monitorInterval="600" >
<Properties>
<Property name="LOG_HOME">logs</Property>
<property name="FILE_NAME">collect</property>
<property name="patternLayout">[%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}] [%level{length=5}] [%thread-%tid] [%logger] [%X{hostName}] [%X{ip}] [%X{applicationName}] [%F,%L,%C,%M] [%m] ## '%ex'%n</property>
</Properties>
<Appenders>
<Console name="CONSOLE" target="SYSTEM_OUT">
<PatternLayout pattern="${patternLayout}"/>
</Console>
<!-- 全量级别日志-->
<RollingRandomAccessFile name="appAppender" fileName="${LOG_HOME}/app-${FILE_NAME}.log" filePattern="${LOG_HOME}/app-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" >
<PatternLayout pattern="${patternLayout}" />
<Policies>
<TimeBasedTriggeringPolicy interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingRandomAccessFile>
<!-- warn级别以上的日志才去收集-->
<RollingRandomAccessFile name="errorAppender" fileName="${LOG_HOME}/error-${FILE_NAME}.log" filePattern="${LOG_HOME}/error-${FILE_NAME}-%d{yyyy-MM-dd}-%i.log" >
<PatternLayout pattern="${patternLayout}" />
<Filters>
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<Policies>
<TimeBasedTriggeringPolicy interval="1"/>
<SizeBasedTriggeringPolicy size="500MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingRandomAccessFile>
</Appenders>
<Loggers>
<!-- 业务相关 异步logger -->
<AsyncLogger name="com.example.*" level="info" includeLocation="true">
<AppenderRef ref="appAppender"/>
</AsyncLogger>
<AsyncLogger name="com.example.*" level="info" includeLocation="true">
<AppenderRef ref="errorAppender"/>
</AsyncLogger>
<Root level="info">
<Appender-Ref ref="CONSOLE"/>
<Appender-Ref ref="appAppender"/>
<AppenderRef ref="errorAppender"/>
</Root>
</Loggers>
</Configuration>
在AsyncLogger 类中使用了AsyncLoggerDisruptor
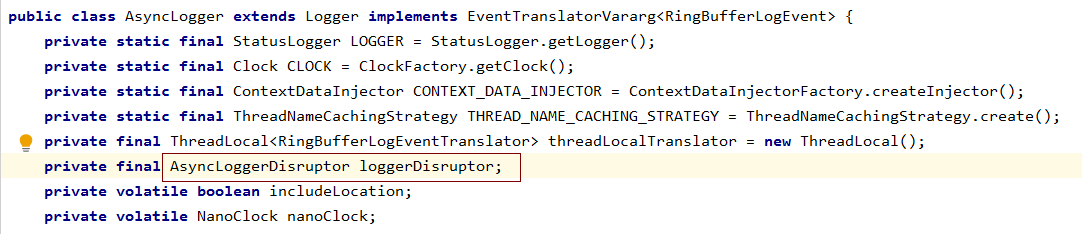
在AsyncLoggerDisruptor中使用了Disruptor, Disruptor是一个高性能,非阻塞组件。
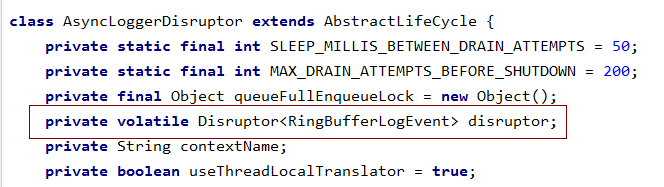
4、创建类InputMDC
@Component
public class InputMDC implements EnvironmentAware {
private static Environment environment;
@Override
public void setEnvironment(Environment environment) {
InputMDC.environment = environment;
}
public static void putMDC(){
MDC.put("hostName", NetUtil.getLocalHostName());
MDC.put("ip", NetUtil.getLocalIp());
MDC.put("applicationName", environment.getProperty("spring.application.name"));
}
}
5、增加测试
@Slf4j
@RestController
public class IndexController {
@RequestMapping(value = "/index")
public String index(){
InputMDC.putMDC();
log.info("这是一条info日志");
log.warn("这是一条warn日志");
log.error("这是一条error日志");
return "ok";
}
@RequestMapping(value = "/err")
public String err(){
InputMDC.putMDC();
try {
int a = 1 / 0;
}catch (Exception e){
log.info("除0异常" , e);
}
return "err";
}
}
三、启动collectlog
1、使用install命令进行打包
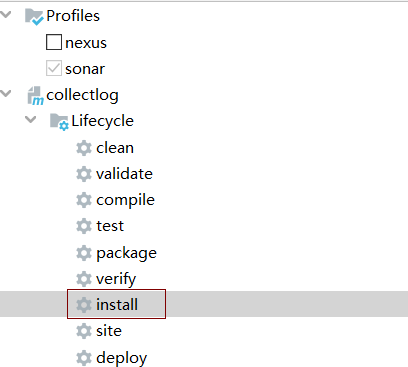
然后将打包生成的collectlog-0.0.1-SNAPSHOT.jar文件上传到服务器/home/files/wars目录下
java -jar collectlog-0.0.1-SNAPSHOT.jar
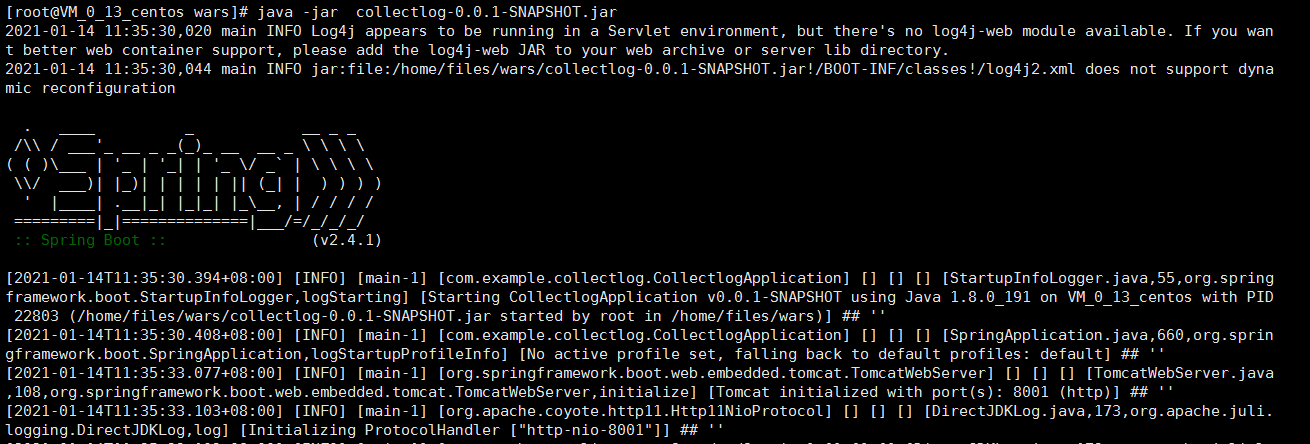
说明启动成功。
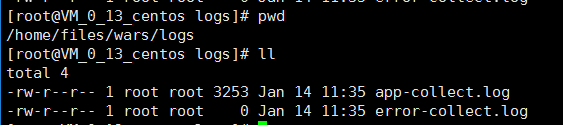
启动成功后,可以看到生成了两个日志文件。路径为:/home/files/wars/logs
四、filebeat收集日志
1、启动kafka
参考: Kafka入门 --安装和Java集成Kafka实践
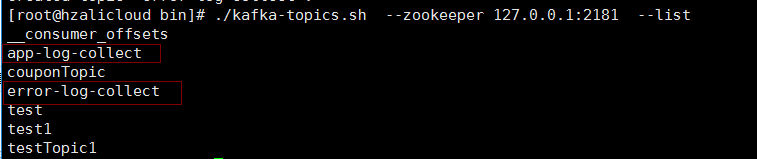
查看kafka的主题
cd /usr/local/kafka_2.11-1.0.1/bin
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --list

创建topic
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic app-log-collect --partitions 1 --replication-factor 1
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic error-log-collect --partitions 1 --replication-factor 1
2、安装FileBeat
这里使用的版本为7.4.2, 对应的ElasticSearch版本为7.4.2
1) FileBeat 下载地址
链接:https://pan.baidu.com/s/19kyIHrvWvTQbAy2dY0o08g
提取码:k4ow
2、解压FileBeat
tar -zxvf filebeat-7.4.2-linux-x86_64.tar.gz -C /usr/local/

修改名称为filebeat-7.4.2
mv filebeat-7.4.2-linux-x86_64/ filebeat-7.4.2
查看filebeat里面的文件
filebeat.yml 提供了抓取文件的默认配置
3、修改 filebeat.yml配置
## multiline 插件也可以用于其他类似的堆栈式信息,比如linux的内核日志
input {
## 订阅kafka的所有app-log-开头和error-log-开头的主题
kafka {
## app-log-服务名称
topics_pattern => "app-log-.*"
bootstrap_servers => "47.xx.xx.120:9092"
codec => json
consumer_threads => 1 ##增加consumer的并行消费线程数
decorate_events => true
# auto_offset_rest => "latest"
group_id => "app-log-group"
}
kafka {
## error-log-服务名称
topics_pattern => "error-log-.*"
bootstrap_servers => "47.xx.xx.120:9092"
codec => json
consumer_threads => 1
decorate_events => true
# auto_offset_rest => "latest"
group_id => "error-log-group"
}
}
## 收到数据后,对数据进行过滤
filter {
## 时区转换
ruby {
code => "event.set('index_time',event.timestamp.time.localtime.strftime('%Y.%m.%d'))"
}
if "app-log" in [fields][logtopic]{
grok {
## [表达式]
match => ["message","\[%NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%NOTSPACE:thread-id}\] \[%NOTSPACE:class}\] \[%NOTSPACE:hostName}\] \[%NOTSPACE:ip}\] \[%NOTSPACE:applicationName}\] \[%NOTSPACE:location}\] \[%NOTSPACE:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
if "error-log" in [fields][logtopic]{
grok {
## [表达式]
match => ["message","\[%NOTSPACE:currentDateTime}\] \[%{NOTSPACE:level}\] \[%NOTSPACE:thread-id}\] \[%NOTSPACE:class}\] \[%NOTSPACE:hostName}\] \[%NOTSPACE:ip}\] \[%NOTSPACE:applicationName}\] \[%NOTSPACE:location}\] \[%NOTSPACE:messageInfo}\] ## (\'\'|%{QUOTEDSTRING:throwable})"]
}
}
}
## 输出到控制台
output {
stdout { codec => rubydebug }
}
4、启动filebeat
cd /usr/local/filebeat-7.4.2/
./filebeat &

5、访问接口
访问index接口
访问err接口
6、如何查看已经被Kafka已经收到消息
查看主题:
./kafka-topics.sh --zookeeper 127.0.0.1:2181 --topic app-log-collect --describe

只能看到分区情况
cd /usr/local/kafka_2.11-1.0.1/kafkaLogs
可以看到,已经有两个文件夹app-log-collect-0和error-log-collect-0。每一个topic,会建一个文件夹存储数据。这是kafka的数据存储结构。
[root@hzalicloud kafkaLogs]# ll total 244 drwxr-xr-x 2 root root 4096 Jan 14 13:36 app-log-collect-0 drwxr-xr-x 2 root root 4096 Jan 14 13:36 error-log-collect-0 drwxr-xr-x 2 root root 4096 Jan 14 13:37 test-0 drwxr-xr-x 2 root root 4096 Jan 14 13:37 test1-0 drwxr-xr-x 2 root root 4096 Jan 14 13:37 testTopic1-0
进入其中一个文件夹app-log-collect-0
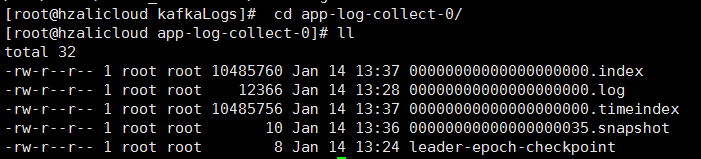
00000000000000000000.log 是真正存放的数据。编号从 00000000000000000000开始
说明数据已经收到了Kafka。
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号