
一、count实验和结论
1、测试数据准备
create table user_test_count
(
id int primary key not null auto_increment,
name varchar(45),
age int,
email varchar(60),
birthday date
) engine 'innodb';
insert into user_test_count( name, age,email, birthday)
values ('zhangsan',30,'zhangsan@163.com','1982-11-11');
insert into user_test_count( name, age,email, birthday)
values ('lisi',31,'lisi@163.com','1982-10-11');
insert into user_test_count( name, age,email, birthday)
values ('wangwu',36,'wangwu@163.com','1980-11-11');
insert into user_test_count( name, age,email, birthday)
values ('zhangliu',37,'zhangliu@163.com','1989-1-21');
执行 explain select count(*) from user_test_count;
返回

使用了主键。
修改email为索引 : create index user_test_count_email_index on user_test_count (email);
执行 explain select count(*) from user_test_count;
返回

在增加birthday索引
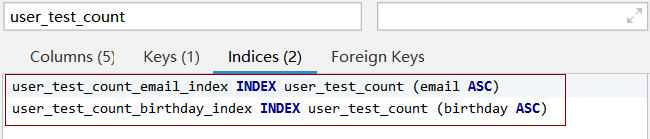
执行 explain select count(*) from user_test_count;
返回

总结:
1、当没有非主键索引时,会使用主键索引
2、如果存在非主键索引的话,会使用非主键索引。user_test_count_email_index
3、如果存在多个非主键索引,会使用一个最小的非主键索引 (减少扫描的次数)原因:
innodb非主键索引: 叶子节点存储的是: 索引+主键
主键索引叶子节点:主键+ 表数据
在1一个page里面,非主键索引可以存储更多的条目,对于一张表,100 0000条数据,
使用非主键索引,扫描page可能为100, 主键索引扫描page可能为500
count(字段) 只会针对该字段统计,使用这个字段上面的索引(如果有的话)
count(字段) 会排除掉该字段值为null的行
couont(*) 不会排除
count(*) 与count(1)
对于Innodb,两者没有区别。
对于MyISAM, 如果没有where条件,如select couont(*) from student; count(*) 能快速返回,因为行数已经存储在storage engine了。如果带有where条件,就不能直接返回
对于MySQL 8.0.13, InnoDB引擎, 如果没有where条件,如select couont(*) from student; 查询也会被优化,性能有所提升。
总结:
count(*) 与count(1)一样,不存在谁比谁快。 https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count
count(*) 会选择最小的非主键索引,如果不存在任何非主键,则会使用主键
count(*) 不会排除为null的行,而count(字段) 会排除。
对于不带查询条件的count(*) 语句,MyISAM及InnoDB (MySQL >= 8.0.13),都做了优化。
如果没有特殊需求,尽量使用count(*)
二、count优化
-- 花费646ms
select count(*) from salaries;
-- 查看存储引擎 ENGINE=InnoDB
show create table salaries;
-- 数据库版本5.7.32。 indodb > 8.0.13 可以针对无条件的couont(*)做了优化。
select version();
方案1: 创建一个更小的非主键索引
方案2: 把数据库引擎改成MyISAM 实际项目用的很少,一般不会修改数据库引擎。
方案3:汇总表 table[table_name, count] , 如employees表的数据为2000000,如果数据量变化,则修改count值。触发器自动维护这张条,增加一条数据 count + 1; 删除1条数据 count -1;
好处:结果比较准确 缺点: 增加了维护成本。
方案4: sql_calc_found_rows
select * from salaries limit 0, 10;
select count(*) from salaries;
优化为
select sql_calc_found_rows * from salaries limit 0, 10;
select found_rows() as salary_count;
Mybatis中使用 https://blog.csdn.net/myth_g/article/details/89672722
缺点: mysql 8.0.17已经废弃这种用法,未来会被删除。
注意点: 需要在MySQL终端执行(命令行),IDEA无法正常返回结果。
方案5: 缓存 select count(*) from salaries; 存放在缓存
优点: 性能比较高,结果比较准确,有误差但是比较小 (除非在缓存更新的期间,新增或者删除了大量的数据)
缺点: 引入了额外的组件,增加了架构的复杂度。
方案6: `information_schema`.TABLES
select * from `information_schema`.TABLES
where table_schema = 'employees' and TABLE_NAME = 'salaries';
好处: 不操作salaries表,不论salaries有多少数据,都可以迅速地返回结果。
缺点:估算值,并不是准确值
方案7
show table status where Name = 'salaries';
好处: 不操作salaries表,不论salaries有多少数据,都可以迅速地返回结果。
缺点:估算值,并不是准确值
方案8
explain select * from salaries;

返回的row字段就是行数
好处: 不操作salaries表,不论salaries有多少数据,都可以迅速地返回结果。
缺点:估算值,并不是准确值
三、实践
-- 耗时945ms
select count(*) from salaries where emp_no > 10010;
执行 explain select count(*) from salaries where emp_no > 10010;
返回:

优化: MySQL 大于8.0.13( 我这里版本为5.7 也能优化?)
select count(*) - (select count(*) from salaries where emp_no <= 10010) from salaries; --耗时313ms
explain select count(*) - (select count(*) from salaries where emp_no <= 10010) from salaries; 先查出小于等于10010的条数,然后总条数 - 小于等于10010的条数 = 大于10010的条数
返回:

作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号