
1、准备数据
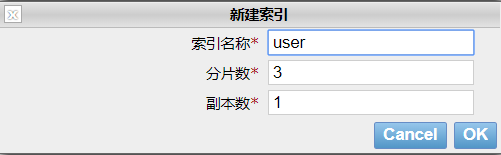
1) 创建索引
2) 创建mapping
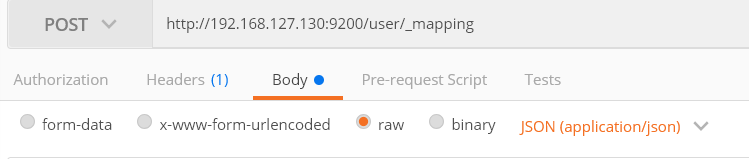
JSON数据如下
{
"properties": {
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"username": {
"type": "keyword"
},
"nickname": {
"type": "text",
"analyzer": "ik_max_word"
},
"money": {
"type": "float"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
},
"sex": {
"type": "byte"
},
"birthday": {
"type": "date"
},
"face": {
"type": "text",
"index": false
}
}
}
3) 增加多条数据
http://192.168.127.130:9200/user/_doc/1001
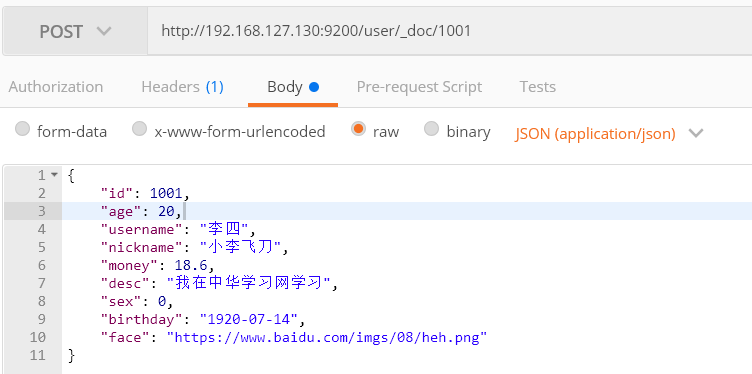
JSON如下":
{
"id": 1001,
"age": 20,
"username": "张三",
"nickname": "小张",
"money": 18.6,
"desc": "我在中华学习网学习",
"sex": 0,
"birthday": "1920-07-14",
"face": "https://www.baidu.com/imgs/08/heh.png"
}
然后修改id,增加多条数据
2、QueryString方式搜索
将搜索的字段和值拼接到Url中
根据索引中某个字段搜索
根据desc搜索
GET请求 http://192.168.127.130:9200/user/_search?q=desc:中华
多条件搜索: 根据desc和age进行搜索
http://192.168.127.130:9200/user/_search?q=desc:中华&q=age:20
QueryString用的很少,复杂测查询参数难以构建,所以大多查询都会使用dsl进行查询更好。
3、DSL方式搜索
DSL: Domain Specific Language 特定领域语言,基于JSON格式的查询,查询更灵活,有利于复杂查询
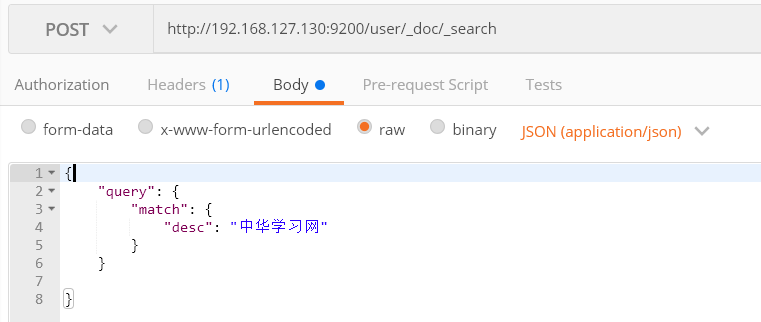
1) 查询desc单个字段
http://192.168.127.130:9200/user/_doc/_search
2) 查询某个字段是否存在
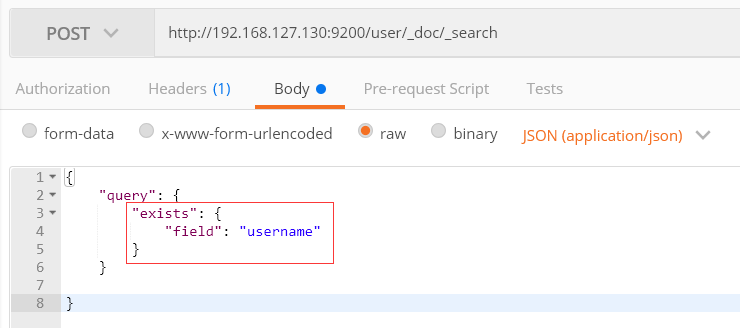
4、查询所有和分页
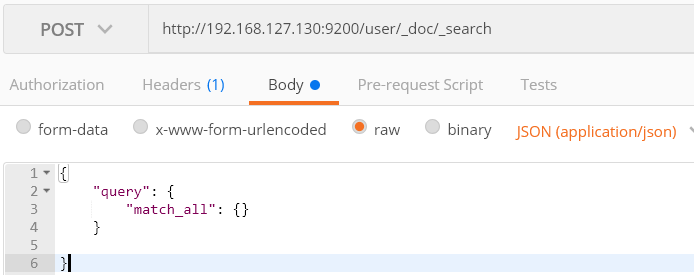
1) 查询所有
GET http://192.168.127.130:9200/user/_doc/_search
DSL方式查询所有, match_all
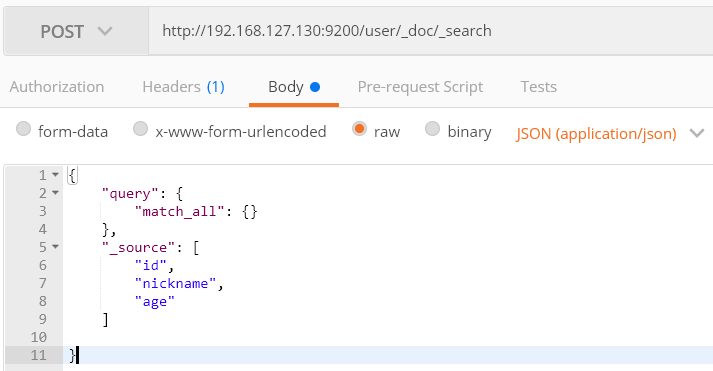
2) 查询指定要查询字段的所有数据
如下图,只查询id,nickname,age
3) 分页查询
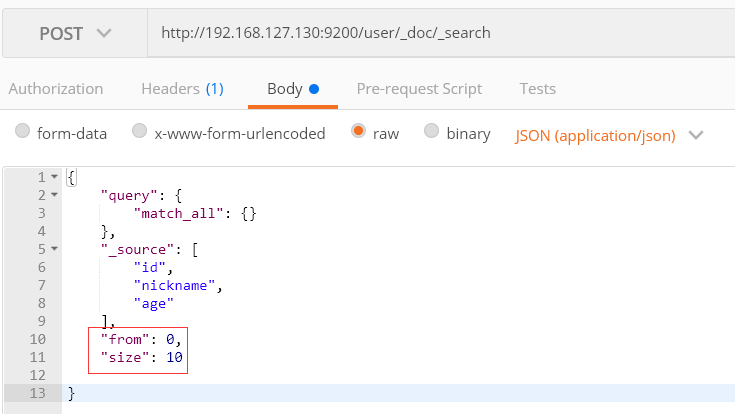
from 从第0条开始
size: 每页显示10条
4) head 可视化查询
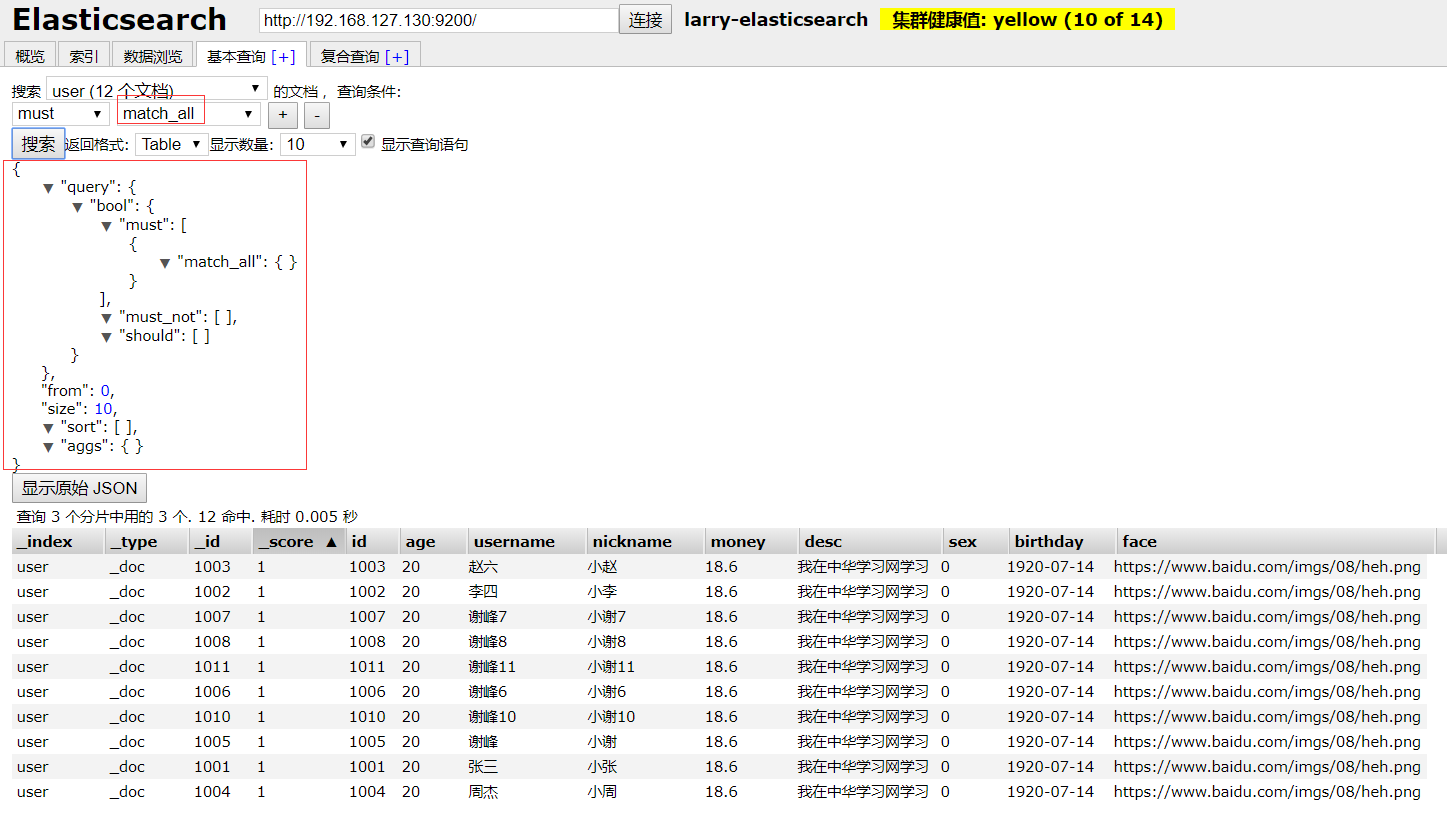
5) term精确搜索
,把搜索的内容,如“中华学习网”作为一个整个关键词去搜索,不会做分词搜索
desc包括有“中华学习网”,就能查询到。 将term换成match后,“中华学习网”会进行分词,将所有匹配分词的结果都能查询出来。
{
"query": {
"term": {
"desc": "中华学习网"
}
},
"_source": [
"id",
"nickname",
"age"
]
}
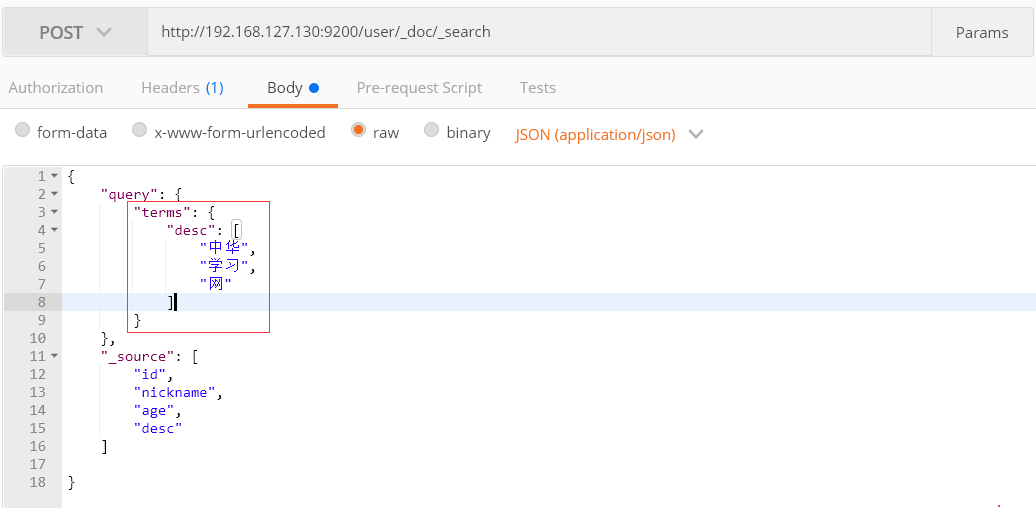
terms 多个词语匹配检索
相当于tag标签查询,比如博客的文章打上了tag, “前端”,“后端”,“ElasticSerach”,完全可以用标签匹配查询
6) match_parse
match: 分词后只要有匹配就返回
match_parse: 分词结果必须是text字段分词中都包含,而且顺序必须相同,而且必须都是连续的。(搜索比较严格)
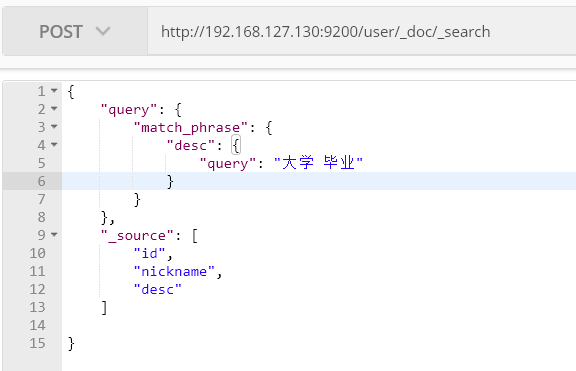
大学后面要跟上研究生,如“大学毕业后去读研究生”
slops: 允许词语间跳过的数量

大学和研究生之间还能有其它字符,如“大学毕业后,去读研究生“
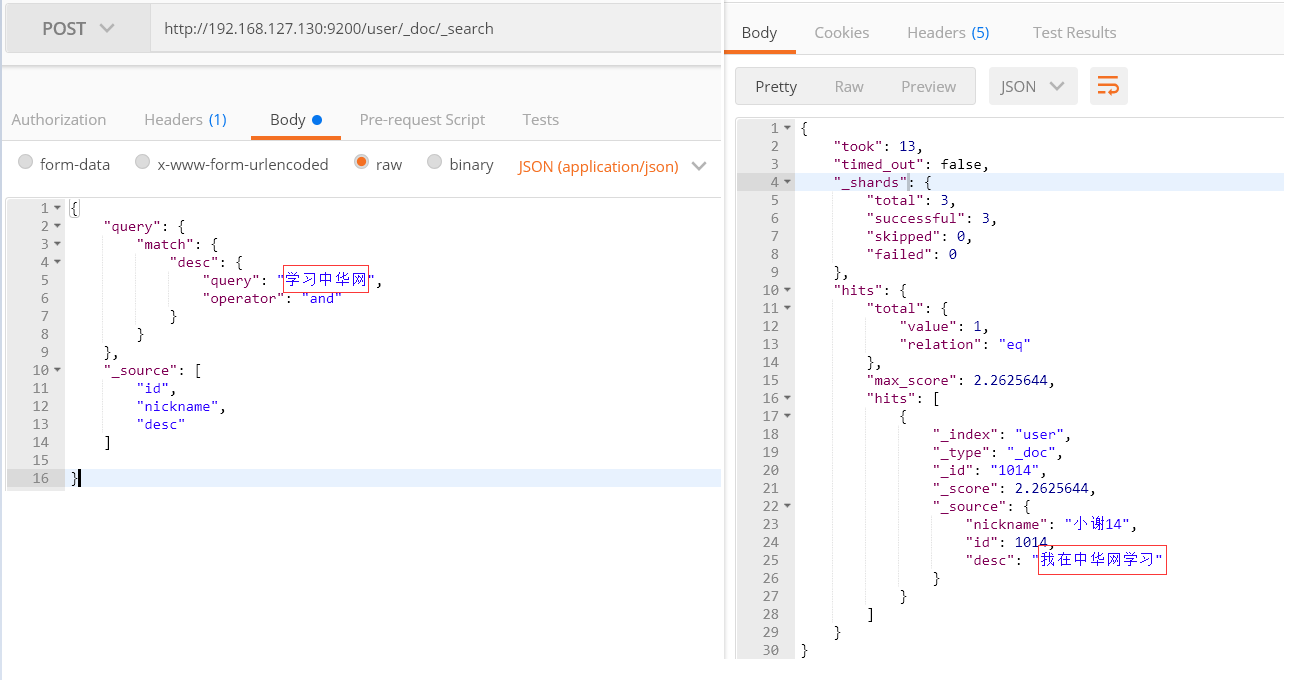
7) match(operator)
operator
or: 搜索内容分词后,只要存在一个词语匹配就展示结果
and: 搜索内容分词后,都要满足词语匹配

9) multi_match
满足使用match在多个字段中进行查询的需求

boost
权重,为某个字段设置权重,权重越高,文档相关性得分就越高。通常搜索商品名称要比商品简介的权重更高。
权重的格式如下图所示
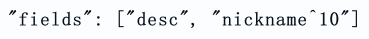
10) 布尔查询
可以组合多种查询
must: 查询必须匹配搜索条件,譬如 and
should: 查询匹配满足1个以上条件,譬如or
must_not: 不匹配搜索条件,一个都不要满足
例如:
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "中华学习网",
"fields": ["desc", "nickname"]
}
},
{
"term": {
"sex": 0
}
},
{
"term": {
"birthday": "1920-07-14"
}
}
]
}
},
"_source": [
"id",
"nickname",
"desc"
]
}
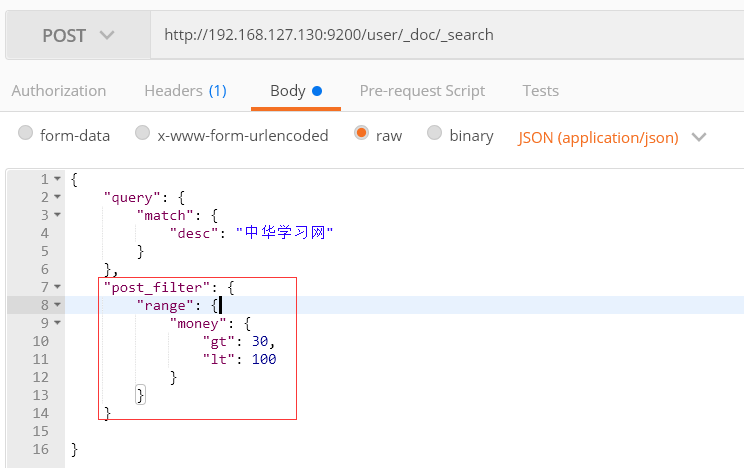
11) 过滤器
money字段值大于30,并且小于100
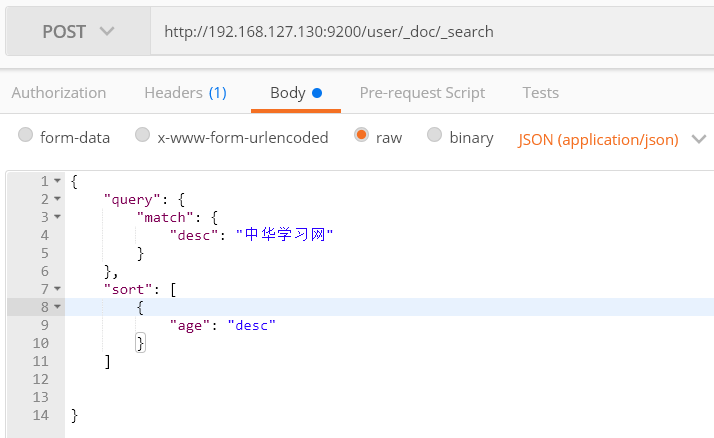
12) 排序
根据年龄降序
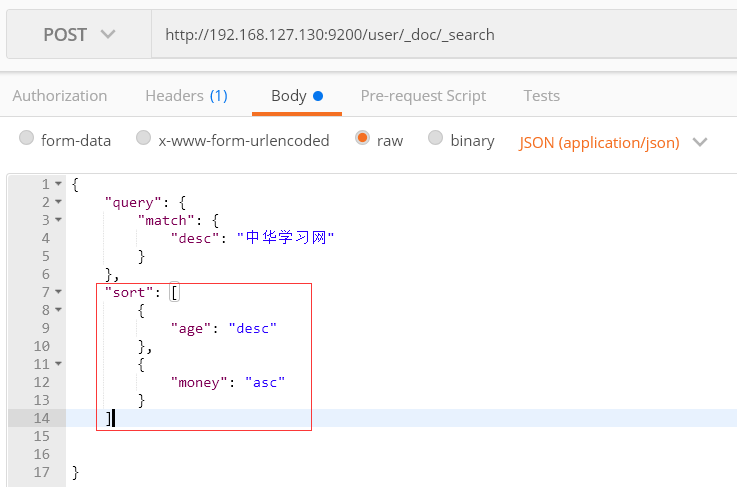
多个字段排序
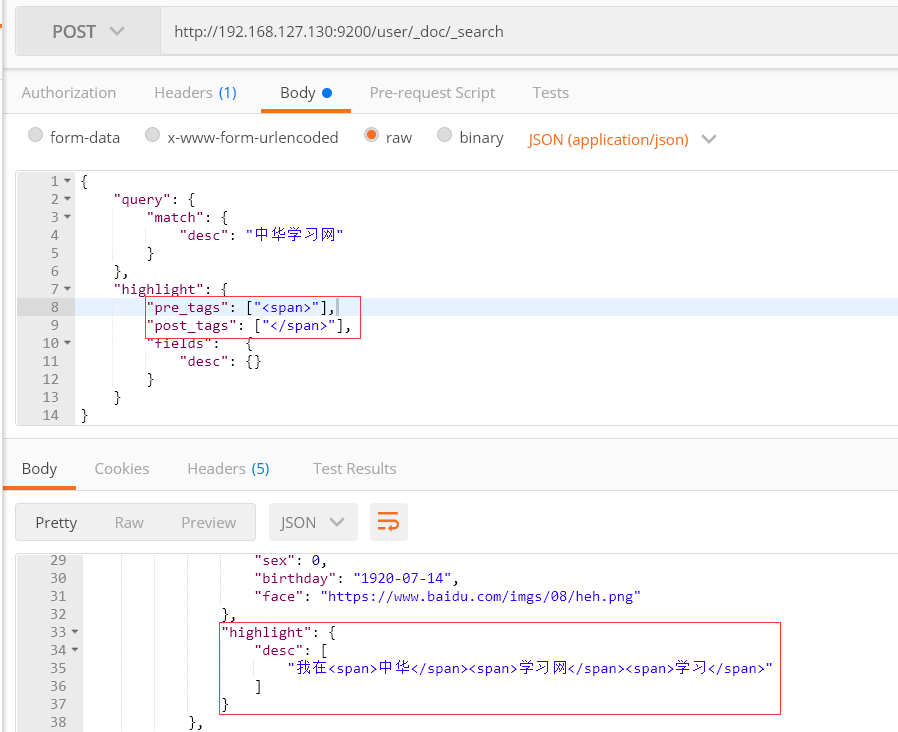
13) 高亮 highlight

默认使用em标签,可以自定义标签,如span
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号