
HBase是一个分布式的数据库
主要作用: 海量数据的存储和海量数据的准实时查询
1、HBase安装说明
JDK1.7以上(JDK安装这里不作介绍)
Hadoop-2.5.0以上。 我这里用的是Hadoop2.6
Zookeeper-3.4.* 以上。 我这里是Zookeeper-3.4.13 参考:Linux下Zookeeper的下载、安装和启动
2、Hadoop2.6.0安装
因为HBase依赖于HDFS,所以先安装Hadoop
下载地址:https://pan.baidu.com/s/1XvL_jas1yVniE-FNQnZNWg
1) 解压 tar -zxvf hadoop-2.6.0.tar.gz
2) 配置hardoop的jdk
cd /root/tools/hadoop-2.6.0/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk/jdk1.8.0_181
3) 修改core-site.xml
cd /root/tools/hadoop-2.6.0/etc/hadoop
vi core-site.xml
cd /root/tools/hadoop-2.6.0
创建 mkdir -p data/tmp
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/tools/hadoop-2.6.0/data/tmp</value>
</property>
</configuration>
4)修改hdfs-site.xml
cd /root/tools/hadoop-2.6.0/etc/hadoop
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
副本数为1, 取消权限
【hadoop 3.2版本】
指定web页面访问地址和端口 dfs.namenode.http-address
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
5) 启动hadoop
在启动前,先进行namenode格式化
cd /root/tools/hadoop-2.6.0/etc/hadoop
bin/hdfs namenode -format

注意:这一步操作,只是在第一次时执行,每次如果格式化的话,那么HDFS上的数据就会被清空
启动hadoop
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
使用jps查看
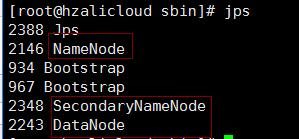
停止hadoop
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop secondarynamenode
6)访问hadoop
http://4x.xx.xx.x20:50070/dfshealth.html#tab-overview
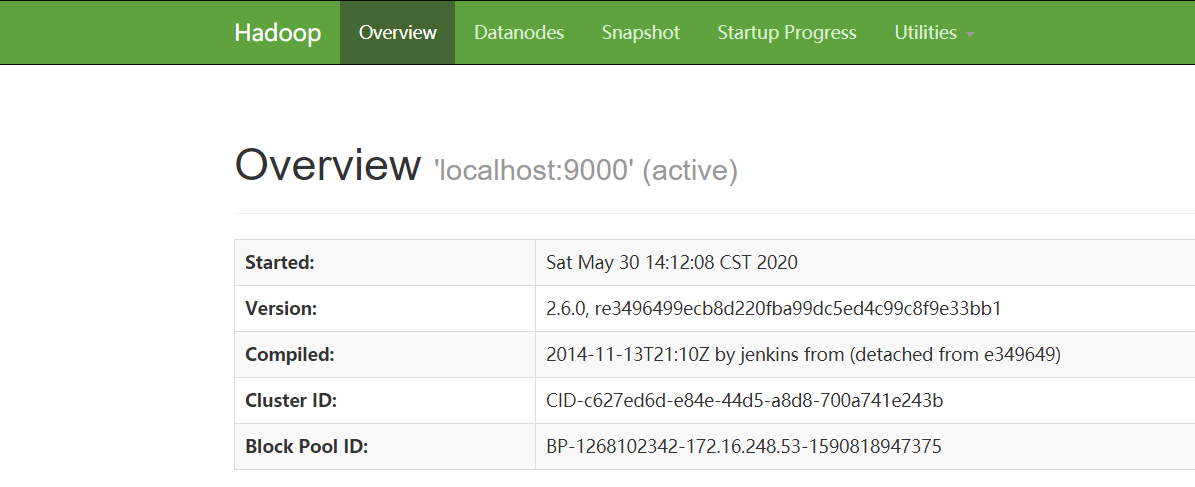
这样hadoop就安装完成了。
7) hdfs shell 常用命令操作
ls, get, mkdir, rm, put
cd ./hadoop fs -ls /
查看文件
./hadoop fs -ls /
创建文件 ./hadoop fs -ls /

创建多层文件夹。如a文件夹下再创建b文件夹
./hadoop fs -mkdir -p /a/b
查看a文件夹下已经有b文件夹了 ./hadoop fs -ls /a

查看指定目录所有的文件结构
./hadoop fs -ls -R /
将hdfs.cmd文件放到刚才新建的test文件夹下
./hadoop fs -put hdfs.cmd /test/
查看test文件夹下的文件./hadoop fs -put hdfs.cmd /test/,可以看到已经有hdfs.cmd这个文件了

查看文件的内容
./hadoop fs -text /test/hdfs.cmd
或者./hadoop fs -cat /test/hdfs.cmd
将hdfs文件拷贝到本地
./hadoop fs -get /test/hdfs.cmd copy_hdfs.cmd

使用浏览器查看我们刚才创建的文件
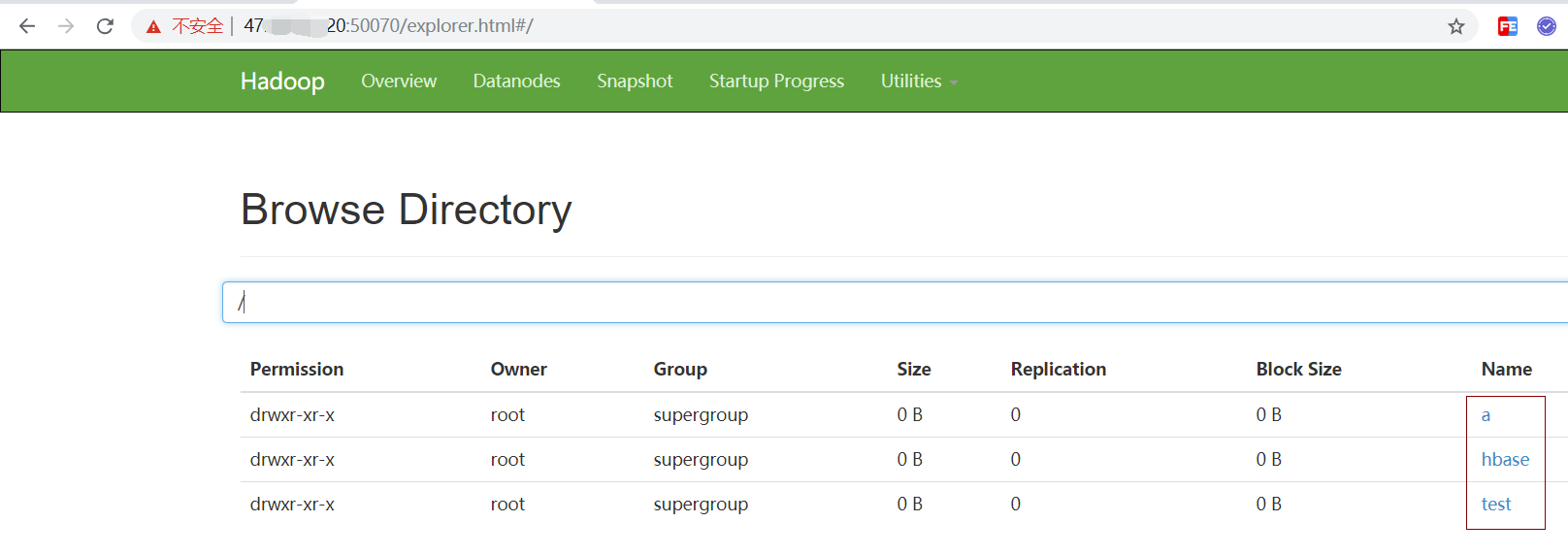
删除文件
./hadoop fs -rm /test/hdfs.cmd
删除文件夹
./hadoop fs -rmr /a
8) HDFS优缺点
优点:
高容错
适合批处理
适合大数据处理
可构建在廉价机器上
缺点:
低延迟的数据访问
小文件存储
[20210130补充]:Hadoop版本选择
1、Apache社区
2、CDH版本(这里选择了cdh5.7.0系列) 国内大概有70%~80%使用该版本 下载地址 http://archive.cloudera.com/cdh5/cdh/5/
cdh-5.7.0 生产或者测试环境选择对应的CDH版本,尾号一定要采用一样的版本。
3、HDP版本 (国内大概有10%使用该版本)
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
作者:Work Hard Work Smart
出处:http://www.cnblogs.com/linlf03/
欢迎任何形式的转载,未经作者同意,请保留此段声明!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号