
Hive 入门
1. Hive 基本概念
1.1 Hive 介绍
- Hive 由 Facebook 开源用于解决海量结构化日志的数据统计;
- Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能;
- 本质是:将 HQL 转化成 MapReduce 程序;
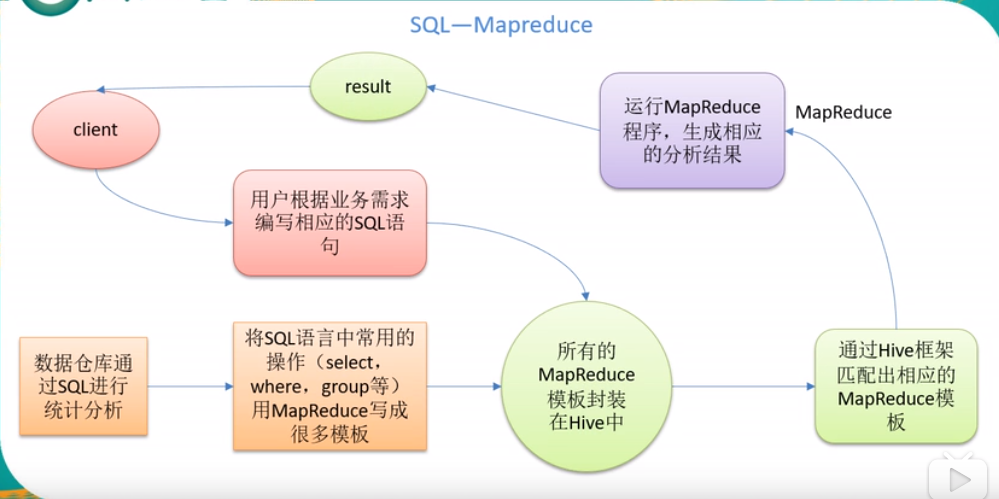
1.2 Hive 架构原理
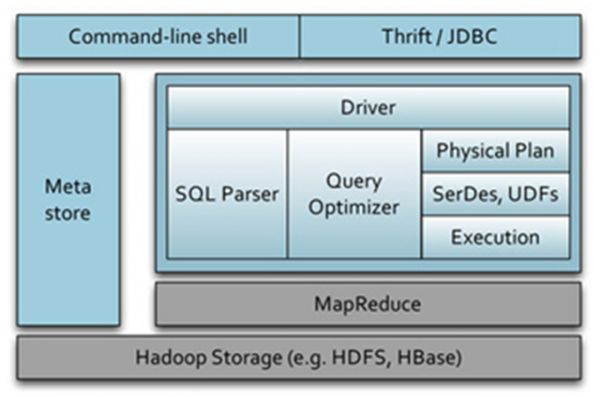
2. Hive 安装与配置
2.1 更改配置文件
// 1. 重命名配置文件
mv hive-default.xml.template hive-site.xml
// 2. 更改配置文件参数
<!--指定存放元数据的数据库名hive(远程mysql数据库)-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://IP地址:3306/hive_metadata?createDatabaseIfNotExsit=true;characterEncoding=UTF-8</value>
</property>
<!--指定DB连接用户名为root: -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--指定DB连接密码为mysql: -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mysql</value>
</property>
<!--指定DB连接引擎:-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--显示查询表的表头信息-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--显示当前数据库-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--修改hive在hdfs上的数据仓库位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/mywarehouse</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/apache-hive-1.2.2-bin/tmp/scratchdir</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hive/apache-hive-1.2.2-bin/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hive/apache-hive-1.2.2-bin/tmp/root/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
// 3. 将所需要的jar包引入到在hive的lib中
mysql-connector-java-5.1.32.jar
// 4. 初始化数据
schematool -dbType mysql -initSchema
2.2 操作Hive
- 启动命令:
bin/hive - 查询数据库:
show databases; - 查询数据库中的表:
show tables; - 查询数据库表中的数据,不启动hive:
bin/hive -e "select * from student"; - 查询数据库表中的数据,不启动hive,使用sql文件:
bin/hive -f hive.sql; - 将本地文件导入Hive:
load data local inpath '文件存放路径' into table 要导入到哪一张表;
// 导入文件的说明:
// 1. 需要在创建表时,指明文件中的分隔符
create table student(id int, name string) row format delimited fields terminated by "\t";
// 2. 创建文件student.txt
1 abc
2 eee
3 mmmm
4 kkkk
// 3. 导入文件
load data local inpath '文件存放路径' into table 要导入到哪一张表;
2.3 使用 JDBC 连接Hive
// 1. 修改配置文件
// 1.1 第一种方式:修改hadoop的core-site.xml
<property>
<name>hadoop.proxyuser.当前使用的用户名.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.当前使用的用户名.hosts</name>
<value>*</value>
</property>
// 1.2 第二种方式:修改hive-site.xml
<property>
<name>hive.server2.enable.doAs</name>
<value>FALSE</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
</description>
</property>
// 2. Hive启动命令
bin/hiveserver2
// 3. 打开一个新的SSH窗口
bin/beeline
!connect jdbc:hive2://Hive IP地址:10000
用户名:root
密码:直接回车
**参考资料:** - [hive修改默认元数据存储数据库derby改为mysql](https://blog.csdn.net/qq_26479655/article/details/52252335) - [Hive配置 远程连接MySQL](https://blog.csdn.net/qq_38799155/article/details/78324663) - [java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D](https://www.cnblogs.com/EnzoDin/p/7376707.html) - [user root cannot impersonate anonymous](https://stackoverflow.com/questions/43180305/cannot-connect-to-hive-using-beeline-user-root-cannot-impersonate-anonymous)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号