

大战设计模式(第二季)【3】———— 从源码看原型模式
前言
对于原型模式比较简单,其实可能我们听到的比较少,但是在实际中其实用到的地方你没有注意。
原型模式基础点:https://www.cnblogs.com/linkstar/p/7810951.html
原型模式用一句话说就是,通过拷贝来创建复杂对象来减少资源开销。
在循环体中产生大量对象的时候比较常用。
需要注意的是原型模式的浅拷贝和深拷贝。
从ArrayList看原型模式
首先我们可以看到ArrayList实现了Cloneable接口
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
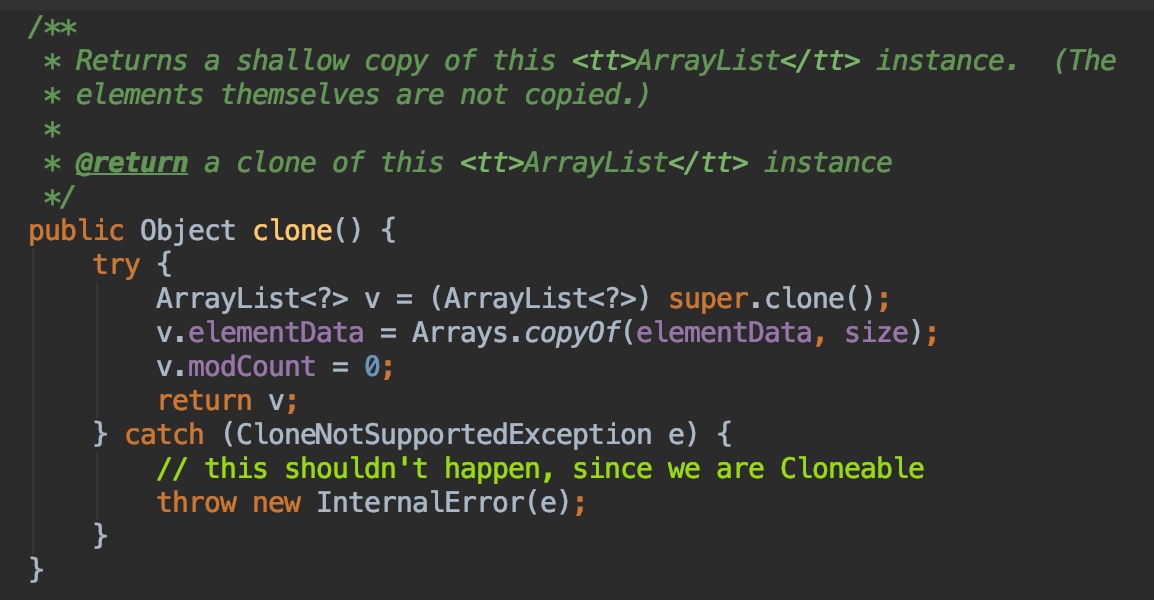 

然后看到重现了clone方法,内部实现的时候注意一个点,使用Arrays.copyOf方法进行数组的拷贝,因为ArrayList内部是数组实现的,并且注意这里重现将modCount赋值为0了。
因为Arrays.copyOf是浅拷贝,所以数组里面的对象还是引用的原地址,这就是一个坑了,我们在使用原型模式的时候,如果有类似ArrayList这样的对象一定要注意。
spring中的原型模式
spring的bean默认是单例模式的,也可以声明为Prototype原型模式,这样每次获取这个对象的时候都会通过原型创建一个新的实例。
在AbstractBeanFactory中有一个doGetBean这个方法,这个方法很长里面记录了bean的创建。有兴趣的朋友请把它看完。
我们这边注意到里面的这一段:
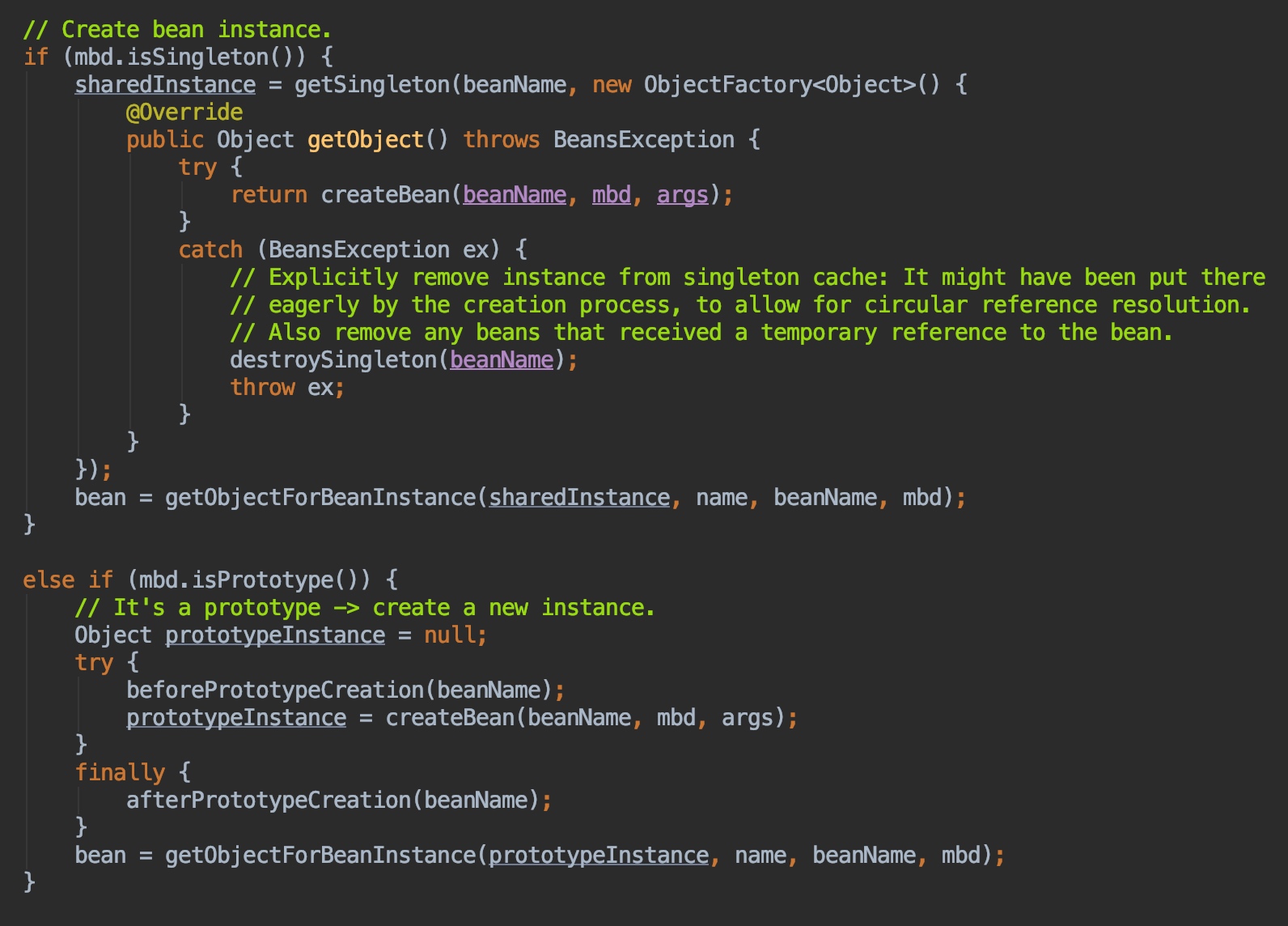 

这一段很容易理解,如果这个bean的定义是单例的,那么就直接通过createBean这个方法去创建这个对象就可以了。
如果这个对象声明的是原型模式,那么就会先创建一个原型实例prototypeInstance然后通过这个原型实例创建bean
从MyBatis看原型模式
// CacheKey.java
@Override
public CacheKey clone() throws CloneNotSupportedException {
CacheKey clonedCacheKey = (CacheKey) super.clone();
clonedCacheKey.updateList = new ArrayList<>(updateList);
return clonedCacheKey;
}
对于缓存CacheKey的clone方法来看,我们可以看到在使用clone创建新的对象的时候,对于内部的updateList需要重新new出来,进行深拷贝。创建出来的对象的使用不能对原对象产生影响,这里一定要注意。
总结
作为原型模式其实比较简单,坑点主要存在于浅拷贝和深拷贝,在创建复杂对象的时候,合理运用一个原型去拷贝生成对象比直接创建来的效率高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号