
scrapy获取页面信息
本例子用命令行调试的方式,演示如何获取页面的特定信息:
0) 示例页面

1) 使用scrapy shell获取目标页面;
scrapy shell http://bj.lianjia.com/ershoufang/pg1tt2/
2)找到提取路径
在页面(本例中使用谷歌浏览器)用F12查看代码,找到要提取目标字段,如第一个房源的地址,在工具下栏有一个css的“路径”:
html body div div ul.sellListContent li.clear div.info.clear div.address div.houseInfo a
使用div后面的css路径,“ul.selListContent li.clear div.info.clear div.address div.houseInfo a”作为response.css函数的输入,如下图,此时已提取到了该页面使用该css的所有数据。

3) 从已选择的数据中进一步提取目标信息
上述得到的结果为一个selector的数组SelectorList,数组的每个元素则对应页面中一个选择到的结果。因此需单独处理每个信息;这里直接使用xpath提取文本信息。提取结果为unicode编码的字符串列表,选择对应的字符串(如本例子中只有一个字符串)。如下:

4) 打印列表信息
至此,目标信息就都找到了,可以使用循环将所有信息打印出来。如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号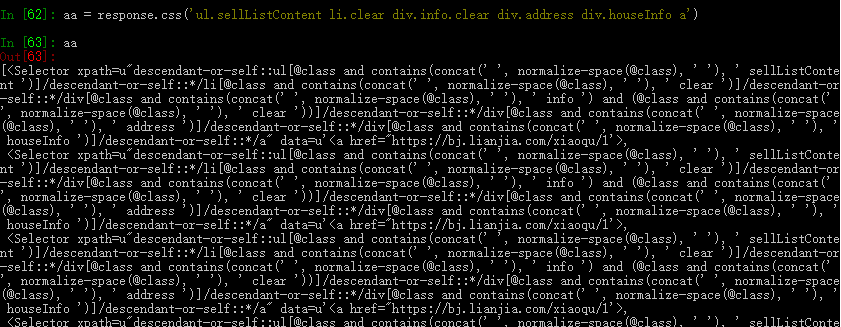{kind=link}