机器学习简介,ALS、LR、GBDT【转载的哦】
【转】https://blog.csdn.net/haozi_rou/article/details/104845317
市面上的主流app,大多数情况下不同的用户看到的页面都是不同的,这里面就有一个推荐的因素了。
那么我们如果想要做推荐,首先需要实现的当然是千人千面,也就是不同的人推荐展示的内容是不一样的,再有就是需要根据场景去推荐。
推荐的方法
基于规则的推荐:可以按照销量、品类等方式来推荐。
基于传统机器学习的推荐:是根据海量的用户的历史行为或门店用户的特征等。当然,上面说的推荐都是基于机器学习的算法。
基于深度学习的推荐:基于神经网络的算法,可以更深层次的发掘用户的诉求,通过不断地反推递归来计算。
推荐模型
规则模型:有明确的规则定义,有简单的算数公式。
机器学习模型训练:数据训练后的算数公式。虽然也有调节的过程,但更多的会依赖历史行为上的数据,只要这些数据足够好,就可以推算出算数公式。
机器学习模型预测:待预测数据经过训练模型算数公式后的结果。例如有用户的基本数据和历史行为,那么就可以拿这些数据跟我们门店的特征共同做训练。算出算数公式。
模型评价指标
离线指标:查全率、查准率、auc(是否预测对的比预测错的更靠前)等
在线指标:点击率、交易转化率等
A/B测试:A组和B组的公式同时测试,看哪个好。
推荐系统架构
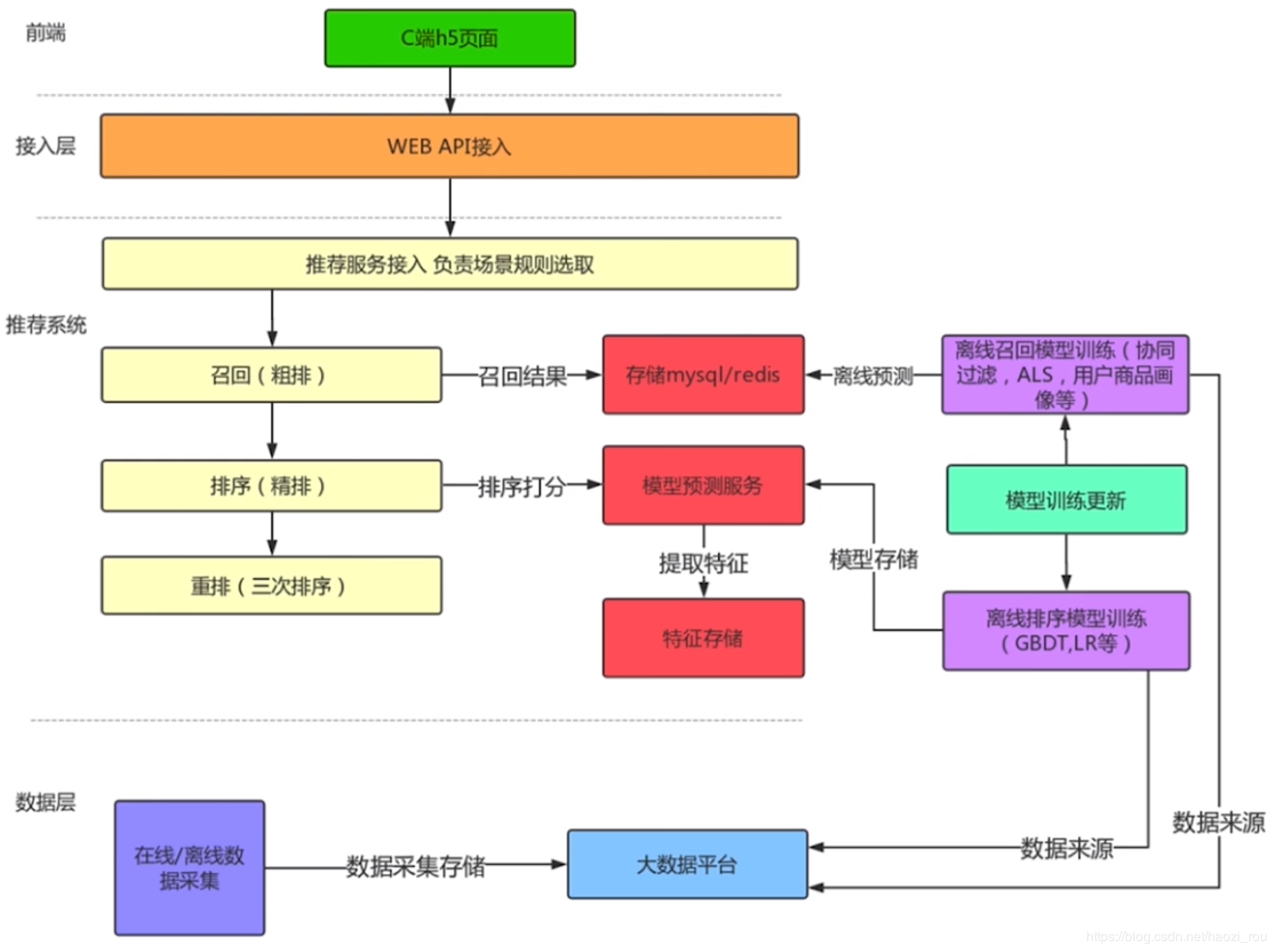
先说一下召回排序和重排,召回相当于根据用户习惯,从一堆数据中心选取其中前100个,然后将前100个商品用另一种算法精排,然后进行第三次排序,这里的重排可以将例如做广告的上架的排序提前。一般三种排序的算法都是不一样的。
再说下数据层,在线数据采集是指用户的行为,例如点击、交易等,离线数据采集是指业务数据库的数据等,这些数据都可以归到大数据平台,供机器学习来使用。离线召回模型是指从大数据平台抽取想要的数据训练的模型。协同过滤大概就是指:AB两个用户的行为都很类似,有一天B新添加了一个商品,那么就把这个商品推荐给A。然后通过模型计算后将数据存到存储设备中,这样,当用户访问的时候,粗排可以从中拿取数据。
个性化召回算法ALS
ALS是最小二乘法,他利用矩阵分解的结果无限逼近现有数据,得到隐含特征。再利用隐含的特征预测其余结果。
先看下表格,4个用户,user2浏览过商品2和商品3,不管浏览了几次,都记做1分,user1购买过商品1,所以在1分的基础上再加2分,也就形成了我们这个矩阵表格。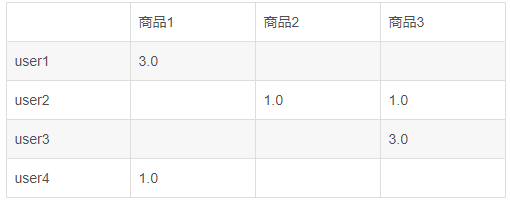
而推荐系统需要做的是挖掘用户的潜在需求,就是预测没有数值的矩阵。这就是ALS要做的事情。
那ALS是怎么做的呢?
有两个表:
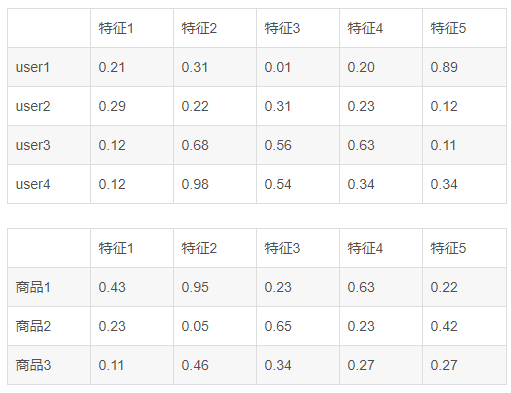
每个user和每个商品都会有五个特征,当然两个表中的特征可以不一样,但是数量必须一样,而且有相对应的打分。然后通过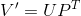
user矩阵和商品p转置矩阵相乘,user1的特征1乘商品1的特征1,最后相加,就会生成一个我们第一个的表格。那么ALS就是通过不断地递归拟合,去逼近现有表格中的分数,从而预测得到其他空格里面的数字。
个性化排序算法LR
LR,也叫逻辑回归。看一个公式:
Y=ax1+bx2+cx3+dx4...
排序的问题在某些意义上也可以看成是点击率预估,公式中x1x2x3这些可以看成是用户的特征,例如x1是年龄,x2是性别等等,在公式中,每个特征都有一个权重abcde等,结果会得到一个Y,越趋近1代表点击概率越大。这是个预测的过程。
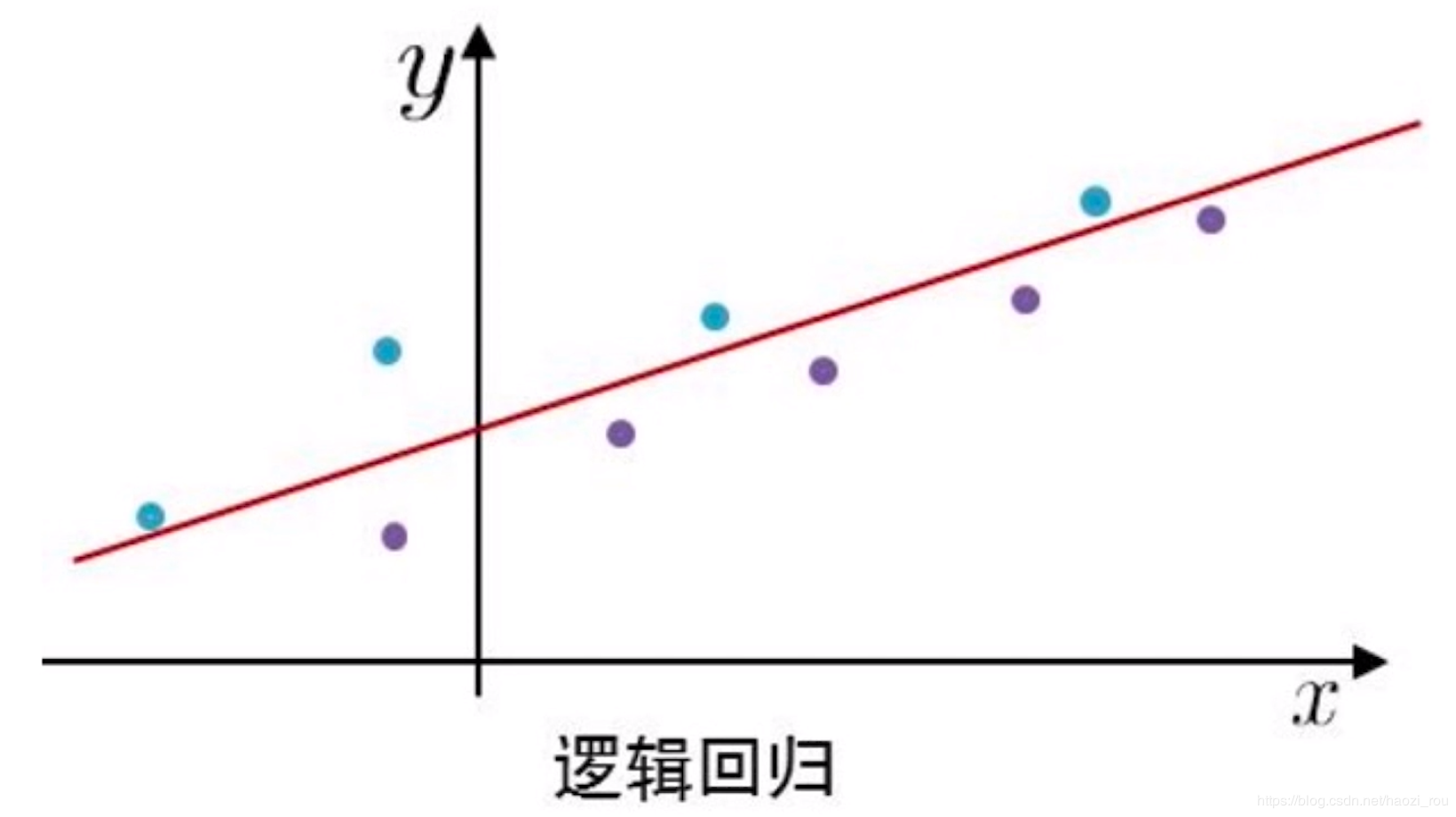
LR算法也就是要算出abcde,在大数据平台会采集Y的样本,可能是1也可能是0,上面途中,蓝色为正样本,紫色为负样本,也lr需要推算出红线,等学习出红线以后,就可以做预测了,新进来一个x点,可以根据红线来推算这个点是正样本的概率大还是负样本的概率大。这就是比较简单的逻辑回归的排序算法原理。
决策树算法
决策树算法,事实上是一个多重分类选择器组合承德结果,也就是输入一个参数,根据这个参数返回1/0,举个例子的话,可以想象成以前杂志上的那种心理测试题。通过多个选择,获得一个结果。
那么如何定义决策树的每个节点的特征呢?原则上越能分出绝大部分特征的越往上。如何衡量?数学上有一个名词叫做信息熵,来衡量信息量的大小,也就是对随机变量不确定的一个衡量,熵越大,不确定性越大。
举个例子,天气有晴天、多云、雨天,温度有冷、热、适中,湿度有高、中等,风有有风、无风,最后有个结果,是否出去玩。
那么我们如何构建这个抉择树?我们选取熵大的节点放在上面,依次往下。离散特征直接按照分类选择器,连续特征可以用二分、三分等分类方式进,例如小20岁,20-40等等。
对于决策树的缺点:样本特征过多时,树的高度太高。样本特征本身有问题时,如果过拟合,会对预测产生偏差。
为了避免决策树的缺点,我们对决策树衍生出了两种算法:随机森林法和GBDT
随机森林:通过随机的选择样本(放回抽样),也就是随机选择几个样本,几个特征,生成一个决策树,放回去再随机选择样本生成决策树,这样就可以生成随机森林。最后在测试阶段,把所有决策树的结果汇总到一起取平均数。
当然,随机的缺点也就是不确定性,既是优势、又是劣势。基于这个,衍生出了另一种算法:GBDT
关于GBDT,顺序为:
从初始训练集中得到一个基准学习器。
用基准学习器预测训练样本并调整做错样本属性的权重。
反复迭代生成T个学习器
T个学习期串行预测加权结合
对于GBDT,它是以第一棵树作为基准,逐步调整,所以这样出来的树也就更准确了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号