python模块
http://www.cnblogs.com/wupeiqi/articles/4963027.html
模块概念:用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
模块分为三种:
1、自定义模块
2、内置模块
3、开源模块
注意:py文件命名时不要跟模块名相同,否则会找不到模块
1、自定义模块
1、导入模块
导入模块方法:
import module from module.xx.xx import xx from module.xx.xx import xx as rename #给导入模块取别名 from module.xx.xx import * #导入module.xx.xx 文件中的所有函数、变量、类等
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys print(sys.path) 打印结果: ['E:\\Lab\\python\\s12\\day6', 'E:\\Lab\\python\\s12', 'E:\\Python\\Python35\\python35.zip', 'E:\\Python\\Python35\\DLLs', 'E:\\Python\\Python35\\lib', 'E:\\Python\\Python35', 'E:\\Python\\Python35\\lib\\site-packages']
#这里会把当前运行的py文件路径、项目根路径、python常用变量添加到sys.path,sys.path返回的是一个列表
例子:
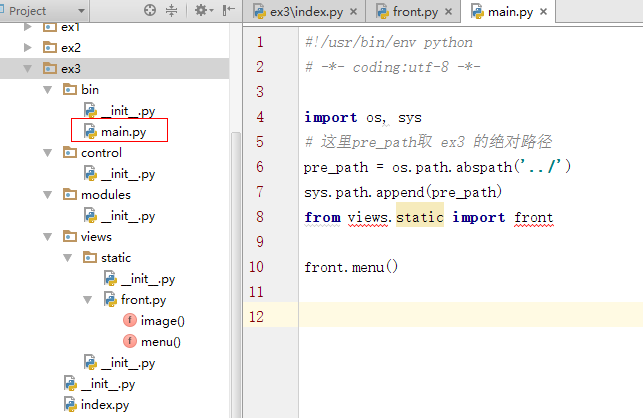
现在目录结构如下:
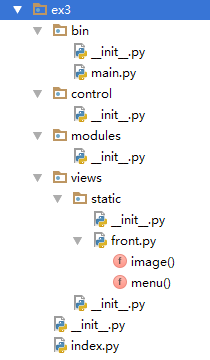
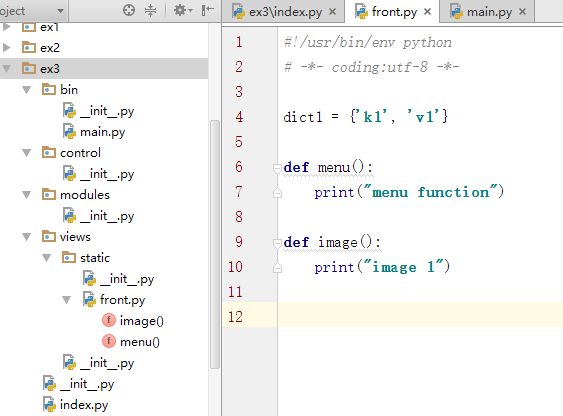
(1)、根目录下的 .py文件里调用子目录 .py文件
注意:from DIR_PATH import py文件或py文件里的函数、类等
import后只能是 py文件或py文件里的
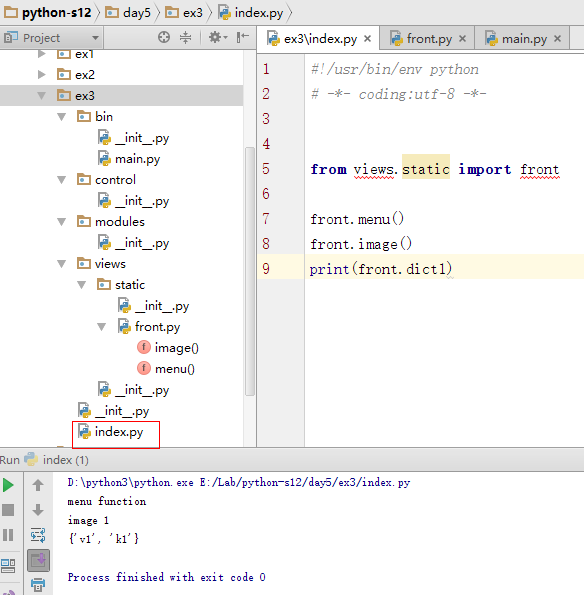
这里也可以只导入某py文件中的某个函数等
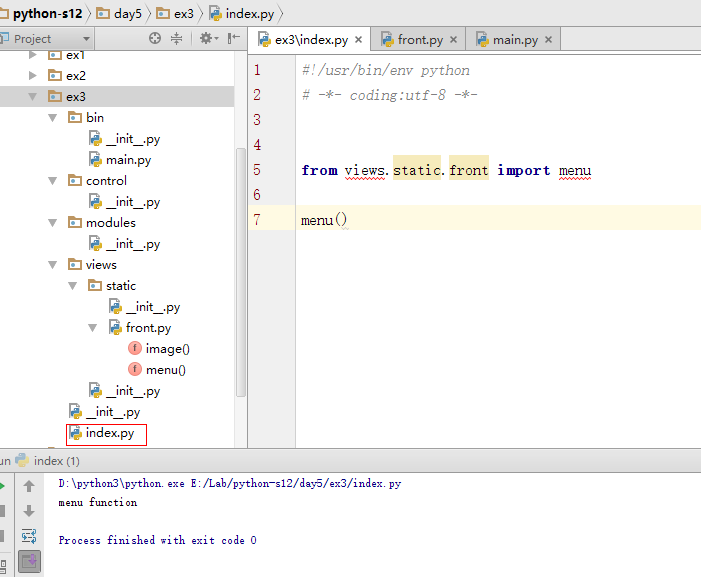
(2)、子目录调用另一个子目录py包
导入包前需要把根路径添加到path环境变量中,否则模块将找不到而报错,此方法仅适用于工作目录py所在目录,即需要在py目录来执行运行。
pre_path = os.path.abspath('../') #获取根的path,os.path.abspath() 这里传当前路径到根路径的相对路径
sys.path.append(pre_path) #将根路径追加到path环境变量中
任意工作目录下获取项目的根路径:
pre_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# __file__ :获取当前py文件的路径
# os.path.abspath(__file__):获取当前py文件的绝对路径
# os.path.dirname(os.path.abspath(__file__)) :获取当前py文件的目录路径
# s.path.dirname(os.path.abspath(__file__)) :获取当前py文件的上一层的目录路径
2、开源模块
下载安装有两种方式:
包管理工具安装
yum
pip
apt-get
2.1 源码安装
下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install
注:在使用源码安装时,需要使用到gcc编译和python开发环境,所以先要安装gcc及python-devvel
yum install gcc
yum install python-devel
或
apt-get python-dev
安装成功后,模块会自动安装到 sys.path 中的某个目录中,如:
/usr/lib/python2.7/site-packages/
2.2 导入模块
导入模块的方式同自定义模块的导入方法
2.3 paramiko模块
paramiko是一个用于做远程控制的模块,使用该模块可以对远程服务器进行命令或文件操作,值得一说的是,fabric和ansible内部的远程管理就是使用的paramiko来现实。
2.3.1 paramiko安装
Centos中安装该模块: pip3 install paramiko
# pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto
# 下载安装 pycryptowget http://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gztar -xvf pycrypto-2.6.1.tar.gzcd pycrypto-2.6.1python setup.py buildpython setup.py install# 进入python环境,导入Crypto检查是否安装成功# 下载安装 paramikowget http://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gztar -xvf paramiko-1.10.1.tar.gzcd paramiko-1.10.1python setup.py buildpython setup.py install# 进入python环境,导入paramiko检查是否安装成功#!/usr/bin/env python #coding:utf-8 import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.1.108', 22, 'alex', '123') stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close();
执行命令--通过密钥连接服务器
需要先配置好ssh_key:
方法:
先在主控端生成ssh-key
ssh-keygen -t rsa #此时会在用户家目录(/root/.ssh)生成两个文件,id_rsa(私钥) id_rsa.pub(公钥)
# id_rsa id_rsa.pub
把公钥复制到被控端
ssh-copy-id -i .ssh/id_rsa.pub "-p 22 root@10.10.50.30" #此时会在目标服务器用户家目录的.ssh目录下生成 authorized_keys
import paramiko private_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(private_key_path) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('主机名 ', 端口, '用户名', key) stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() ssh.close()
上传下载文件--通过用户名和密码
import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test.py','/tmp/test.py') t.close() import os,sys import paramiko t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test.py','/tmp/test2.py') t.close()
上传下载文件--通过密钥
import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.put('/tmp/test3.py','/tmp/test3.py') t.close() import paramiko pravie_key_path = '/home/auto/.ssh/id_rsa' key = paramiko.RSAKey.from_private_key_file(pravie_key_path) t = paramiko.Transport(('182.92.219.86',22)) t.connect(username='wupeiqi',pkey=key) sftp = paramiko.SFTPClient.from_transport(t) sftp.get('/tmp/test3.py','/tmp/test4.py') t.close()
3 内置模块
3.1 os模块
用于提供系统级别的操作
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd
os.curdir #返回当前目录: ('.')
os.pardir # 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') #makedirs(name, mode=0o777, exist_ok=False),可递归生成多层目录,相当于shell下的mkdir -p
os.removedirs('path') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推。如 os.makedirs('dir1/dir2'),os.removedirs('dir1/dir2'),若dir1、dir2均为空上当时,将删除dir1及dir1/dir2
os.mkdir('path') #os.mkdir(path ,mode=0o777) 生成单级目录;相当于shell中mkdir dirname
os.rmdir('path') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(path) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove(path) #删除一个文件
os.rename('src', 'dst') #重命名文件/目录 os.renames('old', 'new') 有相同功能
os.stat(path) #获取文件/目录信息
os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep #输出用于分割文件路径的字符串 win下为";", Linux下为":"
os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system(command) #运行shell命令command,直接显示并显示执行状态,成功为0,每执行个os.system(command)新开一个shell临时进程
os.environ #获取操作系统环境变量
os.path.abspath(path) #返回path规范化的绝对路径
os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.split('path')[0] 可获取父路径
os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) #如果path是绝对路径,返回True
os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(filename) #返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(filename) 返回path所指向的文件或者目录的最后修改时间、
os.path.getctime(filename) #返回path所指向的文件或者目录的创建时间
os.path.getsize(filename) #返回path所指向的文件或者目录的大小
os.popen(command)
a = os.popen("dir").read() # a = 执行执行命令dir的结果
b = os.system("dir") # a = 执行命令dir的状态,正常执行后的状态为0
更多猛击这里
3.2 sys模块
sys.argv #获取命令行参数List,第一个元素是程序本身路径
sys.exit(n) #sys.exit(status=None) 退出程序,正常退出时exit(0)
sys.version #获取Python解释程序的版本信息
sys.maxsize #最大的Int值 2.x 为sys.maxint
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform #返回操作系统平台名称.win-->'win32' linux -->'linux2'
sys.stdout.wirte('please:') #输出
val = sys.stdin.readline()[:-1] #从行读取并去掉回车符
更多猛击这里
进度条小程序:
import time, sys for i in range(10): sys.stdout.write(">") sys.stdout.flush() time.sleep(0.3)
3.3 hashlib模块
用于加密相关的操作,代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
md5--废弃(deprecated)
import md5 hash = md5.new() hash.update('admin') print hash.hexdigest()
#打印结果:21232f297a57a5a743894a0e4a801fc3
sha--废弃(deprecated)
import sha hash = sha.new() hash.update('admin') print hash.hexdigest() #打印结果:d033e22ae348aeb5660fc2140aec35850c4da997
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5() m.update(b"Hello") m.update(b"It's me") print(m.digest()) #b']\xde\xb4{/\x92Z\xd0\xbf$\x9cR\xe3Br\x8a' m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash #b'\xa0\xe9\x89E\x03\xcb\x9f\x1a\x14\xaa\x07?<\xae\xfa\xa5' print(len(m.hexdigest())) #16进制格式hash #32 # md5 h_md5 = hashlib.md5() h_md5.update(b'admin') #python 3.x 需要转二进制,python 2.x 直接使用h_md5.update('admin'),Unicode-objects must be encoded before hashing print(h_md5.hexdigest()) #21232f297a57a5a743894a0e4a801fc3 # sha1 h_sha1 = hashlib.sha1() h_sha1.update(b'admin') #h_sha1.update('admin'.encode('utf-8')) print(h_sha1.hexdigest()) #d033e22ae348aeb5660fc2140aec35850c4da997 # sha224 h_sha224 = hashlib.sha224() h_sha224.update(b'admin') print(h_sha224.hexdigest()) #58acb7acccce58ffa8b953b12b5a7702bd42dae441c1ad85057fa70b # sha256 h_sha256 = hashlib.sha256() h_sha256.update(b'admin') print(h_sha256.hexdigest()) #8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918 # sha384 h_sha384 = hashlib.sha384() h_sha384.update(b'admin') print(h_sha384.hexdigest()) #9ca694a90285c034432c9550421b7b9dbd5c0f4b6673f05f6dbce58052ba20e4248041956ee8c9a2ec9f10290cdc0782 # sha512 h_sha512 = hashlib.sha512() h_sha512.update(b'admin') print(h_sha512.hexdigest()) #c7ad44cbad762a5da0a452f9e854fdc1e0e7a52a38015f23f3eab1d80b931dd472634dfac71cd34ebc35d16ab7fb8a90c81f975113d6c7538dc69dd8de9077ec
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib # md5 h_m = hashlib.md5(b'mykey_1001') h_m.update(b'admin') print(h_m.hexdigest()) #f4e45c78302ae746e0b20c4ad1b889a6
还不够叼?python 还有一个 hmac 模块,它内部先对我们创建的key 和 内容 进行处理,然后再加密
import hmac h = hmac.new(b'jiami') h.update(b'hello') print(h.hexdigest()) #96e8ad3c5dc8c1eeb0bf510f40d0393e
更多关于md5,sha1,sha256等介绍的文章看这里 https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
3.4 json 和 pickle
用于义序列化
json:用于字符串 和 python数据类型间进行转换(可与其他语言通用,仅能序列化基本的数据库类型如字符串,字典。像函数等这些就不行了)
pickle:用于python特有的类型 和 python的数据类型间进行转换(python特有,与其他语言不通用,可把字符串、字典、函数、类等写入文件)
json、pickle模块都提供了4个功能:dumps、dump、loads、load
pickle向同个文件dump了n次,那么再load n次按原来的存入顺序读出
#!/usr/bin/env python # -*- coding:utf-8 -*- import json, pickle data = {'k1':123, 'k2':'hello'} ## json # json.dumps 将数据通过特殊的形式转换为所有程序都识别的字符串 j_str = json.dumps(data) print(j_str) #{"k2": "hello", "k1": 123} # json.loads 读取json.dumps特殊处理后的数据并返回该对象 j_str_loads = json.loads(j_str) print(j_str_loads) #{'k2': 'hello', 'k1': 123} # json.dump 将数据通过特殊的形式转换为所有程序都识别的字符串,并写入文件 with open('file.json', 'w') as fp: json.dump(data, fp) with open('file.json', 'r') as fp: data_j_load = json.load(fp) print(data_j_load) #{'k2': 'hello', 'k1': 123} ## pickle # pickle.dumps将数据通过特殊的形式转换成只有python语言能识别的字符串 p_str = pickle.dumps(data) print(p_str) #b'\x80\x03}q\x00(X\x02\x00\x00\x00k2q\x01X\x05\x00\x00\x00helloq\x02X\x02\x00\x00\x00k1q\x03K{u.' # pickle.loads 读取pickle.dumps特殊处理后的数据并返回该对象 p_loads = pickle.loads(p_str) print(p_loads) #{'k2': 'hello', 'k1': 123} # pickle.dump将数据通过特殊的形式转换成只有python语言识别的字符串,并写入文件 with open('file.pickle', 'wb') as fp: pickle.dump(data, fp) # pickle.loads 从文件中读取pickle.dumps特殊处理后的数据并返回该对象 with open('file.pickle', 'rb') as fp: data_p_load = pickle.load(fp) print(data_p_load) #{'k2': 'hello', 'k1': 123}
3.5 subprocess模块
用于执行复杂的系统命令
可执行系统命令
可以执行shell命令的相关模块和函数有:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
commands模块(3.x 已移除)
import commands
result1 = commands.getoutput('ls')
result2 = commands.getstatus('filename')
result3 = commands.getstatusoutput('hostname')
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes. This module intends to replace several older modules and functions:
os.system
os.spawn*
The recommended approach to invoking subprocesses is to use the run() function for all use cases it can handle. For more advanced use cases, the underlying Popen interface can be used directly.
The run() function was added in Python 3.5; if you need to retain compatibility with older versions, see the Older high-level API section.
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False)Run the command described by args. Wait for command to complete, then return a CompletedProcess instance.
The arguments shown above are merely the most common ones, described below in Frequently Used Arguments (hence the use of keyword-only notation in the abbreviated signature). The full function signature is largely the same as that of the Popen constructor - apart from timeout, input and check, all the arguments to this function are passed through to that interface.
This does not capture stdout or stderr by default. To do so, pass PIPE for the stdout and/or stderr arguments.
The timeout argument is passed to Popen.communicate(). If the timeout expires, the child process will be killed and waited for. The TimeoutExpired exception will be re-raised after the child process has terminated.
The input argument is passed to Popen.communicate() and thus to the subprocess’s stdin. If used it must be a byte sequence, or a string if universal_newlines=True. When used, the internal Popen object is automatically created withstdin=PIPE, and the stdin argument may not be used as well.
If check is True, and the process exits with a non-zero exit code, a CalledProcessError exception will be raised. Attributes of that exception hold the arguments, the exit code, and stdout and stderr if they were captured.
subprocess.run()
subprocess.run(["ls", "-l"]) # doesn't capture output(不捕获输出) subprocess.run("exit 1", shell=True, check=True) '''#运行提示: Traceback (most recent call last): ... subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1) ''' subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE) '''#运行提示: CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0, stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null\n') '''
subprocess.call()
执行命令,返回状态码
ret = subprocess.call(["ls", "-l"], shell=False) ret = subprocess.call("ls -l", shell=True) #shell = True ,允许 shell 命令是字符串形式
subprocess.check_call()
执行命令,如果执行状态码是 0 ,则返回0,否则抛异常
subprocess.check_call(["ls", "-l"])
subprocess.check_call("exit 1", shell=True)
subprocess.check_output()
执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常
subprocess.check_output(["echo", "Hello World!"]) subprocess.check_output("exit 1", shell=True)
subprocess.Popen(...)
用于执行复杂的系统命令
参数:
args:shell命令,可以是字符串或者序列类型(如:list,元组)
bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。
shell:同上
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
执行普通命令:
import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) ret2 = subprocess.Popen("mkdir t2", shell=True)
终端输入的命令分为两种:
输入即可得到输出,如:ifconfig
输入进行某环境依赖,再输入,如:python
import subprocess obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) obj.stdin.write('print 1 \n ') obj.stdin.write('print 2 \n ') obj.stdin.write('print 3 \n ') obj.stdin.write('print 4 \n ') obj.stdin.close() cmd_out = obj.stdout.read() obj.stdout.close() cmd_error = obj.stderr.read() obj.stderr.close() print cmd_out print cmd_error
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write(b"print(1)\n")
obj.stdin.write(b"print(2)\n")
obj.stdin.write(b"print(3)\n")
obj.stdin.write(b"print(4)\n")
out_error_list = obj.communicate(timeout=10)
print(out_error_list) #(b'1\r\n2\r\n3\r\n4\r\n', b'')
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) out_error_list = obj.communicate('print "hello"') print out_error_list
捕获执行命令的显示的结果:
a = subprocess.Popen("ipconfig /a", shell=True, stdout=subprocess.PIPE) #使用PIPE管道 print(a.stdout.read())
更多猛击这里
3.6 shutil模块
文件、文件夹、压缩包 处理模块的高级处理(复制、压缩、解压缩=)
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中,可以部分内容


def copyfileobj(fsrc, fdst, length=16*1024): """copy data from file-like object fsrc to file-like object fdst""" while 1: buf = fsrc.read(length) if not buf: break fdst.write(buf)
shutil.copyfileobj 例子:
import shutil with open('f1.txt', 'r') as f1, open('f2.txt', 'a') as f2: shutil.copyfileobj(f1, f2)
shutil.copyfile(src, dst)
拷贝文件
def copyfile(src, dst): """Copy data from src to dst""" if _samefile(src, dst): raise Error("`%s` and `%s` are the same file" % (src, dst)) for fn in [src, dst]: try: st = os.stat(fn) except OSError: # File most likely does not exist pass else: # XXX What about other special files? (sockets, devices...) if stat.S_ISFIFO(st.st_mode): raise SpecialFileError("`%s` is a named pipe" % fn) with open(src, 'rb') as fsrc: with open(dst, 'wb') as fdst: copyfileobj(fsrc, fdst)
shutil.copyfile 例子:
import shutil shutil.copyfile('f1.txt', 'f3.txt')
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户信息均不变
def copymode(src, dst): """Copy mode bits from src to dst""" if hasattr(os, 'chmod'): st = os.stat(src) mode = stat.S_IMODE(st.st_mode) os.chmod(dst, mode)
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
def copystat(src, dst): """Copy all stat info (mode bits, atime, mtime, flags) from src to dst""" st = os.stat(src) mode = stat.S_IMODE(st.st_mode) if hasattr(os, 'utime'): os.utime(dst, (st.st_atime, st.st_mtime)) if hasattr(os, 'chmod'): os.chmod(dst, mode) if hasattr(os, 'chflags') and hasattr(st, 'st_flags'): try: os.chflags(dst, st.st_flags) except OSError, why: for err in 'EOPNOTSUPP', 'ENOTSUP': if hasattr(errno, err) and why.errno == getattr(errno, err): break else: raise
shutil.copy(src, dst)
拷贝文件和权限
def copy(src, dst): """Copy data and mode bits ("cp src dst"). The destination may be a directory. """ if os.path.isdir(dst): dst = os.path.join(dst, os.path.basename(src)) copyfile(src, dst) copymode(src, dst)
shutil.copy2(src, dst)
拷贝文件和状态信息
def copy2(src, dst): """Copy data and all stat info ("cp -p src dst"). The destination may be a directory. """ if os.path.isdir(dst): dst = os.path.join(dst, os.path.basename(src)) copyfile(src, dst) copystat(src, dst) 复制代码
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件
例如:copytree(source, destination, ignore=ignore_patterns('*.pyc', 'tmp*'))
def copytree(src, dst, symlinks=False, ignore=None): """Recursively copy a directory tree using copy2(). The destination directory must not already exist. If exception(s) occur, an Error is raised with a list of reasons. If the optional symlinks flag is true, symbolic links in the source tree result in symbolic links in the destination tree; if it is false, the contents of the files pointed to by symbolic links are copied. The optional ignore argument is a callable. If given, it is called with the `src` parameter, which is the directory being visited by copytree(), and `names` which is the list of `src` contents, as returned by os.listdir(): callable(src, names) -> ignored_names Since copytree() is called recursively, the callable will be called once for each directory that is copied. It returns a list of names relative to the `src` directory that should not be copied. XXX Consider this example code rather than the ultimate tool. """ names = os.listdir(src) if ignore is not None: ignored_names = ignore(src, names) else: ignored_names = set() os.makedirs(dst) errors = [] for name in names: if name in ignored_names: continue srcname = os.path.join(src, name) dstname = os.path.join(dst, name) try: if symlinks and os.path.islink(srcname): linkto = os.readlink(srcname) os.symlink(linkto, dstname) elif os.path.isdir(srcname): copytree(srcname, dstname, symlinks, ignore) else: # Will raise a SpecialFileError for unsupported file types copy2(srcname, dstname) # catch the Error from the recursive copytree so that we can # continue with other files except Error, err: errors.extend(err.args[0]) except EnvironmentError, why: errors.append((srcname, dstname, str(why))) try: copystat(src, dst) except OSError, why: if WindowsError is not None and isinstance(why, WindowsError): # Copying file access times may fail on Windows pass else: errors.append((src, dst, str(why))) if errors: raise Error, errors
shutil.ignore_patterns(*patterns)
功能相当于shutil.copytree的ignore参数,可用作排除某些文件及文件类型等
def ignore_patterns(*patterns): """Function that can be used as copytree() ignore parameter. Patterns is a sequence of glob-style patterns that are used to exclude files""" def _ignore_patterns(path, names): ignored_names = [] for pattern in patterns: ignored_names.extend(fnmatch.filter(names, pattern)) return set(ignored_names) return _ignore_patterns
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
def rmtree(path, ignore_errors=False, onerror=None): """Recursively delete a directory tree. If ignore_errors is set, errors are ignored; otherwise, if onerror is set, it is called to handle the error with arguments (func, path, exc_info) where func is platform and implementation dependent; path is the argument to that function that caused it to fail; and exc_info is a tuple returned by sys.exc_info(). If ignore_errors is false and onerror is None, an exception is raised. """ if ignore_errors: def onerror(*args): pass elif onerror is None: def onerror(*args): raise if _use_fd_functions: # While the unsafe rmtree works fine on bytes, the fd based does not. if isinstance(path, bytes): path = os.fsdecode(path) # Note: To guard against symlink races, we use the standard # lstat()/open()/fstat() trick. try: orig_st = os.lstat(path) except Exception: onerror(os.lstat, path, sys.exc_info()) return try: fd = os.open(path, os.O_RDONLY) except Exception: onerror(os.lstat, path, sys.exc_info()) return try: if os.path.samestat(orig_st, os.fstat(fd)): _rmtree_safe_fd(fd, path, onerror) try: os.rmdir(path) except OSError: onerror(os.rmdir, path, sys.exc_info()) else: try: # symlinks to directories are forbidden, see bug #1669 raise OSError("Cannot call rmtree on a symbolic link") except OSError: onerror(os.path.islink, path, sys.exc_info()) finally: os.close(fd) else: return _rmtree_unsafe(path, onerror)
shutil.move(src, dst)
递归的去移动文件
def move(src, dst, copy_function=copy2): """Recursively move a file or directory to another location. This is similar to the Unix "mv" command. Return the file or directory's destination. If the destination is a directory or a symlink to a directory, the source is moved inside the directory. The destination path must not already exist. If the destination already exists but is not a directory, it may be overwritten depending on os.rename() semantics. If the destination is on our current filesystem, then rename() is used. Otherwise, src is copied to the destination and then removed. Symlinks are recreated under the new name if os.rename() fails because of cross filesystem renames. The optional `copy_function` argument is a callable that will be used to copy the source or it will be delegated to `copytree`. By default, copy2() is used, but any function that supports the same signature (like copy()) can be used. A lot more could be done here... A look at a mv.c shows a lot of the issues this implementation glosses over. """ real_dst = dst if os.path.isdir(dst): if _samefile(src, dst): # We might be on a case insensitive filesystem, # perform the rename anyway. os.rename(src, dst) return real_dst = os.path.join(dst, _basename(src)) if os.path.exists(real_dst): raise Error("Destination path '%s' already exists" % real_dst) try: os.rename(src, real_dst) except OSError: if os.path.islink(src): linkto = os.readlink(src) os.symlink(linkto, real_dst) os.unlink(src) elif os.path.isdir(src): if _destinsrc(src, dst): raise Error("Cannot move a directory '%s' into itself" " '%s'." % (src, dst)) copytree(src, real_dst, copy_function=copy_function, symlinks=True) rmtree(src) else: copy_function(src, real_dst) os.unlink(src) return real_dst
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
参数:
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
例子:
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录 import shutil ret = shutil.make_archive("test.tar.gz", 'gztar', root_dir='/Users/wupeiqi/Downloads/test') #将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录 import shutil ret = shutil.make_archive("/Users/wupeiqi/test.tar.gz", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
def make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, dry_run=0, owner=None, group=None, logger=None): """Create an archive file (eg. zip or tar). 'base_name' is the name of the file to create, minus any format-specific extension; 'format' is the archive format: one of "zip", "tar", "bztar" or "gztar". 'root_dir' is a directory that will be the root directory of the archive; ie. we typically chdir into 'root_dir' before creating the archive. 'base_dir' is the directory where we start archiving from; ie. 'base_dir' will be the common prefix of all files and directories in the archive. 'root_dir' and 'base_dir' both default to the current directory. Returns the name of the archive file. 'owner' and 'group' are used when creating a tar archive. By default, uses the current owner and group. """ save_cwd = os.getcwd() if root_dir is not None: if logger is not None: logger.debug("changing into '%s'", root_dir) base_name = os.path.abspath(base_name) if not dry_run: os.chdir(root_dir) if base_dir is None: base_dir = os.curdir kwargs = {'dry_run': dry_run, 'logger': logger} try: format_info = _ARCHIVE_FORMATS[format] except KeyError: raise ValueError("unknown archive format '%s'" % format) func = format_info[0] for arg, val in format_info[1]: kwargs[arg] = val if format != 'zip': kwargs['owner'] = owner kwargs['group'] = group try: filename = func(base_name, base_dir, **kwargs) finally: if root_dir is not None: if logger is not None: logger.debug("changing back to '%s'", save_cwd) os.chdir(save_cwd) return filename
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩解压:
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall() z.close()
tarfile压缩解压
import tarfile # 压缩 tar = tarfile.open('your.tar','w') tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip') tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip') tar.close() # 解压 tar = tarfile.open('your.tar','r') tar.extractall() # 可设置解压地址 tar.close()
zipfile源码:
""" Read and write ZIP files. XXX references to utf-8 need further investigation. """ import io import os import re import importlib.util import sys import time import stat import shutil import struct import binascii try: import threading except ImportError: import dummy_threading as threading try: import zlib # We may need its compression method crc32 = zlib.crc32 except ImportError: zlib = None crc32 = binascii.crc32 try: import bz2 # We may need its compression method except ImportError: bz2 = None try: import lzma # We may need its compression method except ImportError: lzma = None __all__ = ["BadZipFile", "BadZipfile", "error", "ZIP_STORED", "ZIP_DEFLATED", "ZIP_BZIP2", "ZIP_LZMA", "is_zipfile", "ZipInfo", "ZipFile", "PyZipFile", "LargeZipFile"] class BadZipFile(Exception): pass class LargeZipFile(Exception): """ Raised when writing a zipfile, the zipfile requires ZIP64 extensions and those extensions are disabled. """ error = BadZipfile = BadZipFile # Pre-3.2 compatibility names ZIP64_LIMIT = (1 << 31) - 1 ZIP_FILECOUNT_LIMIT = (1 << 16) - 1 ZIP_MAX_COMMENT = (1 << 16) - 1 # constants for Zip file compression methods ZIP_STORED = 0 ZIP_DEFLATED = 8 ZIP_BZIP2 = 12 ZIP_LZMA = 14 # Other ZIP compression methods not supported DEFAULT_VERSION = 20 ZIP64_VERSION = 45 BZIP2_VERSION = 46 LZMA_VERSION = 63 # we recognize (but not necessarily support) all features up to that version MAX_EXTRACT_VERSION = 63 # Below are some formats and associated data for reading/writing headers using # the struct module. The names and structures of headers/records are those used # in the PKWARE description of the ZIP file format: # http://www.pkware.com/documents/casestudies/APPNOTE.TXT # (URL valid as of January 2008) # The "end of central directory" structure, magic number, size, and indices # (section V.I in the format document) structEndArchive = b"<4s4H2LH" stringEndArchive = b"PK\005\006" sizeEndCentDir = struct.calcsize(structEndArchive) _ECD_SIGNATURE = 0 _ECD_DISK_NUMBER = 1 _ECD_DISK_START = 2 _ECD_ENTRIES_THIS_DISK = 3 _ECD_ENTRIES_TOTAL = 4 _ECD_SIZE = 5 _ECD_OFFSET = 6 _ECD_COMMENT_SIZE = 7 # These last two indices are not part of the structure as defined in the # spec, but they are used internally by this module as a convenience _ECD_COMMENT = 8 _ECD_LOCATION = 9 # The "central directory" structure, magic number, size, and indices # of entries in the structure (section V.F in the format document) structCentralDir = "<4s4B4HL2L5H2L" stringCentralDir = b"PK\001\002" sizeCentralDir = struct.calcsize(structCentralDir) # indexes of entries in the central directory structure _CD_SIGNATURE = 0 _CD_CREATE_VERSION = 1 _CD_CREATE_SYSTEM = 2 _CD_EXTRACT_VERSION = 3 _CD_EXTRACT_SYSTEM = 4 _CD_FLAG_BITS = 5 _CD_COMPRESS_TYPE = 6 _CD_TIME = 7 _CD_DATE = 8 _CD_CRC = 9 _CD_COMPRESSED_SIZE = 10 _CD_UNCOMPRESSED_SIZE = 11 _CD_FILENAME_LENGTH = 12 _CD_EXTRA_FIELD_LENGTH = 13 _CD_COMMENT_LENGTH = 14 _CD_DISK_NUMBER_START = 15 _CD_INTERNAL_FILE_ATTRIBUTES = 16 _CD_EXTERNAL_FILE_ATTRIBUTES = 17 _CD_LOCAL_HEADER_OFFSET = 18 # The "local file header" structure, magic number, size, and indices # (section V.A in the format document) structFileHeader = "<4s2B4HL2L2H" stringFileHeader = b"PK\003\004" sizeFileHeader = struct.calcsize(structFileHeader) _FH_SIGNATURE = 0 _FH_EXTRACT_VERSION = 1 _FH_EXTRACT_SYSTEM = 2 _FH_GENERAL_PURPOSE_FLAG_BITS = 3 _FH_COMPRESSION_METHOD = 4 _FH_LAST_MOD_TIME = 5 _FH_LAST_MOD_DATE = 6 _FH_CRC = 7 _FH_COMPRESSED_SIZE = 8 _FH_UNCOMPRESSED_SIZE = 9 _FH_FILENAME_LENGTH = 10 _FH_EXTRA_FIELD_LENGTH = 11 # The "Zip64 end of central directory locator" structure, magic number, and size structEndArchive64Locator = "<4sLQL" stringEndArchive64Locator = b"PK\x06\x07" sizeEndCentDir64Locator = struct.calcsize(structEndArchive64Locator) # The "Zip64 end of central directory" record, magic number, size, and indices # (section V.G in the format document) structEndArchive64 = "<4sQ2H2L4Q" stringEndArchive64 = b"PK\x06\x06" sizeEndCentDir64 = struct.calcsize(structEndArchive64) _CD64_SIGNATURE = 0 _CD64_DIRECTORY_RECSIZE = 1 _CD64_CREATE_VERSION = 2 _CD64_EXTRACT_VERSION = 3 _CD64_DISK_NUMBER = 4 _CD64_DISK_NUMBER_START = 5 _CD64_NUMBER_ENTRIES_THIS_DISK = 6 _CD64_NUMBER_ENTRIES_TOTAL = 7 _CD64_DIRECTORY_SIZE = 8 _CD64_OFFSET_START_CENTDIR = 9 def _check_zipfile(fp): try: if _EndRecData(fp): return True # file has correct magic number except OSError: pass return False def is_zipfile(filename): """Quickly see if a file is a ZIP file by checking the magic number. The filename argument may be a file or file-like object too. """ result = False try: if hasattr(filename, "read"): result = _check_zipfile(fp=filename) else: with open(filename, "rb") as fp: result = _check_zipfile(fp) except OSError: pass return result def _EndRecData64(fpin, offset, endrec): """ Read the ZIP64 end-of-archive records and use that to update endrec """ try: fpin.seek(offset - sizeEndCentDir64Locator, 2) except OSError: # If the seek fails, the file is not large enough to contain a ZIP64 # end-of-archive record, so just return the end record we were given. return endrec data = fpin.read(sizeEndCentDir64Locator) if len(data) != sizeEndCentDir64Locator: return endrec sig, diskno, reloff, disks = struct.unpack(structEndArchive64Locator, data) if sig != stringEndArchive64Locator: return endrec if diskno != 0 or disks != 1: raise BadZipFile("zipfiles that span multiple disks are not supported") # Assume no 'zip64 extensible data' fpin.seek(offset - sizeEndCentDir64Locator - sizeEndCentDir64, 2) data = fpin.read(sizeEndCentDir64) if len(data) != sizeEndCentDir64: return endrec sig, sz, create_version, read_version, disk_num, disk_dir, \ dircount, dircount2, dirsize, diroffset = \ struct.unpack(structEndArchive64, data) if sig != stringEndArchive64: return endrec # Update the original endrec using data from the ZIP64 record endrec[_ECD_SIGNATURE] = sig endrec[_ECD_DISK_NUMBER] = disk_num endrec[_ECD_DISK_START] = disk_dir endrec[_ECD_ENTRIES_THIS_DISK] = dircount endrec[_ECD_ENTRIES_TOTAL] = dircount2 endrec[_ECD_SIZE] = dirsize endrec[_ECD_OFFSET] = diroffset return endrec def _EndRecData(fpin): """Return data from the "End of Central Directory" record, or None. The data is a list of the nine items in the ZIP "End of central dir" record followed by a tenth item, the file seek offset of this record.""" # Determine file size fpin.seek(0, 2) filesize = fpin.tell() # Check to see if this is ZIP file with no archive comment (the # "end of central directory" structure should be the last item in the # file if this is the case). try: fpin.seek(-sizeEndCentDir, 2) except OSError: return None data = fpin.read() if (len(data) == sizeEndCentDir and data[0:4] == stringEndArchive and data[-2:] == b"\000\000"): # the signature is correct and there's no comment, unpack structure endrec = struct.unpack(structEndArchive, data) endrec=list(endrec) # Append a blank comment and record start offset endrec.append(b"") endrec.append(filesize - sizeEndCentDir) # Try to read the "Zip64 end of central directory" structure return _EndRecData64(fpin, -sizeEndCentDir, endrec) # Either this is not a ZIP file, or it is a ZIP file with an archive # comment. Search the end of the file for the "end of central directory" # record signature. The comment is the last item in the ZIP file and may be # up to 64K long. It is assumed that the "end of central directory" magic # number does not appear in the comment. maxCommentStart = max(filesize - (1 << 16) - sizeEndCentDir, 0) fpin.seek(maxCommentStart, 0) data = fpin.read() start = data.rfind(stringEndArchive) if start >= 0: # found the magic number; attempt to unpack and interpret recData = data[start:start+sizeEndCentDir] if len(recData) != sizeEndCentDir: # Zip file is corrupted. return None endrec = list(struct.unpack(structEndArchive, recData)) commentSize = endrec[_ECD_COMMENT_SIZE] #as claimed by the zip file comment = data[start+sizeEndCentDir:start+sizeEndCentDir+commentSize] endrec.append(comment) endrec.append(maxCommentStart + start) # Try to read the "Zip64 end of central directory" structure return _EndRecData64(fpin, maxCommentStart + start - filesize, endrec) # Unable to find a valid end of central directory structure return None class ZipInfo (object): """Class with attributes describing each file in the ZIP archive.""" __slots__ = ( 'orig_filename', 'filename', 'date_time', 'compress_type', 'comment', 'extra', 'create_system', 'create_version', 'extract_version', 'reserved', 'flag_bits', 'volume', 'internal_attr', 'external_attr', 'header_offset', 'CRC', 'compress_size', 'file_size', '_raw_time', ) def __init__(self, filename="NoName", date_time=(1980,1,1,0,0,0)): self.orig_filename = filename # Original file name in archive # Terminate the file name at the first null byte. Null bytes in file # names are used as tricks by viruses in archives. null_byte = filename.find(chr(0)) if null_byte >= 0: filename = filename[0:null_byte] # This is used to ensure paths in generated ZIP files always use # forward slashes as the directory separator, as required by the # ZIP format specification. if os.sep != "/" and os.sep in filename: filename = filename.replace(os.sep, "/") self.filename = filename # Normalized file name self.date_time = date_time # year, month, day, hour, min, sec if date_time[0] < 1980: raise ValueError('ZIP does not support timestamps before 1980') # Standard values: self.compress_type = ZIP_STORED # Type of compression for the file self.comment = b"" # Comment for each file self.extra = b"" # ZIP extra data if sys.platform == 'win32': self.create_system = 0 # System which created ZIP archive else: # Assume everything else is unix-y self.create_system = 3 # System which created ZIP archive self.create_version = DEFAULT_VERSION # Version which created ZIP archive self.extract_version = DEFAULT_VERSION # Version needed to extract archive self.reserved = 0 # Must be zero self.flag_bits = 0 # ZIP flag bits self.volume = 0 # Volume number of file header self.internal_attr = 0 # Internal attributes self.external_attr = 0 # External file attributes # Other attributes are set by class ZipFile: # header_offset Byte offset to the file header # CRC CRC-32 of the uncompressed file # compress_size Size of the compressed file # file_size Size of the uncompressed file def __repr__(self): result = ['<%s filename=%r' % (self.__class__.__name__, self.filename)] if self.compress_type != ZIP_STORED: result.append(' compress_type=%s' % compressor_names.get(self.compress_type, self.compress_type)) hi = self.external_attr >> 16 lo = self.external_attr & 0xFFFF if hi: result.append(' filemode=%r' % stat.filemode(hi)) if lo: result.append(' external_attr=%#x' % lo) isdir = self.filename[-1:] == '/' if not isdir or self.file_size: result.append(' file_size=%r' % self.file_size) if ((not isdir or self.compress_size) and (self.compress_type != ZIP_STORED or self.file_size != self.compress_size)): result.append(' compress_size=%r' % self.compress_size) result.append('>') return ''.join(result) def FileHeader(self, zip64=None): """Return the per-file header as a string.""" dt = self.date_time dosdate = (dt[0] - 1980) << 9 | dt[1] << 5 | dt[2] dostime = dt[3] << 11 | dt[4] << 5 | (dt[5] // 2) if self.flag_bits & 0x08: # Set these to zero because we write them after the file data CRC = compress_size = file_size = 0 else: CRC = self.CRC compress_size = self.compress_size file_size = self.file_size extra = self.extra min_version = 0 if zip64 is None: zip64 = file_size > ZIP64_LIMIT or compress_size > ZIP64_LIMIT if zip64: fmt = '<HHQQ' extra = extra + struct.pack(fmt, 1, struct.calcsize(fmt)-4, file_size, compress_size) if file_size > ZIP64_LIMIT or compress_size > ZIP64_LIMIT: if not zip64: raise LargeZipFile("Filesize would require ZIP64 extensions") # File is larger than what fits into a 4 byte integer, # fall back to the ZIP64 extension file_size = 0xffffffff compress_size = 0xffffffff min_version = ZIP64_VERSION if self.compress_type == ZIP_BZIP2: min_version = max(BZIP2_VERSION, min_version) elif self.compress_type == ZIP_LZMA: min_version = max(LZMA_VERSION, min_version) self.extract_version = max(min_version, self.extract_version) self.create_version = max(min_version, self.create_version) filename, flag_bits = self._encodeFilenameFlags() header = struct.pack(structFileHeader, stringFileHeader, self.extract_version, self.reserved, flag_bits, self.compress_type, dostime, dosdate, CRC, compress_size, file_size, len(filename), len(extra)) return header + filename + extra def _encodeFilenameFlags(self): try: return self.filename.encode('ascii'), self.flag_bits except UnicodeEncodeError: return self.filename.encode('utf-8'), self.flag_bits | 0x800 def _decodeExtra(self): # Try to decode the extra field. extra = self.extra unpack = struct.unpack while len(extra) >= 4: tp, ln = unpack('<HH', extra[:4]) if tp == 1: if ln >= 24: counts = unpack('<QQQ', extra[4:28]) elif ln == 16: counts = unpack('<QQ', extra[4:20]) elif ln == 8: counts = unpack('<Q', extra[4:12]) elif ln == 0: counts = () else: raise RuntimeError("Corrupt extra field %s"%(ln,)) idx = 0 # ZIP64 extension (large files and/or large archives) if self.file_size in (0xffffffffffffffff, 0xffffffff): self.file_size = counts[idx] idx += 1 if self.compress_size == 0xFFFFFFFF: self.compress_size = counts[idx] idx += 1 if self.header_offset == 0xffffffff: old = self.header_offset self.header_offset = counts[idx] idx+=1 extra = extra[ln+4:] class _ZipDecrypter: """Class to handle decryption of files stored within a ZIP archive. ZIP supports a password-based form of encryption. Even though known plaintext attacks have been found against it, it is still useful to be able to get data out of such a file. Usage: zd = _ZipDecrypter(mypwd) plain_char = zd(cypher_char) plain_text = map(zd, cypher_text) """ def _GenerateCRCTable(): """Generate a CRC-32 table. ZIP encryption uses the CRC32 one-byte primitive for scrambling some internal keys. We noticed that a direct implementation is faster than relying on binascii.crc32(). """ poly = 0xedb88320 table = [0] * 256 for i in range(256): crc = i for j in range(8): if crc & 1: crc = ((crc >> 1) & 0x7FFFFFFF) ^ poly else: crc = ((crc >> 1) & 0x7FFFFFFF) table[i] = crc return table crctable = None def _crc32(self, ch, crc): """Compute the CRC32 primitive on one byte.""" return ((crc >> 8) & 0xffffff) ^ self.crctable[(crc ^ ch) & 0xff] def __init__(self, pwd): if _ZipDecrypter.crctable is None: _ZipDecrypter.crctable = _ZipDecrypter._GenerateCRCTable() self.key0 = 305419896 self.key1 = 591751049 self.key2 = 878082192 for p in pwd: self._UpdateKeys(p) def _UpdateKeys(self, c): self.key0 = self._crc32(c, self.key0) self.key1 = (self.key1 + (self.key0 & 255)) & 4294967295 self.key1 = (self.key1 * 134775813 + 1) & 4294967295 self.key2 = self._crc32((self.key1 >> 24) & 255, self.key2) def __call__(self, c): """Decrypt a single character.""" assert isinstance(c, int) k = self.key2 | 2 c = c ^ (((k * (k^1)) >> 8) & 255) self._UpdateKeys(c) return c class LZMACompressor: def __init__(self): self._comp = None def _init(self): props = lzma._encode_filter_properties({'id': lzma.FILTER_LZMA1}) self._comp = lzma.LZMACompressor(lzma.FORMAT_RAW, filters=[ lzma._decode_filter_properties(lzma.FILTER_LZMA1, props) ]) return struct.pack('<BBH', 9, 4, len(props)) + props def compress(self, data): if self._comp is None: return self._init() + self._comp.compress(data) return self._comp.compress(data) def flush(self): if self._comp is None: return self._init() + self._comp.flush() return self._comp.flush() class LZMADecompressor: def __init__(self): self._decomp = None self._unconsumed = b'' self.eof = False def decompress(self, data): if self._decomp is None: self._unconsumed += data if len(self._unconsumed) <= 4: return b'' psize, = struct.unpack('<H', self._unconsumed[2:4]) if len(self._unconsumed) <= 4 + psize: return b'' self._decomp = lzma.LZMADecompressor(lzma.FORMAT_RAW, filters=[ lzma._decode_filter_properties(lzma.FILTER_LZMA1, self._unconsumed[4:4 + psize]) ]) data = self._unconsumed[4 + psize:] del self._unconsumed result = self._decomp.decompress(data) self.eof = self._decomp.eof return result compressor_names = { 0: 'store', 1: 'shrink', 2: 'reduce', 3: 'reduce', 4: 'reduce', 5: 'reduce', 6: 'implode', 7: 'tokenize', 8: 'deflate', 9: 'deflate64', 10: 'implode', 12: 'bzip2', 14: 'lzma', 18: 'terse', 19: 'lz77', 97: 'wavpack', 98: 'ppmd', } def _check_compression(compression): if compression == ZIP_STORED: pass elif compression == ZIP_DEFLATED: if not zlib: raise RuntimeError( "Compression requires the (missing) zlib module") elif compression == ZIP_BZIP2: if not bz2: raise RuntimeError( "Compression requires the (missing) bz2 module") elif compression == ZIP_LZMA: if not lzma: raise RuntimeError( "Compression requires the (missing) lzma module") else: raise RuntimeError("That compression method is not supported") def _get_compressor(compress_type): if compress_type == ZIP_DEFLATED: return zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, -15) elif compress_type == ZIP_BZIP2: return bz2.BZ2Compressor() elif compress_type == ZIP_LZMA: return LZMACompressor() else: return None def _get_decompressor(compress_type): if compress_type == ZIP_STORED: return None elif compress_type == ZIP_DEFLATED: return zlib.decompressobj(-15) elif compress_type == ZIP_BZIP2: return bz2.BZ2Decompressor() elif compress_type == ZIP_LZMA: return LZMADecompressor() else: descr = compressor_names.get(compress_type) if descr: raise NotImplementedError("compression type %d (%s)" % (compress_type, descr)) else: raise NotImplementedError("compression type %d" % (compress_type,)) class _SharedFile: def __init__(self, file, pos, close, lock): self._file = file self._pos = pos self._close = close self._lock = lock def read(self, n=-1): with self._lock: self._file.seek(self._pos) data = self._file.read(n) self._pos = self._file.tell() return data def close(self): if self._file is not None: fileobj = self._file self._file = None self._close(fileobj) # Provide the tell method for unseekable stream class _Tellable: def __init__(self, fp): self.fp = fp self.offset = 0 def write(self, data): n = self.fp.write(data) self.offset += n return n def tell(self): return self.offset def flush(self): self.fp.flush() def close(self): self.fp.close() class ZipExtFile(io.BufferedIOBase): """File-like object for reading an archive member. Is returned by ZipFile.open(). """ # Max size supported by decompressor. MAX_N = 1 << 31 - 1 # Read from compressed files in 4k blocks. MIN_READ_SIZE = 4096 # Search for universal newlines or line chunks. PATTERN = re.compile(br'^(?P<chunk>[^\r\n]+)|(?P<newline>\n|\r\n?)') def __init__(self, fileobj, mode, zipinfo, decrypter=None, close_fileobj=False): self._fileobj = fileobj self._decrypter = decrypter self._close_fileobj = close_fileobj self._compress_type = zipinfo.compress_type self._compress_left = zipinfo.compress_size self._left = zipinfo.file_size self._decompressor = _get_decompressor(self._compress_type) self._eof = False self._readbuffer = b'' self._offset = 0 self._universal = 'U' in mode self.newlines = None # Adjust read size for encrypted files since the first 12 bytes # are for the encryption/password information. if self._decrypter is not None: self._compress_left -= 12 self.mode = mode self.name = zipinfo.filename if hasattr(zipinfo, 'CRC'): self._expected_crc = zipinfo.CRC self._running_crc = crc32(b'') & 0xffffffff else: self._expected_crc = None def __repr__(self): result = ['<%s.%s' % (self.__class__.__module__, self.__class__.__qualname__)] if not self.closed: result.append(' name=%r mode=%r' % (self.name, self.mode)) if self._compress_type != ZIP_STORED: result.append(' compress_type=%s' % compressor_names.get(self._compress_type, self._compress_type)) else: result.append(' [closed]') result.append('>') return ''.join(result) def readline(self, limit=-1): """Read and return a line from the stream. If limit is specified, at most limit bytes will be read. """ if not self._universal and limit < 0: # Shortcut common case - newline found in buffer. i = self._readbuffer.find(b'\n', self._offset) + 1 if i > 0: line = self._readbuffer[self._offset: i] self._offset = i return line if not self._universal: return io.BufferedIOBase.readline(self, limit) line = b'' while limit < 0 or len(line) < limit: readahead = self.peek(2) if readahead == b'': return line # # Search for universal newlines or line chunks. # # The pattern returns either a line chunk or a newline, but not # both. Combined with peek(2), we are assured that the sequence # '\r\n' is always retrieved completely and never split into # separate newlines - '\r', '\n' due to coincidental readaheads. # match = self.PATTERN.search(readahead) newline = match.group('newline') if newline is not None: if self.newlines is None: self.newlines = [] if newline not in self.newlines: self.newlines.append(newline) self._offset += len(newline) return line + b'\n' chunk = match.group('chunk') if limit >= 0: chunk = chunk[: limit - len(line)] self._offset += len(chunk) line += chunk return line def peek(self, n=1): """Returns buffered bytes without advancing the position.""" if n > len(self._readbuffer) - self._offset: chunk = self.read(n) if len(chunk) > self._offset: self._readbuffer = chunk + self._readbuffer[self._offset:] self._offset = 0 else: self._offset -= len(chunk) # Return up to 512 bytes to reduce allocation overhead for tight loops. return self._readbuffer[self._offset: self._offset + 512] def readable(self): return True def read(self, n=-1): """Read and return up to n bytes. If the argument is omitted, None, or negative, data is read and returned until EOF is reached.. """ if n is None or n < 0: buf = self._readbuffer[self._offset:] self._readbuffer = b'' self._offset = 0 while not self._eof: buf += self._read1(self.MAX_N) return buf end = n + self._offset if end < len(self._readbuffer): buf = self._readbuffer[self._offset:end] self._offset = end return buf n = end - len(self._readbuffer) buf = self._readbuffer[self._offset:] self._readbuffer = b'' self._offset = 0 while n > 0 and not self._eof: data = self._read1(n) if n < len(data): self._readbuffer = data self._offset = n buf += data[:n] break buf += data n -= len(data) return buf def _update_crc(self, newdata): # Update the CRC using the given data. if self._expected_crc is None: # No need to compute the CRC if we don't have a reference value return self._running_crc = crc32(newdata, self._running_crc) & 0xffffffff # Check the CRC if we're at the end of the file if self._eof and self._running_crc != self._expected_crc: raise BadZipFile("Bad CRC-32 for file %r" % self.name) def read1(self, n): """Read up to n bytes with at most one read() system call.""" if n is None or n < 0: buf = self._readbuffer[self._offset:] self._readbuffer = b'' self._offset = 0 while not self._eof: data = self._read1(self.MAX_N) if data: buf += data break return buf end = n + self._offset if end < len(self._readbuffer): buf = self._readbuffer[self._offset:end] self._offset = end return buf n = end - len(self._readbuffer) buf = self._readbuffer[self._offset:] self._readbuffer = b'' self._offset = 0 if n > 0: while not self._eof: data = self._read1(n) if n < len(data): self._readbuffer = data self._offset = n buf += data[:n] break if data: buf += data break return buf def _read1(self, n): # Read up to n compressed bytes with at most one read() system call, # decrypt and decompress them. if self._eof or n <= 0: return b'' # Read from file. if self._compress_type == ZIP_DEFLATED: ## Handle unconsumed data. data = self._decompressor.unconsumed_tail if n > len(data): data += self._read2(n - len(data)) else: data = self._read2(n) if self._compress_type == ZIP_STORED: self._eof = self._compress_left <= 0 elif self._compress_type == ZIP_DEFLATED: n = max(n, self.MIN_READ_SIZE) data = self._decompressor.decompress(data, n) self._eof = (self._decompressor.eof or self._compress_left <= 0 and not self._decompressor.unconsumed_tail) if self._eof: data += self._decompressor.flush() else: data = self._decompressor.decompress(data) self._eof = self._decompressor.eof or self._compress_left <= 0 data = data[:self._left] self._left -= len(data) if self._left <= 0: self._eof = True self._update_crc(data) return data def _read2(self, n): if self._compress_left <= 0: return b'' n = max(n, self.MIN_READ_SIZE) n = min(n, self._compress_left) data = self._fileobj.read(n) self._compress_left -= len(data) if not data: raise EOFError if self._decrypter is not None: data = bytes(map(self._decrypter, data)) return data def close(self): try: if self._close_fileobj: self._fileobj.close() finally: super().close() class ZipFile: """ Class with methods to open, read, write, close, list zip files. z = ZipFile(file, mode="r", compression=ZIP_STORED, allowZip64=True) file: Either the path to the file, or a file-like object. If it is a path, the file will be opened and closed by ZipFile. mode: The mode can be either read 'r', write 'w', exclusive create 'x', or append 'a'. compression: ZIP_STORED (no compression), ZIP_DEFLATED (requires zlib), ZIP_BZIP2 (requires bz2) or ZIP_LZMA (requires lzma). allowZip64: if True ZipFile will create files with ZIP64 extensions when needed, otherwise it will raise an exception when this would be necessary. """ fp = None # Set here since __del__ checks it _windows_illegal_name_trans_table = None def __init__(self, file, mode="r", compression=ZIP_STORED, allowZip64=True): """Open the ZIP file with mode read 'r', write 'w', exclusive create 'x', or append 'a'.""" if mode not in ('r', 'w', 'x', 'a'): raise RuntimeError("ZipFile requires mode 'r', 'w', 'x', or 'a'") _check_compression(compression) self._allowZip64 = allowZip64 self._didModify = False self.debug = 0 # Level of printing: 0 through 3 self.NameToInfo = {} # Find file info given name self.filelist = [] # List of ZipInfo instances for archive self.compression = compression # Method of compression self.mode = mode self.pwd = None self._comment = b'' # Check if we were passed a file-like object if isinstance(file, str): # No, it's a filename self._filePassed = 0 self.filename = file modeDict = {'r' : 'rb', 'w': 'w+b', 'x': 'x+b', 'a' : 'r+b', 'r+b': 'w+b', 'w+b': 'wb', 'x+b': 'xb'} filemode = modeDict[mode] while True: try: self.fp = io.open(file, filemode) except OSError: if filemode in modeDict: filemode = modeDict[filemode] continue raise break else: self._filePassed = 1 self.fp = file self.filename = getattr(file, 'name', None) self._fileRefCnt = 1 self._lock = threading.RLock() self._seekable = True try: if mode == 'r': self._RealGetContents() elif mode in ('w', 'x'): # set the modified flag so central directory gets written # even if no files are added to the archive self._didModify = True try: self.start_dir = self.fp.tell() except (AttributeError, OSError): self.fp = _Tellable(self.fp) self.start_dir = 0 self._seekable = False else: # Some file-like objects can provide tell() but not seek() try: self.fp.seek(self.start_dir) except (AttributeError, OSError): self._seekable = False elif mode == 'a': try: # See if file is a zip file self._RealGetContents() # seek to start of directory and overwrite self.fp.seek(self.start_dir) except BadZipFile: # file is not a zip file, just append self.fp.seek(0, 2) # set the modified flag so central directory gets written # even if no files are added to the archive self._didModify = True self.start_dir = self.fp.tell() else: raise RuntimeError("Mode must be 'r', 'w', 'x', or 'a'") except: fp = self.fp self.fp = None self._fpclose(fp) raise def __enter__(self): return self def __exit__(self, type, value, traceback): self.close() def __repr__(self): result = ['<%s.%s' % (self.__class__.__module__, self.__class__.__qualname__)] if self.fp is not None: if self._filePassed: result.append(' file=%r' % self.fp) elif self.filename is not None: result.append(' filename=%r' % self.filename) result.append(' mode=%r' % self.mode) else: result.append(' [closed]') result.append('>') return ''.join(result) def _RealGetContents(self): """Read in the table of contents for the ZIP file.""" fp = self.fp try: endrec = _EndRecData(fp) except OSError: raise BadZipFile("File is not a zip file") if not endrec: raise BadZipFile("File is not a zip file") if self.debug > 1: print(endrec) size_cd = endrec[_ECD_SIZE] # bytes in central directory offset_cd = endrec[_ECD_OFFSET] # offset of central directory self._comment = endrec[_ECD_COMMENT] # archive comment # "concat" is zero, unless zip was concatenated to another file concat = endrec[_ECD_LOCATION] - size_cd - offset_cd if endrec[_ECD_SIGNATURE] == stringEndArchive64: # If Zip64 extension structures are present, account for them concat -= (sizeEndCentDir64 + sizeEndCentDir64Locator) if self.debug > 2: inferred = concat + offset_cd print("given, inferred, offset", offset_cd, inferred, concat) # self.start_dir: Position of start of central directory self.start_dir = offset_cd + concat fp.seek(self.start_dir, 0) data = fp.read(size_cd) fp = io.BytesIO(data) total = 0 while total < size_cd: centdir = fp.read(sizeCentralDir) if len(centdir) != sizeCentralDir: raise BadZipFile("Truncated central directory") centdir = struct.unpack(structCentralDir, centdir) if centdir[_CD_SIGNATURE] != stringCentralDir: raise BadZipFile("Bad magic number for central directory") if self.debug > 2: print(centdir) filename = fp.read(centdir[_CD_FILENAME_LENGTH]) flags = centdir[5] if flags & 0x800: # UTF-8 file names extension filename = filename.decode('utf-8') else: # Historical ZIP filename encoding filename = filename.decode('cp437') # Create ZipInfo instance to store file information x = ZipInfo(filename) x.extra = fp.read(centdir[_CD_EXTRA_FIELD_LENGTH]) x.comment = fp.read(centdir[_CD_COMMENT_LENGTH]) x.header_offset = centdir[_CD_LOCAL_HEADER_OFFSET] (x.create_version, x.create_system, x.extract_version, x.reserved, x.flag_bits, x.compress_type, t, d, x.CRC, x.compress_size, x.file_size) = centdir[1:12] if x.extract_version > MAX_EXTRACT_VERSION: raise NotImplementedError("zip file version %.1f" % (x.extract_version / 10)) x.volume, x.internal_attr, x.external_attr = centdir[15:18] # Convert date/time code to (year, month, day, hour, min, sec) x._raw_time = t x.date_time = ( (d>>9)+1980, (d>>5)&0xF, d&0x1F, t>>11, (t>>5)&0x3F, (t&0x1F) * 2 ) x._decodeExtra() x.header_offset = x.header_offset + concat self.filelist.append(x) self.NameToInfo[x.filename] = x # update total bytes read from central directory total = (total + sizeCentralDir + centdir[_CD_FILENAME_LENGTH] + centdir[_CD_EXTRA_FIELD_LENGTH] + centdir[_CD_COMMENT_LENGTH]) if self.debug > 2: print("total", total) def namelist(self): """Return a list of file names in the archive.""" return [data.filename for data in self.filelist] def infolist(self): """Return a list of class ZipInfo instances for files in the archive.""" return self.filelist def printdir(self, file=None): """Print a table of contents for the zip file.""" print("%-46s %19s %12s" % ("File Name", "Modified ", "Size"), file=file) for zinfo in self.filelist: date = "%d-%02d-%02d %02d:%02d:%02d" % zinfo.date_time[:6] print("%-46s %s %12d" % (zinfo.filename, date, zinfo.file_size), file=file) def testzip(self): """Read all the files and check the CRC.""" chunk_size = 2 ** 20 for zinfo in self.filelist: try: # Read by chunks, to avoid an OverflowError or a # MemoryError with very large embedded files. with self.open(zinfo.filename, "r") as f: while f.read(chunk_size): # Check CRC-32 pass except BadZipFile: return zinfo.filename def getinfo(self, name): """Return the instance of ZipInfo given 'name'.""" info = self.NameToInfo.get(name) if info is None: raise KeyError( 'There is no item named %r in the archive' % name) return info def setpassword(self, pwd): """Set default password for encrypted files.""" if pwd and not isinstance(pwd, bytes): raise TypeError("pwd: expected bytes, got %s" % type(pwd)) if pwd: self.pwd = pwd else: self.pwd = None @property def comment(self): """The comment text associated with the ZIP file.""" return self._comment @comment.setter def comment(self, comment): if not isinstance(comment, bytes): raise TypeError("comment: expected bytes, got %s" % type(comment)) # check for valid comment length if len(comment) > ZIP_MAX_COMMENT: import warnings warnings.warn('Archive comment is too long; truncating to %d bytes' % ZIP_MAX_COMMENT, stacklevel=2) comment = comment[:ZIP_MAX_COMMENT] self._comment = comment self._didModify = True def read(self, name, pwd=None): """Return file bytes (as a string) for name.""" with self.open(name, "r", pwd) as fp: return fp.read() def open(self, name, mode="r", pwd=None): """Return file-like object for 'name'.""" if mode not in ("r", "U", "rU"): raise RuntimeError('open() requires mode "r", "U", or "rU"') if 'U' in mode: import warnings warnings.warn("'U' mode is deprecated", DeprecationWarning, 2) if pwd and not isinstance(pwd, bytes): raise TypeError("pwd: expected bytes, got %s" % type(pwd)) if not self.fp: raise RuntimeError( "Attempt to read ZIP archive that was already closed") # Make sure we have an info object if isinstance(name, ZipInfo): # 'name' is already an info object zinfo = name else: # Get info object for name zinfo = self.getinfo(name) self._fileRefCnt += 1 zef_file = _SharedFile(self.fp, zinfo.header_offset, self._fpclose, self._lock) try: # Skip the file header: fheader = zef_file.read(sizeFileHeader) if len(fheader) != sizeFileHeader: raise BadZipFile("Truncated file header") fheader = struct.unpack(structFileHeader, fheader) if fheader[_FH_SIGNATURE] != stringFileHeader: raise BadZipFile("Bad magic number for file header") fname = zef_file.read(fheader[_FH_FILENAME_LENGTH]) if fheader[_FH_EXTRA_FIELD_LENGTH]: zef_file.read(fheader[_FH_EXTRA_FIELD_LENGTH]) if zinfo.flag_bits & 0x20: # Zip 2.7: compressed patched data raise NotImplementedError("compressed patched data (flag bit 5)") if zinfo.flag_bits & 0x40: # strong encryption raise NotImplementedError("strong encryption (flag bit 6)") if zinfo.flag_bits & 0x800: # UTF-8 filename fname_str = fname.decode("utf-8") else: fname_str = fname.decode("cp437") if fname_str != zinfo.orig_filename: raise BadZipFile( 'File name in directory %r and header %r differ.' % (zinfo.orig_filename, fname)) # check for encrypted flag & handle password is_encrypted = zinfo.flag_bits & 0x1 zd = None if is_encrypted: if not pwd: pwd = self.pwd if not pwd: raise RuntimeError("File %s is encrypted, password " "required for extraction" % name) zd = _ZipDecrypter(pwd) # The first 12 bytes in the cypher stream is an encryption header # used to strengthen the algorithm. The first 11 bytes are # completely random, while the 12th contains the MSB of the CRC, # or the MSB of the file time depending on the header type # and is used to check the correctness of the password. header = zef_file.read(12) h = list(map(zd, header[0:12])) if zinfo.flag_bits & 0x8: # compare against the file type from extended local headers check_byte = (zinfo._raw_time >> 8) & 0xff else: # compare against the CRC otherwise check_byte = (zinfo.CRC >> 24) & 0xff if h[11] != check_byte: raise RuntimeError("Bad password for file", name) return ZipExtFile(zef_file, mode, zinfo, zd, True) except: zef_file.close() raise def extract(self, member, path=None, pwd=None): """Extract a member from the archive to the current working directory, using its full name. Its file information is extracted as accurately as possible. `member' may be a filename or a ZipInfo object. You can specify a different directory using `path'. """ if not isinstance(member, ZipInfo): member = self.getinfo(member) if path is None: path = os.getcwd() return self._extract_member(member, path, pwd) def extractall(self, path=None, members=None, pwd=None): """Extract all members from the archive to the current working directory. `path' specifies a different directory to extract to. `members' is optional and must be a subset of the list returned by namelist(). """ if members is None: members = self.namelist() for zipinfo in members: self.extract(zipinfo, path, pwd) @classmethod def _sanitize_windows_name(cls, arcname, pathsep): """Replace bad characters and remove trailing dots from parts.""" table = cls._windows_illegal_name_trans_table if not table: illegal = ':<>|"?*' table = str.maketrans(illegal, '_' * len(illegal)) cls._windows_illegal_name_trans_table = table arcname = arcname.translate(table) # remove trailing dots arcname = (x.rstrip('.') for x in arcname.split(pathsep)) # rejoin, removing empty parts. arcname = pathsep.join(x for x in arcname if x) return arcname def _extract_member(self, member, targetpath, pwd): """Extract the ZipInfo object 'member' to a physical file on the path targetpath. """ # build the destination pathname, replacing # forward slashes to platform specific separators. arcname = member.filename.replace('/', os.path.sep) if os.path.altsep: arcname = arcname.replace(os.path.altsep, os.path.sep) # interpret absolute pathname as relative, remove drive letter or # UNC path, redundant separators, "." and ".." components. arcname = os.path.splitdrive(arcname)[1] invalid_path_parts = ('', os.path.curdir, os.path.pardir) arcname = os.path.sep.join(x for x in arcname.split(os.path.sep) if x not in invalid_path_parts) if os.path.sep == '\\': # filter illegal characters on Windows arcname = self._sanitize_windows_name(arcname, os.path.sep) targetpath = os.path.join(targetpath, arcname) targetpath = os.path.normpath(targetpath) # Create all upper directories if necessary. upperdirs = os.path.dirname(targetpath) if upperdirs and not os.path.exists(upperdirs): os.makedirs(upperdirs) if member.filename[-1] == '/': if not os.path.isdir(targetpath): os.mkdir(targetpath) return targetpath with self.open(member, pwd=pwd) as source, \ open(targetpath, "wb") as target: shutil.copyfileobj(source, target) return targetpath def _writecheck(self, zinfo): """Check for errors before writing a file to the archive.""" if zinfo.filename in self.NameToInfo: import warnings warnings.warn('Duplicate name: %r' % zinfo.filename, stacklevel=3) if self.mode not in ('w', 'x', 'a'): raise RuntimeError("write() requires mode 'w', 'x', or 'a'") if not self.fp: raise RuntimeError( "Attempt to write ZIP archive that was already closed") _check_compression(zinfo.compress_type) if not self._allowZip64: requires_zip64 = None if len(self.filelist) >= ZIP_FILECOUNT_LIMIT: requires_zip64 = "Files count" elif zinfo.file_size > ZIP64_LIMIT: requires_zip64 = "Filesize" elif zinfo.header_offset > ZIP64_LIMIT: requires_zip64 = "Zipfile size" if requires_zip64: raise LargeZipFile(requires_zip64 + " would require ZIP64 extensions") def write(self, filename, arcname=None, compress_type=None): """Put the bytes from filename into the archive under the name arcname.""" if not self.fp: raise RuntimeError( "Attempt to write to ZIP archive that was already closed") st = os.stat(filename) isdir = stat.S_ISDIR(st.st_mode) mtime = time.localtime(st.st_mtime) date_time = mtime[0:6] # Create ZipInfo instance to store file information if arcname is None: arcname = filename arcname = os.path.normpath(os.path.splitdrive(arcname)[1]) while arcname[0] in (os.sep, os.altsep): arcname = arcname[1:] if isdir: arcname += '/' zinfo = ZipInfo(arcname, date_time) zinfo.external_attr = (st[0] & 0xFFFF) << 16 # Unix attributes if compress_type is None: zinfo.compress_type = self.compression else: zinfo.compress_type = compress_type zinfo.file_size = st.st_size zinfo.flag_bits = 0x00 with self._lock: if self._seekable: self.fp.seek(self.start_dir) zinfo.header_offset = self.fp.tell() # Start of header bytes if zinfo.compress_type == ZIP_LZMA: # Compressed data includes an end-of-stream (EOS) marker zinfo.flag_bits |= 0x02 self._writecheck(zinfo) self._didModify = True if isdir: zinfo.file_size = 0 zinfo.compress_size = 0 zinfo.CRC = 0 zinfo.external_attr |= 0x10 # MS-DOS directory flag self.filelist.append(zinfo) self.NameToInfo[zinfo.filename] = zinfo self.fp.write(zinfo.FileHeader(False)) self.start_dir = self.fp.tell() return cmpr = _get_compressor(zinfo.compress_type) if not self._seekable: zinfo.flag_bits |= 0x08 with open(filename, "rb") as fp: # Must overwrite CRC and sizes with correct data later zinfo.CRC = CRC = 0 zinfo.compress_size = compress_size = 0 # Compressed size can be larger than uncompressed size zip64 = self._allowZip64 and \ zinfo.file_size * 1.05 > ZIP64_LIMIT self.fp.write(zinfo.FileHeader(zip64)) file_size = 0 while 1: buf = fp.read(1024 * 8) if not buf: break file_size = file_size + len(buf) CRC = crc32(buf, CRC) & 0xffffffff if cmpr: buf = cmpr.compress(buf) compress_size = compress_size + len(buf) self.fp.write(buf) if cmpr: buf = cmpr.flush() compress_size = compress_size + len(buf) self.fp.write(buf) zinfo.compress_size = compress_size else: zinfo.compress_size = file_size zinfo.CRC = CRC zinfo.file_size = file_size if zinfo.flag_bits & 0x08: # Write CRC and file sizes after the file data fmt = '<LQQ' if zip64 else '<LLL' self.fp.write(struct.pack(fmt, zinfo.CRC, zinfo.compress_size, zinfo.file_size)) self.start_dir = self.fp.tell() else: if not zip64 and self._allowZip64: if file_size > ZIP64_LIMIT: raise RuntimeError('File size has increased during compressing') if compress_size > ZIP64_LIMIT: raise RuntimeError('Compressed size larger than uncompressed size') # Seek backwards and write file header (which will now include # correct CRC and file sizes) self.start_dir = self.fp.tell() # Preserve current position in file self.fp.seek(zinfo.header_offset) self.fp.write(zinfo.FileHeader(zip64)) self.fp.seek(self.start_dir) self.filelist.append(zinfo) self.NameToInfo[zinfo.filename] = zinfo def writestr(self, zinfo_or_arcname, data, compress_type=None): """Write a file into the archive. The contents is 'data', which may be either a 'str' or a 'bytes' instance; if it is a 'str', it is encoded as UTF-8 first. 'zinfo_or_arcname' is either a ZipInfo instance or the name of the file in the archive.""" if isinstance(data, str): data = data.encode("utf-8") if not isinstance(zinfo_or_arcname, ZipInfo): zinfo = ZipInfo(filename=zinfo_or_arcname, date_time=time.localtime(time.time())[:6]) zinfo.compress_type = self.compression if zinfo.filename[-1] == '/': zinfo.external_attr = 0o40775 << 16 # drwxrwxr-x zinfo.external_attr |= 0x10 # MS-DOS directory flag else: zinfo.external_attr = 0o600 << 16 # ?rw------- else: zinfo = zinfo_or_arcname if not self.fp: raise RuntimeError( "Attempt to write to ZIP archive that was already closed") zinfo.file_size = len(data) # Uncompressed size with self._lock: if self._seekable: self.fp.seek(self.start_dir) zinfo.header_offset = self.fp.tell() # Start of header data if compress_type is not None: zinfo.compress_type = compress_type zinfo.header_offset = self.fp.tell() # Start of header data if compress_type is not None: zinfo.compress_type = compress_type if zinfo.compress_type == ZIP_LZMA: # Compressed data includes an end-of-stream (EOS) marker zinfo.flag_bits |= 0x02 self._writecheck(zinfo) self._didModify = True zinfo.CRC = crc32(data) & 0xffffffff # CRC-32 checksum co = _get_compressor(zinfo.compress_type) if co: data = co.compress(data) + co.flush() zinfo.compress_size = len(data) # Compressed size else: zinfo.compress_size = zinfo.file_size zip64 = zinfo.file_size > ZIP64_LIMIT or \ zinfo.compress_size > ZIP64_LIMIT if zip64 and not self._allowZip64: raise LargeZipFile("Filesize would require ZIP64 extensions") self.fp.write(zinfo.FileHeader(zip64)) self.fp.write(data) if zinfo.flag_bits & 0x08: # Write CRC and file sizes after the file data fmt = '<LQQ' if zip64 else '<LLL' self.fp.write(struct.pack(fmt, zinfo.CRC, zinfo.compress_size, zinfo.file_size)) self.fp.flush() self.start_dir = self.fp.tell() self.filelist.append(zinfo) self.NameToInfo[zinfo.filename] = zinfo def __del__(self): """Call the "close()" method in case the user forgot.""" self.close() def close(self): """Close the file, and for mode 'w', 'x' and 'a' write the ending records.""" if self.fp is None: return try: if self.mode in ('w', 'x', 'a') and self._didModify: # write ending records with self._lock: if self._seekable: self.fp.seek(self.start_dir) self._write_end_record() finally: fp = self.fp self.fp = None self._fpclose(fp) def _write_end_record(self): for zinfo in self.filelist: # write central directory dt = zinfo.date_time dosdate = (dt[0] - 1980) << 9 | dt[1] << 5 | dt[2] dostime = dt[3] << 11 | dt[4] << 5 | (dt[5] // 2) extra = [] if zinfo.file_size > ZIP64_LIMIT \ or zinfo.compress_size > ZIP64_LIMIT: extra.append(zinfo.file_size) extra.append(zinfo.compress_size) file_size = 0xffffffff compress_size = 0xffffffff else: file_size = zinfo.file_size compress_size = zinfo.compress_size if zinfo.header_offset > ZIP64_LIMIT: extra.append(zinfo.header_offset) header_offset = 0xffffffff else: header_offset = zinfo.header_offset extra_data = zinfo.extra min_version = 0 if extra: # Append a ZIP64 field to the extra's extra_data = struct.pack( '<HH' + 'Q'*len(extra), 1, 8*len(extra), *extra) + extra_data min_version = ZIP64_VERSION if zinfo.compress_type == ZIP_BZIP2: min_version = max(BZIP2_VERSION, min_version) elif zinfo.compress_type == ZIP_LZMA: min_version = max(LZMA_VERSION, min_version) extract_version = max(min_version, zinfo.extract_version) create_version = max(min_version, zinfo.create_version) try: filename, flag_bits = zinfo._encodeFilenameFlags() centdir = struct.pack(structCentralDir, stringCentralDir, create_version, zinfo.create_system, extract_version, zinfo.reserved, flag_bits, zinfo.compress_type, dostime, dosdate, zinfo.CRC, compress_size, file_size, len(filename), len(extra_data), len(zinfo.comment), 0, zinfo.internal_attr, zinfo.external_attr, header_offset) except DeprecationWarning: print((structCentralDir, stringCentralDir, create_version, zinfo.create_system, extract_version, zinfo.reserved, zinfo.flag_bits, zinfo.compress_type, dostime, dosdate, zinfo.CRC, compress_size, file_size, len(zinfo.filename), len(extra_data), len(zinfo.comment), 0, zinfo.internal_attr, zinfo.external_attr, header_offset), file=sys.stderr) raise self.fp.write(centdir) self.fp.write(filename) self.fp.write(extra_data) self.fp.write(zinfo.comment) pos2 = self.fp.tell() # Write end-of-zip-archive record centDirCount = len(self.filelist) centDirSize = pos2 - self.start_dir centDirOffset = self.start_dir requires_zip64 = None if centDirCount > ZIP_FILECOUNT_LIMIT: requires_zip64 = "Files count" elif centDirOffset > ZIP64_LIMIT: requires_zip64 = "Central directory offset" elif centDirSize > ZIP64_LIMIT: requires_zip64 = "Central directory size" if requires_zip64: # Need to write the ZIP64 end-of-archive records if not self._allowZip64: raise LargeZipFile(requires_zip64 + " would require ZIP64 extensions") zip64endrec = struct.pack( structEndArchive64, stringEndArchive64, 44, 45, 45, 0, 0, centDirCount, centDirCount, centDirSize, centDirOffset) self.fp.write(zip64endrec) zip64locrec = struct.pack( structEndArchive64Locator, stringEndArchive64Locator, 0, pos2, 1) self.fp.write(zip64locrec) centDirCount = min(centDirCount, 0xFFFF) centDirSize = min(centDirSize, 0xFFFFFFFF) centDirOffset = min(centDirOffset, 0xFFFFFFFF) endrec = struct.pack(structEndArchive, stringEndArchive, 0, 0, centDirCount, centDirCount, centDirSize, centDirOffset, len(self._comment)) self.fp.write(endrec) self.fp.write(self._comment) self.fp.flush() def _fpclose(self, fp): assert self._fileRefCnt > 0 self._fileRefCnt -= 1 if not self._fileRefCnt and not self._filePassed: fp.close() class PyZipFile(ZipFile): """Class to create ZIP archives with Python library files and packages.""" def __init__(self, file, mode="r", compression=ZIP_STORED, allowZip64=True, optimize=-1): ZipFile.__init__(self, file, mode=mode, compression=compression, allowZip64=allowZip64) self._optimize = optimize def writepy(self, pathname, basename="", filterfunc=None): """Add all files from "pathname" to the ZIP archive. If pathname is a package directory, search the directory and all package subdirectories recursively for all *.py and enter the modules into the archive. If pathname is a plain directory, listdir *.py and enter all modules. Else, pathname must be a Python *.py file and the module will be put into the archive. Added modules are always module.pyc. This method will compile the module.py into module.pyc if necessary. If filterfunc(pathname) is given, it is called with every argument. When it is False, the file or directory is skipped. """ if filterfunc and not filterfunc(pathname): if self.debug: label = 'path' if os.path.isdir(pathname) else 'file' print('%s "%s" skipped by filterfunc' % (label, pathname)) return dir, name = os.path.split(pathname) if os.path.isdir(pathname): initname = os.path.join(pathname, "__init__.py") if os.path.isfile(initname): # This is a package directory, add it if basename: basename = "%s/%s" % (basename, name) else: basename = name if self.debug: print("Adding package in", pathname, "as", basename) fname, arcname = self._get_codename(initname[0:-3], basename) if self.debug: print("Adding", arcname) self.write(fname, arcname) dirlist = os.listdir(pathname) dirlist.remove("__init__.py") # Add all *.py files and package subdirectories for filename in dirlist: path = os.path.join(pathname, filename) root, ext = os.path.splitext(filename) if os.path.isdir(path): if os.path.isfile(os.path.join(path, "__init__.py")): # This is a package directory, add it self.writepy(path, basename, filterfunc=filterfunc) # Recursive call elif ext == ".py": if filterfunc and not filterfunc(path): if self.debug: print('file "%s" skipped by filterfunc' % path) continue fname, arcname = self._get_codename(path[0:-3], basename) if self.debug: print("Adding", arcname) self.write(fname, arcname) else: # This is NOT a package directory, add its files at top level if self.debug: print("Adding files from directory", pathname) for filename in os.listdir(pathname): path = os.path.join(pathname, filename) root, ext = os.path.splitext(filename) if ext == ".py": if filterfunc and not filterfunc(path): if self.debug: print('file "%s" skipped by filterfunc' % path) continue fname, arcname = self._get_codename(path[0:-3], basename) if self.debug: print("Adding", arcname) self.write(fname, arcname) else: if pathname[-3:] != ".py": raise RuntimeError( 'Files added with writepy() must end with ".py"') fname, arcname = self._get_codename(pathname[0:-3], basename) if self.debug: print("Adding file", arcname) self.write(fname, arcname) def _get_codename(self, pathname, basename): """Return (filename, archivename) for the path. Given a module name path, return the correct file path and archive name, compiling if necessary. For example, given /python/lib/string, return (/python/lib/string.pyc, string). """ def _compile(file, optimize=-1): import py_compile if self.debug: print("Compiling", file) try: py_compile.compile(file, doraise=True, optimize=optimize) except py_compile.PyCompileError as err: print(err.msg) return False return True file_py = pathname + ".py" file_pyc = pathname + ".pyc" pycache_opt0 = importlib.util.cache_from_source(file_py, optimization='') pycache_opt1 = importlib.util.cache_from_source(file_py, optimization=1) pycache_opt2 = importlib.util.cache_from_source(file_py, optimization=2) if self._optimize == -1: # legacy mode: use whatever file is present if (os.path.isfile(file_pyc) and os.stat(file_pyc).st_mtime >= os.stat(file_py).st_mtime): # Use .pyc file. arcname = fname = file_pyc elif (os.path.isfile(pycache_opt0) and os.stat(pycache_opt0).st_mtime >= os.stat(file_py).st_mtime): # Use the __pycache__/*.pyc file, but write it to the legacy pyc # file name in the archive. fname = pycache_opt0 arcname = file_pyc elif (os.path.isfile(pycache_opt1) and os.stat(pycache_opt1).st_mtime >= os.stat(file_py).st_mtime): # Use the __pycache__/*.pyc file, but write it to the legacy pyc # file name in the archive. fname = pycache_opt1 arcname = file_pyc elif (os.path.isfile(pycache_opt2) and os.stat(pycache_opt2).st_mtime >= os.stat(file_py).st_mtime): # Use the __pycache__/*.pyc file, but write it to the legacy pyc # file name in the archive. fname = pycache_opt2 arcname = file_pyc else: # Compile py into PEP 3147 pyc file. if _compile(file_py): if sys.flags.optimize == 0: fname = pycache_opt0 elif sys.flags.optimize == 1: fname = pycache_opt1 else: fname = pycache_opt2 arcname = file_pyc else: fname = arcname = file_py else: # new mode: use given optimization level if self._optimize == 0: fname = pycache_opt0 arcname = file_pyc else: arcname = file_pyc if self._optimize == 1: fname = pycache_opt1 elif self._optimize == 2: fname = pycache_opt2 else: msg = "invalid value for 'optimize': {!r}".format(self._optimize) raise ValueError(msg) if not (os.path.isfile(fname) and os.stat(fname).st_mtime >= os.stat(file_py).st_mtime): if not _compile(file_py, optimize=self._optimize): fname = arcname = file_py archivename = os.path.split(arcname)[1] if basename: archivename = "%s/%s" % (basename, archivename) return (fname, archivename) def main(args = None): import textwrap USAGE=textwrap.dedent("""\ Usage: zipfile.py -l zipfile.zip # Show listing of a zipfile zipfile.py -t zipfile.zip # Test if a zipfile is valid zipfile.py -e zipfile.zip target # Extract zipfile into target dir zipfile.py -c zipfile.zip src ... # Create zipfile from sources """) if args is None: args = sys.argv[1:] if not args or args[0] not in ('-l', '-c', '-e', '-t'): print(USAGE) sys.exit(1) if args[0] == '-l': if len(args) != 2: print(USAGE) sys.exit(1) with ZipFile(args[1], 'r') as zf: zf.printdir() elif args[0] == '-t': if len(args) != 2: print(USAGE) sys.exit(1) with ZipFile(args[1], 'r') as zf: badfile = zf.testzip() if badfile: print("The following enclosed file is corrupted: {!r}".format(badfile)) print("Done testing") elif args[0] == '-e': if len(args) != 3: print(USAGE) sys.exit(1) with ZipFile(args[1], 'r') as zf: zf.extractall(args[2]) elif args[0] == '-c': if len(args) < 3: print(USAGE) sys.exit(1) def addToZip(zf, path, zippath): if os.path.isfile(path): zf.write(path, zippath, ZIP_DEFLATED) elif os.path.isdir(path): if zippath: zf.write(path, zippath) for nm in os.listdir(path): addToZip(zf, os.path.join(path, nm), os.path.join(zippath, nm)) # else: ignore with ZipFile(args[1], 'w') as zf: for path in args[2:]: zippath = os.path.basename(path) if not zippath: zippath = os.path.basename(os.path.dirname(path)) if zippath in ('', os.curdir, os.pardir): zippath = '' addToZip(zf, path, zippath) if __name__ == "__main__": main()
tarfil源码:
#!/usr/bin/env python3 #------------------------------------------------------------------- # tarfile.py #------------------------------------------------------------------- # Copyright (C) 2002 Lars Gustaebel <lars@gustaebel.de> # All rights reserved. # # Permission is hereby granted, free of charge, to any person # obtaining a copy of this software and associated documentation # files (the "Software"), to deal in the Software without # restriction, including without limitation the rights to use, # copy, modify, merge, publish, distribute, sublicense, and/or sell # copies of the Software, and to permit persons to whom the # Software is furnished to do so, subject to the following # conditions: # # The above copyright notice and this permission notice shall be # included in all copies or substantial portions of the Software. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, # EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES # OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND # NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT # HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, # WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR # OTHER DEALINGS IN THE SOFTWARE. # """Read from and write to tar format archives. """ version = "0.9.0" __author__ = "Lars Gust\u00e4bel (lars@gustaebel.de)" __date__ = "$Date: 2011-02-25 17:42:01 +0200 (Fri, 25 Feb 2011) $" __cvsid__ = "$Id: tarfile.py 88586 2011-02-25 15:42:01Z marc-andre.lemburg $" __credits__ = "Gustavo Niemeyer, Niels Gust\u00e4bel, Richard Townsend." #--------- # Imports #--------- from builtins import open as bltn_open import sys import os import io import shutil import stat import time import struct import copy import re try: import grp, pwd except ImportError: grp = pwd = None # os.symlink on Windows prior to 6.0 raises NotImplementedError symlink_exception = (AttributeError, NotImplementedError) try: # OSError (winerror=1314) will be raised if the caller does not hold the # SeCreateSymbolicLinkPrivilege privilege symlink_exception += (OSError,) except NameError: pass # from tarfile import * __all__ = ["TarFile", "TarInfo", "is_tarfile", "TarError"] #--------------------------------------------------------- # tar constants #--------------------------------------------------------- NUL = b"\0" # the null character BLOCKSIZE = 512 # length of processing blocks RECORDSIZE = BLOCKSIZE * 20 # length of records GNU_MAGIC = b"ustar \0" # magic gnu tar string POSIX_MAGIC = b"ustar\x0000" # magic posix tar string LENGTH_NAME = 100 # maximum length of a filename LENGTH_LINK = 100 # maximum length of a linkname LENGTH_PREFIX = 155 # maximum length of the prefix field REGTYPE = b"0" # regular file AREGTYPE = b"\0" # regular file LNKTYPE = b"1" # link (inside tarfile) SYMTYPE = b"2" # symbolic link CHRTYPE = b"3" # character special device BLKTYPE = b"4" # block special device DIRTYPE = b"5" # directory FIFOTYPE = b"6" # fifo special device CONTTYPE = b"7" # contiguous file GNUTYPE_LONGNAME = b"L" # GNU tar longname GNUTYPE_LONGLINK = b"K" # GNU tar longlink GNUTYPE_SPARSE = b"S" # GNU tar sparse file XHDTYPE = b"x" # POSIX.1-2001 extended header XGLTYPE = b"g" # POSIX.1-2001 global header SOLARIS_XHDTYPE = b"X" # Solaris extended header USTAR_FORMAT = 0 # POSIX.1-1988 (ustar) format GNU_FORMAT = 1 # GNU tar format PAX_FORMAT = 2 # POSIX.1-2001 (pax) format DEFAULT_FORMAT = GNU_FORMAT #--------------------------------------------------------- # tarfile constants #--------------------------------------------------------- # File types that tarfile supports: SUPPORTED_TYPES = (REGTYPE, AREGTYPE, LNKTYPE, SYMTYPE, DIRTYPE, FIFOTYPE, CONTTYPE, CHRTYPE, BLKTYPE, GNUTYPE_LONGNAME, GNUTYPE_LONGLINK, GNUTYPE_SPARSE) # File types that will be treated as a regular file. REGULAR_TYPES = (REGTYPE, AREGTYPE, CONTTYPE, GNUTYPE_SPARSE) # File types that are part of the GNU tar format. GNU_TYPES = (GNUTYPE_LONGNAME, GNUTYPE_LONGLINK, GNUTYPE_SPARSE) # Fields from a pax header that override a TarInfo attribute. PAX_FIELDS = ("path", "linkpath", "size", "mtime", "uid", "gid", "uname", "gname") # Fields from a pax header that are affected by hdrcharset. PAX_NAME_FIELDS = {"path", "linkpath", "uname", "gname"} # Fields in a pax header that are numbers, all other fields # are treated as strings. PAX_NUMBER_FIELDS = { "atime": float, "ctime": float, "mtime": float, "uid": int, "gid": int, "size": int } #--------------------------------------------------------- # initialization #--------------------------------------------------------- if os.name in ("nt", "ce"): ENCODING = "utf-8" else: ENCODING = sys.getfilesystemencoding() #--------------------------------------------------------- # Some useful functions #--------------------------------------------------------- def stn(s, length, encoding, errors): """Convert a string to a null-terminated bytes object. """ s = s.encode(encoding, errors) return s[:length] + (length - len(s)) * NUL def nts(s, encoding, errors): """Convert a null-terminated bytes object to a string. """ p = s.find(b"\0") if p != -1: s = s[:p] return s.decode(encoding, errors) def nti(s): """Convert a number field to a python number. """ # There are two possible encodings for a number field, see # itn() below. if s[0] in (0o200, 0o377): n = 0 for i in range(len(s) - 1): n <<= 8 n += s[i + 1] if s[0] == 0o377: n = -(256 ** (len(s) - 1) - n) else: try: s = nts(s, "ascii", "strict") n = int(s.strip() or "0", 8) except ValueError: raise InvalidHeaderError("invalid header") return n def itn(n, digits=8, format=DEFAULT_FORMAT): """Convert a python number to a number field. """ # POSIX 1003.1-1988 requires numbers to be encoded as a string of # octal digits followed by a null-byte, this allows values up to # (8**(digits-1))-1. GNU tar allows storing numbers greater than # that if necessary. A leading 0o200 or 0o377 byte indicate this # particular encoding, the following digits-1 bytes are a big-endian # base-256 representation. This allows values up to (256**(digits-1))-1. # A 0o200 byte indicates a positive number, a 0o377 byte a negative # number. if 0 <= n < 8 ** (digits - 1): s = bytes("%0*o" % (digits - 1, int(n)), "ascii") + NUL elif format == GNU_FORMAT and -256 ** (digits - 1) <= n < 256 ** (digits - 1): if n >= 0: s = bytearray([0o200]) else: s = bytearray([0o377]) n = 256 ** digits + n for i in range(digits - 1): s.insert(1, n & 0o377) n >>= 8 else: raise ValueError("overflow in number field") return s def calc_chksums(buf): """Calculate the checksum for a member's header by summing up all characters except for the chksum field which is treated as if it was filled with spaces. According to the GNU tar sources, some tars (Sun and NeXT) calculate chksum with signed char, which will be different if there are chars in the buffer with the high bit set. So we calculate two checksums, unsigned and signed. """ unsigned_chksum = 256 + sum(struct.unpack_from("148B8x356B", buf)) signed_chksum = 256 + sum(struct.unpack_from("148b8x356b", buf)) return unsigned_chksum, signed_chksum def copyfileobj(src, dst, length=None, exception=OSError): """Copy length bytes from fileobj src to fileobj dst. If length is None, copy the entire content. """ if length == 0: return if length is None: shutil.copyfileobj(src, dst) return BUFSIZE = 16 * 1024 blocks, remainder = divmod(length, BUFSIZE) for b in range(blocks): buf = src.read(BUFSIZE) if len(buf) < BUFSIZE: raise exception("unexpected end of data") dst.write(buf) if remainder != 0: buf = src.read(remainder) if len(buf) < remainder: raise exception("unexpected end of data") dst.write(buf) return def filemode(mode): """Deprecated in this location; use stat.filemode.""" import warnings warnings.warn("deprecated in favor of stat.filemode", DeprecationWarning, 2) return stat.filemode(mode) def _safe_print(s): encoding = getattr(sys.stdout, 'encoding', None) if encoding is not None: s = s.encode(encoding, 'backslashreplace').decode(encoding) print(s, end=' ') class TarError(Exception): """Base exception.""" pass class ExtractError(TarError): """General exception for extract errors.""" pass class ReadError(TarError): """Exception for unreadable tar archives.""" pass class CompressionError(TarError): """Exception for unavailable compression methods.""" pass class StreamError(TarError): """Exception for unsupported operations on stream-like TarFiles.""" pass class HeaderError(TarError): """Base exception for header errors.""" pass class EmptyHeaderError(HeaderError): """Exception for empty headers.""" pass class TruncatedHeaderError(HeaderError): """Exception for truncated headers.""" pass class EOFHeaderError(HeaderError): """Exception for end of file headers.""" pass class InvalidHeaderError(HeaderError): """Exception for invalid headers.""" pass class SubsequentHeaderError(HeaderError): """Exception for missing and invalid extended headers.""" pass #--------------------------- # internal stream interface #--------------------------- class _LowLevelFile: """Low-level file object. Supports reading and writing. It is used instead of a regular file object for streaming access. """ def __init__(self, name, mode): mode = { "r": os.O_RDONLY, "w": os.O_WRONLY | os.O_CREAT | os.O_TRUNC, }[mode] if hasattr(os, "O_BINARY"): mode |= os.O_BINARY self.fd = os.open(name, mode, 0o666) def close(self): os.close(self.fd) def read(self, size): return os.read(self.fd, size) def write(self, s): os.write(self.fd, s) class _Stream: """Class that serves as an adapter between TarFile and a stream-like object. The stream-like object only needs to have a read() or write() method and is accessed blockwise. Use of gzip or bzip2 compression is possible. A stream-like object could be for example: sys.stdin, sys.stdout, a socket, a tape device etc. _Stream is intended to be used only internally. """ def __init__(self, name, mode, comptype, fileobj, bufsize): """Construct a _Stream object. """ self._extfileobj = True if fileobj is None: fileobj = _LowLevelFile(name, mode) self._extfileobj = False if comptype == '*': # Enable transparent compression detection for the # stream interface fileobj = _StreamProxy(fileobj) comptype = fileobj.getcomptype() self.name = name or "" self.mode = mode self.comptype = comptype self.fileobj = fileobj self.bufsize = bufsize self.buf = b"" self.pos = 0 self.closed = False try: if comptype == "gz": try: import zlib except ImportError: raise CompressionError("zlib module is not available") self.zlib = zlib self.crc = zlib.crc32(b"") if mode == "r": self._init_read_gz() self.exception = zlib.error else: self._init_write_gz() elif comptype == "bz2": try: import bz2 except ImportError: raise CompressionError("bz2 module is not available") if mode == "r": self.dbuf = b"" self.cmp = bz2.BZ2Decompressor() self.exception = OSError else: self.cmp = bz2.BZ2Compressor() elif comptype == "xz": try: import lzma except ImportError: raise CompressionError("lzma module is not available") if mode == "r": self.dbuf = b"" self.cmp = lzma.LZMADecompressor() self.exception = lzma.LZMAError else: self.cmp = lzma.LZMACompressor() elif comptype != "tar": raise CompressionError("unknown compression type %r" % comptype) except: if not self._extfileobj: self.fileobj.close() self.closed = True raise def __del__(self): if hasattr(self, "closed") and not self.closed: self.close() def _init_write_gz(self): """Initialize for writing with gzip compression. """ self.cmp = self.zlib.compressobj(9, self.zlib.DEFLATED, -self.zlib.MAX_WBITS, self.zlib.DEF_MEM_LEVEL, 0) timestamp = struct.pack("<L", int(time.time())) self.__write(b"\037\213\010\010" + timestamp + b"\002\377") if self.name.endswith(".gz"): self.name = self.name[:-3] # RFC1952 says we must use ISO-8859-1 for the FNAME field. self.__write(self.name.encode("iso-8859-1", "replace") + NUL) def write(self, s): """Write string s to the stream. """ if self.comptype == "gz": self.crc = self.zlib.crc32(s, self.crc) self.pos += len(s) if self.comptype != "tar": s = self.cmp.compress(s) self.__write(s) def __write(self, s): """Write string s to the stream if a whole new block is ready to be written. """ self.buf += s while len(self.buf) > self.bufsize: self.fileobj.write(self.buf[:self.bufsize]) self.buf = self.buf[self.bufsize:] def close(self): """Close the _Stream object. No operation should be done on it afterwards. """ if self.closed: return self.closed = True try: if self.mode == "w" and self.comptype != "tar": self.buf += self.cmp.flush() if self.mode == "w" and self.buf: self.fileobj.write(self.buf) self.buf = b"" if self.comptype == "gz": # The native zlib crc is an unsigned 32-bit integer, but # the Python wrapper implicitly casts that to a signed C # long. So, on a 32-bit box self.crc may "look negative", # while the same crc on a 64-bit box may "look positive". # To avoid irksome warnings from the `struct` module, force # it to look positive on all boxes. self.fileobj.write(struct.pack("<L", self.crc & 0xffffffff)) self.fileobj.write(struct.pack("<L", self.pos & 0xffffFFFF)) finally: if not self._extfileobj: self.fileobj.close() def _init_read_gz(self): """Initialize for reading a gzip compressed fileobj. """ self.cmp = self.zlib.decompressobj(-self.zlib.MAX_WBITS) self.dbuf = b"" # taken from gzip.GzipFile with some alterations if self.__read(2) != b"\037\213": raise ReadError("not a gzip file") if self.__read(1) != b"\010": raise CompressionError("unsupported compression method") flag = ord(self.__read(1)) self.__read(6) if flag & 4: xlen = ord(self.__read(1)) + 256 * ord(self.__read(1)) self.read(xlen) if flag & 8: while True: s = self.__read(1) if not s or s == NUL: break if flag & 16: while True: s = self.__read(1) if not s or s == NUL: break if flag & 2: self.__read(2) def tell(self): """Return the stream's file pointer position. """ return self.pos def seek(self, pos=0): """Set the stream's file pointer to pos. Negative seeking is forbidden. """ if pos - self.pos >= 0: blocks, remainder = divmod(pos - self.pos, self.bufsize) for i in range(blocks): self.read(self.bufsize) self.read(remainder) else: raise StreamError("seeking backwards is not allowed") return self.pos def read(self, size=None): """Return the next size number of bytes from the stream. If size is not defined, return all bytes of the stream up to EOF. """ if size is None: t = [] while True: buf = self._read(self.bufsize) if not buf: break t.append(buf) buf = "".join(t) else: buf = self._read(size) self.pos += len(buf) return buf def _read(self, size): """Return size bytes from the stream. """ if self.comptype == "tar": return self.__read(size) c = len(self.dbuf) while c < size: buf = self.__read(self.bufsize) if not buf: break try: buf = self.cmp.decompress(buf) except self.exception: raise ReadError("invalid compressed data") self.dbuf += buf c += len(buf) buf = self.dbuf[:size] self.dbuf = self.dbuf[size:] return buf def __read(self, size): """Return size bytes from stream. If internal buffer is empty, read another block from the stream. """ c = len(self.buf) while c < size: buf = self.fileobj.read(self.bufsize) if not buf: break self.buf += buf c += len(buf) buf = self.buf[:size] self.buf = self.buf[size:] return buf # class _Stream class _StreamProxy(object): """Small proxy class that enables transparent compression detection for the Stream interface (mode 'r|*'). """ def __init__(self, fileobj): self.fileobj = fileobj self.buf = self.fileobj.read(BLOCKSIZE) def read(self, size): self.read = self.fileobj.read return self.buf def getcomptype(self): if self.buf.startswith(b"\x1f\x8b\x08"): return "gz" elif self.buf[0:3] == b"BZh" and self.buf[4:10] == b"1AY&SY": return "bz2" elif self.buf.startswith((b"\x5d\x00\x00\x80", b"\xfd7zXZ")): return "xz" else: return "tar" def close(self): self.fileobj.close() # class StreamProxy #------------------------ # Extraction file object #------------------------ class _FileInFile(object): """A thin wrapper around an existing file object that provides a part of its data as an individual file object. """ def __init__(self, fileobj, offset, size, blockinfo=None): self.fileobj = fileobj self.offset = offset self.size = size self.position = 0 self.name = getattr(fileobj, "name", None) self.closed = False if blockinfo is None: blockinfo = [(0, size)] # Construct a map with data and zero blocks. self.map_index = 0 self.map = [] lastpos = 0 realpos = self.offset for offset, size in blockinfo: if offset > lastpos: self.map.append((False, lastpos, offset, None)) self.map.append((True, offset, offset + size, realpos)) realpos += size lastpos = offset + size if lastpos < self.size: self.map.append((False, lastpos, self.size, None)) def flush(self): pass def readable(self): return True def writable(self): return False def seekable(self): return self.fileobj.seekable() def tell(self): """Return the current file position. """ return self.position def seek(self, position, whence=io.SEEK_SET): """Seek to a position in the file. """ if whence == io.SEEK_SET: self.position = min(max(position, 0), self.size) elif whence == io.SEEK_CUR: if position < 0: self.position = max(self.position + position, 0) else: self.position = min(self.position + position, self.size) elif whence == io.SEEK_END: self.position = max(min(self.size + position, self.size), 0) else: raise ValueError("Invalid argument") return self.position def read(self, size=None): """Read data from the file. """ if size is None: size = self.size - self.position else: size = min(size, self.size - self.position) buf = b"" while size > 0: while True: data, start, stop, offset = self.map[self.map_index] if start <= self.position < stop: break else: self.map_index += 1 if self.map_index == len(self.map): self.map_index = 0 length = min(size, stop - self.position) if data: self.fileobj.seek(offset + (self.position - start)) b = self.fileobj.read(length) if len(b) != length: raise ReadError("unexpected end of data") buf += b else: buf += NUL * length size -= length self.position += length return buf def readinto(self, b): buf = self.read(len(b)) b[:len(buf)] = buf return len(buf) def close(self): self.closed = True #class _FileInFile class ExFileObject(io.BufferedReader): def __init__(self, tarfile, tarinfo): fileobj = _FileInFile(tarfile.fileobj, tarinfo.offset_data, tarinfo.size, tarinfo.sparse) super().__init__(fileobj) #class ExFileObject #------------------ # Exported Classes #------------------ class TarInfo(object): """Informational class which holds the details about an archive member given by a tar header block. TarInfo objects are returned by TarFile.getmember(), TarFile.getmembers() and TarFile.gettarinfo() and are usually created internally. """ __slots__ = ("name", "mode", "uid", "gid", "size", "mtime", "chksum", "type", "linkname", "uname", "gname", "devmajor", "devminor", "offset", "offset_data", "pax_headers", "sparse", "tarfile", "_sparse_structs", "_link_target") def __init__(self, name=""): """Construct a TarInfo object. name is the optional name of the member. """ self.name = name # member name self.mode = 0o644 # file permissions self.uid = 0 # user id self.gid = 0 # group id self.size = 0 # file size self.mtime = 0 # modification time self.chksum = 0 # header checksum self.type = REGTYPE # member type self.linkname = "" # link name self.uname = "" # user name self.gname = "" # group name self.devmajor = 0 # device major number self.devminor = 0 # device minor number self.offset = 0 # the tar header starts here self.offset_data = 0 # the file's data starts here self.sparse = None # sparse member information self.pax_headers = {} # pax header information # In pax headers the "name" and "linkname" field are called # "path" and "linkpath". def _getpath(self): return self.name def _setpath(self, name): self.name = name path = property(_getpath, _setpath) def _getlinkpath(self): return self.linkname def _setlinkpath(self, linkname): self.linkname = linkname linkpath = property(_getlinkpath, _setlinkpath) def __repr__(self): return "<%s %r at %#x>" % (self.__class__.__name__,self.name,id(self)) def get_info(self): """Return the TarInfo's attributes as a dictionary. """ info = { "name": self.name, "mode": self.mode & 0o7777, "uid": self.uid, "gid": self.gid, "size": self.size, "mtime": self.mtime, "chksum": self.chksum, "type": self.type, "linkname": self.linkname, "uname": self.uname, "gname": self.gname, "devmajor": self.devmajor, "devminor": self.devminor } if info["type"] == DIRTYPE and not info["name"].endswith("/"): info["name"] += "/" return info def tobuf(self, format=DEFAULT_FORMAT, encoding=ENCODING, errors="surrogateescape"): """Return a tar header as a string of 512 byte blocks. """ info = self.get_info() if format == USTAR_FORMAT: return self.create_ustar_header(info, encoding, errors) elif format == GNU_FORMAT: return self.create_gnu_header(info, encoding, errors) elif format == PAX_FORMAT: return self.create_pax_header(info, encoding) else: raise ValueError("invalid format") def create_ustar_header(self, info, encoding, errors): """Return the object as a ustar header block. """ info["magic"] = POSIX_MAGIC if len(info["linkname"]) > LENGTH_LINK: raise ValueError("linkname is too long") if len(info["name"]) > LENGTH_NAME: info["prefix"], info["name"] = self._posix_split_name(info["name"]) return self._create_header(info, USTAR_FORMAT, encoding, errors) def create_gnu_header(self, info, encoding, errors): """Return the object as a GNU header block sequence. """ info["magic"] = GNU_MAGIC buf = b"" if len(info["linkname"]) > LENGTH_LINK: buf += self._create_gnu_long_header(info["linkname"], GNUTYPE_LONGLINK, encoding, errors) if len(info["name"]) > LENGTH_NAME: buf += self._create_gnu_long_header(info["name"], GNUTYPE_LONGNAME, encoding, errors) return buf + self._create_header(info, GNU_FORMAT, encoding, errors) def create_pax_header(self, info, encoding): """Return the object as a ustar header block. If it cannot be represented this way, prepend a pax extended header sequence with supplement information. """ info["magic"] = POSIX_MAGIC pax_headers = self.pax_headers.copy() # Test string fields for values that exceed the field length or cannot # be represented in ASCII encoding. for name, hname, length in ( ("name", "path", LENGTH_NAME), ("linkname", "linkpath", LENGTH_LINK), ("uname", "uname", 32), ("gname", "gname", 32)): if hname in pax_headers: # The pax header has priority. continue # Try to encode the string as ASCII. try: info[name].encode("ascii", "strict") except UnicodeEncodeError: pax_headers[hname] = info[name] continue if len(info[name]) > length: pax_headers[hname] = info[name] # Test number fields for values that exceed the field limit or values # that like to be stored as float. for name, digits in (("uid", 8), ("gid", 8), ("size", 12), ("mtime", 12)): if name in pax_headers: # The pax header has priority. Avoid overflow. info[name] = 0 continue val = info[name] if not 0 <= val < 8 ** (digits - 1) or isinstance(val, float): pax_headers[name] = str(val) info[name] = 0 # Create a pax extended header if necessary. if pax_headers: buf = self._create_pax_generic_header(pax_headers, XHDTYPE, encoding) else: buf = b"" return buf + self._create_header(info, USTAR_FORMAT, "ascii", "replace") @classmethod def create_pax_global_header(cls, pax_headers): """Return the object as a pax global header block sequence. """ return cls._create_pax_generic_header(pax_headers, XGLTYPE, "utf-8") def _posix_split_name(self, name): """Split a name longer than 100 chars into a prefix and a name part. """ prefix = name[:LENGTH_PREFIX + 1] while prefix and prefix[-1] != "/": prefix = prefix[:-1] name = name[len(prefix):] prefix = prefix[:-1] if not prefix or len(name) > LENGTH_NAME: raise ValueError("name is too long") return prefix, name @staticmethod def _create_header(info, format, encoding, errors): """Return a header block. info is a dictionary with file information, format must be one of the *_FORMAT constants. """ parts = [ stn(info.get("name", ""), 100, encoding, errors), itn(info.get("mode", 0) & 0o7777, 8, format), itn(info.get("uid", 0), 8, format), itn(info.get("gid", 0), 8, format), itn(info.get("size", 0), 12, format), itn(info.get("mtime", 0), 12, format), b" ", # checksum field info.get("type", REGTYPE), stn(info.get("linkname", ""), 100, encoding, errors), info.get("magic", POSIX_MAGIC), stn(info.get("uname", ""), 32, encoding, errors), stn(info.get("gname", ""), 32, encoding, errors), itn(info.get("devmajor", 0), 8, format), itn(info.get("devminor", 0), 8, format), stn(info.get("prefix", ""), 155, encoding, errors) ] buf = struct.pack("%ds" % BLOCKSIZE, b"".join(parts)) chksum = calc_chksums(buf[-BLOCKSIZE:])[0] buf = buf[:-364] + bytes("%06o\0" % chksum, "ascii") + buf[-357:] return buf @staticmethod def _create_payload(payload): """Return the string payload filled with zero bytes up to the next 512 byte border. """ blocks, remainder = divmod(len(payload), BLOCKSIZE) if remainder > 0: payload += (BLOCKSIZE - remainder) * NUL return payload @classmethod def _create_gnu_long_header(cls, name, type, encoding, errors): """Return a GNUTYPE_LONGNAME or GNUTYPE_LONGLINK sequence for name. """ name = name.encode(encoding, errors) + NUL info = {} info["name"] = "././@LongLink" info["type"] = type info["size"] = len(name) info["magic"] = GNU_MAGIC # create extended header + name blocks. return cls._create_header(info, USTAR_FORMAT, encoding, errors) + \ cls._create_payload(name) @classmethod def _create_pax_generic_header(cls, pax_headers, type, encoding): """Return a POSIX.1-2008 extended or global header sequence that contains a list of keyword, value pairs. The values must be strings. """ # Check if one of the fields contains surrogate characters and thereby # forces hdrcharset=BINARY, see _proc_pax() for more information. binary = False for keyword, value in pax_headers.items(): try: value.encode("utf-8", "strict") except UnicodeEncodeError: binary = True break records = b"" if binary: # Put the hdrcharset field at the beginning of the header. records += b"21 hdrcharset=BINARY\n" for keyword, value in pax_headers.items(): keyword = keyword.encode("utf-8") if binary: # Try to restore the original byte representation of `value'. # Needless to say, that the encoding must match the string. value = value.encode(encoding, "surrogateescape") else: value = value.encode("utf-8") l = len(keyword) + len(value) + 3 # ' ' + '=' + '\n' n = p = 0 while True: n = l + len(str(p)) if n == p: break p = n records += bytes(str(p), "ascii") + b" " + keyword + b"=" + value + b"\n" # We use a hardcoded "././@PaxHeader" name like star does # instead of the one that POSIX recommends. info = {} info["name"] = "././@PaxHeader" info["type"] = type info["size"] = len(records) info["magic"] = POSIX_MAGIC # Create pax header + record blocks. return cls._create_header(info, USTAR_FORMAT, "ascii", "replace") + \ cls._create_payload(records) @classmethod def frombuf(cls, buf, encoding, errors): """Construct a TarInfo object from a 512 byte bytes object. """ if len(buf) == 0: raise EmptyHeaderError("empty header") if len(buf) != BLOCKSIZE: raise TruncatedHeaderError("truncated header") if buf.count(NUL) == BLOCKSIZE: raise EOFHeaderError("end of file header") chksum = nti(buf[148:156]) if chksum not in calc_chksums(buf): raise InvalidHeaderError("bad checksum") obj = cls() obj.name = nts(buf[0:100], encoding, errors) obj.mode = nti(buf[100:108]) obj.uid = nti(buf[108:116]) obj.gid = nti(buf[116:124]) obj.size = nti(buf[124:136]) obj.mtime = nti(buf[136:148]) obj.chksum = chksum obj.type = buf[156:157] obj.linkname = nts(buf[157:257], encoding, errors) obj.uname = nts(buf[265:297], encoding, errors) obj.gname = nts(buf[297:329], encoding, errors) obj.devmajor = nti(buf[329:337]) obj.devminor = nti(buf[337:345]) prefix = nts(buf[345:500], encoding, errors) # Old V7 tar format represents a directory as a regular # file with a trailing slash. if obj.type == AREGTYPE and obj.name.endswith("/"): obj.type = DIRTYPE # The old GNU sparse format occupies some of the unused # space in the buffer for up to 4 sparse structures. # Save the them for later processing in _proc_sparse(). if obj.type == GNUTYPE_SPARSE: pos = 386 structs = [] for i in range(4): try: offset = nti(buf[pos:pos + 12]) numbytes = nti(buf[pos + 12:pos + 24]) except ValueError: break structs.append((offset, numbytes)) pos += 24 isextended = bool(buf[482]) origsize = nti(buf[483:495]) obj._sparse_structs = (structs, isextended, origsize) # Remove redundant slashes from directories. if obj.isdir(): obj.name = obj.name.rstrip("/") # Reconstruct a ustar longname. if prefix and obj.type not in GNU_TYPES: obj.name = prefix + "/" + obj.name return obj @classmethod def fromtarfile(cls, tarfile): """Return the next TarInfo object from TarFile object tarfile. """ buf = tarfile.fileobj.read(BLOCKSIZE) obj = cls.frombuf(buf, tarfile.encoding, tarfile.errors) obj.offset = tarfile.fileobj.tell() - BLOCKSIZE return obj._proc_member(tarfile) #-------------------------------------------------------------------------- # The following are methods that are called depending on the type of a # member. The entry point is _proc_member() which can be overridden in a # subclass to add custom _proc_*() methods. A _proc_*() method MUST # implement the following # operations: # 1. Set self.offset_data to the position where the data blocks begin, # if there is data that follows. # 2. Set tarfile.offset to the position where the next member's header will # begin. # 3. Return self or another valid TarInfo object. def _proc_member(self, tarfile): """Choose the right processing method depending on the type and call it. """ if self.type in (GNUTYPE_LONGNAME, GNUTYPE_LONGLINK): return self._proc_gnulong(tarfile) elif self.type == GNUTYPE_SPARSE: return self._proc_sparse(tarfile) elif self.type in (XHDTYPE, XGLTYPE, SOLARIS_XHDTYPE): return self._proc_pax(tarfile) else: return self._proc_builtin(tarfile) def _proc_builtin(self, tarfile): """Process a builtin type or an unknown type which will be treated as a regular file. """ self.offset_data = tarfile.fileobj.tell() offset = self.offset_data if self.isreg() or self.type not in SUPPORTED_TYPES: # Skip the following data blocks. offset += self._block(self.size) tarfile.offset = offset # Patch the TarInfo object with saved global # header information. self._apply_pax_info(tarfile.pax_headers, tarfile.encoding, tarfile.errors) return self def _proc_gnulong(self, tarfile): """Process the blocks that hold a GNU longname or longlink member. """ buf = tarfile.fileobj.read(self._block(self.size)) # Fetch the next header and process it. try: next = self.fromtarfile(tarfile) except HeaderError: raise SubsequentHeaderError("missing or bad subsequent header") # Patch the TarInfo object from the next header with # the longname information. next.offset = self.offset if self.type == GNUTYPE_LONGNAME: next.name = nts(buf, tarfile.encoding, tarfile.errors) elif self.type == GNUTYPE_LONGLINK: next.linkname = nts(buf, tarfile.encoding, tarfile.errors) return next def _proc_sparse(self, tarfile): """Process a GNU sparse header plus extra headers. """ # We already collected some sparse structures in frombuf(). structs, isextended, origsize = self._sparse_structs del self._sparse_structs # Collect sparse structures from extended header blocks. while isextended: buf = tarfile.fileobj.read(BLOCKSIZE) pos = 0 for i in range(21): try: offset = nti(buf[pos:pos + 12]) numbytes = nti(buf[pos + 12:pos + 24]) except ValueError: break if offset and numbytes: structs.append((offset, numbytes)) pos += 24 isextended = bool(buf[504]) self.sparse = structs self.offset_data = tarfile.fileobj.tell() tarfile.offset = self.offset_data + self._block(self.size) self.size = origsize return self def _proc_pax(self, tarfile): """Process an extended or global header as described in POSIX.1-2008. """ # Read the header information. buf = tarfile.fileobj.read(self._block(self.size)) # A pax header stores supplemental information for either # the following file (extended) or all following files # (global). if self.type == XGLTYPE: pax_headers = tarfile.pax_headers else: pax_headers = tarfile.pax_headers.copy() # Check if the pax header contains a hdrcharset field. This tells us # the encoding of the path, linkpath, uname and gname fields. Normally, # these fields are UTF-8 encoded but since POSIX.1-2008 tar # implementations are allowed to store them as raw binary strings if # the translation to UTF-8 fails. match = re.search(br"\d+ hdrcharset=([^\n]+)\n", buf) if match is not None: pax_headers["hdrcharset"] = match.group(1).decode("utf-8") # For the time being, we don't care about anything other than "BINARY". # The only other value that is currently allowed by the standard is # "ISO-IR 10646 2000 UTF-8" in other words UTF-8. hdrcharset = pax_headers.get("hdrcharset") if hdrcharset == "BINARY": encoding = tarfile.encoding else: encoding = "utf-8" # Parse pax header information. A record looks like that: # "%d %s=%s\n" % (length, keyword, value). length is the size # of the complete record including the length field itself and # the newline. keyword and value are both UTF-8 encoded strings. regex = re.compile(br"(\d+) ([^=]+)=") pos = 0 while True: match = regex.match(buf, pos) if not match: break length, keyword = match.groups() length = int(length) value = buf[match.end(2) + 1:match.start(1) + length - 1] # Normally, we could just use "utf-8" as the encoding and "strict" # as the error handler, but we better not take the risk. For # example, GNU tar <= 1.23 is known to store filenames it cannot # translate to UTF-8 as raw strings (unfortunately without a # hdrcharset=BINARY header). # We first try the strict standard encoding, and if that fails we # fall back on the user's encoding and error handler. keyword = self._decode_pax_field(keyword, "utf-8", "utf-8", tarfile.errors) if keyword in PAX_NAME_FIELDS: value = self._decode_pax_field(value, encoding, tarfile.encoding, tarfile.errors) else: value = self._decode_pax_field(value, "utf-8", "utf-8", tarfile.errors) pax_headers[keyword] = value pos += length # Fetch the next header. try: next = self.fromtarfile(tarfile) except HeaderError: raise SubsequentHeaderError("missing or bad subsequent header") # Process GNU sparse information. if "GNU.sparse.map" in pax_headers: # GNU extended sparse format version 0.1. self._proc_gnusparse_01(next, pax_headers) elif "GNU.sparse.size" in pax_headers: # GNU extended sparse format version 0.0. self._proc_gnusparse_00(next, pax_headers, buf) elif pax_headers.get("GNU.sparse.major") == "1" and pax_headers.get("GNU.sparse.minor") == "0": # GNU extended sparse format version 1.0. self._proc_gnusparse_10(next, pax_headers, tarfile) if self.type in (XHDTYPE, SOLARIS_XHDTYPE): # Patch the TarInfo object with the extended header info. next._apply_pax_info(pax_headers, tarfile.encoding, tarfile.errors) next.offset = self.offset if "size" in pax_headers: # If the extended header replaces the size field, # we need to recalculate the offset where the next # header starts. offset = next.offset_data if next.isreg() or next.type not in SUPPORTED_TYPES: offset += next._block(next.size) tarfile.offset = offset return next def _proc_gnusparse_00(self, next, pax_headers, buf): """Process a GNU tar extended sparse header, version 0.0. """ offsets = [] for match in re.finditer(br"\d+ GNU.sparse.offset=(\d+)\n", buf): offsets.append(int(match.group(1))) numbytes = [] for match in re.finditer(br"\d+ GNU.sparse.numbytes=(\d+)\n", buf): numbytes.append(int(match.group(1))) next.sparse = list(zip(offsets, numbytes)) def _proc_gnusparse_01(self, next, pax_headers): """Process a GNU tar extended sparse header, version 0.1. """ sparse = [int(x) for x in pax_headers["GNU.sparse.map"].split(",")] next.sparse = list(zip(sparse[::2], sparse[1::2])) def _proc_gnusparse_10(self, next, pax_headers, tarfile): """Process a GNU tar extended sparse header, version 1.0. """ fields = None sparse = [] buf = tarfile.fileobj.read(BLOCKSIZE) fields, buf = buf.split(b"\n", 1) fields = int(fields) while len(sparse) < fields * 2: if b"\n" not in buf: buf += tarfile.fileobj.read(BLOCKSIZE) number, buf = buf.split(b"\n", 1) sparse.append(int(number)) next.offset_data = tarfile.fileobj.tell() next.sparse = list(zip(sparse[::2], sparse[1::2])) def _apply_pax_info(self, pax_headers, encoding, errors): """Replace fields with supplemental information from a previous pax extended or global header. """ for keyword, value in pax_headers.items(): if keyword == "GNU.sparse.name": setattr(self, "path", value) elif keyword == "GNU.sparse.size": setattr(self, "size", int(value)) elif keyword == "GNU.sparse.realsize": setattr(self, "size", int(value)) elif keyword in PAX_FIELDS: if keyword in PAX_NUMBER_FIELDS: try: value = PAX_NUMBER_FIELDS[keyword](value) except ValueError: value = 0 if keyword == "path": value = value.rstrip("/") setattr(self, keyword, value) self.pax_headers = pax_headers.copy() def _decode_pax_field(self, value, encoding, fallback_encoding, fallback_errors): """Decode a single field from a pax record. """ try: return value.decode(encoding, "strict") except UnicodeDecodeError: return value.decode(fallback_encoding, fallback_errors) def _block(self, count): """Round up a byte count by BLOCKSIZE and return it, e.g. _block(834) => 1024. """ blocks, remainder = divmod(count, BLOCKSIZE) if remainder: blocks += 1 return blocks * BLOCKSIZE def isreg(self): return self.type in REGULAR_TYPES def isfile(self): return self.isreg() def isdir(self): return self.type == DIRTYPE def issym(self): return self.type == SYMTYPE def islnk(self): return self.type == LNKTYPE def ischr(self): return self.type == CHRTYPE def isblk(self): return self.type == BLKTYPE def isfifo(self): return self.type == FIFOTYPE def issparse(self): return self.sparse is not None def isdev(self): return self.type in (CHRTYPE, BLKTYPE, FIFOTYPE) # class TarInfo class TarFile(object): """The TarFile Class provides an interface to tar archives. """ debug = 0 # May be set from 0 (no msgs) to 3 (all msgs) dereference = False # If true, add content of linked file to the # tar file, else the link. ignore_zeros = False # If true, skips empty or invalid blocks and # continues processing. errorlevel = 1 # If 0, fatal errors only appear in debug # messages (if debug >= 0). If > 0, errors # are passed to the caller as exceptions. format = DEFAULT_FORMAT # The format to use when creating an archive. encoding = ENCODING # Encoding for 8-bit character strings. errors = None # Error handler for unicode conversion. tarinfo = TarInfo # The default TarInfo class to use. fileobject = ExFileObject # The file-object for extractfile(). def __init__(self, name=None, mode="r", fileobj=None, format=None, tarinfo=None, dereference=None, ignore_zeros=None, encoding=None, errors="surrogateescape", pax_headers=None, debug=None, errorlevel=None): """Open an (uncompressed) tar archive `name'. `mode' is either 'r' to read from an existing archive, 'a' to append data to an existing file or 'w' to create a new file overwriting an existing one. `mode' defaults to 'r'. If `fileobj' is given, it is used for reading or writing data. If it can be determined, `mode' is overridden by `fileobj's mode. `fileobj' is not closed, when TarFile is closed. """ modes = {"r": "rb", "a": "r+b", "w": "wb", "x": "xb"} if mode not in modes: raise ValueError("mode must be 'r', 'a', 'w' or 'x'") self.mode = mode self._mode = modes[mode] if not fileobj: if self.mode == "a" and not os.path.exists(name): # Create nonexistent files in append mode. self.mode = "w" self._mode = "wb" fileobj = bltn_open(name, self._mode) self._extfileobj = False else: if (name is None and hasattr(fileobj, "name") and isinstance(fileobj.name, (str, bytes))): name = fileobj.name if hasattr(fileobj, "mode"): self._mode = fileobj.mode self._extfileobj = True self.name = os.path.abspath(name) if name else None self.fileobj = fileobj # Init attributes. if format is not None: self.format = format if tarinfo is not None: self.tarinfo = tarinfo if dereference is not None: self.dereference = dereference if ignore_zeros is not None: self.ignore_zeros = ignore_zeros if encoding is not None: self.encoding = encoding self.errors = errors if pax_headers is not None and self.format == PAX_FORMAT: self.pax_headers = pax_headers else: self.pax_headers = {} if debug is not None: self.debug = debug if errorlevel is not None: self.errorlevel = errorlevel # Init datastructures. self.closed = False self.members = [] # list of members as TarInfo objects self._loaded = False # flag if all members have been read self.offset = self.fileobj.tell() # current position in the archive file self.inodes = {} # dictionary caching the inodes of # archive members already added try: if self.mode == "r": self.firstmember = None self.firstmember = self.next() if self.mode == "a": # Move to the end of the archive, # before the first empty block. while True: self.fileobj.seek(self.offset) try: tarinfo = self.tarinfo.fromtarfile(self) self.members.append(tarinfo) except EOFHeaderError: self.fileobj.seek(self.offset) break except HeaderError as e: raise ReadError(str(e)) if self.mode in ("a", "w", "x"): self._loaded = True if self.pax_headers: buf = self.tarinfo.create_pax_global_header(self.pax_headers.copy()) self.fileobj.write(buf) self.offset += len(buf) except: if not self._extfileobj: self.fileobj.close() self.closed = True raise #-------------------------------------------------------------------------- # Below are the classmethods which act as alternate constructors to the # TarFile class. The open() method is the only one that is needed for # public use; it is the "super"-constructor and is able to select an # adequate "sub"-constructor for a particular compression using the mapping # from OPEN_METH. # # This concept allows one to subclass TarFile without losing the comfort of # the super-constructor. A sub-constructor is registered and made available # by adding it to the mapping in OPEN_METH. @classmethod def open(cls, name=None, mode="r", fileobj=None, bufsize=RECORDSIZE, **kwargs): """Open a tar archive for reading, writing or appending. Return an appropriate TarFile class. mode: 'r' or 'r:*' open for reading with transparent compression 'r:' open for reading exclusively uncompressed 'r:gz' open for reading with gzip compression 'r:bz2' open for reading with bzip2 compression 'r:xz' open for reading with lzma compression 'a' or 'a:' open for appending, creating the file if necessary 'w' or 'w:' open for writing without compression 'w:gz' open for writing with gzip compression 'w:bz2' open for writing with bzip2 compression 'w:xz' open for writing with lzma compression 'x' or 'x:' create a tarfile exclusively without compression, raise an exception if the file is already created 'x:gz' create an gzip compressed tarfile, raise an exception if the file is already created 'x:bz2' create an bzip2 compressed tarfile, raise an exception if the file is already created 'x:xz' create an lzma compressed tarfile, raise an exception if the file is already created 'r|*' open a stream of tar blocks with transparent compression 'r|' open an uncompressed stream of tar blocks for reading 'r|gz' open a gzip compressed stream of tar blocks 'r|bz2' open a bzip2 compressed stream of tar blocks 'r|xz' open an lzma compressed stream of tar blocks 'w|' open an uncompressed stream for writing 'w|gz' open a gzip compressed stream for writing 'w|bz2' open a bzip2 compressed stream for writing 'w|xz' open an lzma compressed stream for writing """ if not name and not fileobj: raise ValueError("nothing to open") if mode in ("r", "r:*"): # Find out which *open() is appropriate for opening the file. for comptype in cls.OPEN_METH: func = getattr(cls, cls.OPEN_METH[comptype]) if fileobj is not None: saved_pos = fileobj.tell() try: return func(name, "r", fileobj, **kwargs) except (ReadError, CompressionError) as e: if fileobj is not None: fileobj.seek(saved_pos) continue raise ReadError("file could not be opened successfully") elif ":" in mode: filemode, comptype = mode.split(":", 1) filemode = filemode or "r" comptype = comptype or "tar" # Select the *open() function according to # given compression. if comptype in cls.OPEN_METH: func = getattr(cls, cls.OPEN_METH[comptype]) else: raise CompressionError("unknown compression type %r" % comptype) return func(name, filemode, fileobj, **kwargs) elif "|" in mode: filemode, comptype = mode.split("|", 1) filemode = filemode or "r" comptype = comptype or "tar" if filemode not in ("r", "w"): raise ValueError("mode must be 'r' or 'w'") stream = _Stream(name, filemode, comptype, fileobj, bufsize) try: t = cls(name, filemode, stream, **kwargs) except: stream.close() raise t._extfileobj = False return t elif mode in ("a", "w", "x"): return cls.taropen(name, mode, fileobj, **kwargs) raise ValueError("undiscernible mode") @classmethod def taropen(cls, name, mode="r", fileobj=None, **kwargs): """Open uncompressed tar archive name for reading or writing. """ if mode not in ("r", "a", "w", "x"): raise ValueError("mode must be 'r', 'a', 'w' or 'x'") return cls(name, mode, fileobj, **kwargs) @classmethod def gzopen(cls, name, mode="r", fileobj=None, compresslevel=9, **kwargs): """Open gzip compressed tar archive name for reading or writing. Appending is not allowed. """ if mode not in ("r", "w", "x"): raise ValueError("mode must be 'r', 'w' or 'x'") try: import gzip gzip.GzipFile except (ImportError, AttributeError): raise CompressionError("gzip module is not available") try: fileobj = gzip.GzipFile(name, mode + "b", compresslevel, fileobj) except OSError: if fileobj is not None and mode == 'r': raise ReadError("not a gzip file") raise try: t = cls.taropen(name, mode, fileobj, **kwargs) except OSError: fileobj.close() if mode == 'r': raise ReadError("not a gzip file") raise except: fileobj.close() raise t._extfileobj = False return t @classmethod def bz2open(cls, name, mode="r", fileobj=None, compresslevel=9, **kwargs): """Open bzip2 compressed tar archive name for reading or writing. Appending is not allowed. """ if mode not in ("r", "w", "x"): raise ValueError("mode must be 'r', 'w' or 'x'") try: import bz2 except ImportError: raise CompressionError("bz2 module is not available") fileobj = bz2.BZ2File(fileobj or name, mode, compresslevel=compresslevel) try: t = cls.taropen(name, mode, fileobj, **kwargs) except (OSError, EOFError): fileobj.close() if mode == 'r': raise ReadError("not a bzip2 file") raise except: fileobj.close() raise t._extfileobj = False return t @classmethod def xzopen(cls, name, mode="r", fileobj=None, preset=None, **kwargs): """Open lzma compressed tar archive name for reading or writing. Appending is not allowed. """ if mode not in ("r", "w", "x"): raise ValueError("mode must be 'r', 'w' or 'x'") try: import lzma except ImportError: raise CompressionError("lzma module is not available") fileobj = lzma.LZMAFile(fileobj or name, mode, preset=preset) try: t = cls.taropen(name, mode, fileobj, **kwargs) except (lzma.LZMAError, EOFError): fileobj.close() if mode == 'r': raise ReadError("not an lzma file") raise except: fileobj.close() raise t._extfileobj = False return t # All *open() methods are registered here. OPEN_METH = { "tar": "taropen", # uncompressed tar "gz": "gzopen", # gzip compressed tar "bz2": "bz2open", # bzip2 compressed tar "xz": "xzopen" # lzma compressed tar } #-------------------------------------------------------------------------- # The public methods which TarFile provides: def close(self): """Close the TarFile. In write-mode, two finishing zero blocks are appended to the archive. """ if self.closed: return self.closed = True try: if self.mode in ("a", "w", "x"): self.fileobj.write(NUL * (BLOCKSIZE * 2)) self.offset += (BLOCKSIZE * 2) # fill up the end with zero-blocks # (like option -b20 for tar does) blocks, remainder = divmod(self.offset, RECORDSIZE) if remainder > 0: self.fileobj.write(NUL * (RECORDSIZE - remainder)) finally: if not self._extfileobj: self.fileobj.close() def getmember(self, name): """Return a TarInfo object for member `name'. If `name' can not be found in the archive, KeyError is raised. If a member occurs more than once in the archive, its last occurrence is assumed to be the most up-to-date version. """ tarinfo = self._getmember(name) if tarinfo is None: raise KeyError("filename %r not found" % name) return tarinfo def getmembers(self): """Return the members of the archive as a list of TarInfo objects. The list has the same order as the members in the archive. """ self._check() if not self._loaded: # if we want to obtain a list of self._load() # all members, we first have to # scan the whole archive. return self.members def getnames(self): """Return the members of the archive as a list of their names. It has the same order as the list returned by getmembers(). """ return [tarinfo.name for tarinfo in self.getmembers()] def gettarinfo(self, name=None, arcname=None, fileobj=None): """Create a TarInfo object for either the file `name' or the file object `fileobj' (using os.fstat on its file descriptor). You can modify some of the TarInfo's attributes before you add it using addfile(). If given, `arcname' specifies an alternative name for the file in the archive. """ self._check("awx") # When fileobj is given, replace name by # fileobj's real name. if fileobj is not None: name = fileobj.name # Building the name of the member in the archive. # Backward slashes are converted to forward slashes, # Absolute paths are turned to relative paths. if arcname is None: arcname = name drv, arcname = os.path.splitdrive(arcname) arcname = arcname.replace(os.sep, "/") arcname = arcname.lstrip("/") # Now, fill the TarInfo object with # information specific for the file. tarinfo = self.tarinfo() tarinfo.tarfile = self # Use os.stat or os.lstat, depending on platform # and if symlinks shall be resolved. if fileobj is None: if hasattr(os, "lstat") and not self.dereference: statres = os.lstat(name) else: statres = os.stat(name) else: statres = os.fstat(fileobj.fileno()) linkname = "" stmd = statres.st_mode if stat.S_ISREG(stmd): inode = (statres.st_ino, statres.st_dev) if not self.dereference and statres.st_nlink > 1 and \ inode in self.inodes and arcname != self.inodes[inode]: # Is it a hardlink to an already # archived file? type = LNKTYPE linkname = self.inodes[inode] else: # The inode is added only if its valid. # For win32 it is always 0. type = REGTYPE if inode[0]: self.inodes[inode] = arcname elif stat.S_ISDIR(stmd): type = DIRTYPE elif stat.S_ISFIFO(stmd): type = FIFOTYPE elif stat.S_ISLNK(stmd): type = SYMTYPE linkname = os.readlink(name) elif stat.S_ISCHR(stmd): type = CHRTYPE elif stat.S_ISBLK(stmd): type = BLKTYPE else: return None # Fill the TarInfo object with all # information we can get. tarinfo.name = arcname tarinfo.mode = stmd tarinfo.uid = statres.st_uid tarinfo.gid = statres.st_gid if type == REGTYPE: tarinfo.size = statres.st_size else: tarinfo.size = 0 tarinfo.mtime = statres.st_mtime tarinfo.type = type tarinfo.linkname = linkname if pwd: try: tarinfo.uname = pwd.getpwuid(tarinfo.uid)[0] except KeyError: pass if grp: try: tarinfo.gname = grp.getgrgid(tarinfo.gid)[0] except KeyError: pass if type in (CHRTYPE, BLKTYPE): if hasattr(os, "major") and hasattr(os, "minor"): tarinfo.devmajor = os.major(statres.st_rdev) tarinfo.devminor = os.minor(statres.st_rdev) return tarinfo def list(self, verbose=True, *, members=None): """Print a table of contents to sys.stdout. If `verbose' is False, only the names of the members are printed. If it is True, an `ls -l'-like output is produced. `members' is optional and must be a subset of the list returned by getmembers(). """ self._check() if members is None: members = self for tarinfo in members: if verbose: _safe_print(stat.filemode(tarinfo.mode)) _safe_print("%s/%s" % (tarinfo.uname or tarinfo.uid, tarinfo.gname or tarinfo.gid)) if tarinfo.ischr() or tarinfo.isblk(): _safe_print("%10s" % ("%d,%d" % (tarinfo.devmajor, tarinfo.devminor))) else: _safe_print("%10d" % tarinfo.size) _safe_print("%d-%02d-%02d %02d:%02d:%02d" \ % time.localtime(tarinfo.mtime)[:6]) _safe_print(tarinfo.name + ("/" if tarinfo.isdir() else "")) if verbose: if tarinfo.issym(): _safe_print("-> " + tarinfo.linkname) if tarinfo.islnk(): _safe_print("link to " + tarinfo.linkname) print() def add(self, name, arcname=None, recursive=True, exclude=None, *, filter=None): """Add the file `name' to the archive. `name' may be any type of file (directory, fifo, symbolic link, etc.). If given, `arcname' specifies an alternative name for the file in the archive. Directories are added recursively by default. This can be avoided by setting `recursive' to False. `exclude' is a function that should return True for each filename to be excluded. `filter' is a function that expects a TarInfo object argument and returns the changed TarInfo object, if it returns None the TarInfo object will be excluded from the archive. """ self._check("awx") if arcname is None: arcname = name # Exclude pathnames. if exclude is not None: import warnings warnings.warn("use the filter argument instead", DeprecationWarning, 2) if exclude(name): self._dbg(2, "tarfile: Excluded %r" % name) return # Skip if somebody tries to archive the archive... if self.name is not None and os.path.abspath(name) == self.name: self._dbg(2, "tarfile: Skipped %r" % name) return self._dbg(1, name) # Create a TarInfo object from the file. tarinfo = self.gettarinfo(name, arcname) if tarinfo is None: self._dbg(1, "tarfile: Unsupported type %r" % name) return # Change or exclude the TarInfo object. if filter is not None: tarinfo = filter(tarinfo) if tarinfo is None: self._dbg(2, "tarfile: Excluded %r" % name) return # Append the tar header and data to the archive. if tarinfo.isreg(): with bltn_open(name, "rb") as f: self.addfile(tarinfo, f) elif tarinfo.isdir(): self.addfile(tarinfo) if recursive: for f in os.listdir(name): self.add(os.path.join(name, f), os.path.join(arcname, f), recursive, exclude, filter=filter) else: self.addfile(tarinfo) def addfile(self, tarinfo, fileobj=None): """Add the TarInfo object `tarinfo' to the archive. If `fileobj' is given, tarinfo.size bytes are read from it and added to the archive. You can create TarInfo objects using gettarinfo(). On Windows platforms, `fileobj' should always be opened with mode 'rb' to avoid irritation about the file size. """ self._check("awx") tarinfo = copy.copy(tarinfo) buf = tarinfo.tobuf(self.format, self.encoding, self.errors) self.fileobj.write(buf) self.offset += len(buf) # If there's data to follow, append it. if fileobj is not None: copyfileobj(fileobj, self.fileobj, tarinfo.size) blocks, remainder = divmod(tarinfo.size, BLOCKSIZE) if remainder > 0: self.fileobj.write(NUL * (BLOCKSIZE - remainder)) blocks += 1 self.offset += blocks * BLOCKSIZE self.members.append(tarinfo) def extractall(self, path=".", members=None, *, numeric_owner=False): """Extract all members from the archive to the current working directory and set owner, modification time and permissions on directories afterwards. `path' specifies a different directory to extract to. `members' is optional and must be a subset of the list returned by getmembers(). If `numeric_owner` is True, only the numbers for user/group names are used and not the names. """ directories = [] if members is None: members = self for tarinfo in members: if tarinfo.isdir(): # Extract directories with a safe mode. directories.append(tarinfo) tarinfo = copy.copy(tarinfo) tarinfo.mode = 0o700 # Do not set_attrs directories, as we will do that further down self.extract(tarinfo, path, set_attrs=not tarinfo.isdir(), numeric_owner=numeric_owner) # Reverse sort directories. directories.sort(key=lambda a: a.name) directories.reverse() # Set correct owner, mtime and filemode on directories. for tarinfo in directories: dirpath = os.path.join(path, tarinfo.name) try: self.chown(tarinfo, dirpath, numeric_owner=numeric_owner) self.utime(tarinfo, dirpath) self.chmod(tarinfo, dirpath) except ExtractError as e: if self.errorlevel > 1: raise else: self._dbg(1, "tarfile: %s" % e) def extract(self, member, path="", set_attrs=True, *, numeric_owner=False): """Extract a member from the archive to the current working directory, using its full name. Its file information is extracted as accurately as possible. `member' may be a filename or a TarInfo object. You can specify a different directory using `path'. File attributes (owner, mtime, mode) are set unless `set_attrs' is False. If `numeric_owner` is True, only the numbers for user/group names are used and not the names. """ self._check("r") if isinstance(member, str): tarinfo = self.getmember(member) else: tarinfo = member # Prepare the link target for makelink(). if tarinfo.islnk(): tarinfo._link_target = os.path.join(path, tarinfo.linkname) try: self._extract_member(tarinfo, os.path.join(path, tarinfo.name), set_attrs=set_attrs, numeric_owner=numeric_owner) except OSError as e: if self.errorlevel > 0: raise else: if e.filename is None: self._dbg(1, "tarfile: %s" % e.strerror) else: self._dbg(1, "tarfile: %s %r" % (e.strerror, e.filename)) except ExtractError as e: if self.errorlevel > 1: raise else: self._dbg(1, "tarfile: %s" % e) def extractfile(self, member): """Extract a member from the archive as a file object. `member' may be a filename or a TarInfo object. If `member' is a regular file or a link, an io.BufferedReader object is returned. Otherwise, None is returned. """ self._check("r") if isinstance(member, str): tarinfo = self.getmember(member) else: tarinfo = member if tarinfo.isreg() or tarinfo.type not in SUPPORTED_TYPES: # Members with unknown types are treated as regular files. return self.fileobject(self, tarinfo) elif tarinfo.islnk() or tarinfo.issym(): if isinstance(self.fileobj, _Stream): # A small but ugly workaround for the case that someone tries # to extract a (sym)link as a file-object from a non-seekable # stream of tar blocks. raise StreamError("cannot extract (sym)link as file object") else: # A (sym)link's file object is its target's file object. return self.extractfile(self._find_link_target(tarinfo)) else: # If there's no data associated with the member (directory, chrdev, # blkdev, etc.), return None instead of a file object. return None def _extract_member(self, tarinfo, targetpath, set_attrs=True, numeric_owner=False): """Extract the TarInfo object tarinfo to a physical file called targetpath. """ # Fetch the TarInfo object for the given name # and build the destination pathname, replacing # forward slashes to platform specific separators. targetpath = targetpath.rstrip("/") targetpath = targetpath.replace("/", os.sep) # Create all upper directories. upperdirs = os.path.dirname(targetpath) if upperdirs and not os.path.exists(upperdirs): # Create directories that are not part of the archive with # default permissions. os.makedirs(upperdirs) if tarinfo.islnk() or tarinfo.issym(): self._dbg(1, "%s -> %s" % (tarinfo.name, tarinfo.linkname)) else: self._dbg(1, tarinfo.name) if tarinfo.isreg(): self.makefile(tarinfo, targetpath) elif tarinfo.isdir(): self.makedir(tarinfo, targetpath) elif tarinfo.isfifo(): self.makefifo(tarinfo, targetpath) elif tarinfo.ischr() or tarinfo.isblk(): self.makedev(tarinfo, targetpath) elif tarinfo.islnk() or tarinfo.issym(): self.makelink(tarinfo, targetpath) elif tarinfo.type not in SUPPORTED_TYPES: self.makeunknown(tarinfo, targetpath) else: self.makefile(tarinfo, targetpath) if set_attrs: self.chown(tarinfo, targetpath, numeric_owner) if not tarinfo.issym(): self.chmod(tarinfo, targetpath) self.utime(tarinfo, targetpath) #-------------------------------------------------------------------------- # Below are the different file methods. They are called via # _extract_member() when extract() is called. They can be replaced in a # subclass to implement other functionality. def makedir(self, tarinfo, targetpath): """Make a directory called targetpath. """ try: # Use a safe mode for the directory, the real mode is set # later in _extract_member(). os.mkdir(targetpath, 0o700) except FileExistsError: pass def makefile(self, tarinfo, targetpath): """Make a file called targetpath. """ source = self.fileobj source.seek(tarinfo.offset_data) with bltn_open(targetpath, "wb") as target: if tarinfo.sparse is not None: for offset, size in tarinfo.sparse: target.seek(offset) copyfileobj(source, target, size, ReadError) else: copyfileobj(source, target, tarinfo.size, ReadError) target.seek(tarinfo.size) target.truncate() def makeunknown(self, tarinfo, targetpath): """Make a file from a TarInfo object with an unknown type at targetpath. """ self.makefile(tarinfo, targetpath) self._dbg(1, "tarfile: Unknown file type %r, " \ "extracted as regular file." % tarinfo.type) def makefifo(self, tarinfo, targetpath): """Make a fifo called targetpath. """ if hasattr(os, "mkfifo"): os.mkfifo(targetpath) else: raise ExtractError("fifo not supported by system") def makedev(self, tarinfo, targetpath): """Make a character or block device called targetpath. """ if not hasattr(os, "mknod") or not hasattr(os, "makedev"): raise ExtractError("special devices not supported by system") mode = tarinfo.mode if tarinfo.isblk(): mode |= stat.S_IFBLK else: mode |= stat.S_IFCHR os.mknod(targetpath, mode, os.makedev(tarinfo.devmajor, tarinfo.devminor)) def makelink(self, tarinfo, targetpath): """Make a (symbolic) link called targetpath. If it cannot be created (platform limitation), we try to make a copy of the referenced file instead of a link. """ try: # For systems that support symbolic and hard links. if tarinfo.issym(): os.symlink(tarinfo.linkname, targetpath) else: # See extract(). if os.path.exists(tarinfo._link_target): os.link(tarinfo._link_target, targetpath) else: self._extract_member(self._find_link_target(tarinfo), targetpath) except symlink_exception: try: self._extract_member(self._find_link_target(tarinfo), targetpath) except KeyError: raise ExtractError("unable to resolve link inside archive") def chown(self, tarinfo, targetpath, numeric_owner): """Set owner of targetpath according to tarinfo. If numeric_owner is True, use .gid/.uid instead of .gname/.uname. """ if pwd and hasattr(os, "geteuid") and os.geteuid() == 0: # We have to be root to do so. if numeric_owner: g = tarinfo.gid u = tarinfo.uid else: try: g = grp.getgrnam(tarinfo.gname)[2] except KeyError: g = tarinfo.gid try: u = pwd.getpwnam(tarinfo.uname)[2] except KeyError: u = tarinfo.uid try: if tarinfo.issym() and hasattr(os, "lchown"): os.lchown(targetpath, u, g) else: os.chown(targetpath, u, g) except OSError as e: raise ExtractError("could not change owner") def chmod(self, tarinfo, targetpath): """Set file permissions of targetpath according to tarinfo. """ if hasattr(os, 'chmod'): try: os.chmod(targetpath, tarinfo.mode) except OSError as e: raise ExtractError("could not change mode") def utime(self, tarinfo, targetpath): """Set modification time of targetpath according to tarinfo. """ if not hasattr(os, 'utime'): return try: os.utime(targetpath, (tarinfo.mtime, tarinfo.mtime)) except OSError as e: raise ExtractError("could not change modification time") #-------------------------------------------------------------------------- def next(self): """Return the next member of the archive as a TarInfo object, when TarFile is opened for reading. Return None if there is no more available. """ self._check("ra") if self.firstmember is not None: m = self.firstmember self.firstmember = None return m # Advance the file pointer. if self.offset != self.fileobj.tell(): self.fileobj.seek(self.offset - 1) if not self.fileobj.read(1): raise ReadError("unexpected end of data") # Read the next block. tarinfo = None while True: try: tarinfo = self.tarinfo.fromtarfile(self) except EOFHeaderError as e: if self.ignore_zeros: self._dbg(2, "0x%X: %s" % (self.offset, e)) self.offset += BLOCKSIZE continue except InvalidHeaderError as e: if self.ignore_zeros: self._dbg(2, "0x%X: %s" % (self.offset, e)) self.offset += BLOCKSIZE continue elif self.offset == 0: raise ReadError(str(e)) except EmptyHeaderError: if self.offset == 0: raise ReadError("empty file") except TruncatedHeaderError as e: if self.offset == 0: raise ReadError(str(e)) except SubsequentHeaderError as e: raise ReadError(str(e)) break if tarinfo is not None: self.members.append(tarinfo) else: self._loaded = True return tarinfo #-------------------------------------------------------------------------- # Little helper methods: def _getmember(self, name, tarinfo=None, normalize=False): """Find an archive member by name from bottom to top. If tarinfo is given, it is used as the starting point. """ # Ensure that all members have been loaded. members = self.getmembers() # Limit the member search list up to tarinfo. if tarinfo is not None: members = members[:members.index(tarinfo)] if normalize: name = os.path.normpath(name) for member in reversed(members): if normalize: member_name = os.path.normpath(member.name) else: member_name = member.name if name == member_name: return member def _load(self): """Read through the entire archive file and look for readable members. """ while True: tarinfo = self.next() if tarinfo is None: break self._loaded = True def _check(self, mode=None): """Check if TarFile is still open, and if the operation's mode corresponds to TarFile's mode. """ if self.closed: raise OSError("%s is closed" % self.__class__.__name__) if mode is not None and self.mode not in mode: raise OSError("bad operation for mode %r" % self.mode) def _find_link_target(self, tarinfo): """Find the target member of a symlink or hardlink member in the archive. """ if tarinfo.issym(): # Always search the entire archive. linkname = "/".join(filter(None, (os.path.dirname(tarinfo.name), tarinfo.linkname))) limit = None else: # Search the archive before the link, because a hard link is # just a reference to an already archived file. linkname = tarinfo.linkname limit = tarinfo member = self._getmember(linkname, tarinfo=limit, normalize=True) if member is None: raise KeyError("linkname %r not found" % linkname) return member def __iter__(self): """Provide an iterator object. """ if self._loaded: return iter(self.members) else: return TarIter(self) def _dbg(self, level, msg): """Write debugging output to sys.stderr. """ if level <= self.debug: print(msg, file=sys.stderr) def __enter__(self): self._check() return self def __exit__(self, type, value, traceback): if type is None: self.close() else: # An exception occurred. We must not call close() because # it would try to write end-of-archive blocks and padding. if not self._extfileobj: self.fileobj.close() self.closed = True # class TarFile class TarIter: """Iterator Class. for tarinfo in TarFile(...): suite... """ def __init__(self, tarfile): """Construct a TarIter object. """ self.tarfile = tarfile self.index = 0 def __iter__(self): """Return iterator object. """ return self def __next__(self): """Return the next item using TarFile's next() method. When all members have been read, set TarFile as _loaded. """ # Fix for SF #1100429: Under rare circumstances it can # happen that getmembers() is called during iteration, # which will cause TarIter to stop prematurely. if self.index == 0 and self.tarfile.firstmember is not None: tarinfo = self.tarfile.next() elif self.index < len(self.tarfile.members): tarinfo = self.tarfile.members[self.index] elif not self.tarfile._loaded: tarinfo = self.tarfile.next() if not tarinfo: self.tarfile._loaded = True raise StopIteration else: raise StopIteration self.index += 1 return tarinfo #-------------------- # exported functions #-------------------- def is_tarfile(name): """Return True if name points to a tar archive that we are able to handle, else return False. """ try: t = open(name) t.close() return True except TarError: return False open = TarFile.open def main(): import argparse description = 'A simple command line interface for tarfile module.' parser = argparse.ArgumentParser(description=description) parser.add_argument('-v', '--verbose', action='store_true', default=False, help='Verbose output') group = parser.add_mutually_exclusive_group() group.add_argument('-l', '--list', metavar='<tarfile>', help='Show listing of a tarfile') group.add_argument('-e', '--extract', nargs='+', metavar=('<tarfile>', '<output_dir>'), help='Extract tarfile into target dir') group.add_argument('-c', '--create', nargs='+', metavar=('<name>', '<file>'), help='Create tarfile from sources') group.add_argument('-t', '--test', metavar='<tarfile>', help='Test if a tarfile is valid') args = parser.parse_args() if args.test: src = args.test if is_tarfile(src): with open(src, 'r') as tar: tar.getmembers() print(tar.getmembers(), file=sys.stderr) if args.verbose: print('{!r} is a tar archive.'.format(src)) else: parser.exit(1, '{!r} is not a tar archive.\n'.format(src)) elif args.list: src = args.list if is_tarfile(src): with TarFile.open(src, 'r:*') as tf: tf.list(verbose=args.verbose) else: parser.exit(1, '{!r} is not a tar archive.\n'.format(src)) elif args.extract: if len(args.extract) == 1: src = args.extract[0] curdir = os.curdir elif len(args.extract) == 2: src, curdir = args.extract else: parser.exit(1, parser.format_help()) if is_tarfile(src): with TarFile.open(src, 'r:*') as tf: tf.extractall(path=curdir) if args.verbose: if curdir == '.': msg = '{!r} file is extracted.'.format(src) else: msg = ('{!r} file is extracted ' 'into {!r} directory.').format(src, curdir) print(msg) else: parser.exit(1, '{!r} is not a tar archive.\n'.format(src)) elif args.create: tar_name = args.create.pop(0) _, ext = os.path.splitext(tar_name) compressions = { # gz '.gz': 'gz', '.tgz': 'gz', # xz '.xz': 'xz', '.txz': 'xz', # bz2 '.bz2': 'bz2', '.tbz': 'bz2', '.tbz2': 'bz2', '.tb2': 'bz2', } tar_mode = 'w:' + compressions[ext] if ext in compressions else 'w' tar_files = args.create with TarFile.open(tar_name, tar_mode) as tf: for file_name in tar_files: tf.add(file_name) if args.verbose: print('{!r} file created.'.format(tar_name)) else: parser.exit(1, parser.format_help()) if __name__ == '__main__': main()
3.7 shelve 模块
shelve模块是一个通过的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。是对pickle的高级封装
shelve序列化
import shelve #shelve打开一个文件 d = shelve.open('shelve_test') class Test(object): def __init__(self, n): self.n = n t1 = Test(10) t2 = Test(20) # print(t.n, t2.n) name = ["alex","rain","test"] d['test'] = name #持久化列表 d['t1'] = t1 #持久化类 d['t2'] = t2 d.close()
shelve反序列化
import shelve d = shelve.open('shelve_test') a = d['test'] print(a) #['alex', 'rain', 'test'] b = d['t1'] print(b) #<shelve1.Test object at 0x000000616C0181D0> print(b.n) #10 c = d['t2'] print(c.n) #20 d.close()
3.8 xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
遍历xml文件
import xml.etree.ElementTree as ET tree = ET.parse("xml_src.xml") #解析xml文件到tree句柄 root = tree.getroot() #获取根节点 print(root) #遍历xml文档 for sub_node1 in root: print(sub_node1.tag, sub_node1.attrib) for sub_node2 in sub_node1: #打印节点节点名称和节点值 print("\t%s = %s" %(sub_node2.tag, sub_node2.text)) #只遍历year节点 for node_year in root.iter("year"): print(node_year.tag, node_year.text)
修改xml文件:
import xml.etree.ElementTree as ET tree = ET.parse("xml_src.xml") root = tree.getroot() #修改xml文件,所有年节点值加1,并加上属性 update="yes" <year>2008</year> ==> <year updated="yes">2009</year> for year_node in root.iter("year"): new_year = int(year_node.text) + 1 year_node.text = str(new_year) year_node.set("updated", "yes") tree.write("xml_modify.xml") #写入文件
删除xml文件中的节点信息:
import xml.etree.ElementTree as ET tree = ET.parse("xml_src.xml") root = tree.getroot() #删除节点 #删除 rank值大于50的 country节点 for country_node in root.findall("country"): rank = int(country_node.find("rank").text) if rank > 50: root.remove(country_node) tree.write("xml_del.xml") #写入文件
生成xml文件:
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") #定义根节点 name1 = ET.SubElement(new_xml, "name", attrib={"enrolled":"yes"}) #定义第2层节点 age_name1 = ET.SubElement(name1, "age", attrib={"checked": "no"}) #定义第3层节点 sex_name1 = ET.SubElement(name1, "sex") age_name1.text = "20" #设置age_name1属性值 sex_name1.text = "male" #设置sex_name1属性值 name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age_name2 = ET.SubElement(name2, "age") sex_name2 = ET.SubElement(name2, "sex") age_name1.text = "19" sex_name2 = "famale" # 生成文档对象 et = ET.ElementTree(new_xml) #这里生成的xml文件没有称行符 et.write("xml_new.xml", encoding="utf-8", xml_declaration=True) #生成有换行及缩进的xml文件 from xml.dom import minidom import traceback ''' 需要生成如下格式xml文件 <?xml version="1.0" encoding="utf-8"?> <root> <book isbn="34909023"> <author>dikatour</author> </book> </root> ''' try: f = open("xml_new.xml", "w") try: doc = minidom.Document() rootNode = doc.createElement("root") doc.appendChild(rootNode) bookNode = doc.createElement("book") bookNode.setAttribute("isbn", "34909023") rootNode.appendChild(bookNode) authorNode = doc.createElement("author") bookNode.appendChild(authorNode) authorTextNode = doc.createTextNode("dikatour") authorNode.appendChild(authorTextNode) doc.writexml(f, "\t", "\t", "\n", "utf-8") except: trackback.print_exc() finally: f.close() except IOException: print("open file failed")
3.9 PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
3.10 configparser模块
2.x 为 ConfigParser
来看一个好多软件的常见配置文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser ''' 生成一个下面这样的配置文件 [DEFAULT] #这个默认项是全局的,相当于会在其他荐也加入默认项的属性 ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no ''' config = configparser.ConfigParser() # 直接定义一个字典为无序字典 # config["DEFAULT"] = {"ServerAliveInterval":"45", # "Compression":"yes", # "CompressionLevel":"9" # } # 先定义一个空字典的, configparser自动转成有序字典 config["DEFAULT"] = {} config["DEFAULT"]["ServerAliveInterval"] = "45" config["DEFAULT"]["Compression"] = "yes" config["DEFAULT"]["CompressionLevel"] = "9" config["DEFAULT"]["ForwardX11"] = "yes" config["bitbucket.org"] = {} config["bitbucket.org"]["User"] = "hg" config["topsecret.server.com"] = {} config["topsecret.server.com"]["Port"] = "50022" config["topsecret.server.com"]["ForwardX11"] = "no" with open("my.cgf", "w") as fp: config.write(fp)
configparser读取配置文件:
import configparser conf = configparser.ConfigParser() print(conf.sections()) # [] conf.read("my.cfg") #读取配置文件,执行结果将返回传入的文件名 print(conf.sections()) #['bitbucket.org', 'topsecret.server.com'],这里不显示全局的[DEFAULT] print(conf.defaults()) #OrderedDict([('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes')]) print(conf.defaults()["serveraliveinterval"]) #45 print(conf.options("bitbucket.org")) #['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'] print(conf.items("bitbucket.org")) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] print(conf.get("bitbucket.org", "user")) # hg print(conf.getint("topsecret.server.com", "port")) # 50022 (int型) print('bitbucket.org' in conf) # True print('bytebong.com' in conf) # False print(conf['bitbucket.org']['User']) # hg print(conf['bitbucket.org']['serveraliveinterval']) # 45,这里可以取到全局的属性 print(conf['DEFAULT']['Compression']) # yes for key in conf['bitbucket.org']: print(key) ''' 显示结果,这里把[DEFAULT]全局里的属性也显示出来了 user serveraliveinterval compression compressionlevel forwardx11 ''' # 只打印非全局的属性 # for key in conf['bitbucket.org']: # if key not in conf['DEFAULT']: # print(key)
configparser添加配置:
import configparser conf = configparser.ConfigParser() conf.read("my.cfg") # 添加 conf.defaults().setdefault("log", "yes") #DEFAULT中添加log = yes属性 conf.add_section("admin.com") #添加 [admin.com] conf["admin.com"]["url"] = "admin" # [admin.com]下添加url = admin conf.write(open("my_add.cfg", 'w'))
configparser删除配置:
import configparser conf = configparser.ConfigParser() conf.read("my.cfg") # 删除 conf.defaults().pop("compression") conf.remove_option("topsecret.server.com", "port") conf.remove_section("bitbucket.org") conf.write(open("my_del.cfg", 'w'))
configparser更改配置:
import configparser conf = configparser.ConfigParser() conf.read("my.cfg") conf.defaults()["serveraliveinterval"] = "46" conf["bitbucket.org"]["user"] = "admin" conf.write(open("my_mod.cfg", 'w'))
3.11 logging模块
python的logging模块提供了标准的日志接口,记录日志且线程安全。logging的日志可以分为 debug, info, warning, error and critical 5个级别。
| Level | When it’s used | 数字等级 |
| DEBUG | Detailed information, typically of interest only when diagnosing problems. | 10 |
| INFO | Confirmation that things are working as expected. | 20 |
| WARNING | An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. | 30 |
| ERROR | Due to a more serious problem, the software has not been able to perform some function. | 40 |
| CRITICAL | A serious error, indicating that the program itself may be unable to continue running. | 50 |
只有大于或等于当前日志等级的操作才会被记录。
对应格式:

简单用法:
import logging logging.warning("user [alex] attempted password more than 3 times") logging.critical("server is down") ''' 输出结果: WARNING:root:user [alex] attempted password more than 3 times CRITICAL:root:server is down '''
其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
加上记录时间:
import logging logging.basicConfig(filename="log2.log", level=logging.DEBUG, format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S") #logging.basicConfig(filename="log2.log", level=logging.DEBUG, format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p') #02/29/2016 2:58 PM logging.debug("This message should go to the log file") logging.info("So should this") logging.warning("And this too") ''' 记录结果 2016-02-29 14:58:15 This message should go to the log file 2016-02-29 14:58:15 So should this 2016-02-29 14:58:15 And this too '''
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识了
The logging library takes a modular approach and offers several categories of components: loggers, handlers, filters, and formatters.
- Loggers expose the interface that application code directly uses.
- Handlers send the log records (created by loggers) to the appropriate destination.
- Filters provide a finer grained facility for determining which log records to output.
- Formatters specify the layout of log records in the final output.
import logging # create logger logger = logging.getLogger("TEST LOG") logger.setLevel(logging.DEBUG) #全局的日志级别,全局日志级别高于非全局日志级别,非全局的日志级别将会被覆盖 # create console handler and set level to debug ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) # create file handler and set level to warning fh = logging.FileHandler("log3.log") fh.setLevel(logging.WARNING) # create log formatter formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") #formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') ''' :param asctime: 时间 name: Name of the logger (logging channel levelnames: 日志级别 message: 消息内容 ''' #add formatter to ch and fh ch.setFormatter(formatter) fh.setFormatter(formatter) # add ch and fh to logger logger.addHandler(ch) logger.addHandler(fh) # application code logger.debug("debug message") logger.info("info message") logger.warn("warn message") logger.error("error message") logger.critical("critical message")
logging轮转日志
#!/usr/bin/env python # -*- coding:utf-8 -*- ## logging轮转日志 log_size=100 # 日志文件大小,单位MB log_count=5 # 日志保留个数 class Singleton(object): """ 单例模式 """ def __new__(cls, *args, **kwargs): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls) # 实例化 return cls._instance class MyLog(Singleton): def __init__(self, logpath=log_path, log_count=log_count): self.logpath = logpath self.log_count = log_count if 'log_size' in dir(): self.log_size = log_size # 日志文件大小,单位MB else: self.log_size = 10 self.init_log() def init_log(self): """ 初始化logging :return: """ self.logger = logging.getLogger('mylogger') self.logger.setLevel(logging.DEBUG) # 创建一个handler,用于写入日志文件,(轮转日志) fh = RotatingFileHandler(self.logpath, maxBytes=1024 * 1024 * self.log_size, backupCount=self.log_count) # 基于日志大小的轮转日志 # fh = logging.handlers.TimedRotatingFileHandler(LOG_FILE, when='M', interval=1, backupCount=10) # 基于时间的轮转日志 """ "S": Seconds "M": Minutes "H": Hours "D": Days "W": Week day (0=Monday) "midnight": Roll over at midnight """ fh.setLevel(logging.DEBUG) # 定义handler的输出格式 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s', "%Y-%m-%d %H:%M:%S") # name:前面定义的logger名, 最后一项自定时间格式 # formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # name:前面定义的logger名 fh.setFormatter(formatter) # 给logger添加handler self.logger.addHandler(fh) def record_log(self, msg, level=2): """ 写入日志 :param msg: 要写入的消息 :param level: 级别 1:DEBUG 2:INFO 3:WARNING 4:ERROR 5:CRITICAL :return: """ if level == 1: self.logger.debug(msg) elif level == 2: self.logger.info(msg) elif level == 3: self.logger.warning(msg) elif level == 4: self.logger.error(msg) else: self.logger.critical(msg) if __name__ == '__main__': MyLog().record_log("msg 1 ...") # 记录日志 MyLog().record_log("msg 2 ...", 3)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号