
ElasticSearch安装分词插件IK
ElasticSearch本身带有分词插件,对英文支持的很好,但对中文支持的就不好了,把中文都分成了单个文字
所以我们安装一个支持中文的插件IK
1.下载安装IK
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
选择对应的版本,我这里下载的是7.6.2的版本
下载后,解压到安装目录下的plugin目录里

然后再重启一下ElasticSearch

看到加载了我们新安装的插件
2.测试使用
我们使用postman来测试
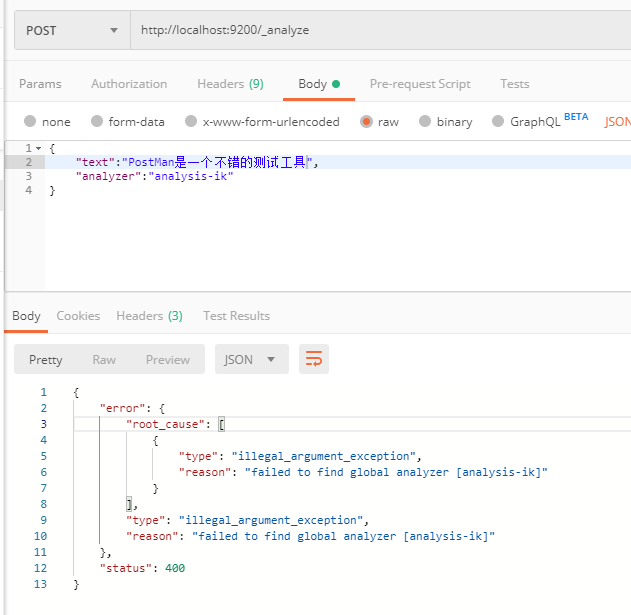
报错了,analyzer参数可能是错的,我们查一下文档

我们修改一下analyzer参数为ik_max_word

{ "tokens": [ { "token": "postman", "start_offset": 0, "end_offset": 7, "type": "ENGLISH", "position": 0 }, { "token": "是", "start_offset": 7, "end_offset": 8, "type": "CN_CHAR", "position": 1 }, { "token": "一个", "start_offset": 8, "end_offset": 10, "type": "CN_WORD", "position": 2 }, { "token": "一", "start_offset": 8, "end_offset": 9, "type": "TYPE_CNUM", "position": 3 }, { "token": "个", "start_offset": 9, "end_offset": 10, "type": "COUNT", "position": 4 }, { "token": "不错", "start_offset": 10, "end_offset": 12, "type": "CN_WORD", "position": 5 }, { "token": "的", "start_offset": 12, "end_offset": 13, "type": "CN_CHAR", "position": 6 }, { "token": "测试", "start_offset": 13, "end_offset": 15, "type": "CN_WORD", "position": 7 }, { "token": "试工", "start_offset": 14, "end_offset": 16, "type": "CN_WORD", "position": 8 }, { "token": "工具", "start_offset": 15, "end_offset": 17, "type": "CN_WORD", "position": 9 } ] }
这次是正确的啦,是我们想要的结果了。
3.其他
a)附带了解一下Analyzer与Tokenizer
https://blog.csdn.net/u014078154/article/details/80135703
Analyzer包含两个核心组件,Tokenizer以及TokenFilter。两者的区别在于,前者在字符级别处理流,而后者则在词语级别处理流。Tokenizer是Analyzer的第一步,其构造函数接收一个Reader作为参数,而TokenFilter则是一个类似的拦截器,其参数可以是TokenStream、Tokenizer。
1)Tokenizer
输入为Reader的TokenStream,其子类必须实现incrementToken()函数,并且在设置属性(attributes) 必须调用AttributeSource中的clearAttributes()方法。
b)ik_max_word 和 ik_smart 什么区别?
https://github.com/medcl/elasticsearch-analysis-ik
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
你今天为你的梦想努力了吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号