

Redis-缓存穿透 缓存击穿 缓存雪崩 缓存预热 缓存更新 缓存降级
在实际生产环境中,缓存的使用规范一直备受重视的,如果使用的不好,很容易遇到缓存穿透、缓存击穿、雪崩等严重异常情景,从而给系统带来难以预料的灾害。
为了避免缓存使用不当带来的损失,我们有必要了解每种异常产生的原因和解决办法,从而做出更好的预防措施。
一 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,每次请求都会去查库,不会查缓存,如果同一时间有大量请求进来的话,就会给数据库造成巨大的查询压力,甚至击垮 db 系统。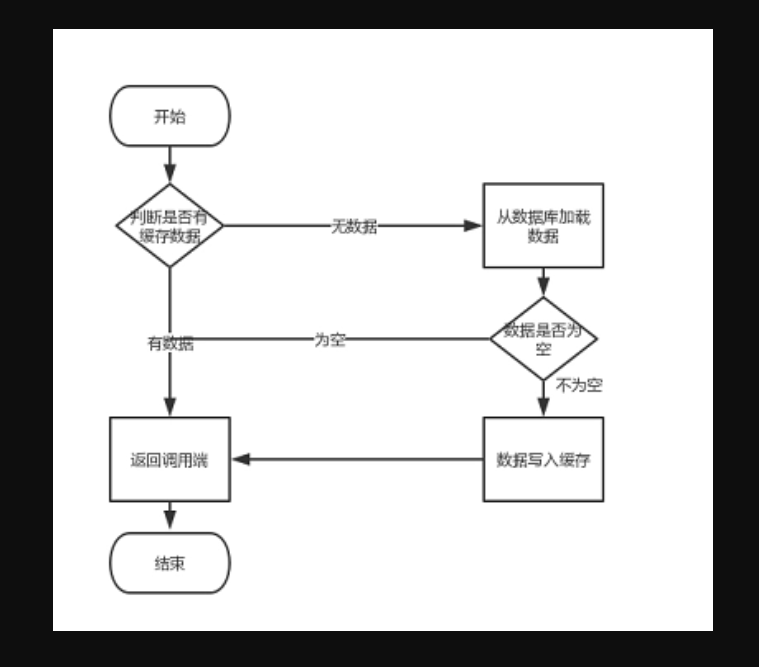
比如说查询 id 为 -1 的商品,这样的 id 在商品表里肯定不存在。如果没做特殊处理的话,攻击者很容易可以让系统奔溃,那我们该如何避免这种情况发生呢?
一般来说,缓存穿透常用的解决方案大概有两种:
1.1 缓存空对象
当缓存和数据都查不到对应 key 的数据时,可以将返回的空对象写到缓存中,这样下次请求该 key 时直接从缓存中查询返回空对象,就不用走 db 了。当然,为了避免存储过多空对象,通常会给空对象设置一个比较短的过期时间,就比如像这样给 key 设置 30秒 的过期时间:
redisTemplate.opsForValue().set(key, null, 30, TimeUnit.SECONDS);
这种方法会存在两个问题:
如果有大量的 key 穿透,缓存空对象会占用宝贵的内存空间。
空对象的 key 设置了过期时间,这段时间内可能数据库刚好有了该 key 的数据,从而导致数据不一致的情况。
这种情况下,我们可以用更好的解决方案,也就是布隆过滤器
1.2 布隆过滤器——Bloom Filter
布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中。
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突
小总结:
1.缓存穿透产生的原因是什么?
用户请求的数据在缓存中和数据库中都不存在,不断发起这样的请求,给数据库带来巨大压力
2.缓存穿透的解决方案有哪些?
缓存null值
布隆过滤
增强id的复杂度,避免被猜测id规律
做好数据的基础格式校验
加强用户权限校验
做好热点参数的限流
二 缓存击穿
缓存击穿从字面上看很容易让人跟穿透搞混,这也是很多面试官喜欢埋坑的地方,当然,只要我们对知识点了然于心的话,面试的时候也不会那么被糊弄。
简单来说,缓存击穿是指一个热点 key。在不停的扛着大并发,大并发集中对这一个点进行访问,当这个 key 在失效的瞬间,持续的大并发就击穿缓存,直接请求数据库,就好像堤坝突然破了一个口,大量洪水汹涌而入。
当发生缓存击穿的时候,数据库的查询压力会倍增,导致大量的请求阻塞。
解决办法也不难,既然是热点 key,那么说明该 key 会一直被访问,既然如此,我们就不对这个 key 设置失效时间了,如果数据需要更新的话,我们可以后台开启一个异步线程,发现过期的 key 直接重写缓存即可。
当然,这种解决方案只适用于不要求数据严格一致性的情况,因为当后台线程在构建缓存的时候,其他的线程很有可能也在读取数据,这样就会访问到旧数据了。
如果要严格保证数据一致的话,可以用互斥锁
三 互斥锁
互斥锁就是说,当 key 失效的时候,让一个线程读取数据并构建到缓存中,其他线程就先等待,直到缓存构建完后重新读取缓存即可。
如果是单机系统,用 JDK 本身的同步工具 Synchronized 或 ReentrantLock 就可以实现,但一般来说,都达到防止缓存击穿的流量了谁还搞什么单机系统,肯定是分布式高大上点啊,这种情况我们就可以用分布式锁来做互斥效果。
缓存雪崩
缓存雪崩也是key 失效后大量请求打到数据库的异常情况,不过,跟缓存击穿不同的是,缓存击穿因为指一个热点 key 失效导致的情况,而缓存雪崩是指缓存中大批量的数据同时过期,巨大的请求量直接落到 db 层,引起 db 压力过大甚至宕机,这也符合字面上的“雪崩”说法。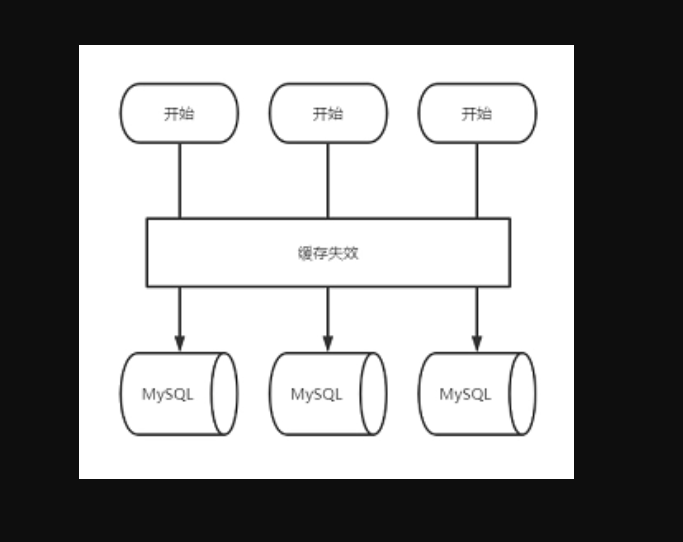
解决方案
缓存雪崩的解决方案和击穿的思路一致,可以设置 key 不过期或者互斥锁的方式。
除此之外,因为是预防大面积的 key 同时失效,可以给不同的 key 过期时间加上随机值,让缓存失效的时间点尽量均匀,这样可以保证数据不会在同一时间大面积失效。
redisTemplate.opsForValue().set(Key, value, time + Math.random() * 1000, TimeUnit.SECONDS);
四 缓存预热
缓存预热就是系统上线后,先将相关的数据构建到缓存中,这样就可以避免用户请求的时候直接查库。
这部分预热的数据主要取决于访问量和数据量大小。如果数据的访问量不大的话,那么就没必要做预热,都没什么多少请求了,直接按正常的缓存读取流程执行就好。
访问量大的话,也要看数据的大小来做预热措施。
a. 数据量不大的时候,工程启动的时候进行加载缓存动作,这种数据一般可以是电商首页的运营位之类的信息;
b. 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
c. 数据量太大的时候,优先保证热点数据进行提前加载到缓存,并且确保访问期间不能更改缓存,比如用定时器在秒杀活动前30分钟就把商品信息之类的刷新到缓存,同时规定后台运营人员不能在秒杀期间更改商品属性。
五 缓存更新
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
六 缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,类似 HashMap、Guava 这样的工具,一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
当然,这样的操作对于业务是有损害的,分布式系统中很容易就出现数据不一致的问题,所以,一般这种情况下,我们都优先保证从运维角度确保缓存服务器的高可用性。比如 Redis 的部署采用集群方式,同时做好备份。总之,尽量避免出现降级的影响。
七 最后
关于缓存的几大异常处理我们就讲解到这了。虽然每种异常我们都给出了解决的方案,但不是说这玩意直接套上就能用了。现实开发过程中还是要根据实际情况来针对缓存做相应措施,比如用布隆过滤器预防缓存穿透虽然很有效,但并不算特别常用。这年头,防止恶意攻击什么的都是先在运维层面做限制,业务代码层面更多的是对参数和数据做校验。
如果每个使用缓存的地方都要考虑的这么复杂的话,那工作量无疑会更加繁杂,过度设计只会让代码维护起来也麻烦,而且实用性还不一定强,没必要啊。程序员嘛,给自己增添烦恼的事情越少越好,毕竟我们最大的敌人不是996,而是那珍贵的发量啊。

