
MySQL关于用户关注粉丝表的设计方案
一、数据结构分析
用户关注粉丝是一个多对多的数据模型,分析对象的数据特征,我们给每个用户设计一个关注者属性和粉丝属性,用于存储用户的关注者id和粉丝id,如用户1:
$arr1 = [
'follow' => '[2,3,4],
'fans' => [4,5,6],
]
二、用户逻辑关系梳理
在用户关注粉丝模型中,有两种常见场景:
1.查看自己的粉丝或者关注列表:
这种情况下最多会出现三种关系:
其中1表示仅为本人所关注的人,2表示仅为本人的粉丝,3表示互粉
2.查看别人的粉丝或者关注列表:
此时是以别人的粉丝或关注者与自己的关系进行判定:
其中find表示别人的粉丝或关注列表,在这里统称为other,1表示other是本人所关注的,2表示other与本人互粉,3表示other是本人的粉丝,4表示和本人没有任何关系
三、数据库设计
CREATE TABLE `tb_vip_follow` (
`id` bigint NOT NULL AUTO_INCREMENT,
`vip_id` bigint DEFAULT '0' COMMENT '用户ID(粉丝ID)',
`followed_vip_id` bigint DEFAULT '0' COMMENT '关注的用户ID',
`status` tinyint(1) DEFAULT '0' COMMENT '关注状态(0关注 1取消)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `vip_followed_indx` (`vip_id`,`followed_vip_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='会员关注关系表';

用户每关注一个人,都会在表中添加一条数据,eg:
用户1关注了用户2,用户3;
用户2关注了用户1,用户3和用户4;
用户1有粉丝用户2;
用户2有粉丝用户1;
用户3有粉丝用户1,用户2;
用户4有粉丝用户2;
用户1和用户2互粉。
四、应用
这里为了省事,就没有考虑status字段,实际应用中,一定要补上,另外在关注之前记得要先查询是否存在取关,存在取关时只需要更新status字段
1.查看自己的粉丝或者关注列表:
以followed_vip_id字段查询,可以获取粉丝列表,以vip_id字段查询,可以获取关注者列表。
如查找用户1的粉丝:
select vip_id from tb_vip_follow where followed_vip_id = 1
如查找用户1的关注:
select followed_vip_id from tb_vip_follow where vip_id = 1
2.查看别人的粉丝或者关注列表:
查看别人的粉丝或者关注时就会复杂一些了,需要用到子查询或者连表
1)、用内连接查找所有互粉(可以根据自身需求在后面把查询范围补上,如用户1&用户2的关注/粉丝列表):
select a.* from tb_vip_follow as a inner join tb_vip_follow as b
on a.followed_vip_id = b.vip_id and a.vip_id = b.followed_vip_id
2)、用子查询查找用户1和用户2的共同关注
select followed_vip_id from tb_vip_follow
where followed_vip_id in (select followed_vip_id from tb_vip_follow where vip_id = 1)
and vip_id = 2
3)、用子查询查找用户2和用户3的共同粉丝
select vip_id from tb_vip_follow
where vip_id in (select vip_id from tb_vip_follow where followed_vip_id = 3)
and followed_vip_id = 2
缺点:
1.当用户量大时表数据量会非常庞大,因此必需要采用水平分表的方式将用户分散到多个表。
2.每一次使用该表时都要将整条数据取出进行计算,对资源耗费太过严重。
3.数据库瓶颈,并发受限。
基于mysql存在的缺点,使用redis的Hash数据类型配合使用。
五、使用redis的Hash数据类型
Redis hash是一个string类型的field和value的映射表。
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
每个用户分一张hash表,表名为用户id(可加前缀或后缀)
用户每关注一个人,便在hash表中添加一条数据
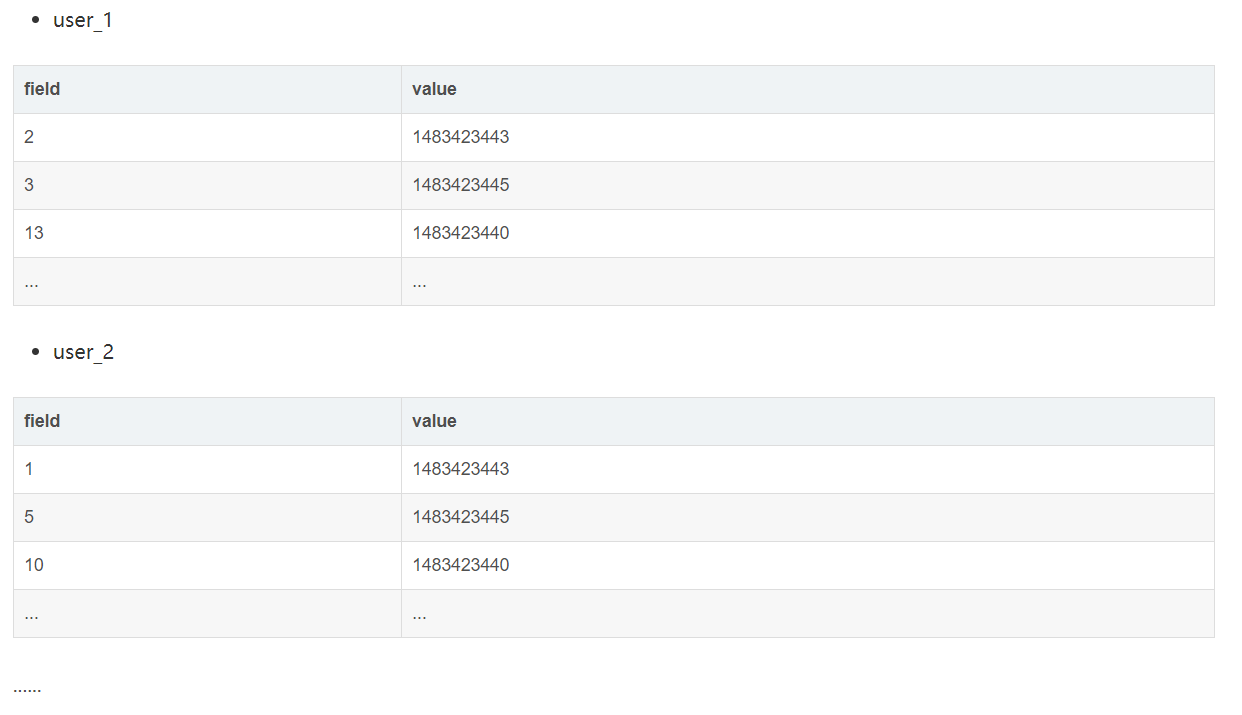
优点
1.查询处理速度快。
缺点
1.消耗服务器内存和CPU。最好使用一台单独的服务器来运行 Redis
2.数据查询,处理不如关系型数据库灵活。
3.开发步骤复杂,学习成本高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号